基于FPGA 的卷积神经网络并行加速器设计
2021-03-11陈斌岳张福海
王 婷,陈斌岳,张福海
(南开大学 电子信息与光学工程学院,天津300350)
0 引言
随着人工智能的快速发展,卷积神经网络越来越受到人们的关注。 由于它的高适应性和出色的识别能力,它已被广泛应用于分类和识别、目标检测、目标跟踪等领域[1]。 与传统算法相比,CNN 的计算复杂度要高得多,并且通用CPU 不再能够满足计算需求。 目前,主要解决方案是使用GPU 进行CNN 计算。 尽管GPU 在并行计算中具有自然优势,但在成本和功耗方面存在很大的缺点。卷积神经网络推理过程的实现占用空间大,计算能耗大[2],无法满足终端系统的CNN 计算要求。 FPGA 具有强大的并行处理功能,灵活的可配置功能以及超低功耗,使其成为CNN 实现平台的理想选择。 FPGA 的可重配置特性适合于变化的神经网络网络结构。 因此,许多研究人员已经研究了使用FPGA 实现CNN 加速的方法[3]。 本文参考了Google 提出的轻量级网络MobileNet 结构[4],并通过并行处理和流水线结构在FPGA 上设计了高速CNN 系统,并将其与CPU 和GPU 的实现进行了比较。
1 卷积神经网络加速器的设计研究
1.1 卷积神经网络的介绍
在深度学习领域中,卷积神经网络占有着非常重要的地位,它的图像识别准确率接近甚至高于人类的识别水平。卷积神经网络是同时具有层次结构性和局部连通性的人工神经网络[5]。 卷积神经网络的结构都是类似的,它们采用前向网络模型结构,节点使用神经元来实现分层连接。 并且,相邻层之间的节点是在局部区域内相连接,同一层中的一些神经元节点之间是共享连接权重的。 传统的卷积神经网络结构如图1 所示,卷积神经网络是直接将准备识别的原始图像作为输入,然后依次通过多个隐藏层连接到各层,得到识别结果。
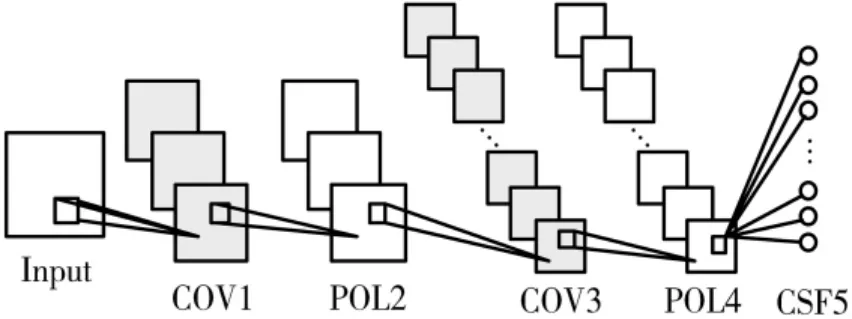
图1 卷积神经网络典型结构
1.2 CNN 的结构框架
MobileNet 是用于移动和嵌入式设备的有效模型。MobileNet 基于简化的架构,并使用深度可分离卷积来构建轻型深度神经网络。 为了进一步减少参数数量并促进在FPGA 上的部署,本文中使用了经过修改的CNN 网络结构,如图2 所示。 共有9 个卷积层和3 个池化层。

图2 卷积神经网络结构
1.3 卷积模块的设计
在卷积神经网络中,卷积运算占据了大部分计算量。传统的卷积分为两个步骤,即每个卷积核与每张特征图片进行按位乘法然后相加,此时的计算量为DF*DF*DK*DK*M*N,DF 是输入特征图的尺寸,DK 是卷积核的尺寸,M、N 分别是输入通道数和输出通道数。 本文采用的卷积方式不同于传统卷积,首先按照输入通道进行按位相乘,得到的结果通道数是没有变化的,接下来使用1*1 的卷积核再进行计算,以改变通道数。这种方法的计算量为DK*DK*M*DF*DF+1*1*M*N*DF*DF, 第1 项表示的是卷积核为3 时的计算量,第2 项表示卷积核为1 时的计算量,当DK=3 时,这种卷积方式比传统卷积减少了8 倍多的计算量,计算量的大幅度减少更有利于部署在资源有限的FPGA 端。 运算一个卷积层需要6 个循环嵌套来实现,循环顺序按照输出通道>输入通道>高度>宽度>卷积内核元素依次来排列计算。 对于每一卷积层来说,最外面的循环按照顺序遍历所有像素。上述循环结构的优化实现可以使用循环展开,循环拆分以及循环合并的指令方法,以设计加速器的IP 核。
1.4 资源占用优化
在训练了卷积神经网络之后,参数数据是一个32 位浮点数。 相关实验已经证实,精度降低一定程度对CNN识别精度的影响非常微弱[6]。 因此,本文设计中经过尝试不同量化位数后,在保证了精度的情况下选择输入的图像数据和权重数据使用9 位定点数。这种设计大大降低了FPGA 资源的利用率,并提高了网络运行速度。
卷积神经网络的计算成本主要有卷积层的大量乘法运算,在FPGA 中通常使用DSP 资源进行乘法运算,而通常不足的DSP 资源会成为卷积神经网络部署在FPGA 端的瓶颈。 BOOTH 算法实现的乘法器可有效地代替使用DSP 资源的传统乘法。 在Vivado HLS 中,数据都是以十六位二进制带符号的补码表示,原码乘法器的移位相加方法并不能直接推广用于补码的乘法运算中。普通的移位相加运算量比较大,乘数的每一位都产生部分积,乘数中值为1 的位数决定着累加的次数。 BOOTH算法的思想是将乘数近似为一个较大的整数值,利用这个整数值与被乘数相乘的结果减去这个整数值的补数与被乘数相乘的结果,对于具有连续的1 和0 的乘数来说产生的部分积较少。 具体运算步骤如下:
(1)被乘数X 与乘数Y 均为有符号数补码,运算结果也是补码。
(2)初始部分积为0,乘数Y 末尾添加附加位,初始值为0。
(3)判断乘数Y 后两位:若是01 则部分积加被乘数X 再右移一位, 若是10 则部分积减被乘数X 再右移一位,若是00 以及11 则只进行右移一位操作。
(4)累加n+1 次(n 表示数据数值位数),右移n 次。
2 基于FPGA 的加速器系统设计
2.1 卷积神经网络层融合策略
卷积层之间的运算有两种实现模式,分为层串行模式和层并行模式[7]。 本文在设计基于FPGA 的CNN 加速器时,选择了高度的灵活性和实现难度低的层串行模式。
在层串行模式中,FPGA 中的所有PE 单元都只用于实现卷积神经网络中一层的功能。并且通过重复调用存在的PE 单元,即使用时分复用PE 单元的策略来实现整个神经网络的运算[8]。 根据卷积神经网络单层操作的类似性原理,因此考虑由单层实现的层串行模式是确实可行的。 并且,在这种操作模式下,从DDR 中读取数据传输给PE 单元,PE 单元计算得到结果后将其写回到DDR,数据控制比较简单。 然而,对于中间数据的存储,层串行模式是通过AXI 总线协议将每一层的中间运算结果都再传输到外部存储器DDR 中,因此这种方法对IO 带宽的要求非常高[9]。
为了增大吞吐量并解决因带宽瓶颈而造成的传输时间过长,可以减少每一层的数据访问以及存储空间,以实现最大程度的数据和模块复用。 因此,本文将每三层合并为一组,然后将结果输出到DDR,从而将12 层CNN 结构减少为5 层,这将节省一部分传输步骤。 此操作将多层融合在一起而形成局部组合的方法,将从DRAM 接收的输入数据和操作的中间结果缓存都存储在片上BRAM 存储器中。
2.2 缓存结构
在带宽瓶颈的影响下,整个硬件平台的加速性能主要受到数据的访存效率限制。为了有效控制数据流的访存将使用缓冲技术,以增加带宽利用率[10]。 乒乓操作的缓冲方式是使用两个数据存储器,先将数据存储在第一个数据缓存中,当第一个数据缓存存满时,数据将转换到第二个数据缓存中存储,并在相同时刻读取第一个数据缓存中的数据。这种方式使得单通道的数据传输有效地变化为双通道的数据流传输, 数据流经过缓冲后,不断地传递到数据处理模块,这将使数据传输时间与数据运算时间重叠,以抵消大部分的时间[11]。
为了提高加速器系统的吞吐效率,在片内的输入缓存设置了图像输入缓存和权值输入缓存,以及结果输出缓存。 输入缓存的作用是从外部存储器DDR 中载入所需数据以及所需参数,输出缓存的作用是将存储运算结果输出至外部存储器DDR 中或者是再应用于计算单元中。缓存结构根据DMA 的方式来进行数据交互。本文的输入图像、权值以及输出的计算结果都采用如图3 所示的乒乓缓冲方式。两个数据缓冲模块通过二选一复用器相互配合使用,使数据可以没有停顿地依次加载到计算单元中,计算单元可以时时刻刻处于计算状态,以此充分利用了有限的计算资源。
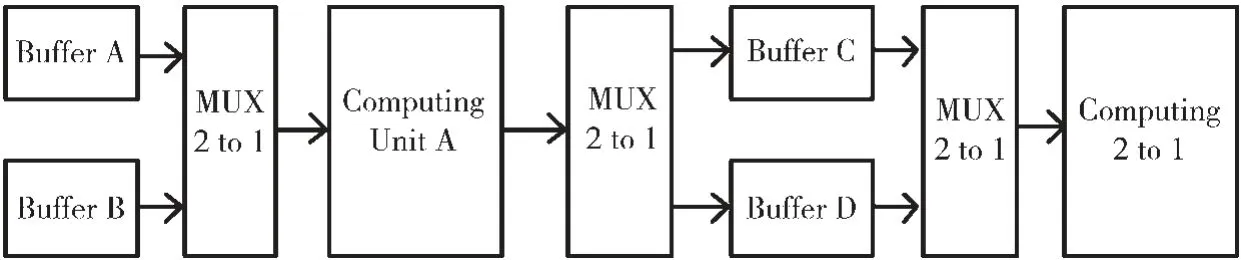
图3 乒乓缓存数据流
2.3 加速器整体架构
加速器的总体设计如图4 所示,由PS 和PL 组成。其中PS 主要负责图像数据预处理,权重数据预处理和特征定位的任务,而PL 负责整个CNN 计算部分。 加速器系统通过AXI 总线将CPU 和外部存储器DDR 中的卷积神经网络参数权重,以及要识别的输入图像像素数据传递给PL 部分。 当操作控制指令传递到PL 端时,PL 端启动系统主程序,并通过输入缓冲区的乒乓操作将参数和像素数据传输到运算操作逻辑单元。在完成整个卷积神经网络的计算后,输出数据通过AXI 总线通过输出缓冲区传输到DDR 存储器,并输出最终结果。
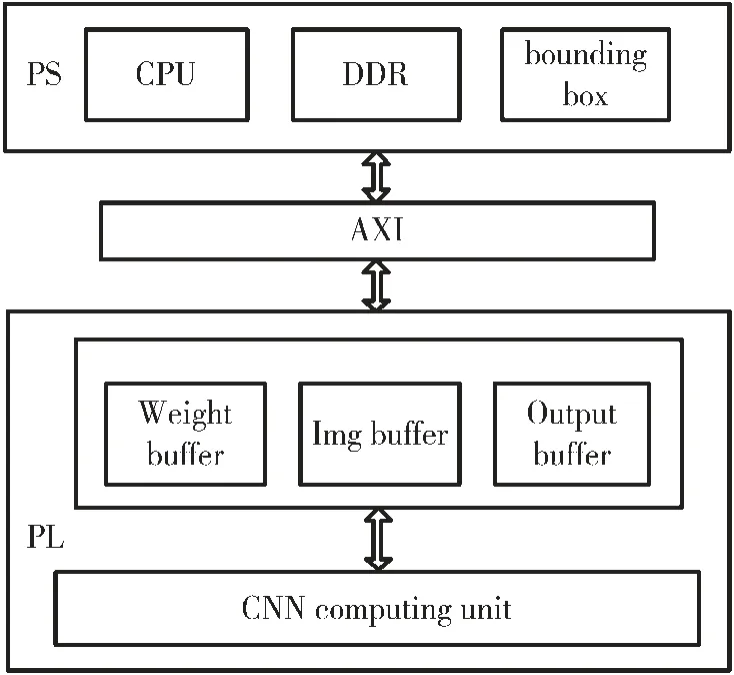
图4 加速器系统的整体设计
3 基于FPGA 的加速器系统设计
3.1 实验环境
实验采用Xilinx Zynq UltraScale+MPSoC ZU3EG A484 Development Board 对本文目标检测定位算法进行加速。片内由ARM 处理器与可重构FPGA 构成,片上资源主要 由432 个BRAM 和360 个DSP 组 成。 CPU 采 用Intel Core i5 2500K 处理器,GPU 是NVIDIA UeForce UTX 960。所用到的软件开发工具为赛灵思公司开发的Vivado 设计套件Vivado IDE 和Vivado HLS。
传统的FPGA 设计流程复杂且繁琐,为了简化开发流程,加速器系统采用高级综合方式来进行优化设计[12]。首先采用Vivado HLS 开发工具将CNN 计算过程的高级编程语言C++转化为硬件描述语言,再封装为Vivado 的IP 核输出。 Vivado HLS 工具具体的设计流程如图5 所示。 然后利用Vivado IDE 开发工具,导入封装好的CNN运算IP 核、主控单元zynq_ultra_ps、时钟单元以及AXI传输模块。 通过综合、设定约束、布局布线来实现完成整个加速器系统的设计。

图5 Vivado HLS 工具设计流程
3.2 实验环境
表1 列出了默认乘法的FPGA 的资源使用情况,表2 列出了部分乘法用BOOTH 算法代替的资源使用情况,由于开发板的LUT 资源使用率已经很高,因此部分乘法还是采用了DSP 资源。 BRAM 用于图像数据、网络权重及输出数据的缓存,DSP 以及LUT 用于卷积模块的乘加运算,该设计高效地利用了FPGA 的内部资源。
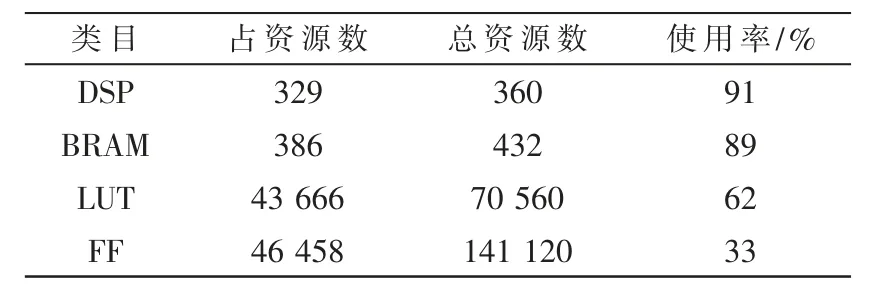
表1 默认乘法FPGA 内部资源的利用率
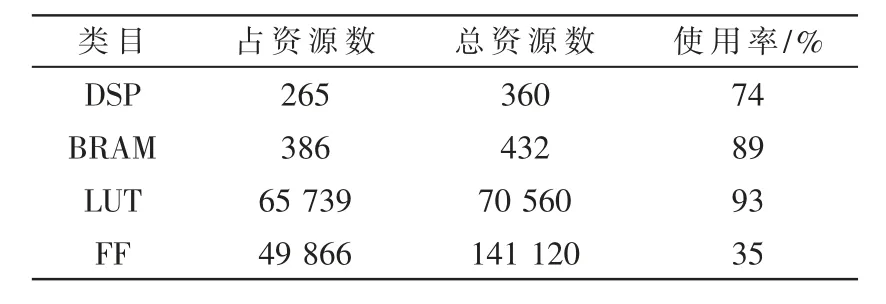
表2 BOOTH 乘法FPGA 内部资源的利用率
表3 中显示了将FPGA 中CNN 的性能与Intel Core i5 CPU 和NVIDIA UeForce UTX 960 UPU 进行比较的结果。 基于FPGA 优化设计的卷积神经网络处理单个图像所需的时间比CPU 要少得多,相当于GPU 的速度。 GPU功耗是本文设计的30 倍以上。
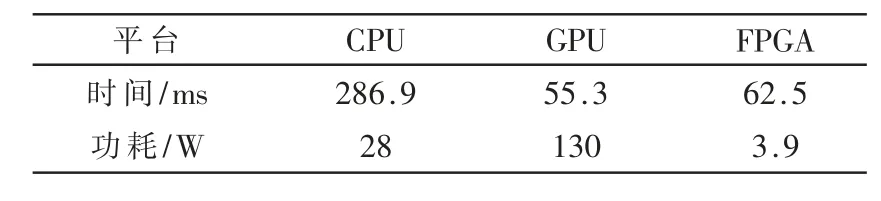
表3 不同硬件平台的性能评估
4 结论
本文提出了一种基于FPGA 有限资源的卷积神经网络加速器。利用BOOTH 算法实现乘法,有效降低了DSP 资源占用量。通过流水线结构和卷积运算的并行性提高了卷积运算的速度。网络加速器的内部结构在资源有限的开发板上实现12 层CNN 网络, 并将其与CPU 和GPU进行比较。 实验结果表明,嵌入式FPGA 的功耗和性能具有很大的优势,更适合于移动端的部署。
