兼容Linux操作系统的域控制器生命周期管理
2021-03-13柳灏


摘 要:文章从未来汽车控制器发展的需求角度阐述了生命周期管理的重要性,分析了传统控制器生命周期方案的局限性,明确了MCU+GPU系统架构下对域控制器生命周期管理的要求,提出了一种可以兼容Linux操作系统的域控制器生命周期管理方案,同时分析了在异常状态下的生命周期响应策略并设计了该生命周期管理方案的软件架构,最后给出了在这种方案设计下实际软件运行的性能。
关键词:域控制器;生命周期管理;稳定性;鲁棒性
中图分类号:U463.6;TP393 文献标识码:A文章编号:2096-4706(2021)15-0054-06
Abstract: This paper explains the importance of life cycle management from the perspective of the development of future automotive controllers, analyzes the limitations of traditional controller life cycle management solutions, clarifies the requirements for domain controller life cycle management under the MCU+GPU system architecture, and proposes a domain controller life cycle management solution compatible with Linux operating system. At the same time, it analyzes the faults reaction strategy and designs the software architecture of life cycle management. Finally, the performance of actual software running under this design is given.
Keywords: domain controller; life cycle management; stability; robustness
0 引 言
未来的汽车将逐步向智能化、网联化、中央集成化发展,高算力的车载控制器是汽车发展的必然趋势。传统车载控制器由于选用MCU作为主控芯片无法满足高算力的要求。搭载Linux操作系统的GPU芯片虽然算力强大,可处理图像识别、深度学习等复杂运算,但安全性和稳定性难以达到车规级要求。所以当下车载域控制器都采用MCU+GPU的系统架构。GPU上运行图像、深度学习和决策算法,MCU上运行通信管理、电源管理、诊断管理等高实时性,高安全性的功能策略。MCU和GPU之间通过高带宽的SPI或以太网实现数据传输。
随着MCU+GPU系统架构的出现,域控制器如何在一次上电到休眠的生命周期中同时管理MCU和GPU,并保证其运行的稳定性和鲁棒性显得迫在眉睫。本文首先将阐述传统控制器的生命周期管理以及局限性;其次会提出兼容Linux操作系统的域控制器的生命周期管理方案;再次會进一步分析故障下的生命周期管理;从次会设计该生命周期管理方案的软件架构及实现方案;最后进行总结和展望。
1 传统汽车控制器的生命周期管理
在传统车载控制器诸如ECU、VCU中仅有一个MCU芯片。所以传统控制器的生命周期管理仅考虑了单MCU架构下的流程状态。图1所示为当前博世VCU8.0的生命周期管理方案。
这种生命周期管理主要用于区分MCU固定调度机制下的初始化流程,正常定周期调度流程以及下电反初始化流程。其中ini状态用于初始化流程的操作以及NVM存储数据的读取;Wait状态用于初始化结束后等待KL15唤醒信号的等待状态;PreDrive状态为收到Kl15唤醒信号后的准备状态;Drive状态为全功能运行状态;PostDrive为KL15下电后的准备下电状态;PrepareShutDown用于执行反初始化流程和NVM数据的存储。ShutDown为等待断电状态。
该生命周期管理有以下三点问题:(1)MCU上电后状态过于冗余。当今比较先进的电子电器架构,KL15的信号逐渐弱化。例如特斯拉Model3上已无启动开关。所以定周期调度中仅需Wait状态即可。(2)控制器级的故障在该生命周期管理中不会体现,所有软硬件故障均释放给上层逻辑处理。该生命周期管理仅负责上电和下电的切换。(3)只能支持MCU定周期的调度,无法同时支持MCU+GPU,无法支持Linux或QNX操作系统。
所以未来域控制器的生命周期管理需要支持多主控芯片的系统架构(MCU+GPU),能够识别硬件不同的工作状态,支持硬件级的故障响应并需要同时兼容定周期OS调度和Linux/QNX操作系统。
2 兼容Linux操作系统的域控制器生命周期管理方案
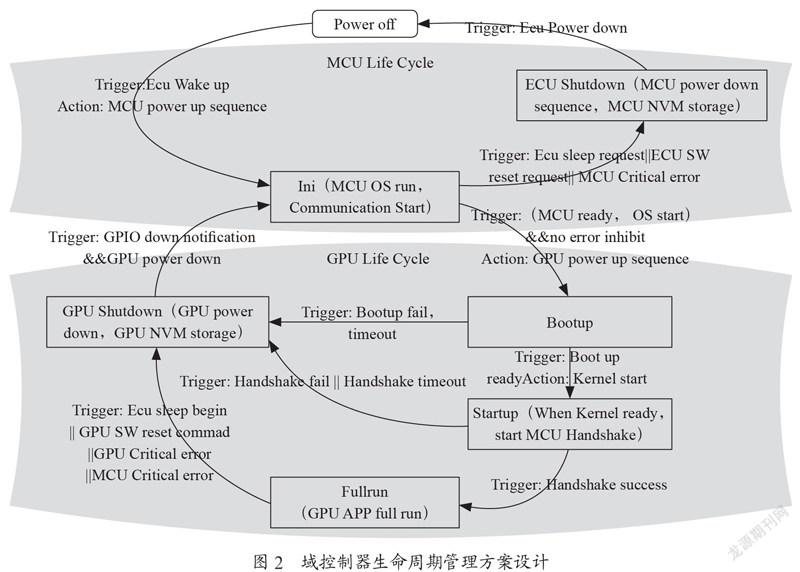
在MCU+GPU的系统架构中,MCU和GPU各司其职。MCU作为电管管理、网络管理、通讯管理的主控芯片会优先运行,GPU上搭载Linux操作系统负责复杂算法运算和摄像头驱动功能,需要在MCU运行后启动。所以域控制器的生命周期管理由两个子生命周期构成:MCU生命周期和GPU生命周期。MCU生命周期可以参考博世VCU8.0的设计,并要求尽早开始通信和启动GPU。GPU的生命周期参考Linux启动流程设计Bootup、Startup、Fullrun和GPUShutdown四个流程状态。由于两个子生命周期流程相互影响,且需要两者间实现握手,通信等交互功能,故整个控制器的生命周期状态的管理及跳转显得错综复杂。图2为本文提出的生命周期管理的方案设计。
其中Poweroff定义为整个域控制器休眠状态,MCU和GPU均不工作。
Ini状态定义为单MCU工作状态。在Ini状态下域控制器已可以正常通信,并能处理电源管理、通信管理、诊断功能的策略逻辑。故此时定义在该生命状态下的上层应用可作网络路由或执行器控制功能。图像以及决策相关的算法由于GPU尚未工作,不可以触发。在从Poweroff跳转到Ini状态过程中需要经历MCU的电源上电管理流程。CAN 通信和以太网通信在MCU启动后即可开始。
在生命周期进入ini状态后,MCU会主动请求GPU上电唤醒并启动GPU上电流程。此时GPU的boot启动,进入Bootup状态。Bootup状态定义为GPU内的Boot开始运行,但Linuxkernel尚未启动。Boot启动成功后,需要GPU通知MCU,进而跳转Startup状态。由于在Boot启动过程中,MCU和GPU芯片间尚未建立通信,故系统设计上要求增加一路GPIO在MCU和GPU之间。当GPUBoot启动成功,需要GPU上拉通知MCU。该GPIO要求高有效,并设计下拉电阻,实现GPU断电时MCU也收到无效信号。在Bootup状态中如停留时间过长MCU仍未收到Boot启动成功信号,认为启动超时,生命周期将会直接跳转到GPU Shutdown状态。从域控制器被喚醒到进入Bootup状态要求时间尽量短,本方案可做到100 ms左右,后文将做进一步阐述。
在生命周期进入GPUStartup状态后,Linux操作系统kernel开始运行,此时GPU上的SPI通信,以太网通信开始启动,Linux上部分APP开始初始化。启动完成后,GPU和MCU之间开始建立握手机制(SPI、以太网或IPC)。MCU收到成功握手信号后触发生命周期状态即跳转到Fullrun。如长时间未建立握手或握手失败,生命周期将会直接跳转到GPUshutdown状态。Startup和Bootup状态均为过程性状态,图像以及决策相关的算法由于APP尚未工作,不可以触发。状态设计上将GPU启动流程拆分为Bootup和Startup两个状态主要考虑到:(1)方便启动异常原因的记录,区分是Boot原因还是kernel原因导致启动失败,方便工程师调试和测试;(2)在Boot失败后能快速下电修复避免过长时间的等待,提高用户满意度。根据实验室数据,在搭载linux的征程2处理器GPU上,Bootup状态可以做到停留1 s内,Startup状态会停留5 s左右。
在生命周期的Fullrun状态定义为MCU和GPU芯片均已正常运行且无硬件及操作系统级故障。此时MCU上功能策略和GPU上所有算法均可满负荷运行。该状态停留时间无特定要求。在出现GPU或MCU故障,以及需要域控制器休眠时才会退出该状态,进入GPUShutdown状态。
GPUShutdown状态为GPU的下电过程状态。进入该状态后,GPU上的APP执行反初始化操作,并做GPU端的NVM数据存储,为下次启动做准备。之后Boot上做准备下电处理,完成后通过拉低上文提到的GPIO通知MCU。MCU执行GPU的下电流程逻辑。当MCU完成GPU端的所有下电流程,并收到GPIO被拉低的通知后,生命周期跳转到Ini状态,单MCU工作。有两点值得注意:(1)在该状态下如MCU长时间未收到GPIO低的通知,认为准备下电超时,MCU将强制执行GPU下电流程。(2)如由于GPU异常故障或启动不成功导致的下电,生命周期进入Ini后会继续请求GPU启动,尝试通过GPUreset实现故障修复。连续5次失败后进入Ini将不再继续请求GPU启动。
EcuShutdown状态为MCU的下电过程。该状态由Ini跳转而来,故此时GPU已完成下电。进入该状态的条件有:(1)正常控制器下电休眠;(2)上层软件请求的reset;(3)MCU端异常故障导致的reset。三者满足一个即可进入EcuShutdown。在该状态中MCU执行Ecu下电逻辑和NVM存储操作,与传统车载控制器下电状态一致。
这种生命周期管理设计,主控逻辑由MCU负责,但需要MCU和GPU保持通信交互,保证两芯片状态和策略的一致性。在异常状态下该方案也支持MCU端的单独运行,所以可以根据不同的软件应用场景灵活地选择GPU+MCU同时运行,MCU单独运行两种芯片级的工作状态。该方案同时支持故障下的各种响应。
3 故障情况下的响应
生命周期管理对不同故障的响应会直接反映出控制器的稳定性和鲁棒性。本文将基于TC234+征程2GPU的系统架构,较详细地分析电源故障、通信故障以及温度故障下的生命周期响应策略,以满足稳定性和鲁棒性的要求。硬件架构图如图3所示。
3.1 控制器电源监控故障
控制器电源监控的主要故障有:对控制器供电12伏电压的过压欠压;对MCU芯片供电5伏的过压欠压;对GPU芯片供电5伏的过压欠压。
当出现对控制器供电12伏的过压欠压时,会导致整个控制器电路的失控和不可信。所以在12伏过压或欠压时,认为是MCU严重故障,生命周期管理将从Fullrun->GPU Shutdown->Ini ->Ecu Shutdown ->Poweroff。并且要求下电结束后不能对MCU和GPU供电,故在从Poweroff跳转Ini过程中如发现12伏过压或欠压,触发硬件复位。同时需要在硬件设计中对12伏的电压有检测,如出现过压或欠压电源芯片不能对MCU供电。
当出现对MCU芯片供电的欠压和过压时,会导致MCU上程序运行不可信,同时GPU端的供电也可能出现不可信。所以在MCU端5伏供电过压或欠压时,认为是MCU严重故障,生命周期管理将从Fullrun->GPU Shutdown->Ini ->Ecu Shutdown ->Poweroff。与12伏供电故障不同的是,MCU端5伏出现故障后,下电完成后需要支持再次唤醒MCU到Ini状态,并监控MCU侧5伏电压。如电压在reset后恢复正常,则再次正常上电至Fullrun状态;如reset后5伏供电仍不正常,再次重启控制器。连续3次重启失败后,在当次生命周期中,不再启动MCU。
当对GPU 供电5 伏出现过压或欠压时,仅GPU端程序运行不可信。所以仅认为是GPU严重故障,生命周期将从Fullrun->GPU Shutdown->Ini,并保持监测GPU供电电压,当对GPU供电正常后由Ini->Bootup ->Startup –>Fullrun。
3.2 MCU与GPU间通信故障
MCU和GPU间通信有以下两种:上电下电GPIO端子通信,SPI/以太网信号交互通信。通信故障所覆盖的异常状态不仅包括MCU和GPU间狭义的通信功能故障,同时也覆盖Linuxkernel crash、GPUboot失控、MCU周期调度崩溃等操作系统级的异常状态。
上电下电GPIO端子通信在上文已提到,主要用于GPUboot失控,或GPU异常断电时通知MCU的一种机制。同时也是GPU正常关机后的一种通知机制。所以在GPIO被拉低后,生命周期管理将从Fullrun->GPU Shutdown->Ini。之后将会连续尝试3次再次启动GPU,若不成功,将保持在Ini状态中。
SPI/以太网信号交互通信在生命周期管理中主要用于MCU和Linuxkernel间的相互监控。在首次上电时会有初始化握手校验,如握手不成功,认为域控制器启动失败,生命周期将会从Fullrun->GPU Shutdown->Ini,并会尝试再次请求启动GPU,连续5次失败后将会保持在Ini状态中。握手成功后,MCU和GPU会定周期监控通信的稳定性。当MCU侧检测到通信丢失,会强制对GPU断电并跳转至Ini;当GPU侧检测到通信丢失,会执行GPU侧的下电操作,并通过GPIO通知MCU,生命周期会跳转至Ini。同样的,进入Ini状态后MCU会尝试再次请求启动GPU,连续5次失败后将会保持在Ini状态中。
3.3 温度监控
根据图3硬件架构,我们会监控控制器PCB板温度和征程2芯片内部温度。
查阅征程2芯片手册,芯片内温度分为两个等级:大于125 ℃,芯片要求关机重启;大于105 ℃小于125 ℃,要求芯片降频处理,以减少功耗。所以在生命周期管理中,需要linux上系统软件实时读取芯片内温度寄存器,当超过125 ℃,linux执行关机流程,并通知MCU,状态机从Fullrun->GPU Shutdown->Ini。当芯片温度超过105 ℃,小于125 ℃,生命周期状态不变,降频处理由Linux上软件负责,复杂算法可根据开发者需求停止运行。
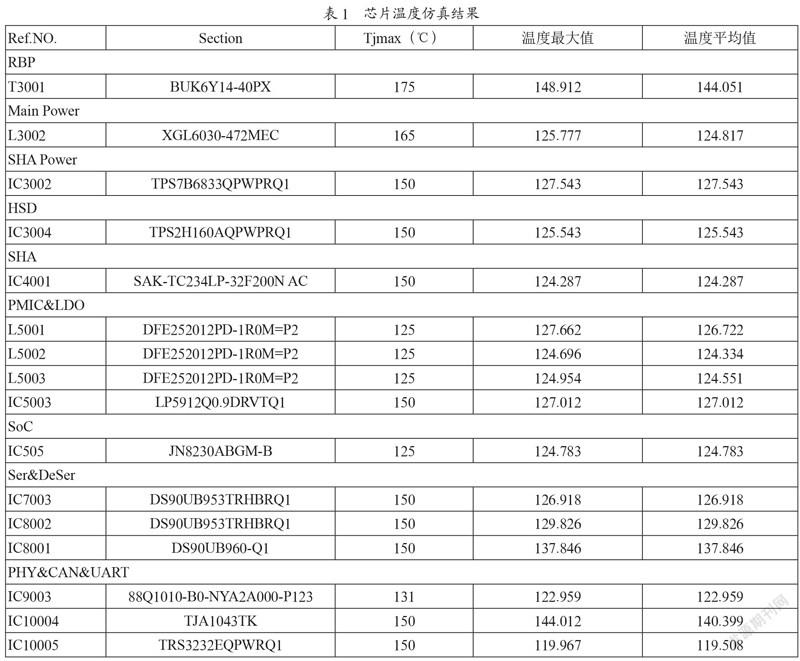
PCB温度由MCU监控。实际温度故障的阈值需要根据控制器热仿真结果进行判断。我们根据图3所示架构图做热仿真。设定热交换系数为10 W/m2K,初始压力为101 325 Pa,环境温度为85 ℃,MCU功率为0.492 W,征程2芯片功率为4.656 W。热仿真结果如表1所示。
我们集中关注MCUTC234和GPU征程2的仿真结果。发现GPU上温度,在环境温度为85 ℃时最高温度已达到124 ℃,并且此时MCU 控制器内环境温度最高也达到了124 ℃。考虑到GPU极限温度125 ℃,MCU极限温度150 ℃,需要在此时做GPU下电处理。此时根据仿真结果,PCB板温达到115 ℃。所以在MCU监控板温达到115 ℃时,生命周期管理需要从Fullrun->GPU Shutdown->Ini。当在Ini状态下监控到PCB板温低于110 ℃时,才会再次启动GPU。
本文只分析了控制器芯片级别的电压故障、通信故障和温度故障的响应策略。实际软件应用中还有诸如摄像头故障、显示器故障、雷达故障等其他类型故障。由于这些故障和外部选用模组、雷达强相关,本文不做阐述。但本文提出的生命周期管理方案中已留有故障响应和软件请求的对应接口,故可根据实际需求做对应的配置。
4 生命周期管理的软件架构实现
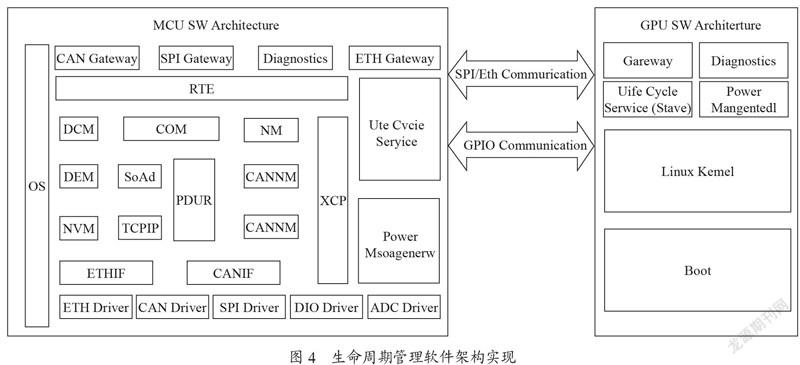
生命周期管理的主要逻辑在MCU中实现,所以MCU会作为主节点部署主体逻辑,GPU会作为从节点部署GPU端的生命周期管理。整个域控制器的静态软件架构如图4所示。
图中左侧为MCU上软件架构。MCU上整体部署Autosar软件架构,生命周期管理模块(上方标红)在其中作为复杂驱动,可通过RTE与上层APP交互,实现与通信信号和诊断结果的交互,从而实现上层应用软件控制生命周期跳转以及上电下电的需求。生命周期管理模块下层为电源管理模块(下方标红),负责整个控制器的上下电。在生命周期进入特定状态,(如GPUShutdown 或EcuShutdown)时,调用电源管理模块接口,实现上下电。该软件架构中Autosar其他服务与生命周期管理并行运行,可实现生命周期管理进入Ini状态即可正常运行通信和诊断功能。
图中右侧为GPU端Linux操作系统的部署。生命周期管理(左侧标红)在其中为APP,当Kernel启动成功后运行,主要负责监控Fullrun状态下的各种异常状态。如需要执行状态机的跳转,通过Gateway模块通知MCU,并同时通知Linux中电源模块(右侧标红)实现GPU外设的下电处理。
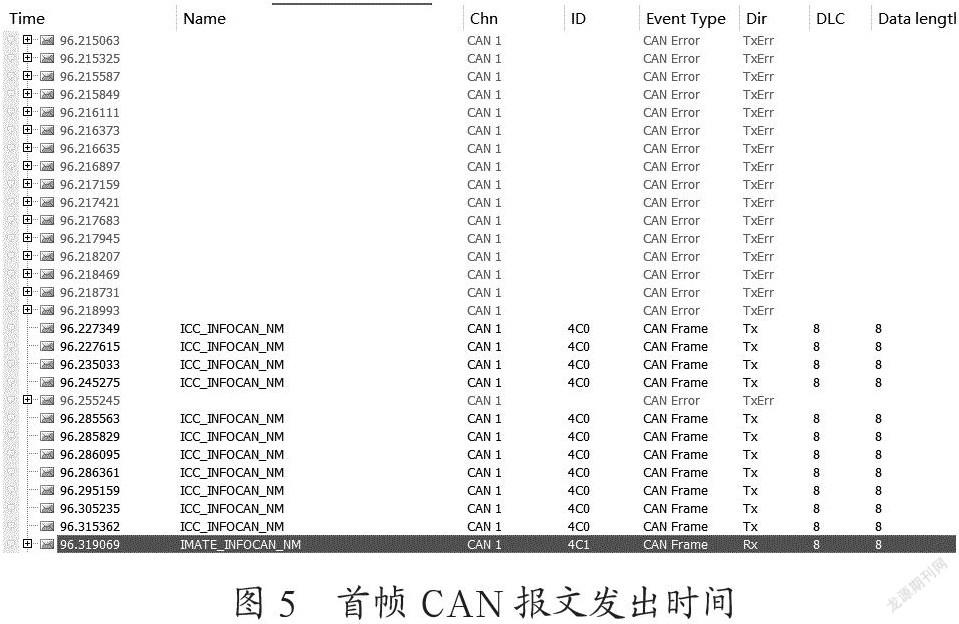
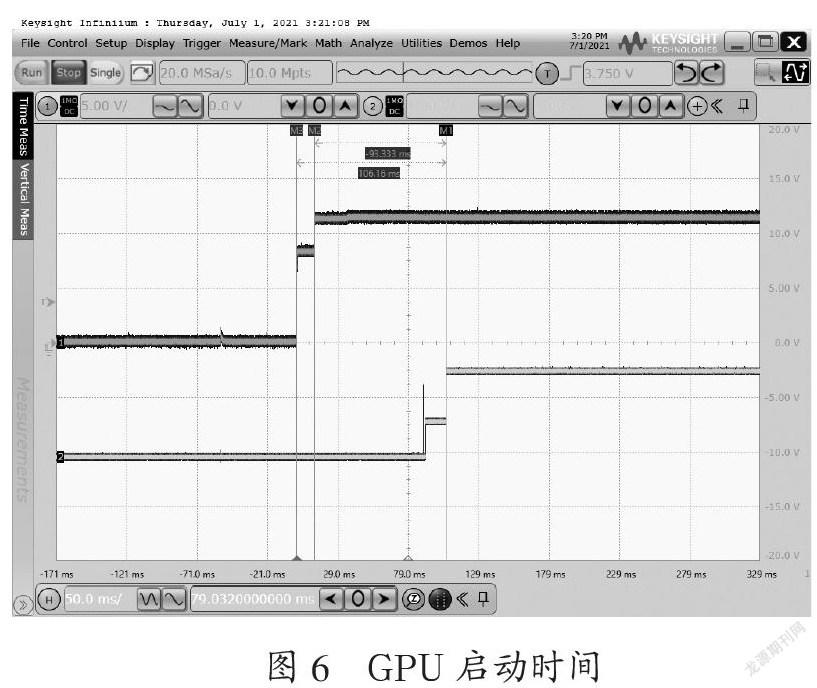
这种软件架构在实验室中已完成部署和测试,可实现110 ms内首个CAN报文的发出,110 ms内开始启动GPU,如图5、图6所示。从开始唤醒到Linux开始正常运行,进入Fullrun时间在7 s内(唤醒帧在96.215 s 发出,首帧报文在96.319 s 发出,间隔104 ms)。
5 结 论
域控制器的生命周期管理是MCU+GPU系统架构的重要技术之一。本文提出了一种兼容GPULinux操作系统的生命周期管理的解决方案,并细化了这种解决方案下的故障响应和软件架构部署,最终给出了在实验室环境下的启动时间。这种解决方案适用于所有MCU+单一GPU的系统架构,并能满足量产项目对稳定性和鲁棒性的要求。但该方案暂不支持多GPU芯片的系统架构。后续将对多GPU的系统架构继续分析讨论,使生命周期管理能兼容多GPU的系统设计。
参考文献:
[1] AUTOSAR. Specification of ECU State Manager [EB/OL].(2021-02-08).https://www.autosar.org/fileadmin/user_upload/standards/classic/4-3/AUTOSAR_SWS_ECUStateManager.pdf.
[2] AUTOSAR. Specification of Operating System. [EB/OL].(2021-02-08).https://www.autosar.org/fileadmin/user_upload/standards/classic/4-3/AUTOSAR_SWS_OS.pdf.
[3] 劉佳熙,丁锋.面向未来汽车电子电气架构的域控制器平台 [J].中国集成电路,2019,28(9):82-87.
[4] ZHOU X,WANG K,ZHU L,et al. Development of Vehicle Domain Controller Based on Ethernet. [J/OL].Journal of Physics:Conference Series 2020,(1802):(2020-04-14).https://iopscience.iop.org/article/10.1088/1742-6596/1802/2/022065.
[5] 刘佳熙,施思明,徐振敏,等.面向服务架构汽车软件开发方法和实践 [J].中国集成电路,2021,30(Z1):82-88.
作者简介:柳灏(1989—),男,汉族,江苏南京人,资深工程师,硕士研究生,研究方向:新能源电动汽车、汽车智能驾驶。
3542500338261
