NL2SQL技术在电厂设备缺陷数据统计中的应用研究
2021-03-13马骏李泽华沈铭科
马骏 李泽华 沈铭科



摘 要:文章提出了一种基于NL2SQL的电厂设备缺陷数据查询统计方法,将设备缺陷数据查询文本转化成SQL语句执行并返回查询统计结果。利用基于NLP预训练模型,将SQL语句预测模型划分为全局条件逻辑运算符预测、条件比较运算符和条件值预测、条件列预测、指标列聚合操作符和指标列预测等四个组件,并在搭建的电厂设备缺陷数据集上进行了测试验证。测试结果表明模型具有良好的SQL语句预测精度和执行效果。
关键词:NL2SQL;电厂;设备缺陷;数据统计;SQL语句预测
中图分类号:TP311.1 文献标识码:A文章编号:2096-4706(2021)15-0176-04
Abstract: This paper proposes a method for statistical analysis of power plant equipment defect data based on NL2SQL, which converts the query text of equipment defect data into SQL statements for execution and returns the query statistics results. Using the NLP-based pre-training model, the SQL statement prediction model is divided into four components: global conditional logic operator prediction, conditional comparison operator and condition value prediction, conditional column prediction, indicator column aggregation operator, and indicator column prediction. Test verification is carried out on the built power plant equipment defect data set. The test result shows that the model has good SQL statement prediction accuracy and execution effect.
Keywords: NL2SQL; power plant; equipment defect; data statistics; SQL statement prediction
0 引 言
電厂中由于设备数量众多,运行时间长,因此存在海量的设备缺陷数据。但是设备运维人员往往缺少有效手段进行方便快捷的获取及统计分析数据,宝贵的设备缺陷数据价值无法有效支撑到日常业务中。主要存在以下问题:(1)设备缺陷数据相关系统一般操作烦琐,耗用时间长,查询效率差;(2)电厂对缺陷业务分析需求经常无法提前预测,基层员工需花费大量时间为领导的报表需求进行数据查询搜索和报表整合,增加了领导决策时间;(3)当前设备缺陷数据信息查询,往往基于纯规则模式对用户的查询意图进行定制开发,虽然能够暂时满足部分业务的查询及统计分析的需求,但当要扩展到更多的数据统计分析需求时,往往要进行重新开发,开发周期长、成本高,运维难[1,2]。NL2SQL是一种将自然语言查询语句自动解析为SQL查询语句的技术,让用户可以口语化方式查询业务系统或数据仓库中的结构化数据,解决传统需要进入系统才能查询数据的烦琐过程,并在多个行业领域进行了应用,是一种轻量化、低成本的数据统计分析方式[3-5]。
本文利用基于NLP预训练模型的NL2SQL技术[6],将模型划分成四个主要组件:全局条件逻辑运算符预测、条件比较运算符和条件值预测、条件列预测、指标列聚合操作符和指标列预测,实现电厂设备缺陷数据SQL查询语句的精准预测。当中文查询语句中存在查询条件时,可以利用上述与条件相关的前3个组件得以解决。各部分组件预测完成后,将查询结果利用规则进行封装处理,得到最终的SQL查询语句并执行返回结果。本模型在搭建的电厂设备缺陷数据集上进行了测试验证。
1 电厂设备缺陷数据
本文针对电厂2012年至2021年运行过程中产生的缺陷数据进行梳理、清洗和标注,建立了包含三万条数据的数据库,依照比例8:1:1将数据划分为训练集、验证集和测试集。模型训练数据样例如表1所示。表中:“问题”对应设备缺陷相关的中文查询语句,数据样例为“2019年主变压器缺陷数量是多少”;“SQL查询语句”为中文查询语句对应的SQL查询语句的标注,在数据样例中,“cond_log_op”表示全局条件逻辑运算符,用0到2来代表单一条件、多条件OR和多条件AND,“cond”表示条件集合,每个条件都用三元组[条件值,条件列,条件比较运算符]来表征,比较运算符分别用0到4来代表NONE(无关系)、不等于、等于、小于、大于,“ind_col”表示指标列,“agg”表示指标列的聚合操作符,用0到5分别代表选择但无操作符、求和(SUM)、求最大值(MAX)、求最小值(MIN)、求平均值(AVG)、未选择(NONE)。
为保证模型与实际缺陷数量分析业务场景匹配,分别针对四个不同场景进行训练数据标注,具体数量如表2所示。其中:“单一指标”指数据只针对某一指标进行统计,比如“缺陷数量”;“多指标”指数据针对多个指标进行统计,比如“缺陷数量、风险累计”;不同顺序输入指查询条件有多个时,按照条件的不同顺序进行文字描述;限定值比较指针对指标进行范围比较,比如“缺陷数量超过100”。单一指标业务场景和多指标业务场景训练数据量超过9 000条,不同输入顺序业务场景训练数据量超过7 000条,限定值比较业务场景训练数据量超过6000条。
2 模型构建
2.1 查询语句的数学表达
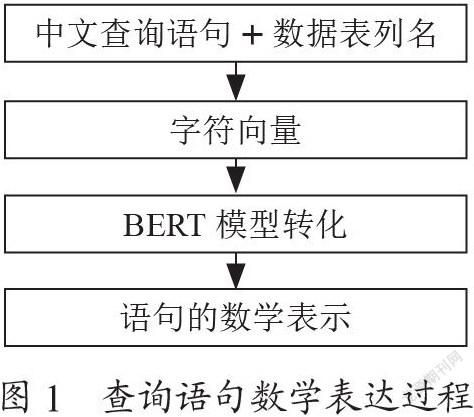
中文查询语句的数学表达是SQL语句正确预测的首要任务,转化过程如图1所示。首先,将中文查询语句和数据表的列名拼接,用字典映射成字符向量形式,再利用BERT模型进行转化,形成最终的用于预测模型输入的向量序列数学表达。
查询语句数学表达的前提是要建立一个字符字典,该字典用于将查询语句中的中文字符转化为数学向量。本文采用pytorch版本的Bert模型来实现字符的向量化编码,该Bert模型为Google公司发布的中文Bert_Base模型,采用了多头注意力机制,增加了对文本中重要信息的权重分配。
2.2 SQL语句预测流程
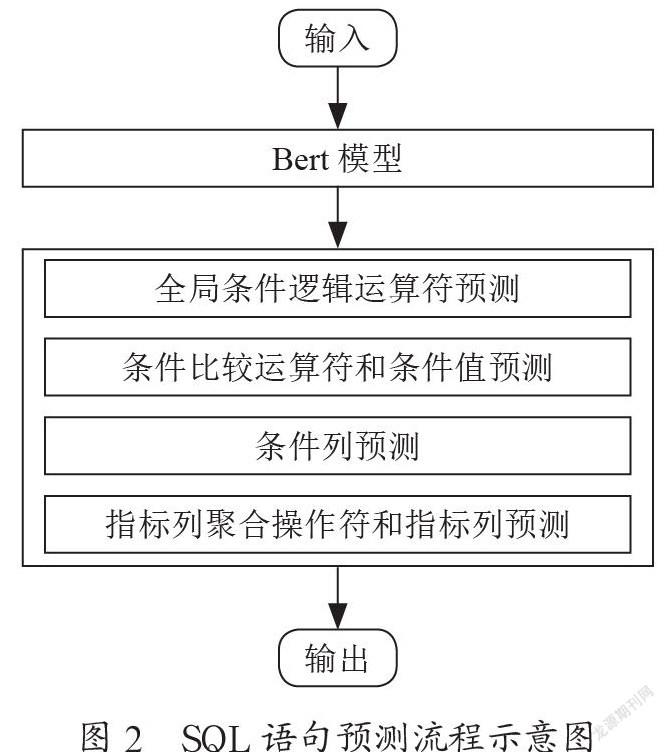
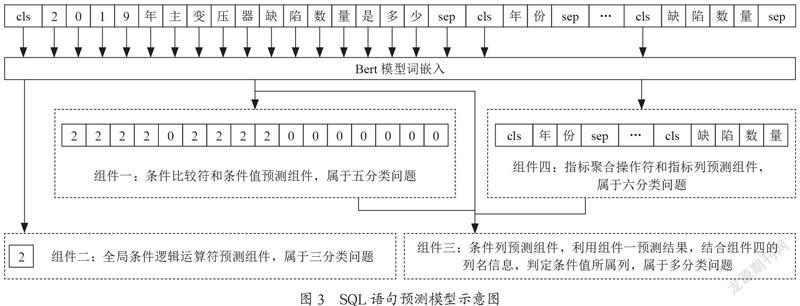
SQL语句预测流程示意图如图2所示,其中,四个组件预测过程均属于多分类任务。全局条件逻辑运算符预测组件用于判定中文查询语句是否存在多条件,且可以针对多条件间的逻辑关系进行预测;条件比较运算符符和条件值预测组件针对各条件值的比较关系进行预测;条件列预测组件负责匹配各条件值的所属列;指标列聚合操作符和指标列预测组件负责判定指标列以及指标列的聚合操作运算类型。
SQL语句预测模型示意图如图3所示。模型将中文查询语句和数据表的列名进行拼接作为输入,语句和列名的开头用“cls”进行标记,结尾用“sep”进行标记,“cls”和“sep”都已经过Bert模型训练。其中,最左边“cls”相应的向量用来进行全局条件逻辑运算符的预测,包括3类关系:单一条件、多条件OR和多条件AND,用0到2来表征;第二个以及之后的“cls”用来对指标列和对应聚合操作的预测,包括6类情况:选择但无操作符、求和(SUM)、求最大值(MAX)、求最小值(MIN)、求平均值(AVG)、未选择(NONE),用0到5来表征,其中未选择(NONE)代表字符不属于目标列;第一个“cls”和第一个“sep”之间的中文查询语句对应的向量用来进行条件比较符和条件值的预测,包括5类:NONE(无关系)、不等于、等于、小于和大于,用0到4来表征;根据组件一预测结果,值不为0的位置即对应条件值的位置,依此可以对应到中文查询语句中条件值,再结合数据表列名信息,即可以转换为多分类问题,将条件值匹配到响应的条件列。
3 结果分析
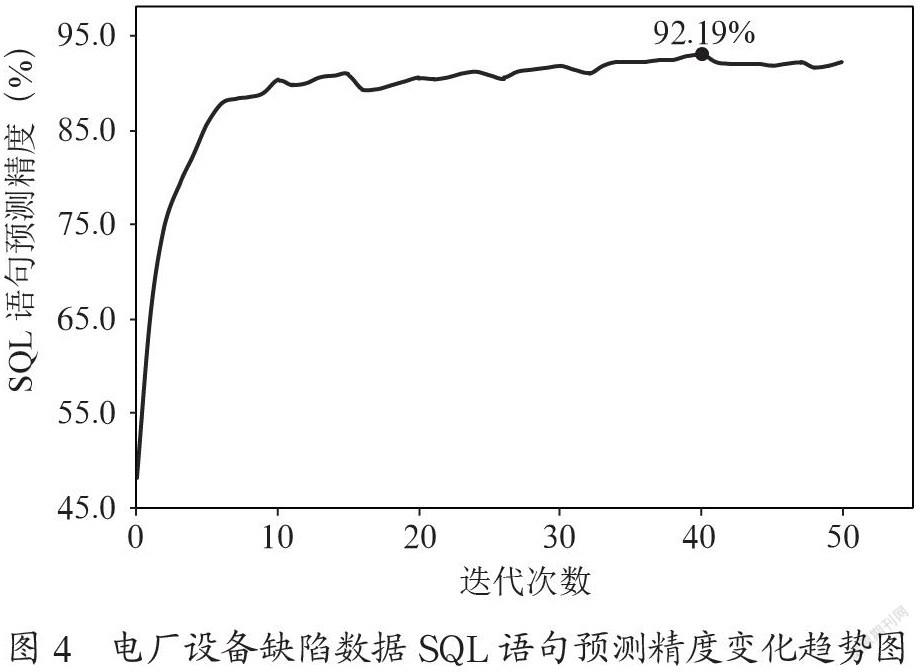
模型采用英伟达T4显卡和Pytorch深度学习框架进行训练,将逻辑准确率作为模型评价方式。逻辑准确率指模型预测的SQL语句结果与实际的SQL语句完全一致。主要模型参数设定包括:学习率(3e-5),Batchsize(15),迭代次数(50)。由图4可见,模型在电厂设备缺陷数据预测中,在迭代次数随着训练次数增加模型预测精度提升。当训练次数小于5次时,SQL语句预测精度快速爬升;当训练次数大于5次以后,SQL语句预测精度开始缓慢爬升,在缓慢爬升阶段,预测精度存在短暂下降的情况,主要是由于模型采用了随机梯度下降算法进行预测。当迭代次数为40时,模型SQL语句预测实现最高精度,达到92.19%。
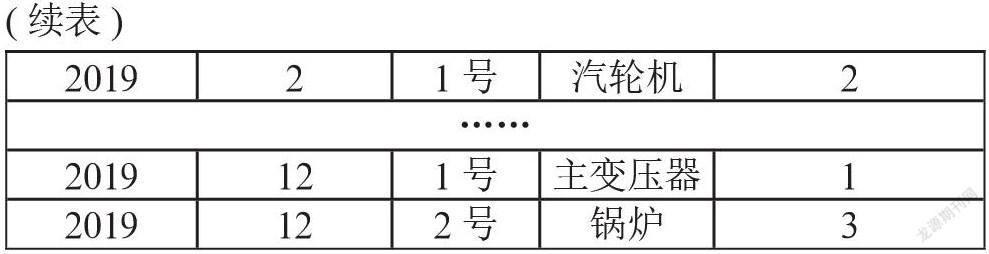
表3为电厂设备缺陷表部分数据展示。将设备缺陷数据提炼为年份、月份、机组、设备名称、缺陷数量等字段。其中:年份和月份指缺陷发生的时间年月;机组值缺陷发生的电厂机组编号;设备名称指设备缺陷发生的电厂具体设备;缺陷数量值各缺陷记录条目所统计的缺陷统计数量。
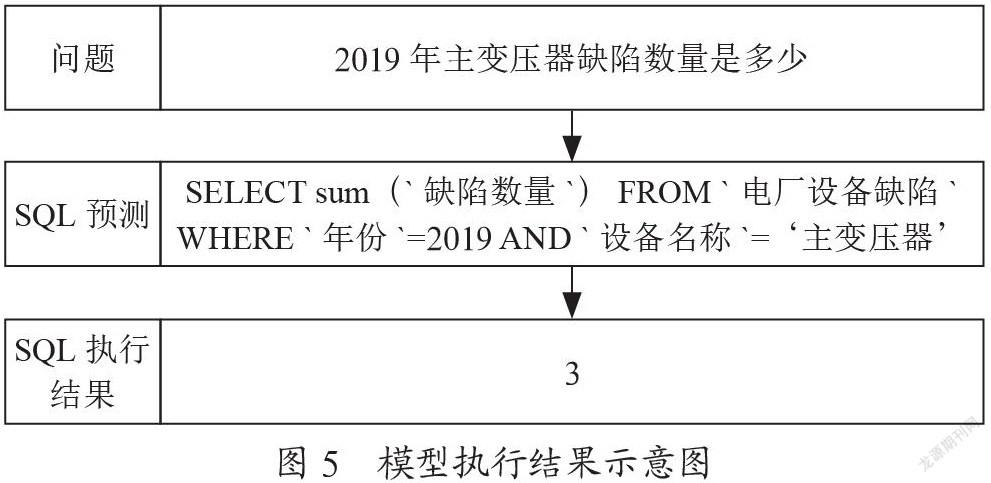
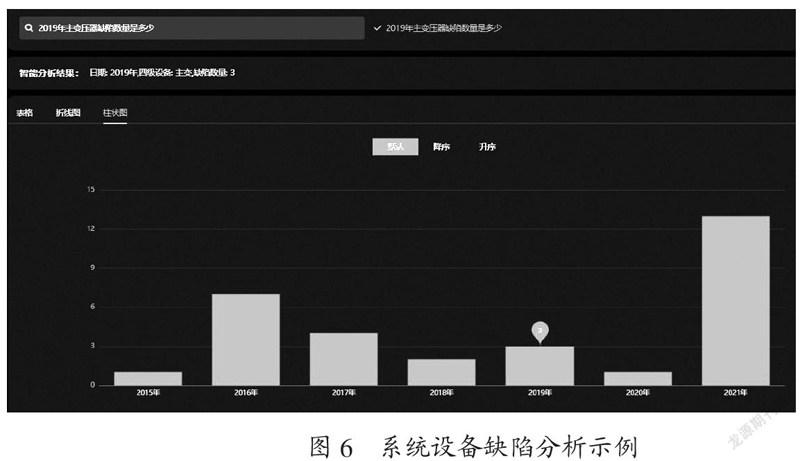
模型执行结果示意如图5所示。用户将查询的问题“2019年主变压器缺陷数量是多少”输入到模型中,模型预测SQL结果“SELECT sum(`缺陷数量`) FROM `电厂设备缺陷` WHERE `年份`=2019 AND `设备名称`=‘主变压器’”并执行,得出缺陷数量结果是“3”。模型执行结果显示,模型可以有效预测SQL查询语句,并通过查询语句得出正确的数据统计分析结果。实验系统实际执行效果如图6所示。
4 结 论
NL2SQL是一种将自然语言查询语句自动解析为SQL查询语句的技术。本文提出了一种基于NL2SQL的电厂设备缺陷数据统计分析方法,将设备缺陷数据查询文本转化成SQL语句执行并返回统计分析结果。利用基于NLP预训练Bert模型,将SQL语句预测模型划分为全局条件逻辑运算符预测、条件比较运算符和条件值预测、条件列预测、指标列聚合操作符和指标列预测等四个组件。各部分组件预测完成后,将查询结果利用规则进行封装处理,得到最终的SQL查询语句并执行返回结果。在搭建的三万条电厂设备缺陷数据集上进行了测试结果表明,模型在迭代次数为40时实现最高预测精度92.19%,具有良好的SQL语句预测精度和执行效果。
参考文献:
[1] 何珍华.电厂设备缺陷管理系统的设计与实现 [D].成都:電子科技大学,2013.
[2] 王林川,宋超翼,吴铁山,等.管理信息专家系统在电厂设备缺陷管理中的应用 [J].东北电力学院学报,2001(4):71-73+76.
[3] 刘译璟,徐林杰,代其锋.基于自然语言处理和深度学习的NL2SQL技术及其在BI增强分析中的应用 [J].中国信息化,2019(11):62-67.
[4] 张立新,于海亮,张栋栋,等.基于NL2SQL的智能问答系统研究与应用 [J].电脑知识与技术,2020,16(35):83-86.
[5] 曹金超,黄滔,陈刚,等.自然语言生成多表SQL查询语句技术研究 [J].计算机科学与探索,2020,14(7):1133-1141.
[6] DEVLIN J,CHANG M W,LEE K,et al. BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding [J/OL].arXiv:1810.04805 [cs.CL].(2018-10-11).https://arxiv.org/abs/1810.04805.
作者简介:马骏(1982.01—),男,汉族,内蒙古霍林郭勒人,工程师,本科,研究方向:电厂信息化技术。
3187500338200
