人工智能技术在移动终端自动化测试中的应用
2021-03-12刘维维
刘维维
(中兴通讯股份有限公司终端事业部,上海 200120)
0 引言
计算机学科一个重要分支就是人工智能,人工智能技术是目前最热门的科技话题之一,在很多方面都有相关应用,如人脸识别手机解锁、语音文字相互转换、智能家居、无人驾驶等等。
在移动终端测试领域,传统测试模式为手工测试,自动化测试是通过机器如机械手工具,提供大量的输入和输出数据训练AI,最终由AI 根据特定需求自动生成测试用例并执行测试,并对测试结果进行分析。自动化测试大大减少了人工测试工作量,大幅提高了工作效率。AI 训练主要是界面自动化执行与数据采集,关键是机器识别UI 的准确度与效率问题。结合人工智能的图像识别与AI 训练技术能更好地监控与记录测试过程中的数据、表格及图像,快速分析手机中存在的性能问题及程序缺陷。因此,人工智能在自动化测试方面应用广泛[1]。
基于人工智能技术建立自动化测试模型,可使自动化测试更高效、识别更准确。
1 移动自动化测试现状
移动自动化测试技术是产品研发过程中必不可少的环节,随着敏捷开发应用越来越广,自动化测试技术在整个研发周期以及各个迭代过程中的比重也越来越大。
移动终端测试类型包括软件测试、硬件测试、结构测试等,本文主要针对软件测试。软件系统测试又分为功能测试、稳定性测试、兼容性测试、压力测试、启动时间测试、平滑性测试、跑分测试等。
软件系统测试一般是用户对各种测试工具的操作过程,如功能测试是在操作系统界面首先检查各类控件信息,然后通过系统间的交互查看控件状态等;稳定性测试,如monkey,则是测试用户在各种场景点击操作对系统的影响,如是否产生黑屏、闪退、无响应、耗电等结果;兼容性测试则是在系统安装指定软件后,通过点击卸载界面进行特定的卸载操作;跑分测试则是安装第三方软件对移动终端进行测评,需要用户安装、启动、抓取界面数据等。
任何自动化测试实现原理均包括以下3 个过程:①用户行为模拟的测试执行过程;②测试异常指标抓取监控过程;③移动终端界面结果数据收集过程。
由于移动终端测试通常是大数据量的反复、长期测试,人工审查难免出现错误,自动化测试不断面临新的挑战,如自动化测试脚本维护时间过长、控件元素定位不准确、上手使用难度较大等等,同时面临大量的数据处理与分析工作。有效解决这些问题,确保高质量的最终产品是很多企业提高软件质量的主要工作[2-3]。
2 Python 语言发展现状
随着人工智能、大数据的快速发展,移动自动化也得到发展,Python 语言成为主流的自动化编程语言。
Python 是一门免费、开源、简单易用易学的跨平台高级动态编程语言,其语法简单,代码可读性强,非常适合初学者。Python 语言科学计算、数据处理、数据分析等功能适应移动终端自动化测试发展趋势。
Python 在移动自动化测试方面已有很多应用。由于Python 带有os 库,可与手机连接,很多公司在此平台上进行终端自动化测试脚本编写及开发自动化测试框架,如airtest。
Python 语言目前是最受欢迎的自动化编程语言,丰富的第三方库既避免了重复开发,又增加了语言张力,目前98%的人工智能开发用的是Python 语言编程。
人工智能编程思路是:在Python 的标准库(pdb、urllib、httplib、hash、os、threading)基础上,采用第三方Python 开源库requests、numpy、matplotlib,opencv 等实现数据分析功能。本文尝试从人工智能编程思路出发,基于Python 语言阐述其在自动化测试用户模拟过程中应用[4]。
3 人工智能应用
3.1 图像文字识别在自动化测试方面应用
在产品研发测试过程中,各类产品纷繁交错,版本迭代也很频繁,传统的手机UI 自动化测试方法是通过dump UI 采取自动化测试脚本分析定位到界面上的控件元素,然后根据元素属性取出具体业务数值,最后获得界面坐标以执行自动化测试过程。
(1)通过坐标点击方法实现用户模拟分析如下:由于版本迭代,系统交错存在很多差异化需求,仅通过定位坐标往往会出现自动化脚本更新频繁导致效率较差问题。此类测试包含功能测试、稳定性测试等。
(2)UI 元素属性识别方法:是一种传统的测试方法,为UIdump 界面信息通过传统的空间元素属性识别控件。但在游戏、Octane、BasemarkOS、BaseMarkX 等方面,传统的空间元素属性识别方法往往不适用。
(3)图像匹配识别方法:Airtest 的测试框架是用图像匹配度进行用户模拟操作,这个方法有一定的局限性,仅仅能操控手机,但是无法提取出图像上的文字供数据采集。
高效准确地进行鉴权测试需要图像文字识别技术支持,采用图像文字识别技术可先对期望结果页面进行截屏,从而对测试结果进行分析。
3.2 图像文字识别传统方式
传统的图像识别方法通过图像匹配算法进行识别,采用BSD 发行的OpenCV 计算机视觉库,其提供Python、Ru⁃by、MATLAB 等语言接口,图片检测、图片识别和图片数据功能均由OpenCV 提供相应的接口实现。
基于OpenCV 和Python 的用户行为模拟测试模型核心是利用OpenCV 和Python 识别图片。该测试模型主要由图像信息采集、文字区域检测、特征值提取和数据处理等模块完成。文字区域检测采用mser 算法,特征值提取通过tesseract ocr 识别文字将待测图片进行处理得到待验证数据,数据处理模块将该数据与校验库中的值进行对比,找到最相近的值作为识别的最终值,但该模型准确度不高[5]。
3.3 卷积神经网络图像识别方式
随着人工智能的发展,深度神经网络成为主流的图像识别技术,其中尤以卷积神经网络最为出名。卷积神经网络是以自动化特征提取的机器学习模型。本文基于卷积神经网络的电子信息图像文字处理技术构建卷积网络结构,研发算法流程,挖掘卷积神经网络的文字识别优势[6-7]。
卷积神经网络(Convolutional Neural Network,CNN)是一种前馈型神经网络,在大型图像处理方面有出色表现,已广泛应用于图像文字识别方面。因此,本文采用卷积神经网络(CNN)实现文字图像识别功能。
采用Python 编写CNN 文字图像识别功能可实现更少的代码行。目前卷积神经网络流行框架是Caffe、Torch、Tensorflow,适用于机器学习和深度学习等,如Tensorflow、Keras、Caffe、Theano 等在Python 中都可进行调用,而且由于Python 语言简单性,它们在Python 中使用也更加容易。
Keras 是一个简约、高度模块化的神经网络库,应用模块(keras.applications)提供带有预训练权值的深度学习模型,这些模型可用来进行预测、特征提取和微调[8]。
4 系统主要功能实现
4.1 卷积神经网络框架结构
卷积神经网络层级结构如图1 所示。
数据输入层(Input layer):该层主要对原始图像数据进行预处理,包括去均值、归一化、白化等。
卷积计算层(CONV layer):局部关联与窗口滑动。
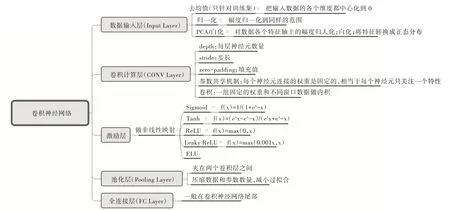
Fig.1 Hierarchical structure of convolutional neural network图1 卷积神经网络层级结构
ReLU 激励层(ReLU layer):将卷积层输出结果做非线性映射。
池化层(Pooling layer):用于压缩数据和参数的量,减小过拟合。
全连接层(Full Connection layer):两层之间所有神经元都有权重连接,通常全连接层在卷积神经网络尾部。
Image 为原始图片,F 为滤波器(filter,也称为kernel)。用这个filter 对图片进行处理,覆盖一块跟filter 一样大的区域之后将对应元素相乘然后求和。计算一个区域之后向其它区域挪动,继续计算直到把原图片的每一个角落都覆盖为止,这个过程就是“卷积”。
通过设计特定的filter 与图片做卷积,就可识别出图片中的某些特征,比如边界。检测竖直边界与水平边界的区别只用把对应的filter 旋转90°即可。对于其它特征,理论上只要经过精细设计就可设计出合适的filter。CNN 原理就是设置每个filter 中的参数。
4.2 基于Keras 实现图像文字识别流程
(1)准备好需要用的库。准备库Keras,PIL,numpy,opencv,tensorflow,在Python3.5 环境下可通过pip install 进行安装的库如表1 所示。

Table 1 Libraries installed through pip install表1 通过pip install 进行安装的库
(2)Python 编程环境中,导入PIL 图像处理标准库,包括PIL 引入Keras 的卷积模块,如Dropout、Conv2D 和Max⁃Pooling2D。
import keras
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense,Dropout,Flatten,Conv2D,MaxPooling2D
from keras.callbacks import EarlyStopping,ModelCheckpoint
from PIL import Image
import numpy as np
(3)数据预处理。在将数据输入神经网络之前需要将数据格式化为经过预处理的浮点数张量。预处理流程如下:读取图像文件➝解码维RGB 像素网格➝转换为浮点张数➝像素缩放为0-1 区间,如图2 所示。

Fig.2 Data preprocessing图2 数据预处理
在TensorFlow API Keras 中有个比较好用的图像处理类ImageDataGenerator,它可以将本地图像文件自动转换为处理好的张量。
下面通过代码解释如何利用Keras 对数据预处理,完整代码如下:

(4)通过Python 代码设计卷积神经网络。
①搭建卷积神经网络;采用Keras 的序列模型(Se⁃quential 类建立神经网络模型)
model=Sequential();
②添加一层卷积层,构造64 个过滤器,每个过滤器的范围是3×3×1,过滤器挪动步长为1,并用relu 进行非线性变换;
model.add(Conv2D(32,kernel_size=(3,),activation=‘relu’,input_shape=input_shape))
model.add(Conv2D(64,(3,3),strides=(1,1),activa⁃tion=‘relu’))
③添加一层MaxPooling,在2×2 格子中取最大值;
model.add(MaxPooling2D(pool_size=(2,2)))
④设立Dropout 层,将Dropout 的概率设为0.5,这个值可以自行设置;
model.add(Dropout(0.25))
⑤把当前层节点铺平;
model.add(Flatten())
⑥构造全连接神经网络层;
model.add(Dense(128,activation=‘relu’))
⑦最后定义损失函数,分类问题的损失函数选择采用交叉熵(Cross En-tropy);放入批量样本进行训练;
model.compile(loss=keras.losses.binary_crossentropy,op⁃timizer=keras.optimizers.Adadelta(), metrics=[‘ac⁃curacy’])
⑧在测试集上评价模型的准确度。
test_loss=model.evaluate_generator(test_generator)
print(test_loss)
4.3 基于Keras 实现图像文字识别模型应用
自动化测试过程中遇到的自定义控件、图片、悬浮界面等无法获得文字信息的场景均可通过文字进行识别与点击操作,同时测试结果中保存的图片也可用文字识别收集结果或进行log 整理。
在用户模拟测试方面,通过图像获取封装文字识别功能,如果识别到截图控件上的文本则对其进行点击操作。
通过手机获取图像,调用文字识别接口识别出文字,然后通过Python 对结果进行解析。
5 结语
人工智能技术与自动化测试技术结合可节省大量的人工成本,使移动终端自动化测试得到较大发展,在工业或商务领域展现出价值[9-10]。
首先,软件测试变得更简单高效。机器学习擅长通过数据训练完成新的数据处理,测试人员无需大量手工编写自动化测试用例执行测试,只需利用AI 自动创建测试用例并执行。测试人员主要工作不再是执行测试,甚至也不是设计自动化测试用例,而是提供输入输出数据来训练AI,最终让AI 自动生成测试用例并执行。对于某些通用测试,只需一个被验证过的模型,甚至连数据也无需提供。
其次,人工智能测试工具可以发现更多的软件缺陷。一边测试一边时刻不停地新增数据输入,测试能力会越来越好,因而能够发现更多的缺陷。与此同时,对于迭代频繁的软件开发而言,当一个软件缺陷发现后,测试人员常常需要确定这个缺陷是什么时候引入的,这往往需要耗费大量的时间和精力,而人工智能测试工具能够持续跟踪软件开发过程,找出其中缺陷被引入的时间,从而为开发人员提供有效信息。
最后,基于AI 的测试会让测试人员感到困惑,他们可能怀疑AI 测试有效性。要消除这种不信任感,测试人员需掌握数据科学技能,还需了解一些机器学习原理。
对于软件测试来说,AI 是一个工具,一个很好的助手。而对于测试人员来说,需要拥抱变化,提升能力,这样才能更好地发挥AI 的作用。
