基于Agent的改进贴近度的多属性评价模型
2021-03-09伍京华吴学桥
伍京华,吴学桥
1.中国矿业大学(北京)管理学院,北京100083
2.北京交通大学 经济管理学院,北京100044
基于Agent的自动谈判[1-2]利用Agent的人工智能优势,采用计算机模拟人们谈判,既能解决实际谈判中的异地问题,还能在节约谈判人工和时间等成本的基础上,有效提高谈判效率和效果,因此处于商务智能中自动谈判研究前沿。
实际商务谈判往往是多属性的,但由于谈判属性性质不同,评价模型也不同,导致基于Agent的自动谈判中的多属性评价问题一直未能很好解决[3],进一步导致基于Agent的自动谈判发挥Agent的人工智能优势不够充分,因此使得对其中多属性评价的研究具有重要的理论意义和实际价值。目前,该领域研究主要集中于基于Agent的自动谈判研究[4]、基于Agent的多属性研究[4]、基于Agent的多属性评价研究三个方面[4]。
在基于Agent的自动谈判方面,Radu[4]建立了捕捉对手行为要素的谈判模型,并提出基于遗传算法的策略设计方法以提高Agent的表现,但没有考虑让步或妥协等对谈判结果的影响。Vahidov等[5]研究了基于Agent的自动谈判策略与任务复杂性的相互作用,以及对Agent的评价产生的影响,该研究仅以问题数量表示谈判任务的复杂性,较为片面。Mell等[6]提出在线交互式人机谈判平台LAGO,考虑人的意识影响,加强Agent与人的交互,但是没能对Agent模拟人的情感深入研究。Haleema等[7]提出了基于Agent的灵活谈判策略及模型,考虑保留值和上一轮谈判提议,并能快速将提议缩小至双方期望值,也对Agent模拟人的情感研究不够。Franciscoa等[8]提出了基于Agent的分布式模糊预测控制模型,在合作博弈算法中引入模糊推理机制,使谈判过程更平稳,但应用的模糊规则对成员函数的精确度影响较大。
在基于Agent的多属性方面,Nassiri-Mofakham等[9]提出基于Agent的多属性竞价策略,综合考虑了竞买人的个性、多单位交易项目集、偏好以及市场情况,但只考虑数量和价格,属性较为单一。曹慕昆等[10]基于多目标优化遗传算法得出pareto边界的出价组合,并通过修正得到双方满意值,研究了基于Agent的多属性决策模型,但模型中的谈判策略还有丰富的机会。在此基础上,张奇志[11]提出了基于Agent及遗传算法的谈判模型,Agent可以动态选择合适策略来应对谈判对方Agent发出的提议,但该研究过多关注双方效用的约束关系,没有考虑情感对谈判属性值的动态影响。
在基于Agent的多属性评价方面,伍京华等[12]运用多属性效用函数,建立了以Agent为主体的提议评价模型,并运用模糊隶属度函数建立了相应的Agent主体信度评价模型,最后结合情感强度计算构建了基于Agent的合作主体选择模型,该研究将情感分类为积极、消极和中性三类,较为简单,存在一定局限。此后,伍京华等[13]重新定义基于Agent的情感劝说的决策过程,结合多属性效用评价定义了引入情感因子的情感触发函数,并建立Agent基本情感与劝说目标的映射关系和相应的决策模型,但研究的属性都是量化型属性。曹慕昆等[14]研究了适用于基于Agent的自动谈判的多属性谈判的固定策略和学习策略,通过学习对手策略进行微小让步,形成组合策略,提高Agent的谈判灵活性,他们的研究同样对基于Agent的情感涉及不多。
综上,本文首先结合犹豫模糊理论,构建基于多属性的方案;其次,将属性分为等级属性和数量属性,采用语言术语集对等级属性进行区间数转换,并给出将数量属性转换成区间数的方法;再次,综合以上研究,引入总体贡献率,对理想贴近度模型进行改进,提出基于总体贡献率的相对贴近度模型,从而提出基于Agent的改进贴近度的多属性评价模型,并对模型步骤及流程图进进行了归纳和梳理;最后,以北京市碳排放权交易为背景拟定算例和数据,通过计算和对比分析验证了该模型的合理性和有效性。
1 构建基于多属性的方案
基于Agent的自动谈判中,Agent能模拟人的各种心理和行为,从而对谈判结果产生影响[15]。因此,为了使谈判结果更符合实际,需要对Agent模拟人的这些心理和行为对其在谈判中的多属性影响进行描述,即构建基于多属性的方案。
犹豫模糊理论运用不确定性数据对事物的不确定性判断进行描述,能较好表达评价过程中存在的犹豫倾向,从而使不易被评价的信息被准确量化后易于评价[16],因此适于用来构建本文研究的基于多属性的方案。具体如下:
通过定义非空集合H为模糊区间集,给出该方案为公式(1)[17]:

其中,Tj代表各属性,h(Tj)是属性Tj的隶属度区间。
简化后为公式(2):
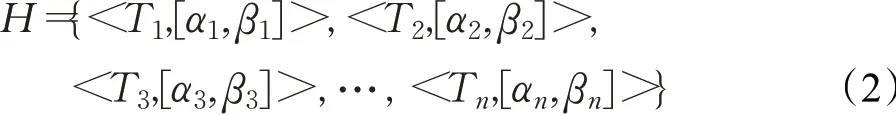
该公式的含义为,属性T1的隶属度是区间[α1,β1]之间的数,其余以此类推。
2 属性分类及其值的区间数转换
文献[12]将属性分为成本型属性和效益型属性,文献[18]将成本型属性全部转化为效益型属性,文献[19]在将属性分为成本型属性和效益型属性的同时,分别按照评价值类型对属性进行数值型评价和随机变量型评价的划分处理。
以上分类都是从成本效益的角度做出的,而很多既不属于成本也不属于效益的属性往往也是评价的重要参考因素,因此不适合本文的研究。
为弥补以上缺陷,本文在这些研究的基础上,将基于Agent的自动谈判中的属性分为等级属性和数量属性,以更适合本文研究。
2.1 属性分类
(1)等级属性
该属性是指评价值以等级形式给出的属性,例如企业信用、产品质量等,其值是诸如“信用较差”“质量高”之类的等级式评价语言。
(2)数量属性
该属性是指评价值都是具体数值的属性,例如产品0价格、购买数量等,其值是诸如“价格100元”“数量20,级区个”之类的准确性数据。
由于等级属性值和数量属性值的类型不同,因此为更适合展开进一步研究,本文采用语言术语集将等属性值转换成区间数,并给出将数量属性值也转换成间数的方法,从而对这两种属性值进行统一,供下节构建评价模型使用。
2.2 等级属性值的区间数转换
语言术语集是有限个连续的模糊性评价语言集合,能包含针对某一属性的所有评价信息,能较好表述谈判属性的不确定性和犹豫性[20],因此适于用来进行等级属性值的区间数转换。
例如,假设对某方案的某等级属性值为S={S0=低,S1=较低,S2=中,S3=较高,S4=高},对应区间数为S0=[0,0.2],S1=[0.2,0.4],S2=[0.4,0.6],S3=[0.6,0.8],S4=[0.8,1],采用语言术语集可将其转化成相应的区间数,则区间[0,0.2]代表属性值“低”,其余以此类推。
2.3 数量属性值的区间数转换
在基于Agent的自动谈判中,数量属性值存在一定的谈判区间。因此,本文给出以下公式,将数量属性值转换成相应的区间数:
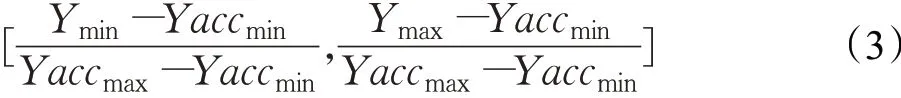
其中,[Yaccmin,Yaccmax]分别表示谈判中的买方Agent所能接受的数量属性最低值和最高值,[Ymin,Ymax]则分别表示谈判中的卖方Agent所能接受的数量属性最低值和最高值。
例如,假设某卖方Agent的某产品议价区间为[43,45]元,而买方Agent对该产品的价格的接收区间是[39,49]元,通过公式(3)转换后可得卖方Agent的产品议价区间数为[0.4,0.6]。
3 模型
结合以上研究,为构建该模型,首先需要设定正负理想方案X+和X-作为方案评价的标准;其次要在对各备选方案进行区间化处理的基础上构建合适的距离测度方法,用于方案评价的排序;最后设定相应的步骤和流程对模型进行描述。
3.1 设定正负理想方案
在基于Agent的自动谈判中,首先设定正负理想方案,作为Agent进行方案评价时的最优和最差标准,分别以公式(4)和(5)表示:其中,X+、X-分别表示正负理想方案。

3.2 基于总体贡献率的相对贴近度模型
首先,为对备选方案与正负理想方案进行评价,需要计算方案之间的距离。现有的距离测度模型如海明距离、曼哈顿距离等都无法保证对两区间的绝对距离测度足够精确[21-23],而经典的Euclidean Distance距离测度模型则能做到[24-26]。因此,本文采用该模型,通过公式(6)计算方案之间的距离:12
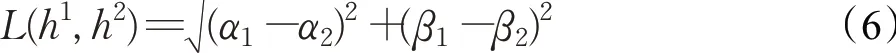
其中,α1、β1是区间h的左右端点,α2、β2是区间h的左右端点。
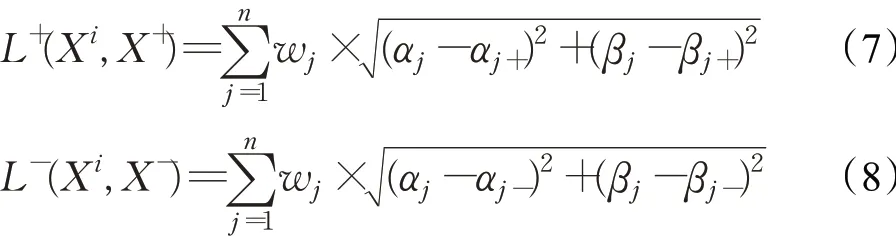
其次,需要计算每个方案与正负理想方案之间的距离,具体如公式(7)和公式(8):其中,j∈N*,L+(Xi,X+)和L-(Xi,X-)分别表示方案Xi与正负理想方案X+、X-之间的距离,wj表示方案的各属性权重,以向量W=(w1,w2,…,wn)t表示,αj、βj是某方案的第j个属性的区间左右端点,αj+、βj+是最优方案的第j个属性的区间左右端点,αj-、βj-同理。
L+(Xi,X+)越小,离正理想方案距离越近,表明此方案越优;L-(Xi,X-)越大,离负理想方案距离越远,方案也越优。
再次,由于以上计算并不能保证与正理想方案距离最近的方案同时与负理想方案之间的距离最远,因此需要寻找一种更加合理有效的模型来有效解决该问题。
Hadi-Vencheh和Mirjaberi[27]提出的理想贴近度模型通过引入劣比来表示最优尺度,反映正理想方案最近距离与负理想方案最远距离之间的平衡,其值越接近零,方案越优。但在备选方案较多、需要做大量筛选的情况下,该模型对各个方案的计算都是分开进行,彼此独立,这会导致出现方案贴近度过于接近或相等,从而导致不利于Agent进一步选择及增加谈判时间等缺点。总体贡献率将所有备选方案视为整体进行考量,每个方案都互相影响,方案不同而贡献率不同,能较好解决这些问题。因此,本文在对文献[27]提出的理想贴近度模型进行改进的基础上,结合总体贡献率思想,提出基于总体贡献率的相对贴近度模型,用于方案评价的排序,具体以公式(9)表示:示备选方案各属性与正理想方案
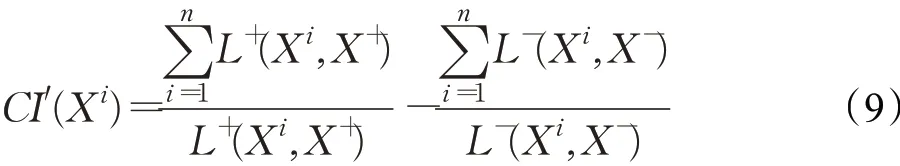
3.3 模型的步骤
综合以上研究,可得模型的具体步骤为:
步骤1为Agent设定正负理想方案和各属性权重,并由Agent确定备选方案。
步骤2Agent将方案中的属性识别划分为等级属性和数量属性,并将值分别转换为对应的区间数形式。
步骤3Agent计算各方案与正负理想方案的距离。
步骤4Agent计算各方案的相对贴近度并进行排序,做出决策。
4 算例分析
4.1 算例
首先,假设在北京市碳交易市场中,代表企业的Agent就碳排放权交易展开自动谈判,谈判属性为价格、额度、信用和活跃度。再假设买方Agent设定价格接受区间为19~28元,需要的额度为420~500 t,对企业信用等级的评价主要为{差、较差、一般、良好、优秀},对企业交易活跃度的评价主要有{低、较低、中等、较高、高},属性权重向量为W=(0.38,0.32,0.19,0.11),备选方案及正负理想方案如下:
方案1议价区间为[23.95,25.3],额度为[420,440],信用较差,活跃度较低。
方案2议价区间为[22.15,23.5],额度为[460,468],信用较差,活跃度低。
方案3议价区间为[21.7,24.4],额度为[444,448],信用一般,活跃度较高。
方案4议价区间为[24.4,26.65],额度为[456,464],信用良好,活跃度中等。
方案5议价区间为[19,22.15],额度为[432,448],信用一般,活跃度中等。
方案6议价区间为[22.6,23.95],额度为[452,464],信用较差,活跃度较低。
方案7议价区间为[22.6,24.85],额度为[436,452],信用一般,活跃度较高。
方案8议价区间为[24.4,26.2],额度为[468,472],信用优秀,活跃度中等。
方案9议价区间为[22.6,24.85],额度为[444,464],信用一般,活跃度较低。
方案10议价区间为[22.6,23.5],额度为[456,468],信用一般,活跃度较低。
方案11议价区间为[23.05,24.4],额度为[436,452],信用一般,活跃度较高。
方案12议价区间为[24.85,26.2],额度为[452,464],信用良好,活跃度中等。
正理想方案议价区间为[22.6,24.4],额度为[448,472],信用良好,活跃度较高。
负理想方案议价区间为[25.75,28.00],额度为[476,500],信用较差,活跃度较低。
其次,将上述备选方案转换成区间数形式,构造方案属性值矩阵如表1。
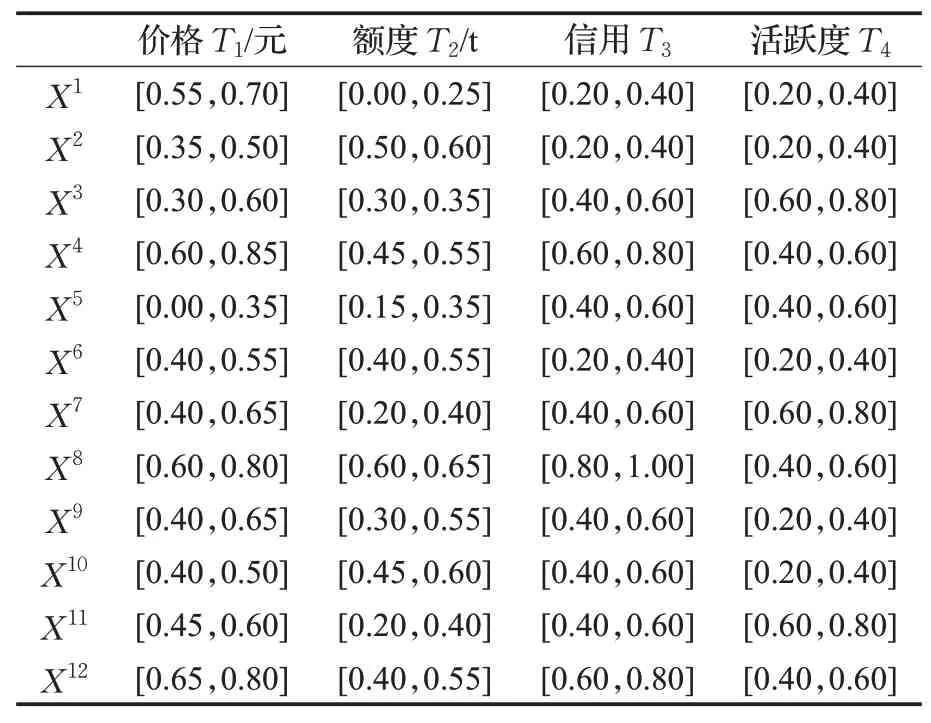
表1 备选方案属性值矩阵
并将正负理想方案也转化成区间数形式:

再次,分别采用文献[27]提出的理想贴近度模型和本文提出的相对贴近度模型进行计算,并根据结果对备选方案排序,具体如下:
(1)采用文献[27]提出的模型
各备选方案理想贴近度为:

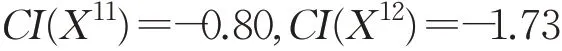
备选方案排序为X11=X7>X3>X12>X4>X8>X5>X10>X9>X2>X6>X1,最佳备选方案为方案7或方案11。
(2)采用本文提出的模型
各备选方案相对贴近度为:

备选方案排序为X11>X7>X3>X8>X12>X4>X5>X1>X10>X2>X9>X6,最优备选方案为方案11。
4.2 分析
图1 是采用两种模型计算得到的贴近度对比图,由图1可知:
(1)与采用文献[27]提出的模型相比,采用本文提出的模型能帮助Agent更进一步选择。例如,采用文献[27]提出的模型,备选方案7和11的贴近度均为−0.8,Agent无法进一步选择。而采用本文提出的模型,备选方案7的贴近度为75.4,备选方案11的贴近度为75.57,能帮助Agent更进一步选择更优方案,即方案11。
(2)采用文献[27]提出的模型计算得到的各方案贴近度相差不大,表现为图中的曲线平稳。而采用本文提出的模型计算得到的各方案贴近度相差较大,表现为图中的曲线更曲折。这不仅更有利于Agent在更多备选方案中做出快速选择,而且能在节约谈判时间的基础上保证谈判效果。
(3)采用文献[27]提出的模型计算的贴近度相互独立,如果方案增多,将会给Agent选择增加复杂度,采用本文提出的模型则能较好解决该问题。

图1 采用两种模型计算得到的贴近度对比图
5 结论
本文结合犹豫模糊理论构建基于多属性的方案,并将属性分为等级属性和数量属性,给出将这两种属性转换成区间数的方法后引入总体贡献率,对理想贴近度模型进行改进,提出基于总体贡献率的相对贴近度模型,从而提出基于Agent的改进贴近度的多属性评价模型。设计的算例及分析表明,本文提出的模型能降低复杂度,有助于Agent在更多备选方案中做出快速选择,节约谈判时间,同时还能帮助Agent更进一步选择更优方案。
