基于微服务的智慧门店视觉感知系统设计与实现
2021-03-12刘瑞康胡君红陈绪君
刘瑞康,胡君红,徐 甜,陈绪君
(华中师范大学物理科学与技术学院,湖北武汉 430079)
0 引言
随着互联网信息时代的到来,以满足消费者需求和提升效率为核心的智慧门店[1-5]逐渐兴起。在线下场景,如何充分利用视频图像信息分析顾客兴趣点,指导商品企划,成为商家越来越关注的问题。目前,计算机视觉技术飞速发展,以目标检测[6-7]技术为核心的视觉感知系统能够从监控视频[8]信息中检测到顾客位置,为商家制定后续服务策略提供帮助。然而,商场、超市等复杂场景下的视频监控质量可能受到采光因素影响,从而对后续检测造成干扰,且对目标检测算法的检测精度要求较高。
针对以上问题,本文设计并实现了应用于智慧门店的视觉感知系统。系统采用微服务架构,确保了模块间的独立性与系统整体的可扩展性,方便系统根据功能需求作出调整;使用暗光增强技术对低照度图像进行预处理,以提升图像质量;改进YOLOv3 算法[9],并在自制商场超市场景下的人群数据集上进行训练,以保证系统在智慧门店场景下具有良好的检测表现。通过实验验证,改进后的检测算法较原YOLOv3 算法的精确率提升了2%,召回率提升了3%。系统整体使用Flask 框架[10]实现,为商家完善服务提供了便利的平台。
1 系统需求分析
目前,智慧门店逐渐兴起,商家希望通过摄像头等图像采集设备获取顾客图像信息,以从中分析、挖掘出有价值的信息。因此,如何有效地从门店顾客视频图像中获取关键信息成为商家的迫切需求。
1.1 功能需求
本文根据具体应用场景对系统功能需求进行分析,对系统各个功能需求进行介绍。
(1)用户管理功能。系统使用对象为商户,用户管理模块需要实现账户注册、身份验证、系统登录、修改资料等功能。
(2)图像采集功能。图像采集模块需要实现视频录制与数据导出功能,帮助商家按照需要选择不同区域的图像采集设备,采集关注区域的视频图像信息。
(3)图像预处理功能。考虑到商场超市场景的复杂性,不同区域采光条件不同,光照不足会导致采集的视频图像画面较暗,图像中关键信息难以辨识。因此,需要对低照度图像进行暗光增强,以提升图像质量,进而提高后续检测与识别的准确性,并调整图像格式,使之符合需求。
(4)目标检测功能。目标检测功能是本系统的核心功能,其中如何选择合适的检测算法尤为关键。本系统应用于智慧门店场景,该场景环境复杂,需要检测算法能够较快地检测出目标,同时保证较高的检测准确率,之后将检测结果以可视化形式呈现,方便商家掌握信息。
1.2 性能需求
系统在满足功能需求的同时,还需要满足性能需求。根据系统实际应用场景,系统需要满足以下4 个性能需求:
(1)精确率。系统检测模块需要对视频图像进行精准地检测,精确率是评价检测性能的重要标准。考虑到应用场景较为复杂,精确率应该在0.8 以上。
(2)实时性。在检测过程中,由于商场、超市等复杂场景下的人群流动性大,因此系统检测模块需要有较快的检测速度,以满足系统对检测实时性的需求。
(3)独立性。要求系统各个模块能够独立实现各自的功能,便于系统后续根据需求进行功能扩展。
本研究单矿物浮选试验在XFGCII型浮选机(吉林探矿机械厂)中按图2流程进行,主要药剂见表2。除温度试验外,其他试验都保持在25 ℃的条件下进行。浮选完成后将泡沫产品与槽内产品分别进行过滤、烘干、称重,并计算单矿物的回收率。
(4)兼容性。系统用户通过Web 浏览器对系统进行操作,因此需要系统能够在不同浏览器上正常运行。
2 系统设计
2.1 系统架构设计
为确保系统功能模块的独立性,以及系统整体的可扩展性,使将来系统能够根据需要对模块进行扩展,系统使用微服务架构进行设计。系统微服务架构如图1 所示,分为用户端与服务端两部分,实现系统前后端分离。其中,Web 服务端是用户操作的UI 页面。服务端根据系统功能划分为用户管理、图像采集、图像预处理、目标检测4 个微服务模块,并将各个模块进行封装,以接口形式提供功能服务。数据库层存储了各模块相关数据以及用户信息、设备信息、数据信息等。
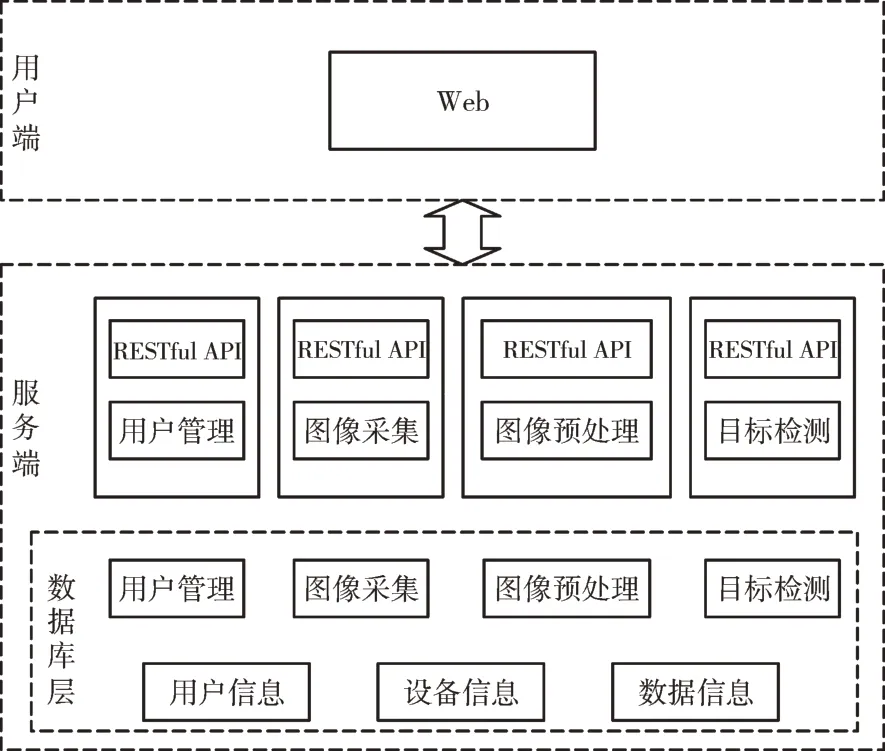
Fig.1 System architecture of microservice图1 系统微服务架构
2.2 系统功能设计
根据需求分析,系统按照功能分为4 部分,分别为用户管理模块、图像采集模块、图像预处理模块、目标检测模块。如图2 所示,其中用户管理模块功能包括用户注册、身份验证、信息修改等;图像采集模块功能包括视频录制、数据导出等;图像预处理模块功能包括暗光增强、数据归一化等;目标检测模块功能包括方法选择、目标检测、数据可视化等。
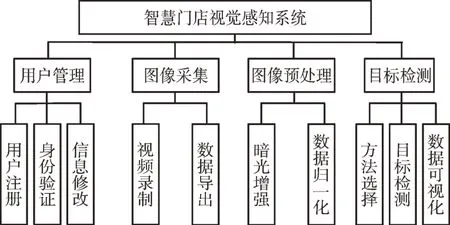
Fig.2 Design of system function module图2 系统功能模块设计
2.3 微服务接口设计
为了保证各个微服务模块的独立性,对模块与类进行封装,使用Flask-RESTful 对API 进行设计,后端通过接口将数据传递给前端。数据主要以JSON 格式进行传输,少部分通过URL 参数进行传递。为了保证代码的整洁性与易读性,使用驼峰命名法对接口进行命名。
3 算法设计
3.1 暗光增强算法
受采光条件影响,低照度图像整体效果较暗,严重影响了图像信息的辨识度,而增强图像的像素亮度能够提升图像整体质量[11]。在RGB 空间中,RGB 三分量既包含颜色信息,又包含亮度信息,如果只是单纯地将灰度图像增强方法应用于彩色图像增强中,在提升亮度的同时会改变图像颜色信息,无法达到暗光增强的要求[12]。根据RGB颜色模型特点,如果两个像素点[R1,G1,B1]与[R2,G2,B2]满足=λ的关系,则该两点可能亮度信息不同,但拥有相同的颜色信息,其中λ表示亮度增益。由此可见,想要在对图像进行亮度增强的同时不改变颜色信息,关键在于确定亮度增益λ。确定亮度增益λ需要提取图像中的亮度分量[13],HSV 颜色空间实现了颜色与亮度的分离。图像灰度化定义公式如下:

式(1)中,V(x,y) 表示像素点(x,y) 在HSV 颜色空间中的亮度信息,R(x,y)、G(x,y)、B(x,y) 表示像素点(x,y) 在RGB 颜色空间中分别对应的R、G、B数值信息。
通过对原始图像HSV 空间亮度V1进行非线性变换,获得变换后HSV 空间的亮度V2,即可获得亮度增益λ。亮度增益λ计算公式如下:

获取亮度增益λ后,通过更改图像像素的RGB 值,达到增强图像亮度而不引起色彩失真的目的。RGB 变换如下:

式(3)中,λ表示亮度增益,R1、G1、B1分别为原始图像的RGB 值,R2、G2、B2分别为处理后图像的RGB 值。
当使用亮度增益对图像RGB 值进行变换时,会导致较高的RBG 值在变换后超出合理的灰度级范围[14]。由于幂函数变换方法在极低灰度区变换幅度较大,而从中灰度区到高灰度区的变换幅度较小,根据这一特点,使用幂函数对图像进行亮度增强不会因亮度增益过大而引起色彩失真。变换方法如下:

式(4)中,V2表示变换后图像的HSV 空间亮度,V1表示原始图像的HSV 空间亮度,p是一个参数,可以进行调整。
由式(4)可知,V2单调递增,当参数p取值为128、V1取最大灰度级255 时,V2值最多只能达到255,经过变换不会超出灰度级范围。图像RGB 的同比增强也均在灰度级范围内,不会引起Gamut 问题。
3.2 目标检测算法
本文设计的视觉感知系统应用于智慧门店场景,使用的检测算法需要有较高的检测精度。针对YOLOv3 算法[9,15]在小目标检测过程中存在漏检的情况,本文改进YOLOv3 网络,利用网络4 倍降采样输出特征图进行目标检测,以获取更多小目标的位置信息。对原网络输出的8倍降采样特征图进行2 倍上采样,与Darknet-53 网络的第二块残差块输出的4 倍降采样特征图进行融合,建立输出为4 倍降采样的特征融合检测层,以提高网络对小目标的检测能力。与此同时,增加2 个残差单元,以获得更多的小目标位置信息。
在原YOLOv3 网络中,使用3 个尺度对VOC 数据集进行预测,尺度1 对应(116,90)、(156,198)、(373,326)预测框,尺度2 对应(30,61)、(62,45)、(59,119)预测框,尺度3对应(10,13)、(16,30)、(33,23)预测框。为提高对小目标的检测精度,用4 倍降采样特征融合检测层代替以上3 个尺度的输出检测,将原网络中的6 个DBL 单元变成2 个DBL 单元加上2 个残差网络单元[16-17],如图3 所示。

Fig.3 Improved network output structure图3 改进的网络输出结构
改进的网络结构将第二个残差块4 倍降采样输出的特征图与经过8 倍降采样后又进行2 倍上采样的特征图进行拼接,实现输出为4 倍降采样的特征融合检测层,以提高网络对小目标的检测性能。
为使模型在商场超市场景下有更好的检测表现,收集了时长共计115h 的商场超市场景人群视频,这些视频包含商场不同场景、不同光照、不同人群密度等情况的人群信息。借助Opencv 工具,按帧读取图像信息并生成10 万张图片,之后从中挑选2 万张图片。首先使用本文介绍的暗光增强技术对受到采光影响的图片进行处理,然后对图片进行归一化操作,根据网络输入要求,将图片裁剪、缩放成416×416 尺寸,接着使用labelimg 标注工具对图片进行标注,最后将制作好的数据转换为VOC 数据集格式,并对模型进行训练与测试。
目标检测模型训练环境为:操作系统为Ubuntu 14.04.5 LTS;GPU 为NVIDIA GTX 1080Ti;CPU 为Intel Core i7-7700K;深度学习框架为tensorflow。
本文从20 000 份标注好的数据中选出18 000 份作为训练集,剩余2 000 份作为测试集。将训练集平均分为10个子集,每个子集包含1 800 份标注好的数据,以10 折交叉验证[18]方式进行模型训练。
将Batch size 设置为100,为加快模型收敛,避免出现过拟合,将初始学习率设置为0.000 1,权值衰减系数设置为0.000 5,冲量常数设置为0.9。当训练迭代次数为20 000次时,将学习率调整至0.000 01;当迭代次数为30 000 次时,将学习率调低至0.000 001。大约经过40 000 次迭代,损失值下降到0.2 左右,Avg IOU 稳定在0.85 左右。
文献[19]介绍了二分类评价方法,其采用精确率(pre⁃cision)与召回率(recall)指标,在二分类问题中,通常将关注的类作为正例,其它类作为负例。分类器预测时可能出现的4 种情况[20]如表1 所示。

Table 1 Four kinds of forecast situation of binary表1 二分类4 种预测情况
精确率(precision)是指在算法给出的所有正例中,预测正确的正例占所有预测为正例的比例,精确率计算公式如下:

式(5)中,precision 表示精确率;TP 表示样本实际是正例,预测结果也是正例的数量;FP 表示样本实际是负例,预测结果却是正例的数量;TP+FP 表示预测为正例的总数。
召回率(recall)是指算法检测出的正例占所有真实正例的比例,召回率计算公式如下:
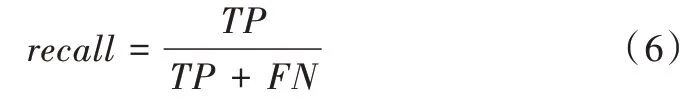
式(6)中,recall 表示召回率;TP 表示样本实际是正例,预测结果也是正例的数量;FN 表示样本实际是正例,预测结果却是负例的数量;TP+FN 表示实际为正例的样本总数。
原YOLOv3 网络与本文改进网络在一份共包含1 035个目标数的测试集上的检测结果如表2 所示。其中,XTP表示正确检测出的目标数,XFP表示错误检测出的目标数,XFN表示未检测出的目标数。通过测试结果可以验证,本文提出的改进网络在商场超市场景下有更好的检测表现。

Table 2 Data comparison between YOLOv3 and the network in this paper表2 原YOLOv3 网络与本文网络部分数据对比
4 系统实现
本文设计的视觉感知系统采用Flask 框架进行后台开发,系统使用流程如图4 所示。首先,新用户需要使用邮箱注册账号,之后进行身份验证并登录系统,可进入信息修改页面对个人信息进行修改。然后,用户可进入图像采集页面,选择图像采集设备对视频进行采集,并根据需要保存采集的视频信息。接下来,进入视觉感知页面,可选择图像设备获取视频图像信息,并根据场景采光条件选择是否对图像进行暗光增强。如果需要进行暗光增强,将页面中暗光增强的勾选框选中,系统自动对图像进行暗光增强处理。系统使用改进的YOLOv3 算法对视频图像信息进行目标检测,根据检测结果生成热力图,并对检测结果进行直观展示。
页面展示效果如图5 所示。系统视觉感知页面左边显示带有当前人数与预测框信息的图像,右边显示根据检测结果绘制的热力图,商家可直观获取当前人数信息与场景热点区域。
5 结语
本文设计的视觉感知系统旨在解决智慧门店场景下人群检测、人群计数等问题。系统按照功能划分为用户管理、图像采集、图像预处理、目标检测4 个微服务模块,各模块具有独立性,系统整体具有可扩展性。系统使用暗光增强技术对图像亮度进行增强,以提升图像质量;改进YO⁃LOv3 网络,并在自制商场超市场景下的人群数据集上进行训练,以提高视觉感知系统在智慧门店场景下的检测表现。通过实验验证,在自制的商场超市场景下的人群数据集上的测试结果表明,改进后的检测算法较原YOLOv3 算法的精确率提升了2%,召回率提升了3%,在商场超市等场景下的检测表现良好。系统根据检测结果统计当前人数并生成热力图,可直观展示检测结果,便于商家获知场景当前人数以及场景热点区域,从而进一步提升管理服务水平,让门店变得更加智慧。

Fig.4 System flow图4 系统流程
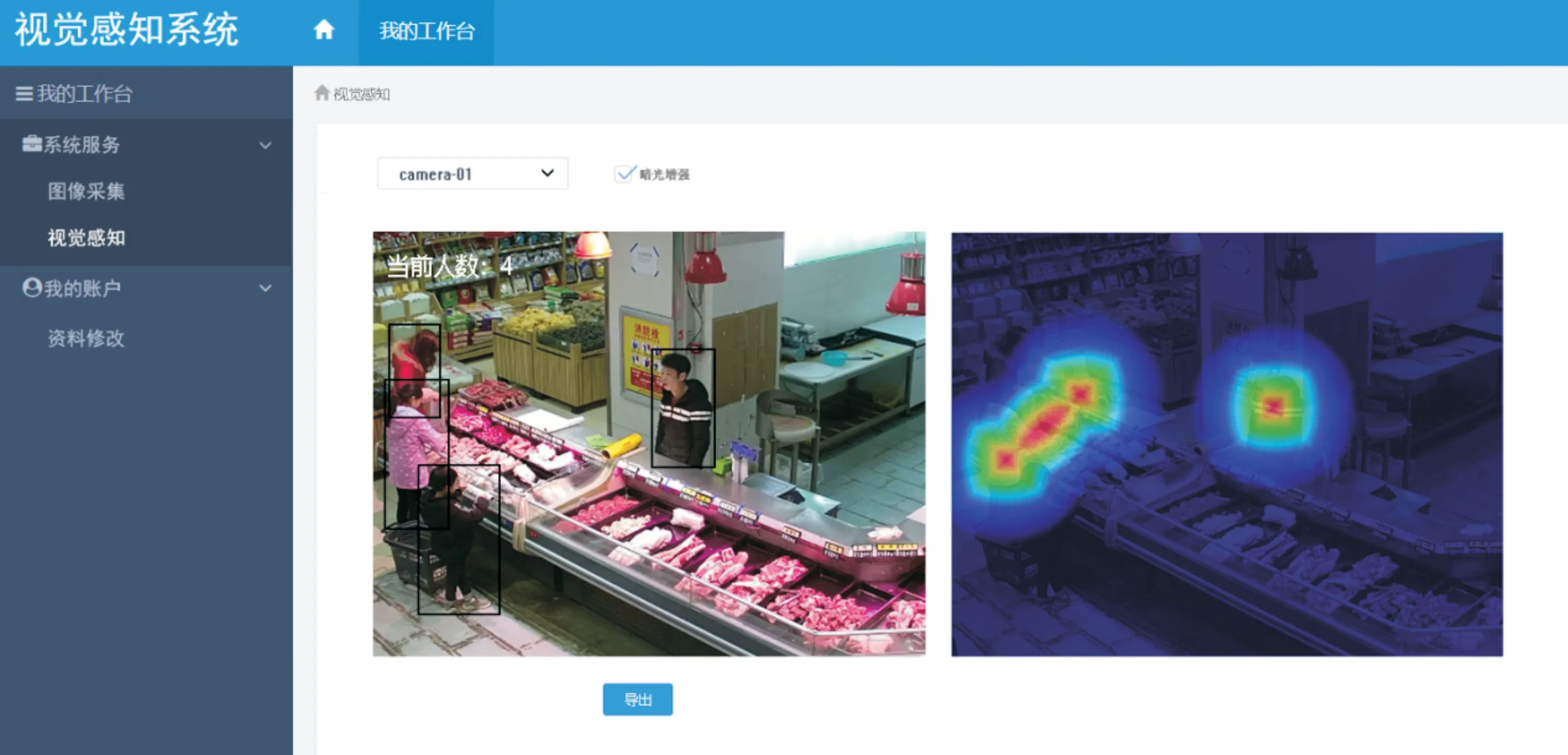
Fig.5 Page of visual perception system图5 视觉感知系统页面
