基于改进人工蜂群算法的大数据特征选择方法
2021-03-10李玮瑶
李玮瑶
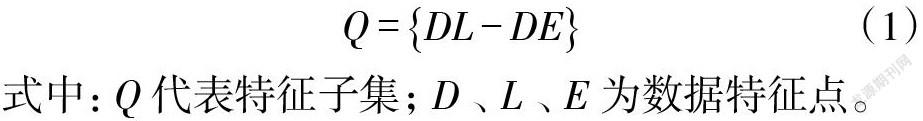
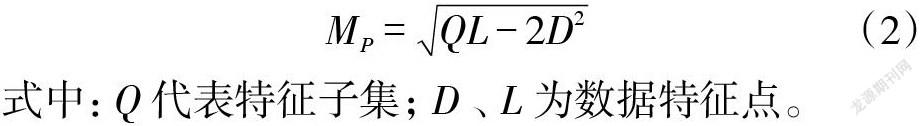


摘 要:数据特征选择就是从初始的数据特征中选择指定数据进行子集筛选。目前,通常使用人工蜂群算法进行特征选择,但由于收敛慢、寻优差,无法满足人们的需求。因此,本文提出一种改进人工蜂群算法,通过特征选择绘制大数据特征选择框架图,建立多项搜索渠道;利用改进的人工蜂群算法提取并行特征,使用MapReduce模型降低编程难度,获取并行特征最优解;设计特征选择复杂粗糙集模型,并构建特征学习模型来实现大数据特征选择。试验结果表明,设计的特征选择方法性能优于传统方法。
关键词:改进人工蜂群算法;大数据;特征选择
中图分类号:TP18 文献标识码:A 文章编号:1003-5168(2021)19-0027-03
Abstract: Data feature selection is to select specified data from the initial data features for subset filtering. Currently, artificial bee colony algorithms are usually used for feature selection, but due to slow convergence and poor optimization, it cannot meet people's needs. Therefore, this paper proposes an improved artificial bee colony algorithm, which draws the framework of big data feature selection through feature selection, and establishes multiple search channels; uses an improved artificial bee colony algorithm to extract parallel features, uses the MapReduce model to reduce programming difficulty, and obtains the optimal solution for parallel features; designs a complex rough set model for feature selection, and builds a feature learning model to realize big data feature selection. The test results show that the performance of the feature selection method designed in this paper is better than the traditional method.
Keywords: improve artificial bee colony algorithm;big data;feature selection
数据特征选择的过程就是属性约简,主要是针对数据的重组优化而产生的,属于查找类型的问题,目前是一个计算难题,需要使用全局搜索、启发式搜索和随机函数来解决。特征选择过滤方法的评价基准与分类器无关,旨在通过构建与分类器无关的评估指标来评估特征[1]。由于人工蜂群算法目前存在收敛慢、寻优差的问题,不足以进行数据特征选择,因此需要改进该算法[2]。
1 大數据特征选择方法设计
1.1 绘制大数据特征选择框架图
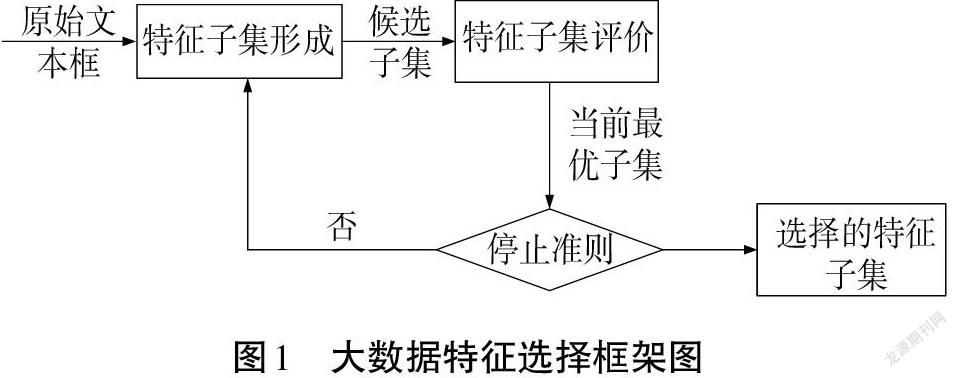
绘制大数据特征选择框架图首先要明确其制约指标,即子集范围。特征选择的子集是特征选择中最优解的一部分,因此与特征选择最优解的属性相同就可用于框架绘制[3]。
在数据并行层面,基于并行模型MapReduce实现数据的并行运算。在模型并行层面,特征选择算法在每次迭代时都可从一组候选集中选择最佳特征,然后根据最佳特征,使用多线程方法同时评估多个候选特征,而后进行汇总。为得到最好的选择效果,在方法层面,基于改进人工蜂群算法的大数据特征选择方法利用分割计算理论中的细分割原理,可在不同的信息分割表示之间快速渐进地切换。对于并行评估,需要构建分段表达框架来计算候选特征,最后将这3个方面有机结合起来,绘制出如图1所示的框架[4]。
1.2 基于改进人工蜂群算法提取并行特征
在特征选择模型中,每次迭代首先产生一个特征子集,必须使用评估函数对所有特征子集的优缺点进行评估。这些特征子集(也称为评估值)的重要性可根据模型本身的特性进行确定[5-8]。它的计算公式如式(1)所示。
式中:[Q]代表特征子集;[D]、[L]、[E]为数据特征点。
传统的小数据集可以实现很好的性能加速,但不能满足当前不断增长的数据量需求。GB级或TB级的数据规模使计算单个特征子集的速度变得非常缓慢,甚至会由于内存限制和其他问题导致其计算失败。此类问题最流行的解决方法之一是使用MapReduce模型,模型的求解式[MP]如式(2)所示。
式中:[Q]代表特征子集;[D]、[L]为数据特征点。
MapReduce模型降低了并行编程的难度,成为云计算平台的主流并行编程模型,可靠性和容错性高。输入数据被自动分区并发送到其他计算节点后在Map端进行计算。映射接收输入键值时,需要生成中间键值。MapReduce模型收集中间所有具有相同键值的值,并将它们传递给Reduce函数。Reduce函数接收数据输入,然后将这些值组合起来形成一组新的数值,最后计算出结果并输出。Hadoop平台是工业界和学术界广泛使用的MapReduce模型的重要实现平台之一,主要由Hadoop内核、MapReduce和Hadoop分布式文件系统组成。
匹配追踪算法MapReduce(MP)和动态规划算法Dynamic Programming(DP)在几个步骤中可以并行化进行特征选择。MP用于并行化模型层,缺点是不能处理大量数据。DP用于并行化数据层,但忽略了模型本身的并行化。本文将两种方法有机结合,提出一种模型数据并行化方法(简称MDP法)来改进人工蜂群算法。简而言之,改进算法可以为每次迭代创建一个搜索策略。多线程候选特征子集可以启动所有特征子集的重要性计算模块,其中每个特征子集的重要性计算模块都可以使用MapReduce模型来计算。实际上,MDP法采用一种两相并联模式,在计算出所有特征子集的重要性后,再进行特征筛选。利用改进人工蜂群算法提取变量,可以采取式(3)进行计算。
式中:[A]代表提取的变量;[C]代表初始值;[Y]代表变化矢量;[X]代表实际曲线变化。将提取的变量与最优解融合,利用式(4)即可提取并行特征。
式中:[P]代表最优解;[K]代表函数变量。代入相关参数,进行并行特征提取,此时提取出的数值即为最优解。
1.3 设计特征选择复杂粗糙集模型
实际应用中,通常有多种类型的数据,如符号、数字、设置值、缺失数据等。作为数据建模和规则提取的重要方法之一,粗糙集取得了较大进步。特征选择复杂粗糙集模型的优势在于可以在不使用先验知识的情况下发现数据特征。当复杂数据像其他建模方法一样高维、大容量时,数据融合法存在耗时过长甚至无法处理的缺点。因此,本方法提出有效执行复杂数据融合的关系,设计相应的复杂粗糙集模型。基于粗糙集设计各种特征选择算法,关键步骤是计算近似二元关系的计算式[CV],如式(5)所示。
式中:[CV]代表流量系数;[A]代表提取的变量;[K]代表函数变量;[P]代表相关参数。根据式(5)构建特征选择复杂粗糙集模型。
本方法引入了复杂关系并提出了复杂的粗糙集模型。非符号数据在实际应用中非常普遍,为了解决这个问题,需要引入不同的二元关系来处理不同的数据类型,因此提出了各种扩展的粗糙集模型。
1.4 实现大数据特征选择
为改进人工蜂群算法,本方法还需构建一个特征学习模型。假设有[n]个训练样本,它们都采用无监督学习法来学习高级表达式,需要建立学习主要目标,即在分类和回归问题中估计条件分布。
所有的预训练方法都基于这样的假设,即各个输入数据的边际分布包含有关条件分布的重要信息。当有大量标记数据时,采用监督学习方法通常非常有效。但是,如果只想要轻松地获取少量未标记数据,则需要将现有的标记数据与大量未标记数据相结合,以提高边缘分布估计的准确性。举一个线性特征空间的例子,潜在表示可只从未标记的数据中学习,或可只从标记的数据中学习,也可同时从两者中学习。不难发现,无监督学习方法能更好地分布数据,而监督学习方法可很好地进行分类,但不能保证与所需数据分布呈现一致性状态。协作培训有助于产生良好的表达能力。
2 试验分析
在多个数据集上应用多个分类算法往往不能更直接地比较各个方法的性能,所以需要通过假设检验来进行验证。本文采用显著性检验方法比较两种方法的差异性,且该方法不受条件和假设的限制。Friedman检验要求多个样本间无显著差异。
2.1 试验准备
首先提出一种特征选择和特征构造方法,通过GP先构造多特征,然后再用GP做特征选择,最后用K最邻近(K-Nearest Neighbor ,KNN)分类器测试分类性能。在数据集上比较两种方法的分类效果和特征维数。使用mini-batch SGD方法,即每次使用80个训练样本,权重衰减因子一般设为0.000 5,Momentum因子初始为0.5,在迭代过程中线性增加到0.9,通过均匀分布进行初始化。
2.2 试验结果与讨论
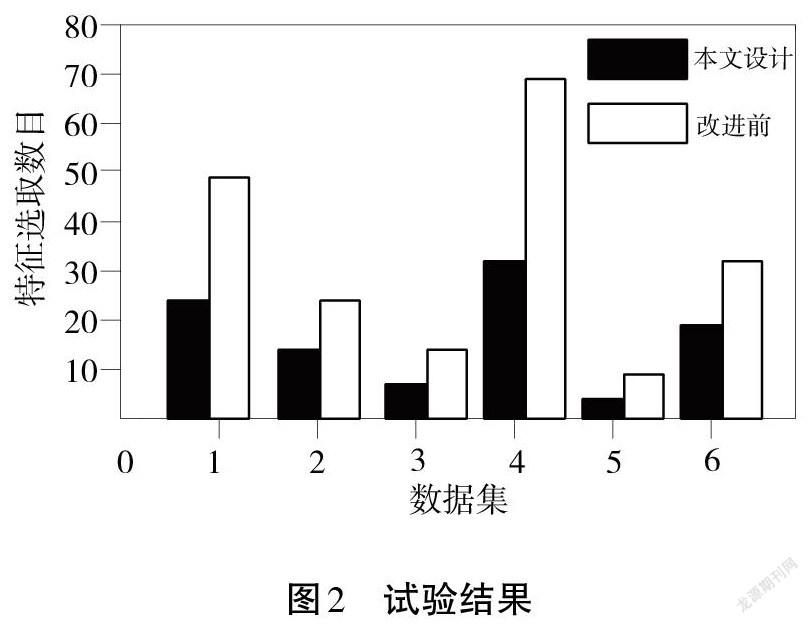
对改进前后数据特征选择方法进行检测,试验结果如图2所示。
从图2可知,改进算法的大数据特征选择方法性能优于未改进算法,其特征选取数目少,选取精度高。
3 结语
数据特征选择在数据筛选与传输中占有重要地位,提高数据特征选择精度对整个数据特征选择流程优化具有重要影响。本文对人工蜂群算法进行改进,优化其精度和寻优度,并通过对比试验证明改进算法后大数据特征选择方法性能优于改进前。改进后特征选择方法的特征选取数目少,选取精度高,有一定的应用价值,且具有高效性。
参考文献:
[1]王俊,冯军,张戈,等.基于改进灰狼优化算法的医学数据特征选择应用研究[J].河南大学学报(自然科学版),2020(5):570-578.
[2]曾海亮,林耀进,王晨曦,等.利用一致性分析的高维类别不平衡数据特征选择[J].小型微型计算机系统,2020(9):1946-1951.
[3]李帅位,张栋良,黄昕宇,等.数据特征选择与分类在机械故障诊断中的应用[J].振动与冲击,2020(2):218-222.
[4]刘辉,曾鹏飞,巫乔顺,等.基于改进遗传算法的转炉炼钢过程数据特征选择[J].仪器仪表学报,2019(12):185-195.
[5]刘芳.基于大数据特征选择的深度学习算法[J].赤峰学院学报(自然科学版),2019(5):46-48.
[6]高薇,解辉.基于粗糙集与人工蜂群算法的动态特征选择[J].计算机工程与设计,2019(9):2697-2703.
[7]吴颖,李晓玲,唐晶磊.Hadoop平台下粒子滤波结合改进ABC算法的IoT大数据特征选择方法[J].计算机应用研究,2019(11):3297-3301.
[8]孫倩,陈昊,李超.基于改进人工蜂群算法与MapReduce的大数据聚类算法[J].计算机应用研究,2020(6):113-116.
3246500338203
