基于深度学习的英语自然语言处理系统
2021-03-10曹艳琴
曹艳琴
(西安培华学院人文与国际教育学院,陕西西安 710125)
自然语言处理(Natural Language Processing,NLP)是指利用人类交流所使用的自然语言与机器进行交互通信的技术[1-4]。在NLP研究的早期,学者主要焦点集中在语言结构分析、技术驱动的机器翻译和语言识别方面[5-6]。目前的研究重点是NLP如何更加自然地在现实世界中使用,相应的研究领域包括智能对话系统和社交媒体数据等[7-8]。
随着机器学习的发展,有学者提出基于词典和规则的有监督机器学习分词算法[9-10],该类方法的优点是简单、易于实现,并且可以根据特定场景制定合适的词典。然而,由于没有统一的分词标准,词典的质量无法明确界定,分词结果存在较大差异。此外,有学者提出利用深度学习在NLP领域进行序列标记[11-12]。然而,深度学习网络训练过程比较复杂,许多传统文本标记方法无法直接移植到深度学习网络。最后,NLP中最重要的为文本特征提取,常用的特征提取方法包括TF-IDF算法、TextRank算法、LDA算法等[13-14]。然而,现有的模型并没有考虑不同模式对当前学习任务的重要性,只关注如何有效地同时使用多种模式进行特征提取。
为解决上述问题,本文提出了一种多模态融合特征提取模型,结合条件随机场(Conditional Random Field,CRF),解决句子层次分析中的序列标注问题。并基于混合网络英语分词处理方法,提高英语分词效率及准确率。
1 英语分词混合网络
1.1 网络架构
基于字符的序列标注任务同样可以看作是一个英语分词任务。在分词处理过程中,深度学习对于四元组的描述,主要是借助A4nin,即注释集的方式来实现。
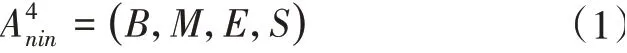
式(1)中,B表示句子开头;M代表句子中间;E为结束分词;S是由单个词组成的分词。
令输入句子设定为c(n),长度设定为n,窗口规格选定为w,起始字符设定为c(1)与c(n)。分词过程可描述如下:
步骤1将zi定义为输入层到隐藏层的线性转换结果,其表达式为

式(2)中,w1是权重矩阵;b1是偏差系数。
步骤2通过元素级激活函数传递线性变换的结果σ,得到隐含层函数hi,具体计算如下:

步骤3利用给定的标号集,用线性变换方式,开展线性变换操作,实现输入字符标记的可能性,即概率设定为yi,则
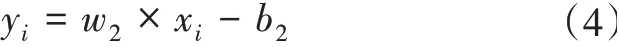
式(4)中,w2为权重矩阵,b2为偏差系数。
1.2 网络分词处理
为解决长短时记忆神经网络(LSTM)在英语分词处理中结构复杂、处理数据时间长等缺点,在保证处理精度接近的前提下,本文采用门控循环单元(Gate Recurrent Unit,GRU)[15]结合CRF16]模型提高模型训练效率及精度。图3所示为网络结构。
令网络中新引入的状态转移矩阵为A,双层GRU神经网络的输出矩阵为P。令Aij表示时间序列中从标签i转移到标签j的权重;如果Aij的值较大,则表示从标签i转移到标签j的概率较大。令Pij表示输入观测序列,即第i个单词是第j个标签的概率。因此,标记序列的预测输出y=(y1,y2,…,yn),对应于观察序列T=(t1,t2,…,tn)可表示为
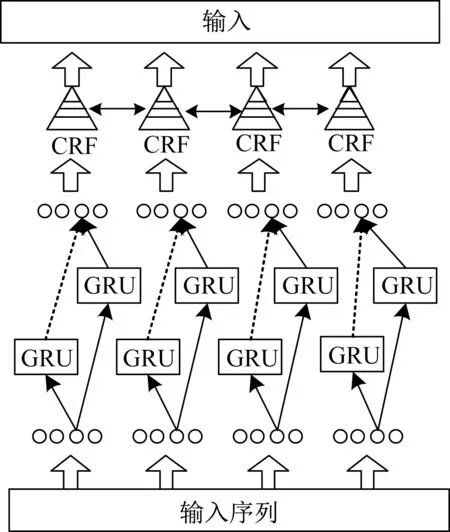
图1 GRU-CRF混合网络模型结构Fig.1 Structure of GRU-CRFhybrid network model
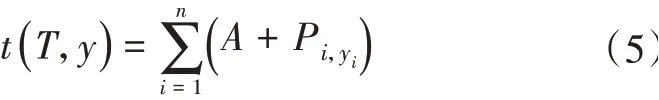
2 仿真与分析
2.1 数据集与仿真环境
实验中使用的数据来自SQuAD数据集,共包含107785个问题和相配套的536篇文章。仿真时随机选取20%的训练集作为开发集,其余训练集作为本实验的训练集。在对输入数据集进行训练之前,对所有数据进行预处理。
仿真环境为Python Tensorflow+GPU编译环境;显卡为NVIDIA rtx2080ti;Win10系统,64 GB内存;表1所示为实验部分网络参数。

表1 系统训练参数Tab.1 System training parameters
2.2 特征提取性能测试
表2所示为模型特征降维能力精度测试结果。可以看出,本文提出的模型能够从原始的高维特征中提取低维特征,有效地融合多种原始特征。
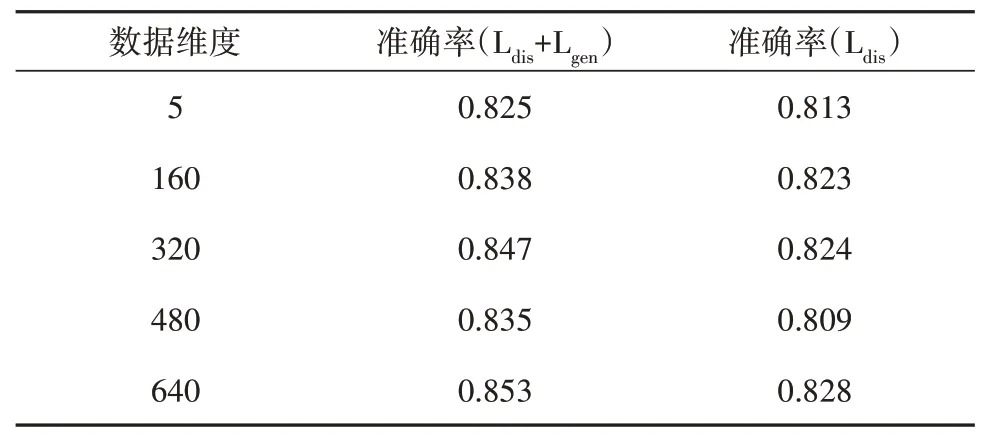
表2 精度测试结果Tab.2 Accuracy test results
2.3 网络分词性能测试
将本文提出的混合GRU-CRF网络模型与CRF、LSTM、BI-LSTM、GRU网络模型进行比较,准确率测试结果如图4所示。可以看出,所提出的混合GRU-CRF网络分词方法准确率高于其他模型的测试精度,表明本文的方法具有优异的分词性能。
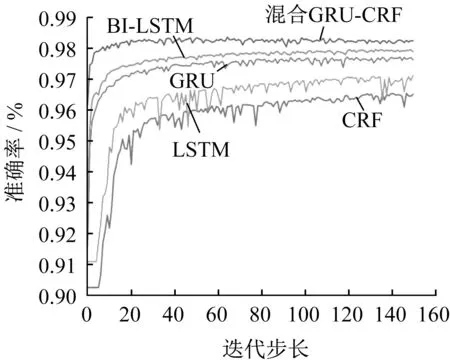
图2 不同策略模型性能对比结果Fig.2 Performance comparison results of different strategy models
3 结论
本文对英文自然语言处理中文本分割及特征提取进行了研究,构建了GRU-CRF混合网络为内核的分词模型,从而提高英语分词效率及准确率。本文所提出的模型不仅在时间指标上具备优势,而且还兼备LSTM优势,可借助CRF层实现对句子前后标签的关注与分析。本研究为英语自然语言处理有一定借鉴的作用。
