结合多元度量指标软件缺陷预测研究进展
2021-03-09杨丰玉黄雅璇周世健
杨丰玉,黄雅璇,周世健,郑 巍
1.南昌航空大学 软件学院,南昌330063
2.南昌航空大学 软件测评中心,南昌330063
软件缺陷是指软件产品的结果不符合软件要求或最终用户期望。它通常会以非预期的方式产生不正确或意外的结果和行为。软件日益增加的复杂性和依赖性增加了软件高质量、低成本和可维护的难度,以及创建软件缺陷的可能性。软件缺陷预测[1]是在测试之前识别出易出错的样本,达到提高软件质量的目的,它能自动检测出最可能出现错误的代码区域中的潜在缺陷,有效地优化有限资源的分配以进行测试和维护。
缺陷预测在软件质量保证中起着重要作用,是近年软件测试领域的研究重点之一。软件缺陷预测包括两个阶段[2]:从源文件中提取度量指标,使用各种机器学习算法构建缺陷预测模型。首先从软件历史仓库中创建数据样本,根据样本是否包含缺陷,可以将其标记为有缺陷或无缺陷。然后,用机器学习算法构建缺陷预测模型。最后,预测测试样本是否有缺陷。利用预测模型,开发人员可以有效地在缺陷样本上分配可用的测试资源,以便在开发生命周期的早期阶段提高软件质量。如图1所示。

图1 软件缺陷预测过程
其中,软件历史仓库包含版本控制系统和缺陷跟踪系统,版本控制系统包含源代码和文件变更信息,缺陷跟踪系统包含缺陷信息。软件历史仓库中每个样本的粒度包含方法、类、文件、变更和包级别等,根据预测粒度,每个样本可以表示为一个方法、一个类、一个源代码文件、一个程序包或一个代码更改。一个样本通常包含许多缺陷预测度量指标,度量指标表示软件及其开发过程的复杂性。
由于度量指标的质量会直接影响缺陷预测的效率和准确性,现如今提取度量指标的方法主要分为两个方面:一方面手动设计新的判别度量指标或组合度量指标,另一方面使用深度学习挖掘源代码中复杂的非线性特征,这些特征可以很好地表达源代码的语义和结构。
目前已有一些研究人员从不同方面对缺陷预测的相关研究工作进行梳理和归纳[3-7],李勇等人[4]从数据驱动的角度对基于版本内数据、跨版本数据和跨项目数据实现缺陷预测进行分类归纳,陈翔等人[3,5]对静态软件缺陷预测方法和跨项目软件缺陷预测进行归纳和分析,蔡亮等人[6]从数据标注、特征提取、模型构建和模型评估等人方面对即时软件缺陷预测进行梳理归纳,宫丽娜等人[7]从数据集、构建方法、评价指标等多个角度对软件缺陷预测进行全面总结。
与此不同的是,本文侧重度量指标的选择,对多元度量指标缺陷预测已有研究进行归纳总结,并总结了当前存在的主要问题和未来发展方向。主要通过IEEE Xplore Digital Library、ACM Digital Library、Springer Link online Library、Elsevier ScienceDirect及CNKI等在线数据库进行检索,检索关键词主要包括software defect prediction和software fault prediction等,最终选出与该研究问题直接相关的论文共73篇(截止到2020年10月)。
1 基于传统度量指标的缺陷预测
1.1 传统度量指标
软件度量指标是影响缺陷预测质量的核心因素,若设计与缺陷强相关性的度量指标将很大幅度地提高缺陷预测的准确度。源代码是一种特殊的形式语言,包含丰富的语义和结构信息,根据源代码信息和软件开发过程中的复杂性,现有的度量指标分为代码度量和过程度量[8]。代码度量是直接收集现有源代码,主要度量源代码的代码规模和复杂性等属性,具有越高复杂度的软件模块更容易出现缺陷。从存储在版本控制系统和缺陷跟踪系统的历史信息中提取的信息称为过程度量,这些度量量化了随着时间变化的软件开发过程,如源代码变更、代码更改的数量、开发人员信息等。表1列出了常见的用于软件缺陷预测的代码度量和过程度量。
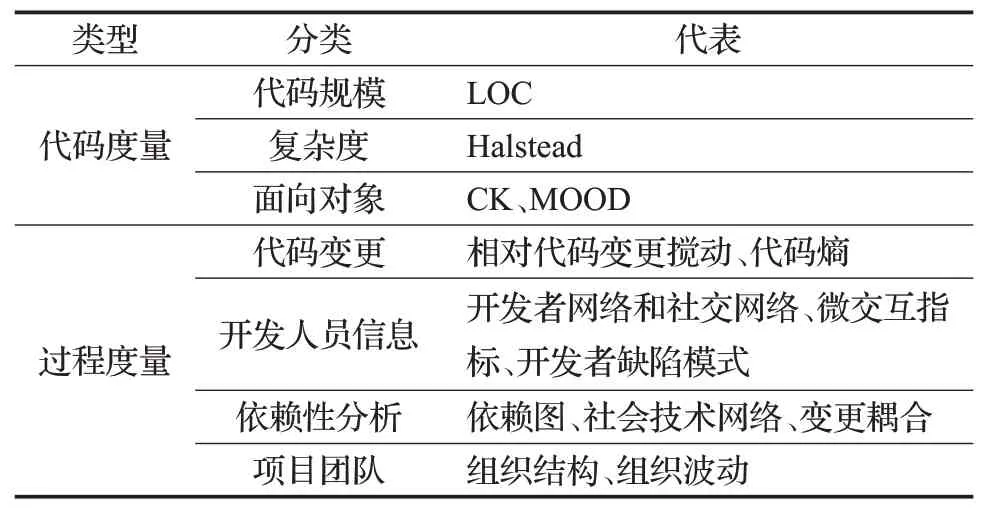
表1 常见的传统度量指标
1.1.1 传统代码度量
常用的传统度量指标有代码行(LOC)[9],基于运算符和操作数的Halstead度量[10],基于依赖性的McCabe度量[11],面向对象程序的CK度量[12],基于多态性因子、耦合因子的MOOD度量[13]和代码气味度量[14]。除此之外,Aman等人[15]证明了注释行也能作为分析模块缺陷的度量指标。Majd等人[16]引入了32种新的语句级别的代码度量指标,该预测模型可以预测某条语句可能存在多少缺陷。
但是,并非所有的传统代码度量都对缺陷预测有利,冗余和无关度量会增加模型构建时间,甚至降低模型性能,如何选择合适的指标是问题的关键。研究人员已尝试用特征选择来解决该问题,特征选择旨在选择特征子集来替换原始特征集[17],此特征子集能更有效地区分软件模块的类别标签。由于存在多种特征选择方法,比较不同特征选择方法的有效性变得至关重要。Chen等人[18]基于搜索的软件工程的思想,将特征选择形式化为一个多目标问题并进行多目标优化。他们考虑了两个目标,一个是尽可能少地选择特征,另一个是尽可能提高缺陷预测模型的性能。Xu等人[19]对32种不同的特征选择方法进行了大规模的实验,最后确定出一组优秀的特征选择方法。随后,他们提出了一种称为KPWE的缺陷预测框架[20],该框架结合了基于核函数的主成分分析(Kernel Principal Component Analysis,KPCA)和加权极限学习机算法(Weighted Extreme Learning Machine,WELM)。首先,KPWE利用KPCA技术的非线性映射将原始数据投影到潜在特征空间,在空间中映射的特征可以很好地表示原始特征。其次,通过映射特性,KPWE应用WELM来构建一个高效且有效的缺陷预测模型,该模型可以处理不平衡的缺陷数据。
1.1.2传统过程度量
近年来,研究者提出了许多代表性过程度量,如相对代码更改搅动指标[21]、开发者网络和社交网络指标[22]、依赖图指标[23]和组织结构指标[24]等。其中,研究工作集中在如何利用软件模块之间的依赖关系,构建网络度量指标[22-23,25-26]。
一个软件系统包括许多实体和元素,例如类、函数和变量。因此,如果将软件系统的元素视为节点,将关系视为网络系统的边缘,就可以将其转换为网络系统。许多软件网络的拓扑特征与缺陷密切相关,可以用作软件缺陷预测的指标。例如,Zimmermann等人[23]基于Windows Server 2003生成了模块依赖关系图并对该图进行了网络分析。该研究定义了局部、全局和中心网络指标,并表明依赖图上的网络度量指标可用于预测缺陷数量。实验表明,网络度量指标在预测关键二进制文件和缺陷方面比复杂性指标更好。随后,Premraj等人[27]复制了Zimmermann等人[23]的实验,揭示在代价感知和CPDP方面,网络度量指标并不优于代码度量。因此,Ma等人[28]对11个具有不同规模、编程语言和应用程序域的开源项目的多个版本进行研究,与Premraj等人[27]不同的是,他们发现大多数网络度量指标都与缺陷倾向显著正相关,并且网络度量指标对于大型和复杂项目更为有效,而在小型项目中则不稳定。
Yang等人[29]基于软件元素之间的关系及其演化关系建立了一个面向对象的软件网络,并建立了许多度量指标来宏观地描述软件模块。此外,一些研究人员认为可以将开发人员活动交互视为软件网络,组成网络度量。Meneely等人[22]使用一套新的基于开发人员社交网络的开发人员指标,如果两个开发人员在同一时间段内处理相同的文件,则将其连接在一起。结果发现基于文件的开发人员指标与软件缺陷之间的显著相关性。
代码度量和过程度量都能建立缺陷预测模型,但是,代码度量和过程度量谁更优存在不同争论。Arisholm等人[30]分析了不同度量指标对模型预测性能的影响,结果表明若选择不同的性能评价指标,结果将相反。Moser等人[31]发现若使用Eclipse数据集,过程度量的效果比代码度量更好。Rahman等人[32]从多个角度分析了代码度量和过程度量的适用性和有效性,结果表明代码度量有很高的滞后性,不如过程指标有用。
1.2 缺陷预测模型构建
根据数据来源不同,软件缺陷预测可分为同项目缺陷预测(Within Project Defect Prediction,WPDP)和跨项目缺陷预测(Cross-Project Defect Prediction,CPDP)。WPDP指在带标签的样本上训练模型,并对同一项目中其余未标记的样本执行预测。CPDP是指从其他项目中迁移出与目标项目相关的知识进行训练。目前最流行、应用最广泛的缺陷预测建模方法是机器学习方法[33],将基于传统度量指标的缺陷预测文献大致分为以下四类:有监督学习缺陷预测、半监督学习缺陷预测、无监督学习缺陷预测和跨项目缺陷预测。
1.2.1 有监督学习缺陷预测
有监督学习方法是指在项目中使用带有标签的缺陷数据来训练分类或回归模型,然后用该模型确定新软件模块的缺陷信息。如人工神经网络[34-35]、贝叶斯网络[36]、支持向量机[37]、字典学习[38]、关联规则[39]、朴素贝叶斯[40]、随机森林[41]、遗传算法[42]和集成学习[43]。
Xu等人[44]提出一个基于深度神经网络(Deep Neural Networks,DNN)的学习深度特征表示框架,并向DNN引入了一种混合损失函数以学习更多具有区分度的特征,结果表明,在同项目缺陷预测可以获得更好的性能。Yang等人[45]提出结合决策树和集成学习的双层集成学习方法来构建即时缺陷预测模型。该方法在内层使用基于决策树的装袋集成学习方法来构建随机森林模型,在外层使用随机抽样的方法来训练不同的随机森林模型,然后按照堆叠方式来集成这些不同的随机森林模型。Qiu等人[46]利用DNN从传统特征中自动学习高维特征表示,然后用决策森林进行分类,主要解决了以端到端方法结合神经网络和决策森林的问题。
1.2.2 半监督学习缺陷预测
半监督学习方法是通过在项目中仅使用少量标签的训练数据和大量没有标签的数据来构建缺陷预测模型。He等人[47]提出了半监督学习方法extRF,该方法通过自我训练模式扩展了有监督的随机森林算法。首先从数据集中抽取小部分数据作为有标签的数据集,使用这小部分数据集训练随机森林分类器,根据训练好的分类器去预测未标记的数据集,然后选择最好的样本加入到训练集中,并进行训练初始模型,以此类推,最后形成精炼模型。Zhang等人[48]提出了一种基于非负稀疏图的标签传播方法进行缺陷预测。首先对标记的无缺陷实例重新采样以生成平衡的训练数据集,并使用非负稀疏图算法计算关系图的权重以更好地学习数据关系。最后,在非负稀疏图中,使用标签传播算法来迭代预测未标记的软件模块。Arshad等人[49]提出了一种基于半监督的深度模糊C均值聚类的特征提取方法,该方法通过利用未标记和标记数据集的深度多聚类来生成新特征。Wu等人[50]介绍了半监督词典学习技术并提出了一种成本敏感的内核化半监督词典学习(Cost-sensitive Kernelized Semisupervised Dictionary Learning,CKSDL)方法,CKSDL可以充分利用内核空间中有限的标记缺陷数据和大量未标记数据,在16个项目上进行大量实验,结果表明,该方法在WPDP和CPDP上都具有较好的预测性能。
1.2.3 无监督学习缺陷预测
无监督学习方法不需要有标签的训练数据,它们直接利用项目中的未标记数据来学习缺陷预测模型。对新项目或没有足够历史数据的项目进行缺陷预测是一个具有挑战性的问题,为了解决这个问题,Nam和Kim[51]提出CLA和CLAMI方法,CLA方法对样本进行聚集和标记,CLAMI方法在CLA基础上还进行了度量选择和样本选择,其关键思想是通过度量值大小来标记没有标签的数据集。随后,Yan等人[52]扩展了CLAMI样本聚集部分,在14个开源项目上评估了这种无监督方法,结果表明,无监督方法可以产生比有监督方法更好的效果。由于频谱聚类是基于连通性的无监督聚类方法,不需要训练数据,Zhang等人[53]利用频谱聚类解决CPDP中源项目和目标项目之间的异质性,发现使用频谱聚类的无监督学习方法在CPDP和WPDP场景下都有可比较性。
1.2.4 跨项目缺陷预测
在实际情况下,目标项目可能没有任何标记样本的新项目,或者这个项目的标记样本较少,不足以训练高质量的缺陷预测模型。如果直接使用从其他项目(即源项目)收集的带标签数据并且不执行任何数据预处理,训练后的模型的性能可能不佳,因为在大多数情况下,不同项目之间的数据分布无法满足。因此,研究人员设计了不同的方法[54]来缓解跨项目情况下的数据分布差异。
Pan等人[55]提出一种迁移成分分析(Transfer Component Analysis,TCA)方法,通过最小化数据分布之间的距离的同时保留住原始数据属性,为源项目和目标项目的数据发现新的特征表示,并根据新的特征表示对数据进行转换。结果显示,TCA可以减小数据分布差异。然后,Nam等人[56]提出了TCA+,将源项目和目标项目映射到共享的潜在空间中,使它们之间的数据分布距离很近,以提升跨项目缺陷预测的性能。
常规的CPDP始终假定源项目和目标项目使用相同的度量标准集。研究人员考虑到通用指标的数量可能很小,或者在通用指标中没有高质量的指标,在目标项目中寻找源项目的相同指标有一定难度等问题,他们提出异构缺陷预测(Heterogeneous Defect Prediction,HDP)方法。He等人[57]提出一种特征集不平衡的CPDP(Cross-Project Defect Prediction Imbalanced Feature Sets,CPDP-IFS)方法,该方法提出了16个基于分布特征的新指标。随后,Nam等人[58]提出一种HDP方法,通过计算不同项目中源度量指标和目标度量指标的匹配分数,删除冗余无关的特征,找到相似性高的匹配度量指标。实验结果表明,使用该方法,即使项目使用不同的度量集,也有可能快速地迁移关于缺陷预测的信息。可以最小化源项目和目标项目之间的数据分布差异。
Li等人[59]提出集成多核相关对齐(Ensemble Multiple Kernel Correlation Alignment,EMKCA)方法,通过多次内核学习将源项目和目标项目数据映射到高维内核空间中,并利用内核相关性对齐方法减少源项目和目标项目的数据分布,最后集成了多个内核分类器用来解决类不平衡问题。实验结果显示,该方法能更好地分离高维内核空间中的有缺陷和无缺陷的模块。随后,他们提出一种代价敏感迁移核规范相关分析(Cost-sensitive Transfer Kernel Canonical Correlation Analysis,CTKCCA)方法[60],设计用于HDP的迁移核规范相关分析方法解决线性不可分问题,利用代价敏感缓解类不平衡问题。实验表明,CTKCCA可以使非线性特征空间中的源项目和目标项目的数据分布更加相似,且学习的特征具有良好的分离性。之后,他们扩展了先前的研究[59],提出两阶段集成学习方法[61],该方法包含集成多内核域自适应(Ensemble Multi-kernel Domain Adaptation,EMDA)阶段和集成数据采样(Ensemble Data Sampling,EDS)阶段。EMDA阶段使用EMKCA预测器,EDS阶段采用带有替换技术的重采样学习多个EMKCA预测器,并使用平均集成将它们组合在一起。
1.3 数据质量
软件缺陷预测的数据可以来源于开源项目和商业项目,现有的常用公开数据集包括PROMISE、NASA[62]、AEEEM[63]、SOFTLAB[64]和ReLink[65]等。有少量文献和企业合作使用了商业项目[66]。
数据质量对缺陷预测性能有着巨大的影响,数据集中常包含一些降低预测模型性能的问题,如关键特征选择和类不平衡等。
1.3.1 数据集
表2 汇总了研究文献所用的数据集,以下对常用的数据集进行简短介绍。

表2 数据集
PROMISE:自2005年以来收集了一些开源项目和一些研究人员自发提供的项目的缺陷信息构成PROMISE Repository。至今,该数据集包含38个开源项目,其中类级软件度量指标有20个。
NASA:NASA MDP数据集包含13个NASA软件项目的方法级软件度量指标。在这13个数据集中,一个用Java(KC3)编写,其余使用C/C++。这些数据集中的缺陷率范围从0.5%(PC2)到32.3%(MC2)。此外,这些数据集中的度量指标并不完全相同,其中一些包含其他指标。在该组数据集中,CM1、KC3、MC2、MW1、PC1、PC2、PC3和PC4有40个度量指标,MC1和PC5包含39个度量指标,JM1、KC1、KC2有21个度量指标。
AEEEM:AEEEM数据集包含五个开源项目(Eclipse JDT Core、Eclipse PDE UI、Equinox Framework、Mylyn、Apache Lucence)。每个数据集包含61个软件度量指标,包括面向对象指标和变更度量指标。
SOFTLAB:SOFTLAB由嵌入式控制器AR1、AR2、AR3、AR4、AR5和AR6项目组成,这些项目从PROMISE中获得。每个数据集包含29个度量指标,其中包括Halstead和McCabe度量指标。
ReLink:ReLink中包含三个数据集Apache HTTP Server、OpenIntents Safe和ZXing。这些数据集包含26个软件度量指标,并且手动验证了缺陷标签。
ELEF:ELEF数据集[67]一共有23个Java开源项目,包含了类级和方法级度量指标,其中类级度量指标有39个,方法级度量指标有26个。
NetGen:NetGen是Herzig等人[68]收集的变更级数据集,此数据集由四个开源项目组成,总共有456个度量指标,包括与文件历史相关的复杂性度量指标、网络度量指标和变更度量指标。
1.3.2 关键特征选择
维数爆炸是影响缺陷预测模型性能的问题之一,特征选择方法能够从高维特征中选取具有代表性的特征子集,避免不相关或冗余特征带来的分类干扰。为了解决这个问题,Jia[69]提出了一种结合了不同特征分类技术的混合特征选择方法,该方法根据卡方、信息增益、Pearson相关系数对特征进行排序并使用随机森林构建预测模型。Balogun等人[70]提出特征选择的影响取决于搜索方法的选择,使用四种不同的分类器对NASA的五个数据集进行了四种筛选特征排序和十四种筛选特征子集选择方法的评估。实验表明,基于特征排序的缺陷预测在预测性能方面更加稳定。
Liu等人[71]提出一种基于特征聚类和特征排名的新特征选择框架(Feature Clustering and Feature Ranking,FECAR),根据特征间的相关性将原始特征划分为k个聚类,使内部聚类特征高度相关。然后,从每个聚类中选择相关特征并按照相关性排序构建最终特征子集,实验表明,该方法有效地处理了冗余和不相关的特征。Xu等人[72]提出层次聚类的最大信息系数特征系数框架(Maximal Information Coefficient with Hierarchical Agglomerative Clustering,MICHAC),MICHAC利用最大信息系数对候选特征进行排序,过滤不相关的特征;然后,采用分层聚类的方法对特征进行分组,并从每一组特征中选取一个特征来去除冗余特征。
1.3.3 类不平衡
类不平衡问题是指至少一个类别比其他类别多。在软件缺陷数据集中,缺陷模块要少于非缺陷模块,因此不平衡缺陷数据集上训练的模型通常偏向于非缺陷类模块,而忽略了缺陷类模块。类不平衡问题是软件缺陷预测模型性能差的主要原因之一。随机欠采样和过采样技术已被广泛使用[73-74],但是它们的准确性取决于现有数据和分类算法,为了普遍缓解类不平衡问题带来的影响,Bennin等人[75]提出了一种基于染色体遗传理论的新型高效合成过采样方法(MAHAKIL),MAHAKIL将两个不同的子类解释为父类,并生成一个新实例,该实例从每个父类继承不同特征并有助于数据分布内的多样性。为了同时解决类不平衡问题和支持向量机(Support Vector Machines,SVM)的参数选择问题,Cai等人[76]提出了一种基于支持向量机的混合多目标布谷鸟搜索欠采样软件缺陷预测模型,利用混合多目标布谷鸟搜索与动态局部搜索来同步选择无缺陷采样并优化SVM的参数。然后,该模型提出了三种欠采样方法来选择无缺陷的模块。结果显示,提出的方法对解决类不平衡问题生效。Huda等人[77]集成了随机欠采样和过采样方法解决类不平衡问题,并在PROMISE数据集上验证了所提出的方法的有效性。
表3 列出了基于传统度量指标的研究文献使用的度量指标和数据集。
2 基于语义结构度量指标的缺陷预测
过去的几十年已经提出了多种研究人员手工设计的传统度量指标来区分有缺陷和无缺陷文件[78-79]。随着研究的逐渐深入,研究人员发现传统度量指标主要关注代码复杂性,通常无法区分具有不同语义的程序,不能完全捕获源代码中的复杂语义信息和度量指标之间的潜在关联[80-81]。
近些年,深度学习方法已成功解决许多自然语言处理问题,包括解析、机器翻译、情感分析和自动问答等。有学者[73]将深度学习引申到软件缺陷预测中,开始尝试利用深度学习自动捕获程序的语义表示和度量指标之间的潜在关联(即语法结构),得到源代码语义度量指标和结构度量指标。从数据挖掘角度来看,软件度量指标可视为特征,传统度量指标可称为传统特征,语义度量指标可称为语义特征,结构度量指标可称为结构特征。
2.1 语义度量指标
传统代码度量主要关注程序的统计特征,并假定有缺陷的软件模块和无缺陷的模块具有可区分的统计特征和面向对象特征。但是,研究者[80]通过对实际开发的软件模块观察发现,现有的传统代码度量指标无法区分不同语义的模块,即具有不同语义软件模块可能具有相似或相同的传统代码度量指标。例如,在图2中,有两个Java文件,两个文件都包含一个for语句和两个函数调用。使用传统度量来表示这两个代码段时,它们的特征向量是相同的,但是,语义信息明显不同。如果队列为空,调用remove()时,File2.java将遇到异常,需要建立更准确的预测模型来区分此类语义差异的模块。为了捕获源代码中的复杂语义信息和语法结构,Wang等人[80]首次提出利用深度学习从源代码中提取语义特征。
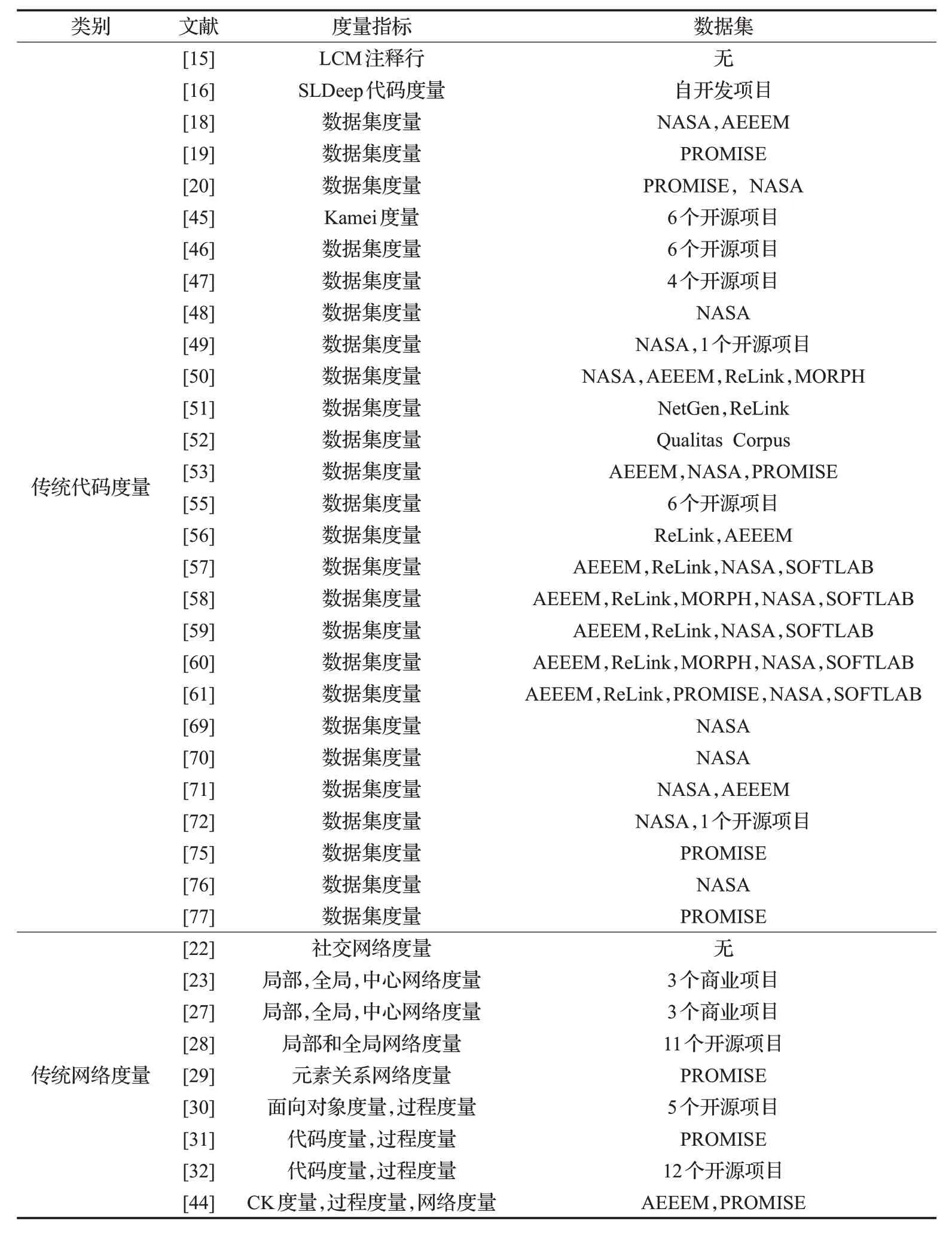
表3 研究文献中度量指标和数据集(一)

图2 例子
2.1.1 从抽象语法树捕获语义度量
目前,现有常用的提取方法是将源代码转化为抽象语法树(Abstract Syntax Tree,AST)。AST是代码在计算机内存的一种树状数据结构,用于描述代码上下文关系。AST可以有效地存储语义信息和语法结构[82],有助于准确地分析和定位缺陷。利用深度学习来挖掘AST的隐藏特征可以生成更能体现代码上下文信息的度量指标,从而更准确地预测软件缺陷。
Wang等人[80]先将源代码解析为AST,然后利用深度置信网络(Deep Belief Network,DBN)从AST节点中提取token向量并生成语义特征。随后,他们从源代码变更中提取语义特征,对变更级的软件缺陷预测进行了扩展[83]。Li等人[81]将传统特征与卷积神经网络(Convolutional Neural Networks,CNN)学习的语义特征相结合,以构建一个混合预测模型。为了更好地利用AST的树结构并在源代码中反映语法和语义的多个层次,在记录AST的声明节点时,没有记录节点名称,而是提取节点的值来构建token向量。随后,邱少健等人[84]采用三层卷积神经网络提取源代码潜在语义特征,并用代价敏感对数据进行处理解决了类不平衡问题。Pan等人[85]在此基础上进行了改进,将CNN模型的全连接层增加为四个,还添加了三个dropout层防止模型过拟合。结果表明,改进的CNN模型在WPDP方面明显优于最新的机器学习模型。为了从程序中捕获语义信息,Liang等人[86]构建了一种基于长短期记忆网络(Long Short Term Memory networks,LSTM)的缺陷预测框架,该框架采用了连续词袋(Continuous Bag-Of-Words Model,CBOW)来学习程序AST的向量表示,其抛弃了传统的机器学习模型,而是采用LSTM来构建缺陷预测模型。
程序中的上下文语义至关重要,但CNN无法捕获长距离特征,Fan等人[87]开始采用具有注意力机制的递归神经网络(Recurrent Neural Network,RNN)来区分关键语法结构和语义特征。先从AST中提取的token向量中自动学习语义特征,再用注意力机制进一步捕获重要特征并赋予更高的权重,使训练更准确。结果表明,缺陷预测模型性能得到了提升。与Liang等人[86]不同的是,Deng等人[88]并没有选择LSTM构建缺陷预测模型,而是利用双向长短期记忆网络的长距离依赖特性更好地学习上下文语义特征。因为Transformer突出的并行计算能力,Zhang等人[89]尝试使用Transformer捕获向量中特定位置的关键特征。
上述从AST节点中提取token向量过程中,通常选择遍历AST来进行序列化,但这种方式会损失一定的语义信息。一些研究人员尝试通过其他方法将AST序列化,从而捕获更全面的语义特征。例如,Fan等人[90]基于四个开源Android应用程序,从AST中提取高频关键字获得基于规则的编程模式,使用DBN从编程模式中学习源代码的内部信息。实验结果表明,该方法学习到的特征能比传统特征预测更多缺陷。Dam等人[91]认为遍历AST没有完全编码代码的语义和语法结构,提出了一个基于树的长短期记忆网络(TB-LSTM)模型来获取整个AST的向量表示。为了避免AST序列化的损失,该模型直接使用树形LSTM匹配AST表示,将每个AST节点都输入LSTM单元,在Samsung项目和公共PROMISE数据集上的实验结果证实了其有效性。Shi等人[92]认为接近的源代码之间存在很强的语义相关性,提出短路径的概念来描述每个终端节点及其控制逻辑,并使用成对的短路径描述代码的语义信息,并通过注意力机制将它们融合在一起,在PROMISE数据集上进行实验表明,该方法比TB-LSTM具有更好的性能。Rahman等人[93]通过分析AST得到代码配置文件,使用代码配置文件作为语义特征代替传统度量指标来改进缺陷预测。在Eclipse数据集和Github缺陷数据库进行实验,结果表明,在版本内缺陷预测中该方法比传统度量指标更好,而在跨版本缺陷预测中表现不佳。
考虑到细粒度级别的预测可能更能准确定位预测的缺陷,Shippey等人[94]使用AST n-gram来识别有缺陷的Java代码特征。将模块中每个Java方法进行AST序列化,再将方法序列按照字节进行大小为N的滑动窗口操作,形成长度为N的字节片段序列,这个字节片段序列称为AST n-gram。结果表明,AST n-gram在某些系统中与缺陷非常相关,对预测模型影响很大,某些频繁出现的AST n-gram意味着该方法包含缺陷的可能性比其他方法提高了三倍。曹靖[95]试图考虑更细粒度的预测,他将代码缺陷定位在代码行,从AST中提取指定类的实例的API调用序列,预测API序列中的API误用缺陷。
2.1.2 其他方式捕获语义度量
一些研究者认为,AST序列化不能完全表达源代码语义,开始尝试通过其他方式从源代码中捕获语义特征。Phan等人[96]认为AST仅表示源代码的抽象语法结构,不显示程序的执行过程,该方法通过编译源代码获取汇编指令构造控制流程图(Control Flow Graph,CFG),然后利用基于多视图多层有向图的卷积神经网络在CFG上学习语义特征,结果表明与基于AST的语义特征相比,基于CFG的语义特征性能更好。Zhang等人[97]将交叉熵作为一种新的代码度量引入缺陷预测中,该方法利用LSTM挖掘代码语料库,捕获程序中常见模式和规律,然后将模型输入到token序列的联合概率分布中得到软件模块的交叉熵,实验结果表明,交叉熵符合代码自然性,对传统代码度量进行很好的补充。随后,在此基础上,他们进行了扩展研究,提出了代码抽象语法树节点序列交叉熵(CE-AST)[98],结果表明,CE-AST具有更大的区分力。
Scandariato等人[99]将Android源代码中的Java文件看作文本,采用词袋模型统计文件中相关词的频率,用符号特征生成缺陷特征向量。针对Android源代码难以获取的问题,Dong等人[100]从Android二进制可执行文件中提取符号特征和语义特征来构建缺陷预测模型,结果表明,该方法在WPDP中的准确率比CPDP更高。
Okutan等人[101]从抄袭和克隆检测技术中得到启发,从源代码中学习到一种新的语义度量指标。他们发现源文件的语法或语义相似度与其缺陷倾向性可能存在关联,基于这种假设,他们为每个文件计算相似性度量指标得到源文件之间的相似性,用这些相似性度量指标来预测特定文件是否有缺陷。Huo等人[102]认为注释可以视为源代码的另一个视图,帮助生成语义特征,这些语义特征反映了用于识别缺陷模块的代码特征。但由于部分开发人员的习惯,有些项目的注释很少,为了克服这个问题,他们构建了一种基于注释增强程序的卷积神经网络(CAP-CNN)的缺陷预测模型,该网络可以在训练过程中自动编码和吸收注释信息以自动生成语义特征,实验结果表明,注释特征能够提高缺陷预测性能。
为了避免AST序列化过程中损失语义信息,Humphreys等人[103]直接将源代码作为序列输入到深度学习模型中,由于源代码文件组成成千上万个token,并且代码区域之间的距离很长,因为需要能快速处理长距离依赖关系的深度学习模型,该研究使用transformer从长序列中提取语义特征并证明了模型的可解释性。Miholca等人[104]提出一种将渐进关系关联规则与人工神经网络相结合的混合分类模型,该模型可以根据从源代码中自动学习的语义特征来预测缺陷。
2.1.3 基于CPDP的语义度量指标
在以前利用深度学习捕获语义特征的研究中[80-81],没有考虑项目之间语义特征分布差异的影响,因此,Lin等人[105]尝试将从现有软件项目获取的语义表示迁移到新项目中,为了验证方法的可行性,手动标记了457个缺陷特征,并从6个开源项目中收集了30 000多个非缺陷特征。实验结果证实,训练后的模型能跨多个项目进行调整。Chen等人[106]设计了一种基于双向长短期记忆网络和注意力机制的CPDP方法,提出一种新的无监督嵌入算法自动学习了从AST中提取的token向量的有意义表示,最后利用双向长短期记忆网络和注意力机制学习上下文语义特征。在不同的应用程序域的10个开源项目中进行实验表明,该方法可以应用在CPDP。
为了最小化项目之间的分类误差和分布差异,Qiu等人[107]将源和目标项目特定数据的隐藏表示形式嵌入到再生内核Hilbert空间中进行分布匹配,然后将源文件解析的整数向量放入CNN中生成语义特征。Deng等人[108]探索了更合适CPDP的AST节点粒度并在CNN中添加多内核匹配层以最小化源和目标项目的数据分布差异。Sheng等人[109]提出了对抗判别卷积神经网络,通过欺骗甄别器来学习目标项目到源项目特征空间的判别映射。
与Dam等人[91]类似的是,Cai等人[110]基于树的嵌入,将AST节点编码为向量并在再生内核Hilbert空间中迁移不同项目的特征,其中还测量了AST之间的语义差距,最后将编码后的AST馈入神经网络提取语义和结构特征。
2.2 结构度量指标
若仅关注代码度量,使用文件或类粒度的统计特征或语义特征,会忽略软件模块的宏观完整性,破坏软件模块元素之间的相互影响。相比需要人工建立的传统网络度量指标,研究人员试图使用网络嵌入等方法对软件系统网络结构进行分析。
网络嵌入是将软件网络嵌入到低维空间,其中每个网络节点都表示为低维向量,这种低维嵌入已经解决了很多问题,例如节点分类、链路预测和个性化推荐。目前,大量的网络嵌入算法已成功应用于网络表示学习中,包括DeepWalk[111]、Node2vec[112]和LINE[113]。这些算法对代码文件之间依赖关系形成的软件网络进行表示性学习,提取软件模块的结构特征进行缺陷预测。
与Meneely等人[22]的研究工作相似的是,Loyola等人[114]用开发人员活动数据构建了依赖关系图,但该研究没有使用传统网络度量,而是将依赖关系图中每个节点进行截断的随机游走,从数据中自动学习表示。结果表明,数据的表示形式会极大地影响缺陷预测的性能。Qu等人[115]提出一种node2defect的方法,该方法先构造了分析程序的类依赖网络(Class Dependency Network,CDN),然后使用node2vec自动学习CDN的结构特征。最后将该特征和传统代码度量结合形成新特征,实验结果表明,node2defect方法可以显著提高软件缺陷的预测能力。
与网络嵌入不同的是,一些研究者试图用其他方法对依赖关系图进行学习,Qu等人[116]采用k-core算法分析CDN上的缺陷分布,他们发现具有越大k值的类,有更大几率存在缺陷,根据结果对软件模块的所有类进行排列能帮助测试人员更快速地找到缺陷。田永清[117]将系统依赖图进行程序切片,得到程序结构的向量表示,然后利用门控循环单元神经网络提取网络特征。
一些研究者将语义度量指标和结构度量指标混合使用。Meilong等人[118]用CNN从AST中自动学习语义特征,再基于软件模块之间的依赖关系构建了网络模型,并用node2vec进行随机游走得到结构特征。最后将语义特征和结构特征组合进行缺陷预测,实证结果表明,语义特征和结构特征的混合是目前软件缺陷预测的首选。同样,刘成斌等人[119]基于Apache的三个开源软件项目将语义特征和结构特征进行混合预测,这两项研究为多元度量指标提供了有效的研究思路。
2.3 缺陷预测模型构建
基于语义结构度量指标的缺陷预测的研究重点在提取更合适的度量,为了与传统度量指标进行对比,研究人员对WPDP的模型构建和数据质量部分选择和基于传统度量指标的缺陷预测保持一致,没有改进。
综上所述,研究人员对度量指标的提取进行了大量研究,主要包括传统代码度量、传统网络度量、语义度量、结构度量和其他过程度量。其中,这些度量指标体现了软件模块不同角度的信息,从现有研究来看,混合多元度量指标能使缺陷预测模型最大程度上精确。表4列出了基于语义结构度量指标的研究文献使用的度量指标和数据集。
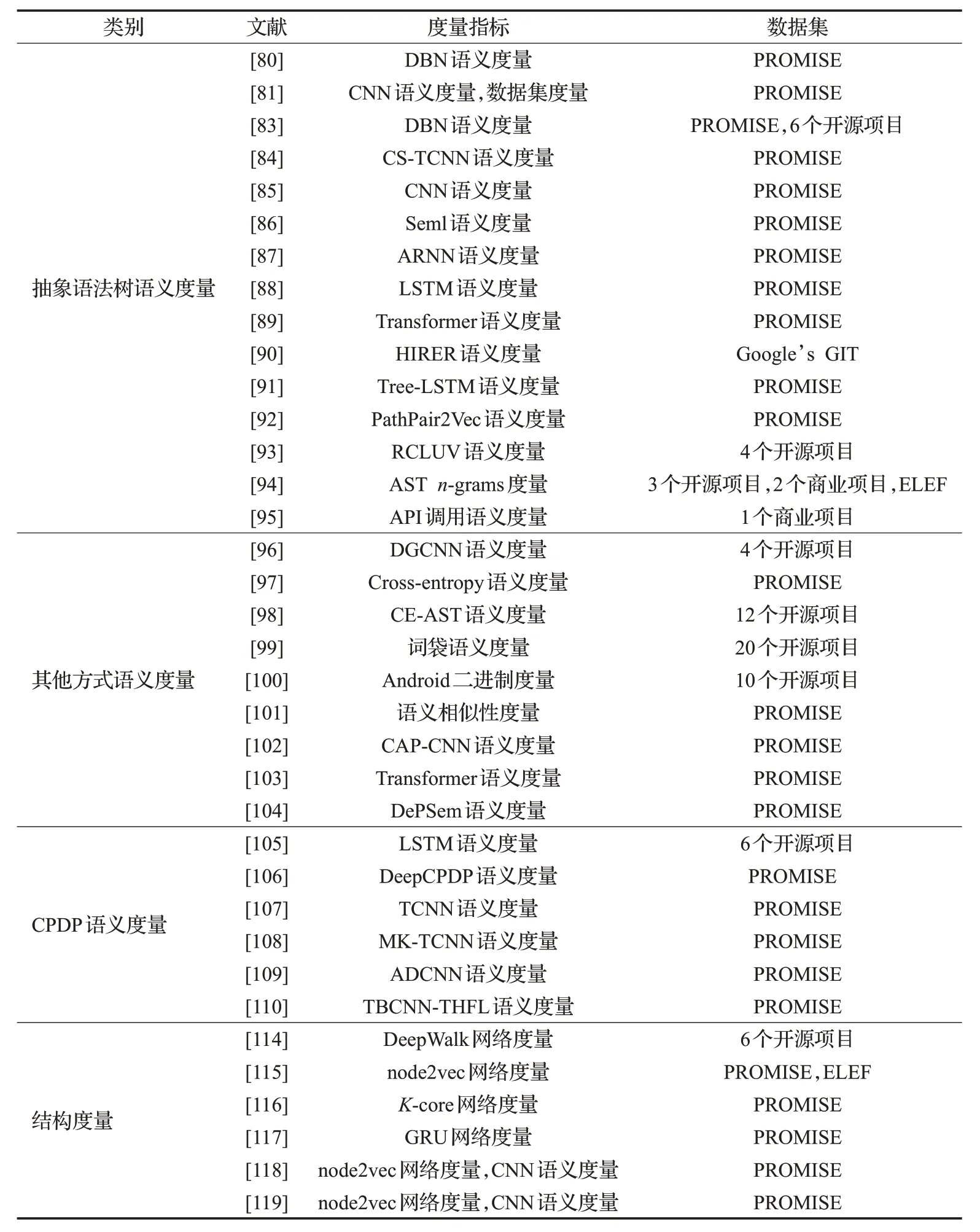
表4 研究文献中度量指标和数据集(二)
3 评价指标
为了判断构建的缺陷预测模型的性能,研究人员提出了多种评价指标,但在实际开发过程中,没有充足的时间和资源审查代码。为了将精力集中在最有可能发生缺陷的模块上,开发人员提出了代价感知(effort-aware)指标。而相对地,机器学习领域常用来缺陷预测模型的指标称为非代价感知(non-effort-aware)指标。表5列出了现有研究中使用最广泛的评价指标。
3.1 非代价感知指标
在非代价感知情况下,最常用的模型性能评价指标是查准率(Precision)、查全率(Recall)、F-measure和AUC[3,7]。

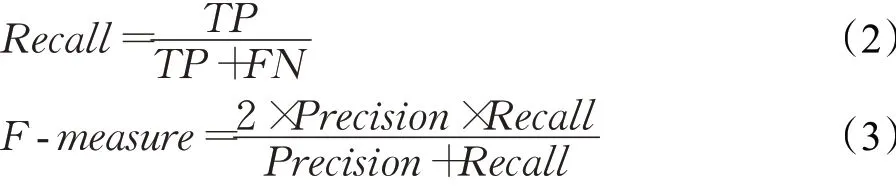
其中,真正例(TP)表示有缺陷模块被分类器正确标记为有缺陷的数量,真负例(TN)表示无缺陷模块被正确标记为无缺陷的数量,假正例(FP)是指无缺陷模块被错误地标记为有缺陷的数量,假负例(FN)是指有缺陷模块被错误地标记为无缺陷的数量。更高的查准率可以让开发人员不将调试工作浪费在无缺陷代码上,查全率越高说明发现的缺陷越多。F-measure是综合调和查准率和查全率的指标,用来衡量缺陷预测的性能。
AUC是ROC曲线下面积,ROC是一个x轴为假正例率,y轴为真正例率的二维曲线,AUC越高,模型性能越好。

表5 评价指标
准确率(Accuracy)表示正确预测实例的百分比。
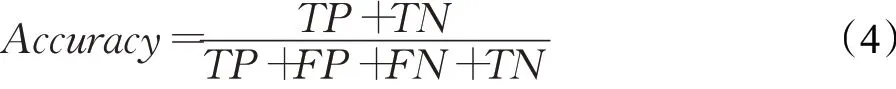
马修斯相关系数(MCC)通过考虑所有真假的有缺陷数据和无缺陷数据来衡量预测结果和真实结果之间的关系。返回值是[−1,1],其中1表示完美正相关,−1表示完美负相关。

3.2 代价感知指标
在代价感知情况下,开发人员通常通过检查代码的前20%行来识别缺陷百分比,性能评价指标是PofB20[26]。首先根据缺陷预测模型为每个实例生成的置信度,并使用置信度对测试数据集中的所有实例进行排序,置信度是指被预测为缺陷的概率。然后,模拟一个开发人员来检查这些潜在的缺陷实例,并累积检查的代码行和发现的缺陷数量。当检查了测试数据中的LOC的20%,并且已发现错误的百分比称为PofB20分数时,该过程将终止。PofB20越高表示在检查有限代码行时,开发人员能检测到的缺陷越多。
另一个广泛使用的代价感知指标是Popt,被定义为1-Δopt,其中Δopt是预测模型和最优模型之间的面积,用来描述两者的偏差,Popt越大预测模型越接近最优模型,标准化的Popt定义如下:

其中,Area(optimal)、Area(pre_model)、Area(worst)分别表示最优模型、预测模型和最差模型对应曲线下的面积。
3.3 统计显著分析方法
统计显著分析方法可以帮助分析两个方法是否有统计学上的显著性差异。
(1)Wilcoxon signed-rank test[120]是一种非参数统计假设测试,用来比较两个相关样本,匹配样本,或对单个样本重复测量,可用于确定是否从具有相同分布的总体中选择了两个相关样本。该测试不需要基础数据遵循任何分布,另外,它可以应用于数据对,并且能够将差值与零进行比较。在95%置信水平下,p值小于0.05表示受试者之间的差异具有统计学意义,而p值大于或等于0.05则表明差异在统计学上不显著。
(2)Scott-Knott ESD test[121]是一种使用层次聚类算法进行统计分析的多重比较技术。本测试将方法进行排序和聚类,分为差异显著的组,同一组的方法无显著差异,不同组的方法有显著差异。该测试的优点是,它产生完全不同的组,没有任何重叠。
(4)Friedman test[123]是一种非参数统计测试,它是基于绩效值而不是实际值的排序,测试统计量由下式给出:
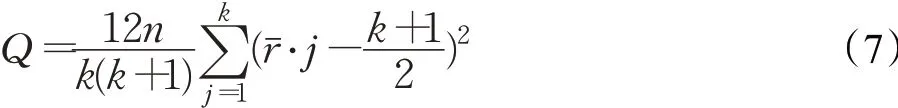
其中,n表示数据集的项目总数,k表示特征选择方法的总数表示第i个方法在第j个项目排名。
3.4 其他指标
(1)CEπ成本效益[124]是如何有效地使用并行计算来解决特定问题的指标。标准化的成本效益指标为:
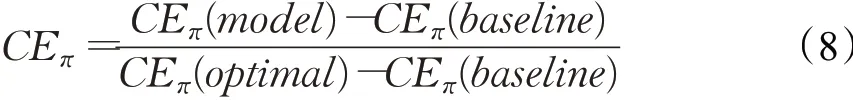
(2)Win/Tie/Loss用于不同实验设置之间的性能比较,当对目标项目数据集重复实验1 000次时,若模型的性能优于相应基线结果,标记为“Win”,当基线结果更好时,标记为“Loss”,如果模型和基线之间没有差异,标记为“Tie”,根据Win/Tie/Loss评估的结果,可以改进模型。
4 结束语
准确的软件缺陷预测保证了软件可靠性、提高了软件测试效率,本文从多元度量指标角度总结了当前软件缺陷预测的相关工作,并列举了部分具有代表性的研究文献。尽管在软件缺陷预测方面已经进行了很多研究,仍存在许多潜在的挑战。在这里,对未来研究工作进行展望。
(1)预测粒度的研究展望
现在的研究粒度大部分是文件级,由于文件的长度,开发人员需要很长时间才能找到缺陷,如果发生误报,会过多地浪费资源,所以需要缩小预测的缺陷的范围。更细粒度的预测可以为开发人员提供更少的代码行,其中方法级缺陷预测有助于预测软件项目中带有缺陷的方法,但是构建方法级缺陷预测模型仍然是一个挑战。
(2)传统软件度量指标的研究展望
过去几十年,研究人员提出了大量的传统代码度量和过程度量,但是冗余和无关度量指标降低模型性能,为了使模型更精确,他们将多种度量指标组合并试图从软件历史仓库中提取更能体现缺陷的新的度量指标。如何提出合适的指标仍需要进一步研究。
(3)基于深度学习的软件度量指标的研究展望
近年来,语义度量代替了传统代码度量,许多研究表明语义度量构建的缺陷预测模型比传统代码度量预测得更准确。用深度学习直接从源代码中学习语义表示过程,为了将源代码馈入深度学习模型,通常会损失一些语义信息,哪种方式可以最小限度地减少损失需要进一步研究。
(4)跨项目软件缺陷预测度量指标的研究展望
对于新项目或缺少足够历史数据的项目,研究和使用语义度量来预测缺陷非常有意义。由于源项目和目标项目之间存在不同的数据分布,因此难以建立可实现令人满意性能的良好缺陷预测模型。此外,CPDP方面的语义度量提取只是简单地迁移了WPDP的方法,没有针对数据分布问题进行更好的可行性研究,若能针对该问题进入深入研究,则可以为CPDP方面提供更好的缺陷预测模型。
