基于深度卷积神经网络特征层融合的小尺度行人检测
2021-03-11张时雨寇墨林
卓 力, 张时雨, 寇墨林, 闫 璞, 张 辉
(北京工业大学 信息学部,北京 100124)
行人检测是计算机视觉领域的一个重要研究方向,可以广泛应用于智能监控、无人驾驶、机器人等多个领域。受到光照、视角、尺度、环境、遮挡、姿态变化等多种复杂因素的影响,行人检测面临着巨大的技术挑战。
近年来,人们开展了行人检测技术的研究。整个研究工作可以分为两个阶段:第一阶段是采用传统的手工特征+分类器框架进行行人检测,关键技术是行人特征提取和分类器。其中HOG(Histogram of Oriented Gradient)是针对行人特点设计的特征,它与SVM(Support Vector Machine)相结合是一种最具代表性的行人检测方法,在此基础上王谦等[1]又融入遗传算法(GA)和粒子群优化算法(PSO)进一步优化参数。但是手工特征主要依赖于设计者的先验知识或者经验,特征的表达和区分能力有限,因此这类方法的检测性能难以令人满意。 第二阶段是基于深度学习的行人检测,该方法把行人看作是一种特定的目标,对通用的目标检测方法进行改进,如R-CNN(Region-Based Convolutional Neural Network)系列[2-5]、YOLO(You Only Look Once)系列[6-8]和SSD(Single Shot Multi-Box Detector)系列[9-10]等,使之适用于行人目标的检测。基于深度学习的目标检测方法是在大数据背景下产生的方法,该方法通过模仿人类大脑的多层抽象机制实现对目标的抽象表达和解释,将特征学习和分类器整合在一个框架下,通过海量的训练数据和构建多隐层的神经网络结构,可以大幅提高目标检测的准确性。
目前基于深度学习的行人检测取得了诸多的研究进展,但是还面临着以下两个问题:① 由于实际应用中的应用场景复杂,对于小尺度行人,漏检率非常高。这是因为小尺度行人包含的视觉信息非常有限,难以提取行人目标的鲁棒视觉特征表达。② 基于深度学习的方法可以获得很好的性能,但是往往是以复杂的网络结构作为代价,网络层数过多,导致计算复杂度太高,难以得到推广应用。
为此,针对目前基于深度学习的行人检测方法存在的不足,提出了一种基于深度卷积神经网络特征层融合的小尺度行人检测方法。其基本思想是借鉴YOLO端到端的思想,搭建了一个包含9个卷积层和一个全连接层的CNN网络架构,对不同层级的特征进行融合,提升小尺度行人的检测准确度。在Caltech[11]、INRIA[12]两个公共行人数据集上的实验结果表明,本文提出的行人检测方法能够有效检测小尺度的行人,且网络架构的参数量更少,检测速度更快。
1 基于深度卷积神经网络特征层融合的小尺度行人检测框架
本文搭建的基于CNN的小尺度行人检测整体框架如图1所示。首先,为了提升小尺度行人的检测精度,采用了分块的预处理操作,减少小尺度行人图像的视觉信息损失。进而将CNN第5层与第8层的卷积特征进行级联,充分利用不同层级卷积特征的表征能力,提升检测性能。

图1 基于CNN的小尺度行人检测整体框图
对于基于深度学习的行人检测方法来说,较大尺寸的行人目标往往可以获得较为准确的检测结果,而对于小尺度行人,则难以获得理想的检测结果。针对这一问题,本文首先对输入图像进行分块预处理操作,将每张图像切分成4块,之后再和原图一起归一化到同一尺寸共同输入到网络中,然后再根据不同的尺度缩放系数将其映射回原图并融合得到最终结果,如图2所示。目的就是利用简单的分块操作,避免损失原始图像中的视觉信息,有效提升对小尺度行人的检测性能。
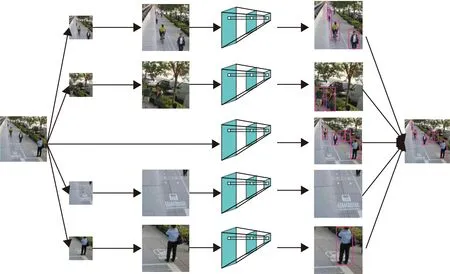
图2 行人检测框架
整个检测过程分为两个阶段:训练阶段和检测阶段。
(1) 训练阶段。
虽然目前有许多公开的行人数据集,但是它们的图像格式、标注方式、标注内容都不完全一致,因此需要首先对来自不同数据集的行人图像进行预处理,成为统一格式。本文参照PASCAL VOC数据集[13]的标注格式,将所需的两个行人数据集全部进行了转换。并采用数据扩充的方式,增加不同类型的样本数量,以提升网络的训练性能。之后将数据集中的训练图像样本进行预处理后,输入到网络进行有监督训练,得到行人检测模型。
(2) 检测阶段。
在检测阶段,输入待检测图像,进行分块预处理后得到一组相同大小的图像,将这组图像一同输入到网络,利用训练得到的行人检测模型进行预测,最后融合每块的预测结果得到最终的行人检测结果。
2 深度卷积神经网络结构设计
2.1 网络结构设计
如前所述,CNN已经被广泛应用于各种计算机视觉任务中,并获得了远超过传统方法的性能。大量的研究结果表明,利用CNN网络提取的深度特征对于平移、旋转、缩放等形变具有很好的鲁棒性,不同卷积层能够提取不同层级的特征,可以有效表征图像的局部和全局特性。
为此,参考YOLO网络架构,搭建了一种CNN网络架构,用于行人检测,如图3所示。该网络共包含9个卷积层、6个池化层和1个全连接层,并且将第8个卷积层特征上采样后与第5个卷积层特征进行级联,充分利用不同层级特征的表达能力,以达到更好的检测效果。本文提出的CNN网络模型的参数量大小为34.7 MB,仅有YOLO模型的1/3左右,大大减小了参数量。
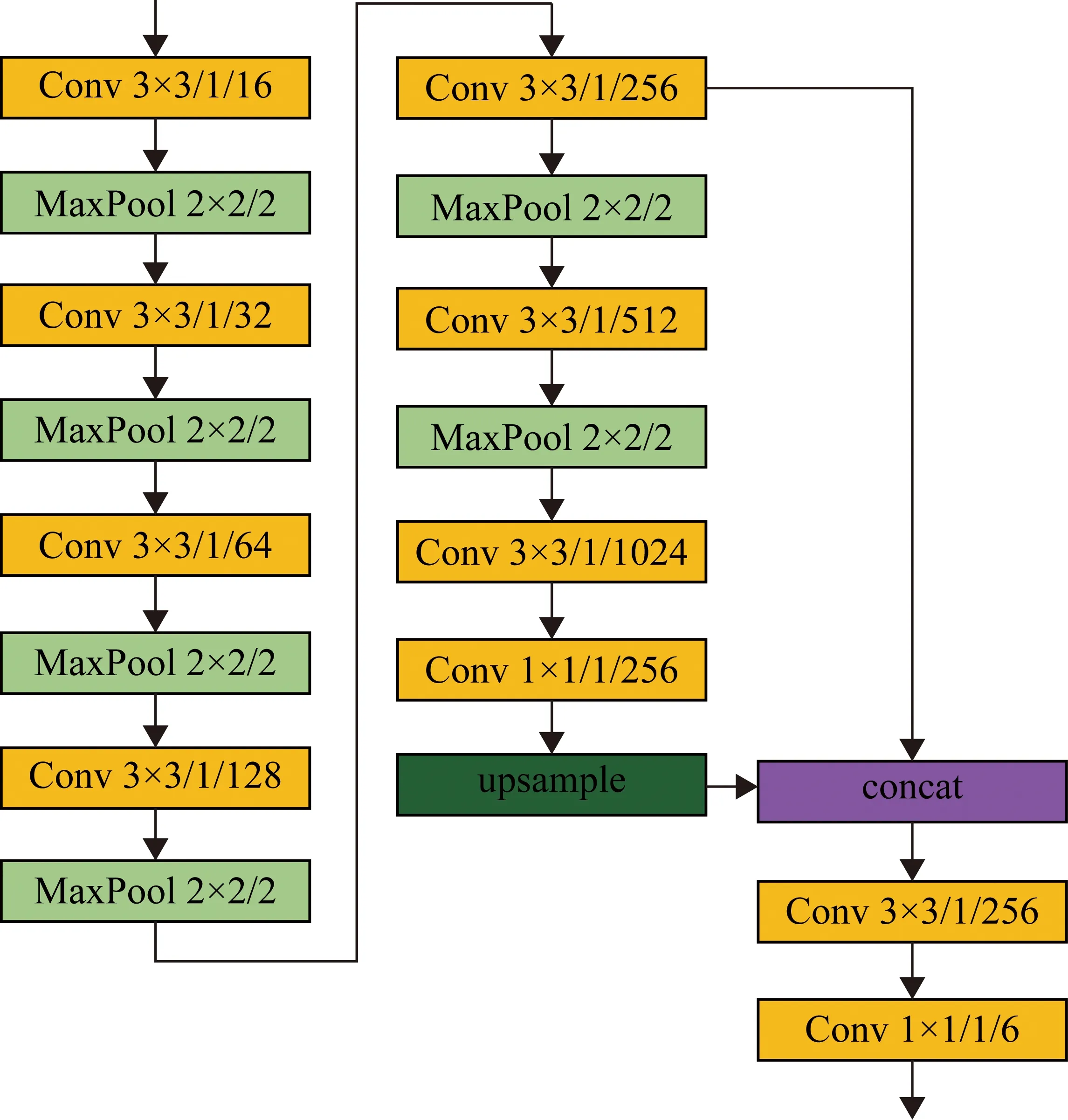
图3 基于深度卷积神经网络特征层融合的行人检测网络结构图
深度神经网络模型的参数量集中在大的卷积核和全连接层。本网络多选用3×3的卷积核,既可以保证感受野,又能有效减少卷积层的参数。在前6个卷积层后均增加一个最大池化层,能够有效进行特征降维、压缩数据和参数数量,抑制过拟合,同时提高模型的容错性。
2.2 网络参数设置
所提出的行人检测网络中卷积层、池化层和全连接层的具体参数在图3中给出,其中每层名称之后的数字表示“核尺寸/步长/卷积核数量”,网络中的全连接层采用1×1的卷积层实现。
训练过程中各项参数的选择对网络的性能起着非常关键的作用。在训练优化网络的过程中采用了随机梯度下降法,初始学习率(learning_rate)设置为 0.0001,momentum设置为0.9,之后在迭代固定次数后减小学习率。为了防止过拟合,将权重衰减(weight decay)设置为0.0005,每次迭代训练的图像数量(batch)大小为64,最大迭代次数(max_batches)设置为500200。
3 实验结果及分析
3.1 实验数据集
目前行人检测的公开数据集大致分为两类:一类是动态数据库,以车载视频数据为主,如Caltech[11]等;另一类是静态数据库,是用于研究静态图像行人检测的图像数据集,如MIT[14]、INRIA[12]等。为了验证所提出的行人检测方法的有效性,在INRIA[12]、Caltech[11]两个代表性的行人数据集上进行了实验。
(1) Caltech行人数据库。
Caltech行人数据库[11]是目前最大的车载视频数据库,共包含约10 h的道路视频,分辨率为640像素×480像素,帧率为30 f/s。其中137 min的图像内容被标注,涉及250000 f,其中行人数量为2300,矩形框数量为350000,包含行人遮挡情况。由于Caltech只包含视频文件,所以需要先将视频中的行人图像截取出来进行标注。其中set06~set10的标注信息尚未公开,所以本文仅使用了set00~set05子集,每个子集中具体图像数量由表2所示。

表2 Caltech数据集子集的图像数量
(2) INRIA数据库。
这是最为常用的静态行人图像数据库。因其样本图像均有标注好的标签文件,并有训练集合测试集的划分,所以在对比算法效果时,更具有说服力。训练集包含正样本614张,负样本1218张;测试集包含正样本288张,负样本453张。图像中行人多为站立姿势且大于100像素,主要来源于GRAZ-01、个人照片和Google,因此图像的清晰度较高。
这两个数据集有不同的标注格式,所以在进行训练时,对数据集进行了预处理,统一转换为标准PASCAL VOC格式[13],便于训练和测试。
3.2 性能评价标准
评价一个行人检测算法是否有效,可以通过在某一数据集上的准确性来进行验证。而衡量准确性的两个最重要的指标就是查准率(Precision,又称精确率)和查全率(Recall,又称召回率)。除此之外,漏检率(Miss Rate)也常被用来评价行人检测算法的性能。本文采用查准率、查全率和漏检率作为性能评价指标。
在行人检测中,检测为“是”的正样本为True Positive,记为TP;检测为“否”的负样本为True Negative,记为TN;错误检测为“是”的负样本为False Positive,记为FP;错误检测为“否”的正样本为False Negative,记为FN。则上述3个指标的定义如下:
(1)
(2)
(3)
3.3 预训练模型对检测性能的影响
大量的研究结果表明,对于特定的计算机视觉任务来说,有标注的训练样本往往比较有限。在此情况下,采用预训练策略可以有效提升网络性能。为了探究预训练策略对于行人检测性能的影响,首先在大型目标检测数据库——PASCAL VOC数据集[13]上进行了预训练,然后再在本节的2个数据集上进行微调。
本文将两个数据集中的训练数据进行合并之后用于模型训练,在训练过程中迭代了500200次后,loss为0.0573,平均loss为0.1152。训练得到的模型很小,参数量为34.7 MB,检测单张图像用时0.003 s,检测速度很快。
图4和图5为在未采用预训练策略的情况下,不同的迭代次数,得到的训练过程中的平均损失avg_loss和平均交并比avg_iou曲线。图6和图7为采用了预训练策略的情况下,不同的迭代次数后得到的训练过程中的avg_loss和avg_iou曲线。通过对比可以看出,采用了预训练策略,训练过程中avg_loss会迅速下降,最终loss值由0.0573降为0.0178,avg_loss由0.1152下降为0.0235。
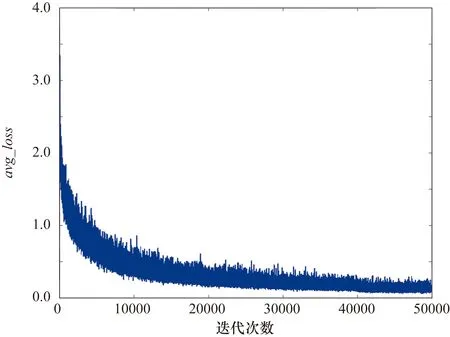
图4 训练过程的avg_loss
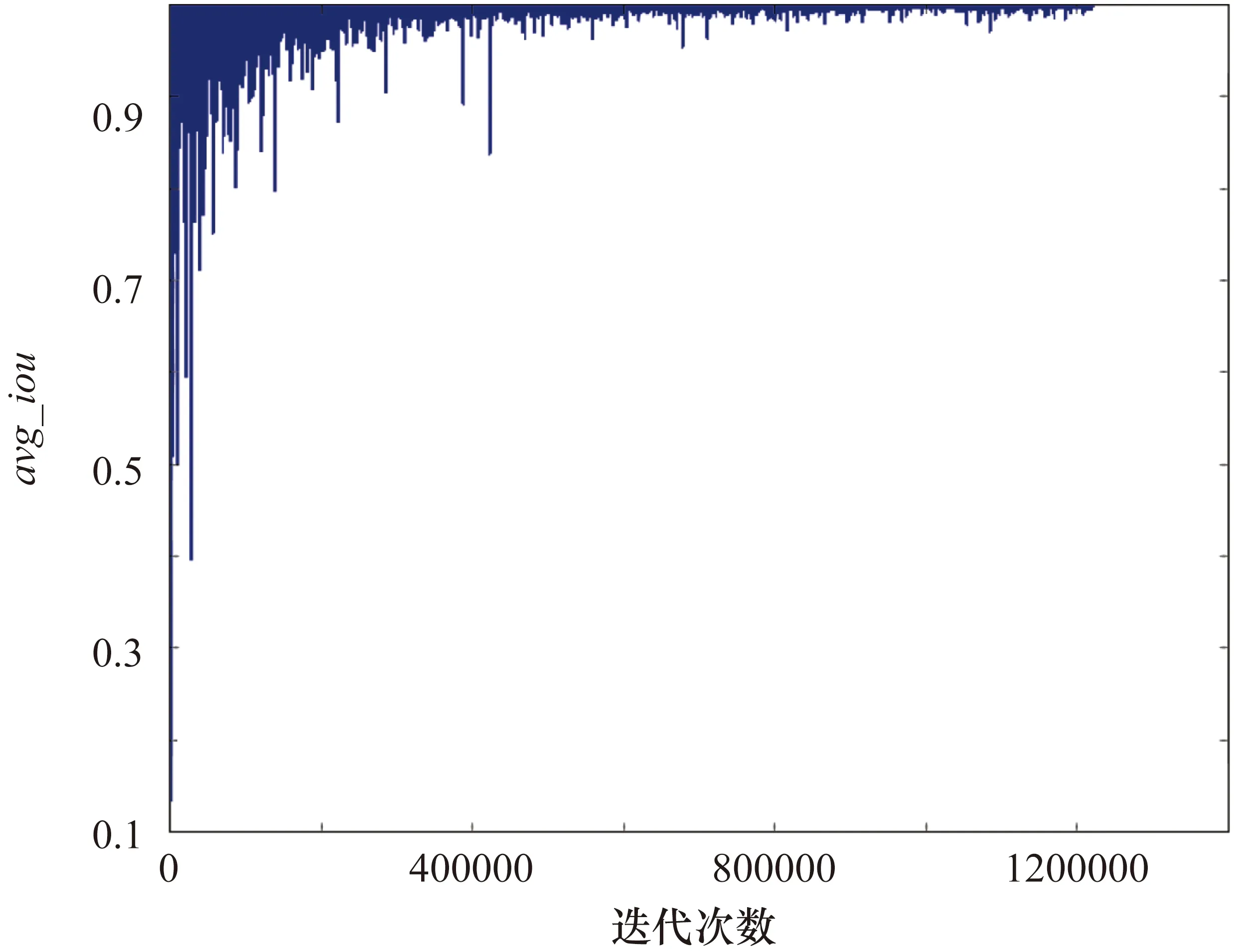
图5 训练过程的avg_iou
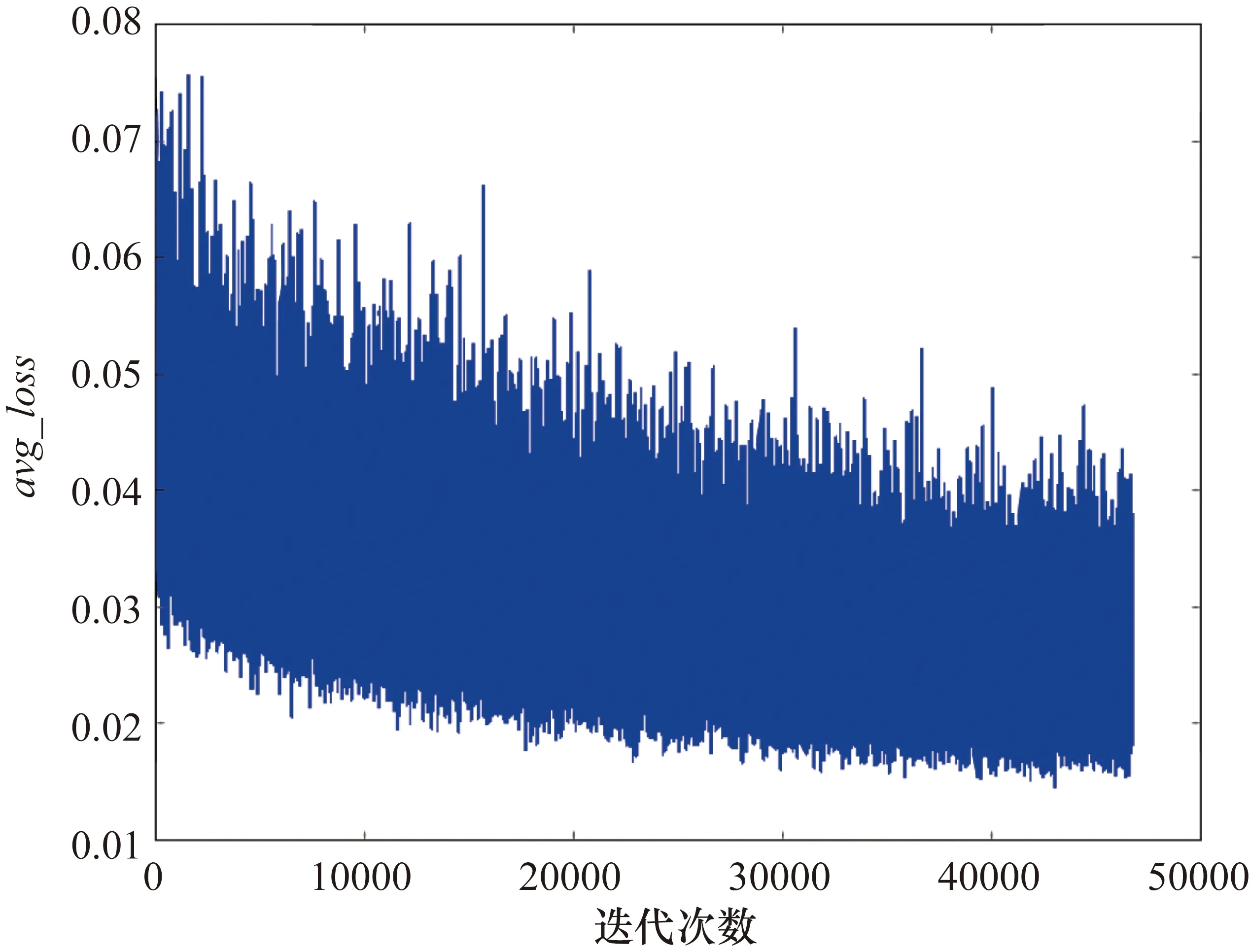
图6 预训练后训练过程的avg_loss
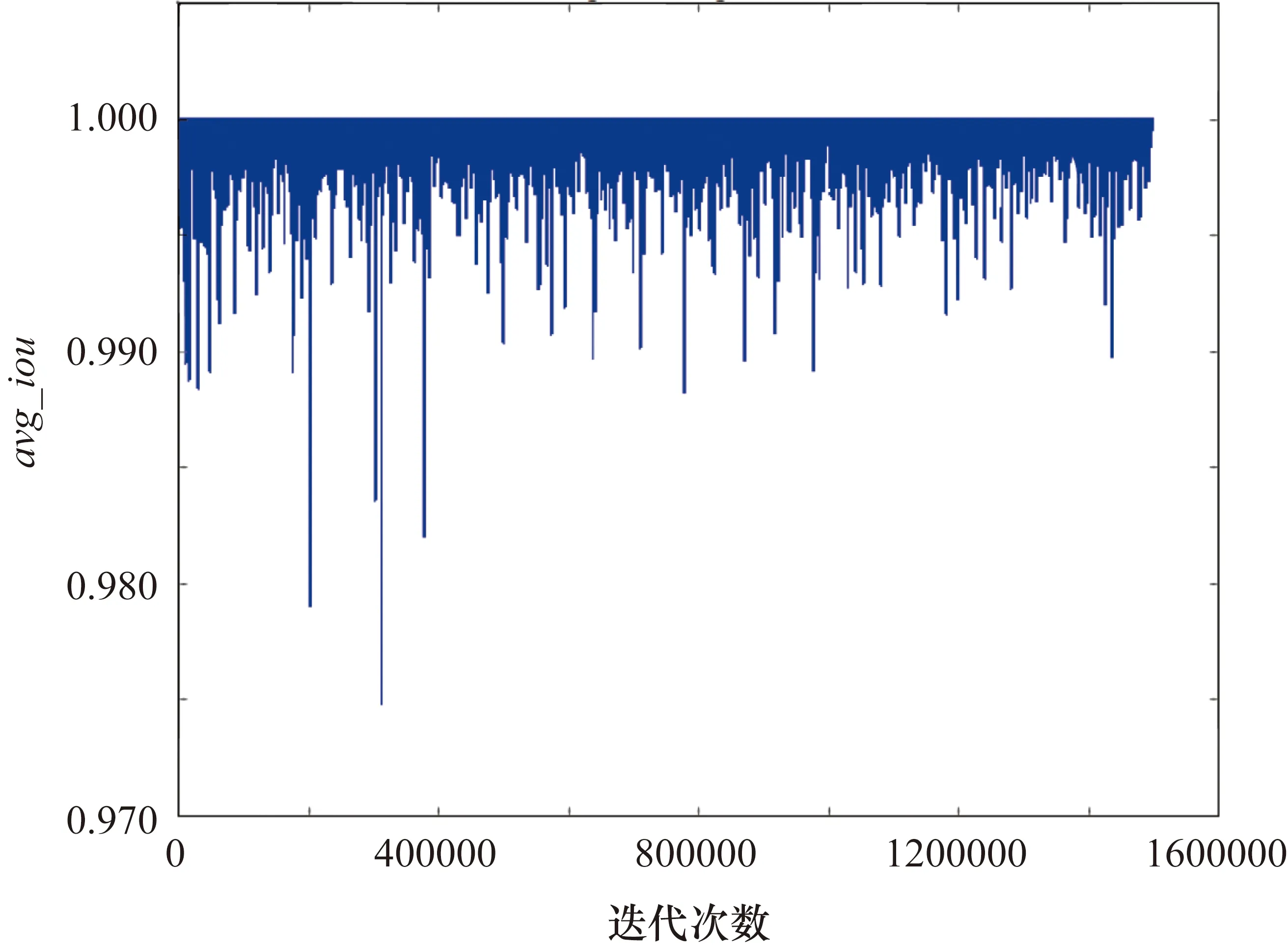
图7 预训练后训练过程的avg_iou
表3为在INRIA数据集上,采用和未采用预训练策略对行人检测性能的影响对比结果。可以看出,采用预训练策略,查准率提升了4.98%,查全率提升了4.56%,分别达到了97.29%和98.14%。可见在标注样本有限的情况下,预训练策略对于行人检测性能的提升起着非常重要的作用。

表3 预训练模型对检测性能的影响
3.4 特征融合对检测性能的影响
所提出的行人检测方法是将第8个卷积层特征上采样后与第5个卷积层特征进行级联,以充分利用不同卷积层特征的表征能力,达到更好的检测效果。为了验证第5层卷积特征与第8层卷积特征级联方式的有效性,本节还将与直接用第8层卷积特征进行行人检测的方式进行了对比。未添加级联层的网络结构如图8所示。
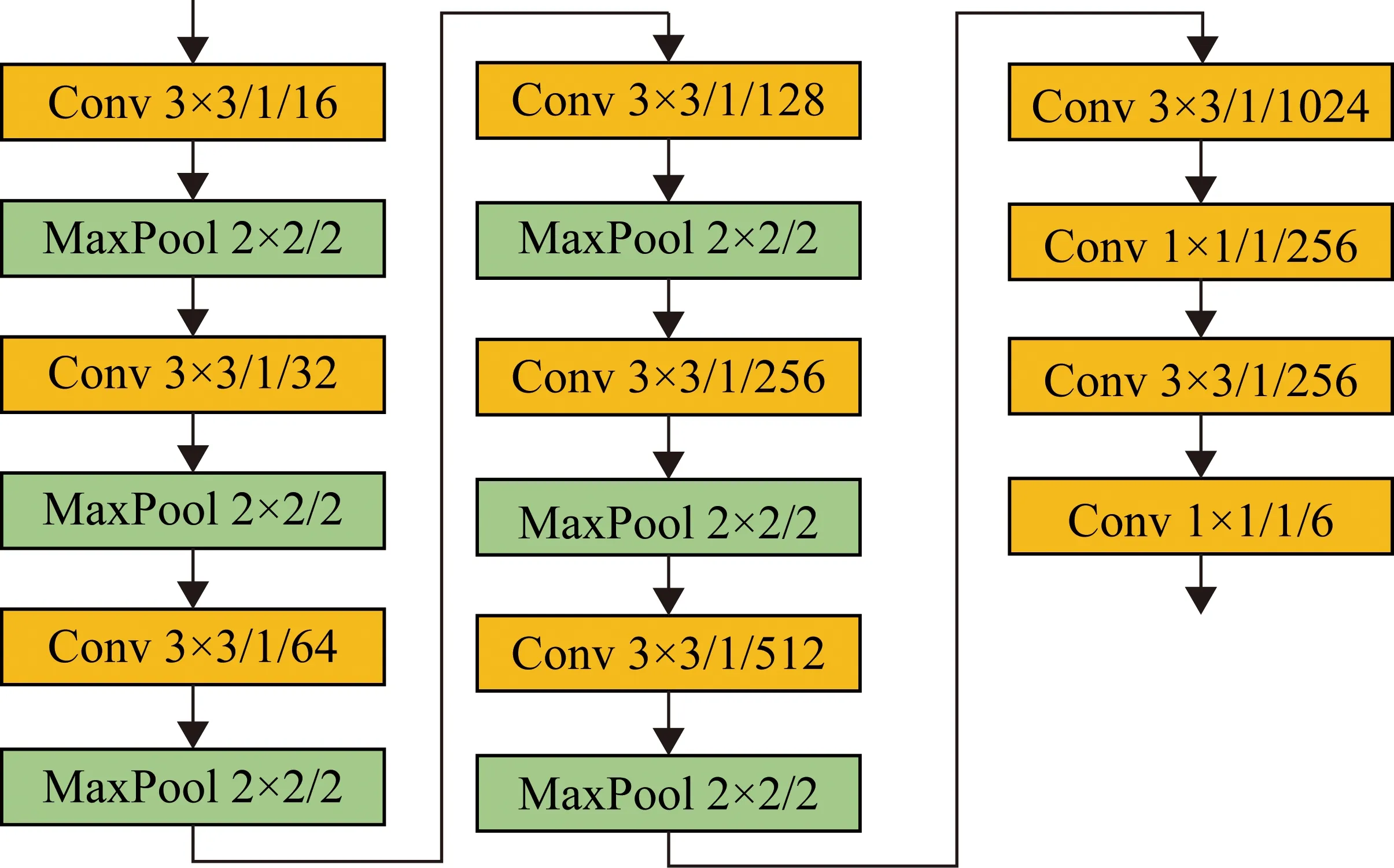
图8 未添加级联特征层的网络结构图
图9和图10为采用图8所示的结构,在相同的数据集下训练迭代了500200次后,得到的训练过程中的avg_loss和avg_iou。最终loss为0.9318,avg_loss为0.7636,查全率为85.92%,查准率为90.65%。通过与表3的实验结果进行对比,可以看出,与仅使用第8层的卷积特征相比,采用本文提出的第5层卷积特征与第8层卷积特征级联的方式可以获得更优的检测性能。
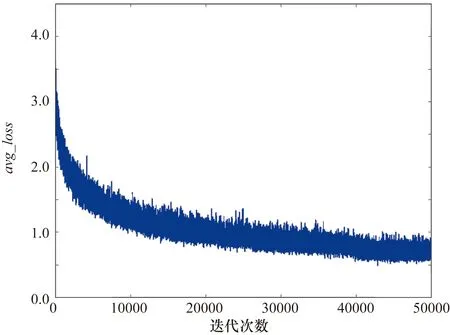
图9 未级联特征结构训练过程的avg_loss
图10 未级联特征结构训练过程的avg_iou
由表4所示的实验结果可知,采用第5层卷积特征与第8层卷积特征级联的方式,可以将查全率提升6.81%,查准率提升2.51%。由此可证明,采用本文提出的卷积特征级联的方式能够有效利用不同层级特征的表征能力,从而提升行人检测的性能。

表4 网络结构对检测性能的影响
3.5 本文方法与其他方法对比
INRIA数据集[12]作为目前被使用最多的公开数据集,大多数算法都会在此数据集上通过对比,展示自己的优越性。本文同样在此数据集上进行验证对比,实验平台为 Ubuntu 16.04,其拥有 Intel i5 6400 CPU,以及 16 GB内存和 GeForce Titan XP GPU。进行对比的算法既包括传统算法中的代表算法——HOG算法[14],也包括了利用轻型CNN网络架构的深度学习算法代表——AlexNet算法[3,16]和PCANet算法[17]。
HOG是最具代表性的行人检测手工特征,可以获得较好的检测性能。AlexNet包含5层卷积层和3层全连接层,其中前两个卷积层使用了11×11和5×5大小的卷积核,以减少特征维度,增大局部感受野,后3层的卷积核大小为3×3。虽然网络结构简单,但是在行人检测方面同样有较好的应用。PCANet则是通过两层都是5×5的较大卷积核搭建的轻型网络进行行人检测[18-19]。
表5是在INRIA数据库上分别采用不同的方法得到的行人检测性能对比结果,由表中结果可以看出,本文方法在查准率上均高于其他3个算法。虽然在漏检率上来看,本文算法的漏检率不是最低的,但考虑到模型的大小和参数量,本文算法仍具有一定的优势。
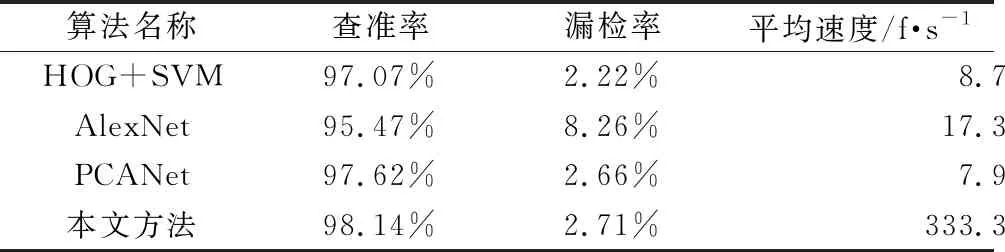
表5 不同方法在INRIA数据库上的行人检测性能对比结果
3.6 不同数据集上行人检测效果展示
将训练好的行人检测模型在不同数据集上进行测试,随机选取了INRIA数据库[12]、Caltech数据库[11]、MIT[15]数据库中的行人图像进行检测,检测效果如图11所示。从图11中可以看出,采用本文提出的方法对小尺寸行人目标具有较好检测结果。

图11 数据库示例检测结果
4 结束语
本文针对目前已有的基于深度学习的行人检测技术存在的不足,提出了一种基于CNN的行人检测算法。该方法利用YOLO算法端到端的思想,搭建了一种包含9个卷积层和一个全连接层的深度卷积网络架构,网络参数量更少,检测速度更快。同时,该方法还利用分块对图像进行预处理以提升不同尺度行人的检测精度。实验表明,与其他方法相比,本文提出的方法在检测精度上具有良好的表现,并且处理一帧640像素×480像素的图像平均仅需0.003 s,可为行人检测算法系统的工程化实现提供参考。
虽然本方法在查准率上高于对比方法,但在漏检率上却高于传统方法,这可能是由于本方法仅融合中间层特征进行预测,未考虑到底层特征,并且仅采用特征级联作为融合方式。因此未来工作可从利用多层特征结构和特征的融合方式这两个方面进行深入研究。同时,本方法虽然使用浅层网络大大降低了计算量,但是针对于实际应用来说,对于硬件设备的依赖还是较大,无法应用于未配备GPU的移动设备,今后仍需要对该算法的网络架构进行优化,以满足不同硬件设备的处理需求。
