基于CITA区块链的纠删码分片存储实现
2021-03-14尹笑蓉朱承宇赵斌张召
尹笑蓉 朱承宇 赵斌 张召


摘要:区块链系统采用全复制的数据存储机制,为每个节点保留整个区块链的完整副本,系统扩展性差. 同時由于区块链系统中拜占庭节点的存在,导致传统分布式系统中使用的分片方案不能被直接应用于区 块链系统中.本文结合纠删码和拜占庭容错算法,使每个区块的存储消耗由O(n)降到0(1),增强了系统的 可扩展性.本文还提出了对区块数据进行划分的方法,在降低存储冗余的同时减小对查询效率的影响.提 出了无需网络通信的编码块存储方法,降低了系统存储和通信开销.还提出了区块链节点加入和退出的动 态重编码方法,既保证系统的稳定性,又降低了系统重编码开销.最后,在开源区块链系统CITA上实现, 并通过充分的实验,证明系统可扩展性、可用性和存储效率提升.
关键词:区块链;纠删码;拜占庭容错;存储可扩展性
中图分类号:TP302 文献标志码:A DOI: 10.3969/j.issn.1000-5641.2021.05.005
Erasure code partition storage based on the CITA blockchain
YIN Furong1, ZHU Chengyu1, ZHAO Bin2, ZHANG Zhao1
(X. School of Data Science and Engineering, East China Normal University, Shanghai 200062, China;
2. School of Computer and Electronic Information/School of Artificial Intelligence,
Nanjing Normal University, Nanjing 210023, China)
Abstract: Blockchain system adopts full replication data storage mechanism, which retains a complete copy of the whole block chain for each node. The scalability of the system is poor. Due to the existence of Byzantine nodes in the blockchain system, the shard scheme used in the traditional distributed system cannot be directly applied in the blockchain system. In this paper, the storage consumption of each block is reduced from O(n) to O(1) by combining erasure code and Byzantine fault-tolerant algorithm, and the scalability of the system is enhanced. This paper proposes a method to partition block data, which can reduce the storage redundancy and affect the query efficiency less. A coding block storage method without network communication is proposed to reduce the system storage and communication overhead. In addition, a dynamic recoding method for entry and exit of blockchain nodes is proposed, which not only ensures the reliability of the system, but also reduces the system recoding overhead. Finally, the system is implemented on the open source blockchain system CITA, and through sufficient experiments, it is proved that the system has improved scalability, availability and storage efficiency.
Keywords: blockchain; erasure code; Byzantine fault tolerance; storage scalability
收稿日期:2021-08-07
基金项目:国家自然科学基金(U1811264,U1911203, 6197215(2)
通信作者:张召,女,教授,博士生导师,研究方向为区块链系统研发、海量数据管理与分析
E-mail: zhzhang@dase.ecnu.edu.cn
0引 言
区块链是一种分布式、去中心化、无需信任的数据库系统,正在被越来越广泛地应用于金融管 理、银行、保险等领域.在区块链网络中,每个节点都需要遵守基于密码学的规则,每笔交易都需要与 网络中的其他节点达成共识,不需要任何第三方机构背书,降低了运行成本.
随着区块链系统规模的不断扩大,全复制的方法已经不能适应海量数据的增长需求.全复制存储 机制中数据量随节点数量增加线性增长,整个系统需要投入巨大的存储空间来保存区块,在有N个参与者的情况下,每个块的总体存储消耗为O(N).目前,逐步提高的交易吞吐率导致存储成为了整个区 块链扩展的瓶颈.研究者一直在寻找一种高效的区块链扩容方案.
为了缓解区块链系统的存储扩展性问题,业界提出了许多方案.如只在客户端保留区块头部,在 全节点保留着完整区块的轻量级客户端[1-21.其虽然减轻了客户端的存储压力,但每个全节点仍保留所 有区块数据的完整副本.闪电网络收集多个微支付,最终仅将余额信息上传到区块链网络上,其虽 然减轻了每个节点的存储压力,但没有从根本上解决区块数据全复制的问题.分片技术[4-5]将区块链网 络分成多个组,每个组存储系统中的部分数据,但在同一组内,仍采取了全复制的存储方式.
纠删码是一种数据保护方法,最初被用于解决网络传输中的丢包问题,后被推广到存储领域,可 提高存储的可靠性.本文继承BFT (Byzantine Fault Tolerance,拜占庭容错)协议的假设,实现了一 种基于纠删码的区块链系统,即在有n个节点的系统中,最多有/=「?]个节点是能够入侵甚至破 坏整个网络的拜占庭节点.为了保证基于纠删码的系统在有/个节点发生故障时仍能正常运行,须保 证纠删码编码后的冗余块个数不小于/,同时为降低冗余度,令冗余块个数为/.与全复制的存储方式 相比,本文实现的方法可以降低数据存储的冗余度,且不降低数据的可靠性.
本文的主要贡献如下:
(1)设计了纠删码编码前原始区块数据划分的方法.采用区块区间划分的方法对一个区块区间内 的区块进行划分,使得进行编码块存储时,一个区块的信息只存在于一个节点中;
(2)设计了无需节点间通信的编码块存储方法.利用区块头部的共识节点公钥地址列表全局一致 的特性,在不需要节点通信的情况下,每个节点只保留一个对应的编码块,全网拥有所有编码块的完 整信息;
(3)设计了依据节点的加入和退出动态同步编码的方法.通过动态同步编码,解决节点加入和退 出引起的系统存储消耗和容错能力下降的问题;
(4)在开源区块链系统CITA (https://citahub.com/)上实现了以上设计.
1 相关工作
纠删码(Erasure Code)[6-7]是一种可以在存储系统和通信系统中实现高可用性和高可靠性的前向 错误纠正技术.在网络传输中,其主要用于丟包恢复;在存储系统中,其主要应用于提高存储的可靠 性.与多副本的冗余复制方式相比,纠删码技术能够在保证数据可靠性的基础上降低数据存储的冗 余度.
CITA是一个开源的企业级联盟区块链.CITA采用BFT共识算法,当系统中有1/3的节点作恶 的情况下,仍能正常工作.其采用全复制的冗余存储方式,每个节点存储整个区块链的完整副本.CITA 对自身的共识机制和底层逻辑进行了深度优化.
随着区块链系统应用的领域越来越广泛,区块链系统存储带来的存储扩展性差,对服务器节点存 储性能要求高的问题渐渐地显露出来,这造成了区块链技术落地困难和存储成本高的问题.国内外针
对区块链的存储问题做了许多研究.总体而言,虽然众多的模型各有特色,但它们都有许多不足之处, 如贾大宇等[8]的模型对数据进行不平均存储,导致系统的去中心化水平降低,Dai等[9]只是提出了一 个框架,并没有形成完整的编码方案,而Xu等[10]设计的方法不适用于交易吞吐量较高的应用.
目前,纠删码在分布式系统中的应用已比较成熟,但由于区块链系统中拜占庭节点的存在,不能 将其移植到区块链中.将纠删码技术应用于区块链存储系统优化的研究较少,Perard等[11]在区块链系 统中存储能力较弱的节点上使用纠删码,虽在一定程度上降低了区块链的存储消耗,但导致系统去中 心化水平降低.同时,其并未处理拜占庭节点的错误信息,系统的稳定性较差. Qi等[12]的研究将纠删 码和拜占庭容错算法相结合,不仅降低了区块链系统的存储消耗,更使系统数据可靠性得到保障,但 其编码、查询效率较低,在实际应用中延迟较高.
2 基于纠删码的区块链分片存储方法设计
2.1系统架构
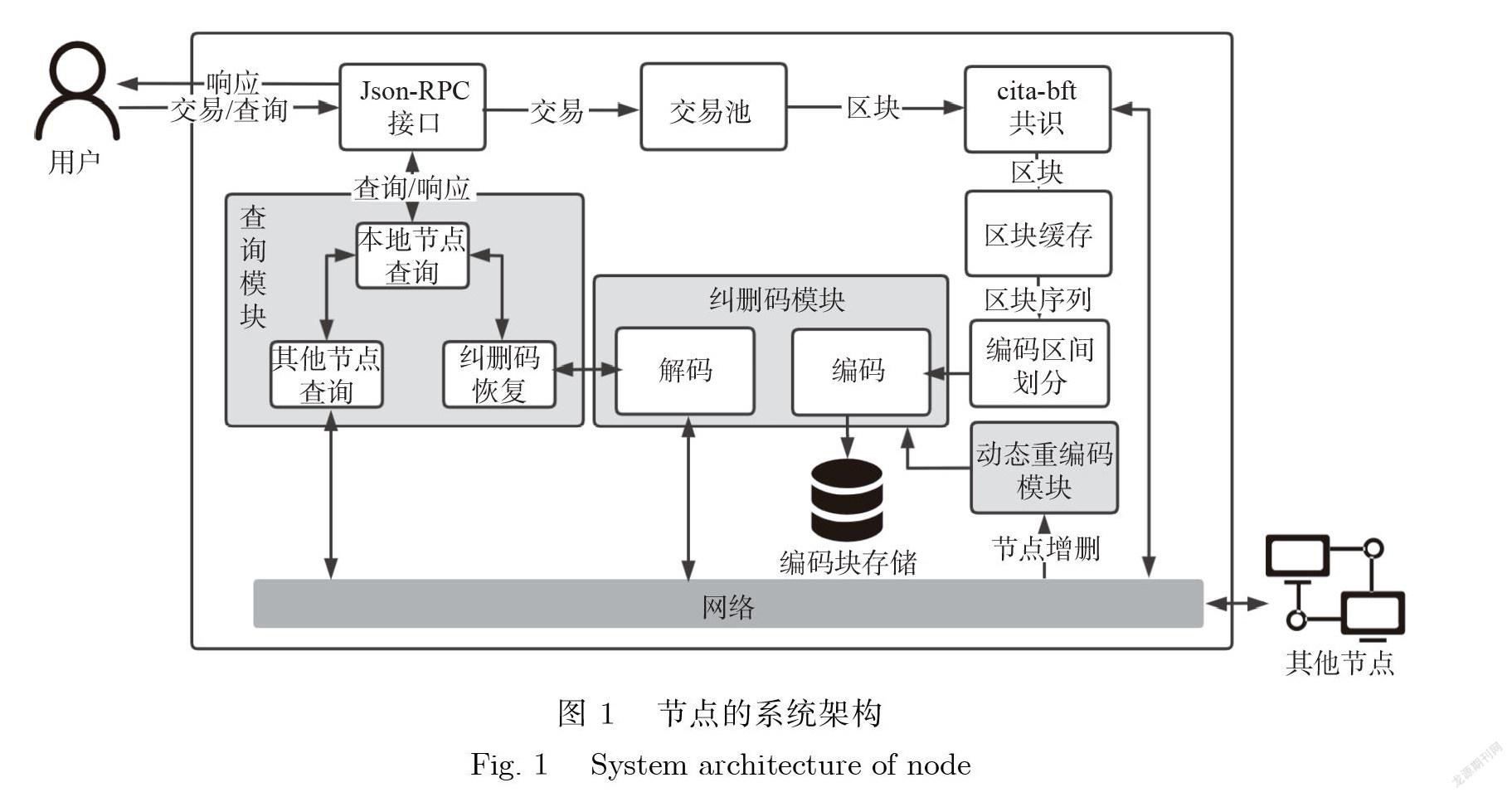
本系统是一个基于纠删码分片存储的区块链系统.每个用户通过客户端将交易发送到系统,并暂 存在交易池中.每隔一段时间,交易池中的交易被打包成一个区块,在节点之间对其进行共识,然后缓 存在系统中,最后经过纠删码编码,分布存储在系统的节点上.系统框架如图1所示,3个主要组成部 分为:纠删码模块、查询模块和动态重编码模块.
2.1.1纠删码模块
纠删码模块包括编码器和解码器两个子模块.区块缓存中的区块序列,经过区块区间划分,形成 原始数据块,通过编码器编码,形成纠删码编码块.每个节点根据自身在共识列表中的位置,存储对应 的编码块,丢弃其余块.系统并不是在一个节点上将区块编码成数据块,然后将它们分派给其他节点, 而是在每个节点上独立编码,无需节点间网络通信.所有的节点都遵循相同的编码规则,每个块的可 用性得到了保证.解码器可以通过底层网络从其他节点获取编码块,利用纠删码解码对原始数据块进 行恢复.
2.1.2 查询模块
查询模块接收来自客户端的查询请求,并进行响应.当查询模块处理查询区块B的请求时,有三
种不同的情况:
(1)如果区块B存储在本地,查询模块在没有任何网络通信的情况下将它返回客户端;
(2)如果目标节点^⑶是正确的,则查询模块可以从^⑶中获取区块B ;
(3)如果目标节点M (B)是拜占庭节点,则查询模块必须通过纠删码模块中的解码器恢复区块B . 最终,查询模块将验证来自其他节点的所有数据,避免通过解码恢复不正确的块数据.
2.1.3 动态重编码模块
当节点加入或退出系统时,动态重编码模块开始工作.为了在确保数据可用性的同时减少冗余, 历史数据可能需要被重新编码.在进行重编码时,需要通过纠删码模块中的解码器,从其他节点获取 数据.为了减少重编码开销,采用动态重编码策略,当冗余度达到阈值时,对历史数据进行重新编码. 此外,在删除旧编码块之前,每个节点都要确保其余的块已经完成了重新编码,以保证块的可用性.
2.2区块区间划分方法
本文提出对区块区间进行划分形成纠删码数据块的方法,区块区间是区块链中一段连续的区块 序列,将区块区间作为纠删码编码的基本单位具有两个优点:首先,在生成多个区块后对区块区间进 行编码,而非每产生一个区块进行一次编码,可降低纠删码编码开销;其次,避免了请求区块信息时, 向多个节点请求数据的问题,可降低网络资源的消耗.该方法中区块区间的大小用连续区块的数量来 表示,如图2所示区块区间,其大小为10.
为了保证每个区块或交易的查询最多只涉及一次网络通信或纠删码解码,需要使每个区块仅存 于一个纠删码数据块中.同时,纠删码编码算法要求输入的&个数据块的长度相等.所以,在对区块区 间进行划分时,需保证:(1)每个区块只能被分配到一个数据块中;(2) —个区块区间内的区块需尽可能 平均地分配到各个数据块中.由以上两个条件,可以将每个数据块中区块数量s的计算公式总结为下 式(1):
其中n为区块区间的大小,k为纠删码编码所需的数据块数量,n%k为n对k求余.
通过以上划分方法得到数据块,在长度较短的数据块后补充冗余数据,使得k个数据块的长度相 等.经过纠删码编码,生成m个纠删码冗余块,与数据块一起组成k + rn个编码块.
以上区块划分及纠删码编码过程采用的算法详见算法1.算法1的时间复杂度为O (n).算法1通 过循环检查新生区块的数量判断是否达到输入的区间大小标准(第1行),满足条件后根据式(1)处理 得到数据块(第2-5行),经过数据预处理使得数据块达到编码要求(第6、7行),通过编码得到编码块 结果(第8、9行).该算法实时监测区块数量变化,满足条件后对一个区间中的区块进行编码,不需要 每个区块编码一次,采用批处理的思想,可以提高编码的效率.数据预处理阶段可以通過开辟新线程, 增加系统并行性,进一步提高编码效率.
算法1区块区间划分编码算法
输入:包含^个区块的区块区间,数据块数量^ ,冗余块数量m 输出:fc + m个编码块
1: While新生成的区块数量大于等于n
2: If n%k == 0
3: 将n个区块平均分配到个数据块中
4: Else
5: 前n%fc个数据块每个存n/fc+ 1个区块,其他每个数据块存n/fc个区块
6: End if
7: 获得长度最长的数据块长度maxl
8: 在其余数据块后补“ 0”,使数据块长度达到一致maxl
9: 将fc个数据块作为纠删码的输人进行编码
10: 得到fc + m个编码块
11: End while
采用以上算法,当区块区间大小n = 10 ,数据块数量fc = 3 ,冗余块数量m = 1时,区块划分及纠 删码编码结果如图3所示.
2.3无需网络通信的编码块存储方法
为降低系统的冗余度,经过纠删码编码后,每个节点仅保存一个编码块,可将其他编码块删除.这 需要与其他节点达成共识,才能保证每个节点保存的区块不同,同时保证系统中保存着所有的编码块 信息.然而,区块链系统运行在一个不可靠的环境中,网络通信会增加系统的不稳定性,还会导致系统 的吞吐率降低.为了解决上述问题,本文利用每个节点上相同区块的共识节点公钥列表具有一致性的 特性,设计了一种无需网络通信的编码块存储方法.如图4所示,对原始数据进行划分并编码之后,根 据本节点公钥地址在所有节点公钥地址序列中的位置,保存对应于本节点的编码块,并删除其余编码 块.由于公钥地址有序序列在所有节点上都是一致的,所以节点间不需要网络通信就可以仅保存自己 所对应的编码块,同时保证系统中包含所有编码块的信息.
CITA采用键值数据库存储数据,在存储编码块时,为能够在请求区块时从数据库中查询到其所 在的编码块,需增加一个表来存储区块高度与编码块编号的映射关系.该方式会增大系统的存储消耗, 并增加查询的响应延迟.为了在查询时快速利用区块高度得到其所在的编码块,本文根据计算每个数 据块中区块数量的式(1),对编码块的编号进行定义.将编码块编号以文本形式表示,它由两部分组 成,第一部分标识该编码块所处的区块区间&第二部分标识该编码块处于该区块区间的第D个数据 块,两部分用下划线连接,表示为^_乃.如图4所示,高度为4的区块位于区块0?9所对应的区块区 间,其区块区间^ = 0,又因其在该区间的第D = 1个数据块,故高度为4的区块所对应的编码块编号 为 0—1.0_2 0_3
当用户向系统查询区块时,可以通过区块高度计算得到其所处的区块区间和数据块号,进而得到 其所对应编码块的编号.由区块高度计算编码块编号的算法详见算法2.算法2的时间复杂度为O (1).
算法2编码块编号计算算法
输入:区块高度\区块区间大小^,数据块个数&,冗余块个数爪 输出:编码块编号S_D
1: S = h/n
2: If n%k == 0
3: D = (h°%n) /(n/k)
4: Else if h°%n < (n/k +(1) * (n%k)
5: D = (h%n) /(n/k + (1)
6: Else
7: D = n%k + (h%n — (n/k + 1 )*( n%k)) /(n/k)
8: End if
9: Return S_D
假設系统对前10个区块的编码结果如图5所示,节点0接收到客户端对于区块3的请求,即区块 高度为3,由上述计算方法,得到S = 0(3/10 = 0),D = 0(3%10)/4 = 0),即S_D = 0_0.节点0读取 共识节点公钥地址有序序列,比对本地公钥地址在有序序列中的位置,若节点0上不存储0_0编码块, 则向公钥地址有序序列中的第D个节点(节点(3)发出对编码块0_0的请求.节点0将从节点3得到的 区块数据返回给客户端.
2.4动态重编码方法
区块链是一种分布式账本,账本数据的一致性依赖多个节点的共同维护.新机构加入时,需为其 搭建一个新的节点,并将其加入区块链系统;原有机构退出时,需将该节点从系统中删除.为了应对区 块链系统中节点加入或退出造成的重编码时间消耗过大的问题,本文提出了动态重编码的方法.
CITA区块链系统中存在不参与区块共识的普通节点.普通节点的加入或退出不会影响区块的共 识进程.普通节点加入后只需要提供查询功能即可,不需要保存编码块.为了在不保存编码块的情况 下保证普通节点的查询功能,普通节点需要同步共识节点的编码块索引.当用户向普通节点发起查询 请求时,普通节点根据从共识节点处同步的索引,向对应的共识节点发起请求,实现查询功能.
共识节点的加入与区块的共识同步进行,如图6所示.在生成一个区块区间时,新的共识节点加 入会导致共识节点列表的变化,该区块区间的前6个区块的共识节点为{N0, N1, N2, N3},而后4个区 块的共识节点为{N0, N1, N2, N3, N4}.这导致对该区块区间中的区块进行纠删码编码后,存储编码块的共识节点列表可以是{N0, N1, N2, N3},也可以是{N0, N1, N2, N3, N4}.为了统一存储该区块区间的共识节点列表,对区块区间共识节点列表做如下定义:区块区间最后一个区块的共识节点列表为此 区块区间的共识节点列表.由此可得存储10?19区块区间编码块的共识节点列表为{N0, N1, N2, N3, N4}.
共识节点加入后,系统中共识节点的数量会发生变化.CITA区块链系统保证系统中共识节点数 #和拜占庭节点数P的数量关系为:N>3F+ 1,即(N-(1)/3.当系统中共识节点数量变为 N + 1时,系统所能容忍的拜占庭节点的数量变为F',F'满足F'>F.若保持原来的编码参数不变, 系统只能在F个节点作恶时恢复丢失的数据.此时若系统中有F'个节点作恶,且F' > F,则不能保证 可以通过纠删码解码将原始数据恢复出来,从而不能保证系统的数据可用性.共识节点从系统中退出 时也面临相同的情况.为了解决上述问题,需要在新的共识节点加入时,对历史数据进行重新编码.
本文提出了动态纠删码重编码算法,即在保证系统中所有区块可恢复的情况下,不在节点加入或 退出时立刻对历史数据进行重新编码,而是根据节点加入或退出后,系统所容忍拜占庭节点数量是否 增多或减少,来动态地对历史数据进行重新编码.采用此方法可以降低重编码带来的系统开销,提高 系统的效率.动态重编码算法详见算法3.算法3的时间复杂度为0(1).算法3的第4-7行和第 9-12行分别对节点增加和删除的情况进行处理,由公式F=「(N-(1)/3]可得拜占庭节点数量,如果 节点数量的增加没有使拜占庭节点数量发生变化,或节点数量的减少恰好可以使拜占庭节点数量减 少相同的个数,则原来的编码模式可以保证系统的稳定性.由于并不是每次节点增删都会导致拜占庭 节点数量的变化,采用动态重编码的方法可以减少重编码的开销.
算法3动态重编码算法
输入:历史共识节点数量I ,新共识节点数量新区块区间,历史编码块数据 输出:编码结果
1: F'=「(,—(1)/3LF=「(N — (1)/3]
2:对新的区块区间,采用^共识节点列表进行纠删码编码 3: If N; >N
4: If F' == F
5: 新节点保存历史编码块索引
6: Else
7: 采用N'共识节点列表,对历史编码块数据进行重编码
8: End if
9: Else if N 10: If F' = F — 1 11: 不处理历史数据 12: Else 13: 采用N'共识节点列表,对历史编码块数据进行重编码 14: End if 15: End if 16:保存编码结果 3实验与评价 3.1实验环境和配置 (1)實验环境 本文实验在以下实验环境中进行,其中操作系统为Ubuntu18.04,配置AMD Ryzen 5 3550H (4核8线程,主频2.1 GHz,加速频率3.7 GHz)处理器,内存大小为16 GB,硬盘大小为512 G.本文 设计的算法使用Rust程序设计语言在0.25.2版本的CITA上实现. (2)参数配置 实验测试的节点数量为4,纠删码编码的数据块数量为3,冗余块数量为1. 3.2实验结果与分析 本文的实验评价主要参考4个指标:存储消耗、编码性能、响应延迟和稳定性. 3.2.1存储消耗 存储消耗的评估分为两部分,首先,为了证明纠删码编码的存储方式能降低系统的存储消耗,将 纠删码编码存储与全复制存储相比,评价纠删码编码存储在空间占用方面的优化效果,其中全复制的 存储系统中存储消耗与节点数成正比;其次,调整编码区间的大小,评估纠删码编码区块区间大小对 每个区块存储消耗的影响,由此结论可根据需求调整区块区间的大小,降低存储消耗. (1)全复制的存储方式与纠删码的存储方式的存储消耗对比 区块区间的大小固定为10,区块大小固定为80 kB,节点数量从4到15变化.如图7所示,展示了 在不同节点设置下存储每个块的平均存储消耗.对于全复制的存储方式(all),由于每个节点都需要保存区块链的完整副本,每个区块的平均存储容量随着节点数量的增加而线性增加.对于纠删码的存储 方式(ec),随着节点的增加,每个区块的平均存储容量产生轻微的波动,且总是小于所有区块大小的 2倍.全复制存储每个区块的存储消耗与纠删码存储每个区块的存储消耗的比值(%)随着节点的数量 增加而线性增加. 由以上实验分析得出,随着节点数量的增加,纠删码存储方式与全复制方式相比表现出更加明显 的存储性能优势,纠删码的存储方式在有多个节点的区块链系统中具有更高的应用价值.同时,采用 纠删码的存储方式,系统的存储压力不会因为节点数量的变化而发生大幅度的变化,无须因为节点的 增加调整系统存储配置,降低了系统维护工作量. (2)纠删码编码区块区间大小对每个区块存储消耗的影响 纠删码区块区间的大小会在一定程度上影响每个区块的平均存储容量,固定系统中的节点数为4, 固定区块的大小为80 kB,区块区间在10?21间变化.图8所显示的是每个区块的平均存储消耗与 区块区间大小的关系. 如图8实线所示,每个区块的存储消耗会随区块区间的变化产生周期性波动,这与本文设计的数 据块划分策略有关.当区块区间大小s= 10时,数据块的划分模式为(4,3,(3),其中4个区块形成一个 编码块,剩余的6个区块,每3个生成一个编码块,最终在较短的编码块后补0,然后进行纠删码编码 运算,得到冗余块的大小应约等于4个区块形成的编码块的大小,最终编码块的模式可表示为 (4, 3, 3, (4).每个区块的平均存储消耗为(4 +3+ 3 +(4)/10 = 1.4 .同理可以得到其他区块区间大小所对 应的每个区块的存储消耗.在一个区块区间变化周期中,当编码块的模式为沁,,,…,O0时(a为每个 纠删码编码块中区块数量的近似值),每个区块的平均存储消耗最低;当编码块的模式为(a+1,a, a,…,a + (1)时,每个区块的平均存储消耗最高. 如图8趋势线所示,在保持节点数量为4不变的情况下,虽然随着区块区间的增大,每个区块的 平均存储消耗总体呈下降的趋势,但实线所示折线具有周期性,适当调整区块区间大小可使纠删码的存储方式的优势达到最大值,并不需要盲目增大区块区间来提高存储效率. 3.2.2编码性能 全复制的存储系统存储一个区块的延迟约为2 ms,纠删码存储的编码操作会造成编码延迟,本小 节首先对编码延迟做了测试.其次,对于降低编码延迟的区块区间划分编码算法,对比区块区间划分 与单个区块划分编码方法所需编码时间,评估其优化效果.最后,综合评价区块区间划分编码算法中 的参数区块区间大小对整体编码延迟的影响和对单个区块编码延迟的影响.在实际应用中可通过调 整区块区间大小,降低编码延迟. (1)编码延迟 在进行区块存储时,与全复制的存储方式相比,纠删码的存储方式需要时间进行纠删码的编码. CITA系统中,保存一个区块需要约2 ms,当纠删码区块区间为12时,一次纠删码编码需要约20 ms, 平均到每个区块上为1.6 ms.由以上数据,可以总结得出,使用基于纠删码的存储方式,在存储时消耗 的时间约为全复制存储方式的1.8倍.相对于纠删码编码存储方式带来的从O (n)到O (1)的存储空间 优化而言,纠删码编码造成的时间开销是可以接受的. (2)区块区间划分与单个区块划分编码方法所需编码时间对比 确定区块大小为80 kB,节点数量为4,区块区间的大小为12?30,对比使用两种方法编码一个 区块区间内的区块所消耗的时间.实验结果如图9所示,采用区块区间划分的方法进行编码能够节省 编码的时间,且随着区块区间的增大,采用区块区间编码的优势也随之增大,在区块区间大小为30时, 采用区块区间编码的方法节省了近45%的编码时间.获得编码性能提升的主要原因为区块区间划分 的方法采用了批处理思想,减小了每次编码预处理及编码器启动时间在总编码时间中的占比. (3)区块区间大小对编码延迟的影响 如图10所示,随着区块区间的增大,每个区间的编码时间也随之增大. 但将该区间的编码时间平均到区块区间内的每个区块上,得到每个区块的平均编码时间与区块区间大小关系如图ii所示,随着区块区间的增大,区块的平均编码时间呈下降趋势.增大区块区间的 大小,可以降低每个区块的平均编码时间,但区块区间的增大会使得一次编码的时间增长,在具体使 用过程中,可以根据需求调整纠删码编码区块区间大小. 3.2.3响应延迟 在采用纠删码存储方式的系统中,每个节点上只保存部分区块的信息,当所需区块不存在所请求 的节点上或系统中的节点发生故障时,需要利用网络传输和纠删码的解码功能将原始数据恢复出来, 数据的恢复操作会造成响应延迟.采用全复制存储方式的CITA系统,由于没有节点间通信,用户查 询请求的响应延迟约为1.35 ms. 采用纠删码存储方式后,查询存在本地节点的区块,响应延迟约为9.5 ms,查询存在其他节点的区块,响应延迟约为44.05 ms.虽然与全复制的存储方式相比,由于区块数据的提取和节点间的通信, 响应延迟有所增加,但44 ms的延迟时间不会影响用户的使用体验.若不采用算法1而是采用对每个 区块进行编码存储的方法,则向某个节点请求一个区块得到响应所需的时间约为70 ms,约为采用算 法1响应延迟的7倍. 若查询时发现某编码块丢失,采用纠删码解码方式恢复数据,再返回给用户,响应延迟约为238 ms. 用户会感受到轻微的卡顿,但如果系统运行在一个较可靠的环境中,节点发生故障的概率将大大降低, 从而很少需要进行解码恢复,不会影响用户的使用体验. 3.2.4稳定性 系统的稳定性体现了系统应对外界干扰和故障的能力,采用全复制存储方式的系统能够容忍小 于等于?的拜占庭节点数.采用纠删码存储方式的系统稳定性以功能测试的形式,通过模拟系统故 障情况进行.首先,从系统外部将存储的数据块从数据库中删除,模拟数据丢失的情况.其次,通过命 令行指令强制节点掉线,模拟系统中的拜占庭节点.在以上两组模拟功能测试中,纠删码的解码恢复 功能都能正常运行,系统能够在发生故障时,通过纠删码解码恢复功能给出准确的查询结果,系统能 够容忍小于等于^的拜占庭节点数,没有因纠删码的加入降低系统的稳定性. 4结论 本文将纠删码与拜占庭容错算法相结合,在满足系统容错率的基础上,降低了区块存储的冗余度. 本文提出了原始区块数据划分的方法,提高了区块查询的速度,提出了无需节点间通信的存储编码块 方法,减少了节点间的通信开销.提出了根据节点的加入和删除动态同步编码的方法,降低了历史数 据重编码的系统消耗.最后,通过实验测试,验证了系统的可用性和效率提升. 本文的方法將系统的存储空间复杂度由O(n)降低到O(1),但不可避免因纠删码编码解码造成的 时间消耗,在后续的工作中将重视纠删码的编码和解码效率的优化. [参考文献] [1]CASTRO M, LISKOV B. Practical byzantine fault tolerance [C]//Proceedings of the Third Symposium on Operating Systems Design and Implementation. 1999: 173-186. [2]WOOD G. Ethereum: A secure decentralised generalised transaction ledger [J]. Ethereum Project Yellow Paper, 2014, 151: 1-32. [3] BURCHERT C, DECHER C, WATTENHOFER R. Scalable funding of bitcoin micropayment channel networks [J]. Royal Society Open Science, 2018, 5(8): 180089. [4]DANG H, DINH T T A, LOGHIN D, et al. Towards scaling blockchain systems via sharding [C]// Proceedings of the 2019 International Conference on Management of Data. 2019: 123-140. [5] AL-BASSAM M, SONNINO A, BANO S, et al. Chainspace: A sharded smart contracts platform [EB/OL]. (2017-08-1(2) [2021-07-05]. http://arXiv.org/pdf/1708.03778.pdf. [6] REED I S, SOLOMON G. Polynomial codes over certain finite fields [J]. Journal of the Society for Industrial & Applied Mathematics, 1960, 8(2): 300-304. [7]LIN W K, CHIU D M, LEE Y B. Erasure code replication revisited [C]//Proceedings of the Fourth International Conference on Peer- to-Peer Computing. IEEE, 2004: 90-97. [8]贾大宇,信俊昌,王之琼,等.区块键的存储容量可扩展模型[J].计算机科学与探索,2018, 12(4): 525-535. [9] DAI M, ZHANG S, WANG H, et al. A Low Storage Room Requirement Framework for Distributed Ledger in Blockchain [J]. IEEE Access, 2018(6): 22970-22975. [10]XU Y, HUANG Y. Segment blockchain: A size reduced storage mechanism for blockchain. IEEE Access, 2020(8): 17434-17441. [11]PERARD D, LACAN J, BACHY Y, et al. Erasure code-based low storage blockchain node [C]//2018 IEEE International Conference on Internet of Things and IEEE Green Computing and Communications and IEEE Cyber, Physical and Social Computing and IEEE Smart Data. IEEE, 2018: 1622-1627. [12]QI X, ZHANG Z, JIN C, et al. BFT-Store: Storage partition for permissioned blockchain via erasure coding [C]// 2020 IEEE 36th International Conference on Data Engineering. IEEE, 2020: 1926-1929. (責任编辑:林晶)
