联合罪名预测的涉案新闻重叠实体关系抽取
2021-03-09张明芳余正涛郭军军高盛祥线岩团
张明芳,余正涛,郭军军,高盛祥,线岩团
(昆明理工大学 1.信息工程与自动化学院;2.云南省人工智能重点试验室,云南 昆明 650500)
涉案新闻实体关系抽取作为司法领域信息抽取[1]的重要组成部分,是构建案件知识图谱的基础。相比通用领域,涉案新闻中的实体是指被告人、被害人和作案地点等与案件相关的人名、地名、机构名,关系是这些实体之间的相互联系,比如被告人和被害人之间的关系定义为“被告人-被害人”。在涉案新闻句级文本中,普遍存在多个关系,并且不同关系的关联实体有重复,这类关系被称作重叠实体关系。例如图1所示,句子中有“被告人-被害人”和“被告人-作案地点”两个关系,“程华”是关系“被告人-被害人”的源实体,也是关系“被告人-作案地点”的源实体。准确抽取出重叠实体关系,是涉案新闻实体关系抽取研究的难点。
针对重叠实体关系抽取任务,Zeng等[2]提出基于复制机制的端到端模型,解码器从源句复制实体词,不同的实体关系三元组由不同的解码器生成。Takanobu等[3]提出一种通过定位关系指示符来抽取重叠实体关系的方法。关系指示符是指句子中的一个位置,在这个位置有足够的信息来识别语义关系,并依照该语义关系识别相关联的实体对。
从以上分析可知,重叠实体关系抽取的效果依赖于是否准确定位关系指示符。在涉案新闻中,存在误导定位关系指示符的干扰词,且预测罪名的关键词是定位关系指示符的重要依据。因此融入罪名信息可以使模型在定位关系指示符时增强对关键词的敏感性,进而减少干扰词所带来的影响。例如图1所示,干扰词“骚扰”和“辱骂短信”将关系“被告人-被害人”的指示符定位为“辱骂短信”之后的“,”,并错误抽取出源实体“刘兴荣”和目标实体“程华”。“打伤”是预测罪名“故意伤害罪”的关键词,同时也是正确定位关系“被告人-被害人”的指示符的重要依据,因此在抽取重叠实体关系时引入“故意伤害罪”能够指导模型将“被告人-被害人”关系的指示符准确定位到“打伤”之后的“。”位置,并正确识别出关系对应的源实体“程华”和目标实体“刘兴荣”。

图1 重叠实体关系及罪名与实体关系之间的联系举例
基于以上分析,本文提出一种联合罪名预测的涉案新闻重叠实体关系抽取方法,使用罪名预测的结果指导重叠实体关系抽取。为了缓解因联合罪名预测而对重叠实体关系抽取带来的错误传播,本文使用了一种分层级联的强化学习机制,将罪名预测和重叠实体关系抽取视为两个交互的强化学习任务,并将重叠实体关系抽取任务分为关系抽取主任务和实体识别辅任务,辅任务服务于主任务。罪名首先指导主任务抽取出关系,然后指导辅任务依照该关系识别关系的关联实体对,并将辅任务的结果视为主任务关系抽取的验证,不同关系的实体识别辅任务相互独立,有效抽取重叠实体关系。完成重叠实体关系抽取后,将结果反馈给罪名预测任务优化罪名预测的强化学习策略。
1 相关工作
命名实体识别[4]和关系分类[5]是构建知识图谱[6]的重要组成步骤,对许多自然语言处理任务都有帮助,目前有流水线和联合学习两种主要框架。
流水线抽取方式[7]是将实体关系抽取模型分为命名实体识别和关系分类两个独立的子任务,首先在文本中检测实体,然后发现实体之间的关系[8]。流水线方式虽然灵活,但下游任务容易受到上游任务错误传递的影响[9],并且未考虑两个任务之间的内在联系和依赖关系。
联合学习抽取方式包括共享参数[10]和联合解码[11]两类联合抽取模型。共享参数的联合抽取模型通过共享参数实现联合,例如Miwa等[12]提出首先检测实体,然后检测实体之间的关系,并使用实体和关系标签共同对神经网络参数进行解码更新。共享参数的联合抽取模型对子模型没有限制,但由于使用独立的解码算法,导致实体模型和关系模型之间交互不强。联合解码的抽取模型通过共享解码实现联合,加强了实体模型和关系模型的交互,需要在子模型特征的丰富性以及解码的精确性之间做权衡。例如,Dai等[13]提出一种根据查询词位置P标记实体和关系的标签的方法,实体识别和关系抽取共享同一个模型;Zheng等[14]将联合抽取任务转化为标签问题,然后基于该标签问题研究了不同端到端模型来直接抽取实体及其关系。联合学习的方法将两个子模型统一建模,因此可以进一步利用两个任务之间的潜在信息[15,16],以缓解流水线方法错误传播的缺点。
强化学习在实体关系抽取任务中得到广泛的应用,例如,Feng等[17]针对远程监督获得的训练数据噪声大的问题,使用通过强化学习训练的实例选择器对数据去噪,在进行关系分类。Qin等[18]在远程监督关系抽取中,通过强化学习,将假正例样本重新分配到负例样本中。
在目前已有的实体关系抽取研究中,大部分只关注实体之间的单关系抽取,而涉案新闻句级文本中普遍存在重叠实体关系。因此,本文将实体识别看做是关系抽取的验证,提出联合罪名预测的涉案新闻重叠实体关系抽取方法,罪名不仅帮助检测关系指示符,还指导识别关系的关联实体。
2 联合罪名预测的涉案新闻重叠实体关系抽取方法
本文提出联合罪名预测的涉案新闻重叠实体关系抽取方法,将罪名预测和重叠实体关系抽取视为两层交互的强化学习模型,并将重叠实体关系抽取层分为关系抽取的主模块和实体识别的辅模块。罪名预测层预测出的罪名指导重叠实体关系抽取层主模块检测关系指示符预测关系,每预测到一个关系,启动辅模块依照关系以罪名作为指导,识别关系的关联实体对。将辅模块的实体识别结果反馈给主模块作为关系的验证,不同时刻预测出的关系的实体识别辅模块相互独立,有效处理重叠实体关系。当重叠实体关系抽取任务完成,将结果反馈给罪名预测层优化罪名预测的强化学习策略。
模型框架如图2所示,Agent首先在罪名预测层通过扫描整个文本预测出罪名c。

图2 模型整体框架图
罪名c指导重叠实体关系抽取层的关系抽取主模块逐字扫描句子在一个特定位置定位关系指示符预测关系类型,这种关系抽取方法不同于关系分类,不需要对实体进行标注,可以理解为寻找足够的信息预测关系类型。当某时间步骤t找到足够的信息确定一个关系ot时,Agent依照ot以罪名c指导辅模块启动实体识别任务,可以看作是为文本逐字打标签,根据标签(α1,α2,…,αL)即可知道关系ot所对应的关联实体对,并将结果反馈给主模块,主模块通过将该结果用作关系抽取的验证进而优化关系抽取强化学习策略。当实体识别辅任务完成,Agent返回到主模块从当前位置开始扫描抽取下一个关系,并触发下一个实体识别辅任务,不同时间步骤预测出的关系的实体识别辅任务相互独立,当主模块扫描到句末,结束整个句子的重叠实体关系抽取。并将重叠实体关系抽取层主模块抽取出的关系和辅模块识别出的实体反馈给罪名预测层优化罪名预测强化学习策略。图中虚线箭头代表强化学习的反馈机制,r代表与反馈机制相关的奖励,下文将分别详细介绍。
联合罪名预测的涉案新闻重叠实体关系抽取模型如图3所示,下文将详细介绍模型的实现过程。

图3 联合罪名预测的涉案新闻重叠实体关系抽取模型
2.1 罪名预测层

(1)状态。状态S由整个文本的隐状态H最大池化后经过非线性激活函数得到。将其表示为
(1)

(2)
(3)
(4)
H=(h1,h2,h3,…,hL)
(5)
(2)选项。选项c从ε={NC}∪C中选择,NC代表无罪名,C是罪名的集合。不管Agent做何选择,都立即被接管到重叠实体关系抽取层执行相关任务。
(3)策略。罪名预测的随机策略λ:S→c,用于指定选项的概率分布,最后根据该概率分布选择概率最大的选项c作为强化学习的动作
c~λ(c|S)=softmax (WλS)
(6)
式中:S为状态,c为预测出的罪名,Wλ为可学习参数。
(4)奖励。Agent提供标量中间奖励来估计罪名c未来的回报,并通过最大化预期累积奖励来优化策略函数λ,奖励计算如下
(7)
(8)

(9)

2.2 重叠实体关系抽取层
在重叠实体关系抽取层,目的是从涉案新闻句级文本中抽取出包括重叠实体关系在内的所有实体关系。本文通过联合罪名预测和将实体识别看做关系抽取的验证,优化了关系抽取主模块策略,进而有效解决重叠实体关系抽取问题。Agent以罪名作为指导,扫描句子在适当位置预测关系,当时间步骤t预测出一个关系后,Agent启动实体识别辅模块依照关系并以罪名作为指导为每一个字打标签,并将标签结果反馈给关系抽取主模块验证关系的合理性。完成辅任务后,Agent又被接管到关系抽取主模块进行下一时间步骤的关系预测。不同时间步骤预测到的关系的实体识别任务相互独立,使一个实体可以被多次识别,有效抽取重叠实体关系。下文将分别介绍关系抽取主模块和实体识别辅模块。
2.2.1 关系抽取主模块

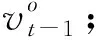
(10)

(2)选项。选项ot在集合ϑ={NR}∪R中选择,其中,NR代表不存在关系,R代表定义的关系集合。在某个时间步骤,如果没有足够的信息表明一个关系存在时,Agent选择NR。否则确定一个关系并触发实体识别辅任务,当实体识别任务完成,Agent继续被关系抽取模块接管去执行下一个选项,直到句末。
(11)

(4)奖励。关系抽取模块提供给Agent的t时刻的关系抽取层自身的奖励,由该时刻预测出的关系与金标注比较得到。计算如下
(12)
涉案新闻句级文本普遍为含有两个重叠实体关系的数据,且训练模型时不使用没有关系的数据,因此,通过经验设计了如上奖励参数。本文认为当关系名称预测正确且关系对应的原实体和目标实体的开始位置定位准确,则正确抽取出一个关系。最后用一个最终奖励来评价一个句子的抽取效果
(13)
式中:ST指一个句子所有时间步骤的实体关系抽取模块状态集合。Fβ(ST)是指整个句子重叠实体关系抽取的精度p和回收率r加权平均值,β指权重,取0.1。
2.2.2 实体识别辅模块

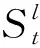
(14)

(2)选项。每一个时间步的选项是为当前字分配对应的标签,标签包括A=({S,T,O}×{B,I})∪{N},其中S和T分别代表与关系相关联的源实体与目标实体,O代表与该关系无关的实体,N代表非实体字,B和I分别代表实体的开头字与非开头字。同一实体可以根据目前所涉及的不同关系类型分配不同的标记,因此可以处理重叠实体关系。有关示例,请参见图4。

图4 实体标签示例
o
t′
a
t
(15)
式中:Wπ[ot′]为关系ot′对应的关联实体标签预测时softmax分类的可学习参数。
(4)奖励。由罪名预测层预测的罪名和主模块抽取的关系,Agent通过该模块策略采样,得到每个字的实体标签。因此,在对动作进行采样时,通过将采样结果和金标注进行比较提供即时奖励
(16)
式中:sgn(·)为符号函数,yt为关系o的金标准实体标注。这里,Φ(yt)为非实体标记的向下偏置权重函数,定义如下
(17)

2.3 强化学习策略优化

(18)
式中:T为该罪名所指导的关系抽取主任务的总时间步长,T′为该罪名指导下的基于当前关系的实体识别辅任务的总时间步长。
为了优化重叠实体关系抽取层关系抽取主模块的强化学习策略μ,本文的目标是最大化当前时间步骤t,Agent遵循策略μ的动作的预期累积回报J(θμ),计算如下
(19)

类似地,当Agent在关系抽取模块抽取出一个关系ot后,沿着实体识别辅模块策略π采样时,通过最大化当前时间步骤t′遵循策略π的预期累积回报J(θπ)来优化实体识别强化学习策略π
(20)
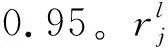
通过将未来预期累积奖励分别分解为贝尔曼方程,得到三个任务的当前期望最大奖励分别为
(21)
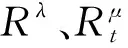
然后使用策略梯度方法去分别优化每一个模块的策略。利用似然比技巧,罪名预测层、关系抽取主模块、实体识别辅模块的策略梯度分别为
(22)
3 试验
3.1 数据集
本试验使用的语料来自于各司法新闻网站,将语料爬取下来清洗过后进行分句,对句子进行人工标注,标记出罪名、关系以及关系的实体对,最后得到22 860条数据,数据汇总如表1所示。
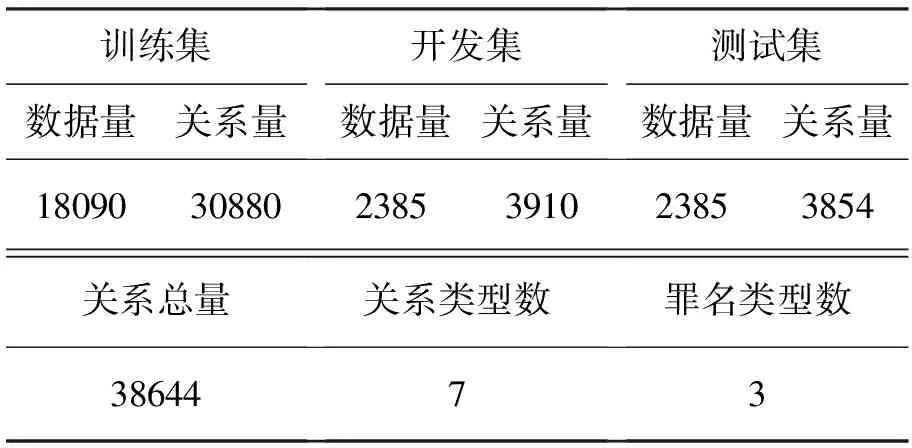
表1 试验语料统计
随机抽取80%作为训练集,10%作为开发集,10%作为测试集。为了保证数据的均衡,三种数据集关系量和数据量的比例基本一致。
本文定义了无罪和和涉案新闻中最常见的3种罪名,涉案新闻中对构建案件知识图谱有意义的7种实体关系,如表2和表3所示。

表2 罪名类别数量统计
3.2 参数设置
所有超参数都在开发集上调优,所有状态向量的维度均为300维,罪名向量、关系类型向量和实体标签向量随机初始化,优化算法采用Adam算法,学习率取0.000 01,dropout系数取0.5,奖励参数均由经验所得,训练批次大小取16,测试批次大小取64,epoch取15。
3.3 评价指标
本文使用准确率(p),召回率(r),F1值(F1_score)作为评价指标。其中,F1_score计算方式为
F1_score=2*p*r/(p+r)
(23)
当关系名称预测正确,并且准确定位与关系相关联的源实体和目标实体开始位置时,本文认为正确抽取出一个关系。
3.4 基线模型
本文选择了5个实体关系联合抽取模型进行试验对比,其中包括基于特征的方法CoType和神经网络的方法CopyR、Tagging、ATT+LSTM、SPTree。
CoType[19]:通过运行一种数据驱动的文本分割算法来提取实体提及,并同时将文本特征和类型标签嵌入到两个低维空间,分别用于实体提及和关系提及。
CopyR[2]:解决重叠实体关系抽取。提出一种基于复制机制的的端到端学习模型,可以从任意一个类的句子中联合提取相关关系。在译码过程中,采用了两种不同的译码策略:一种是联合译码器,另一种是多个独立译码器。
Tagging[14]:通过一种新的标注方案联合提取实体和关系,将提取问题转化为标注任务。并使用了具有偏置损失函数的端到端模型来适应新标注模式,增强实体之间的关联。
ATT+LSTM[20]:利用双向长短期记忆网络Bi-LSTM和词向量级别attention神经机制来捕捉句子中最重要的语义信息,可以自动聚焦于对分类有决定性影响的词语,并将该句子级特征向量用于关系分类。
SPTree[12]:一种端到端神经网络模型,通过在双向序列LSTM-RNNs上叠加双向树型结构来捕获单词序列和依赖树的子结构信息。
3.5 试验结果
为了验证方法的有效性,本文做了以下4组试验。(1)将本文模型和几个模型进行比较,验证了在普遍具有重叠实体关系的涉案新闻数据集中,本文模型具有很大优势;(2)进行消融试验,验证罪名分别从直接协助关系抽取和通过指导实体识别间接协助关系抽取两方面有效提高重叠实体关系抽取的准确性,并且当同时作用于实体识别和关系抽取两个模块时取得最好效果;(3)进行罪名预测的准确性试验,验证重叠实体关系抽取层的反馈对罪名预测层有很大的促进作用;(4)列举了3个输入输出实例,证明本文的方法可以处理多种场景下的问题。
试验1:将不同的模型作用到涉案新闻数据集上,结果如表4所示。
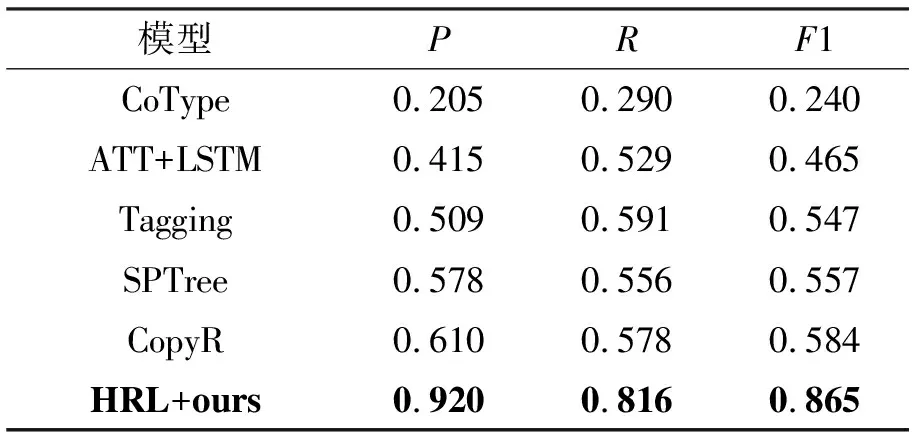
表4 不同方法的试验结果
分析表4可知,基于特征提取的方法CoType的F1值仅达到0.240,基于神经网络的方法普遍优于基于特征提取的方法。本文模型F1值取得0.865的结果,高出ATT+LSTM、Tagging、SPTree各0.401、0.318、0.308。在涉案新闻数据集上,ATT+LSTM将句子级特征用于关系分类,每一个句子只能得到唯一一个关系。Tagging为实体分配唯一标签,句子中的每一个实体仅被识别一次,因此只能抽取出实体没有重复的关系。SPTree仅将一种关系与实体对配对,只能抽取出句子中唯一一个关系。CopyR在抽取重叠实体关系上取得了不错的结果,但该方法强烈依赖标注过的噪声训练数据,本文使用的涉案新闻数据集没有对噪声数据进行标注,F1值比本文模型低了0.281。本文模型得益于联合罪名预测和以实体识别作为关系抽取的验证的方法,在涉案新闻句级重叠实体关系抽取任务上达到了最优的效果。
试验2:消融试验。本文分别将不联合罪名预测、仅将罪名作用于关系抽取主模块、仅将罪名作用于实体识别辅模块、将罪名作用于关系抽取主模块和实体识别辅模块4个方法进行对比,对比结果如表5所示。

表5 消融试验结果
分析表5可知,罪名分别对关系抽取和实体识别都有指导作用,当罪名只作用于关系抽取主任务时F1值为0.839,比不联合罪名高出0.014,说明罪名有效帮助准确定位关系指示符。当罪名只作用于实体识别辅任务时F1值为0.852,比不联合罪名高出0.027,罪名通过作用于实体识别辅任务进而协助关系抽取主任务的方法,比直接作用于关系抽取主任务效果更好,这不仅说明罪名对实体识别具有很大的指导作用,还说明本文使用的实体识别辅助关系抽取方法的有效性。当罪名不仅作用于关系抽取主任务还作用于实体识辅任务时达到最好的效果,此时F1值为0.865,比不联合罪名预测高出0.04。
试验3:罪名预测的准确率试验。将不反馈重叠实体关系抽取层的结果、只反馈关系抽取模块的结果、只反馈实体识别模块的结果和同时反馈关系抽取模块和实体识别模块的结果4个试验进行比较,试验结果如表6所示。
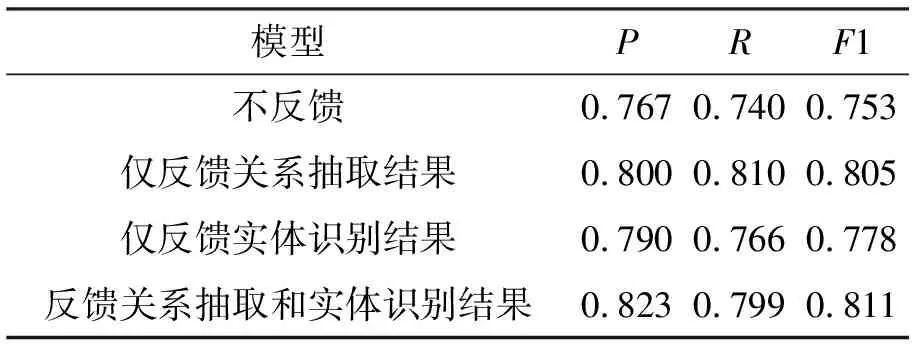
表6 罪名预测结果试验
分析表6可知,当不反馈重叠实体关系抽取的结果时,无延迟奖励,此时F1值仅达到0.753。当仅反馈关系抽取结果时,只计算关系抽取模块对于罪名预测的延迟奖励,此时F1值为0.805比不反馈高出0.052。当仅反馈实体识别结果时,只计算实体识别对于罪名预测的延迟奖励,此时F1值为0.778,比不反馈高出0.025。当反馈整个重叠实体关系抽取层抽取出的关系和实体时,不仅计算关系抽取对罪名预测的延迟奖励,还计算了实体识别对罪名预测的延迟奖励,此时F1值为0.811,比不反馈高出0.076。综上所述,实体识别和关系抽取对罪名预测都有正反馈作用,当同时将两者反馈给罪名预测层时,获得最好效果。
试验4:模型抽取结果示例。列举了3个在不同场景下模型的抽取结果。证明罪名对实体识别和关系抽取的指导作用且模型能够抽取重叠实体关系。
如表7所示,场景1,当存在“骚扰”和“辱骂短信”等对关系的关联实体对识别产生误导的信息时,罪名“故意伤害罪”可以帮助将“被告人-被害人”关系的关联实体对定位到“打伤”附近,进而正确识别出来。场景2,当罪名预测与关系抽取共用相同的信息“偷走”等,罪名“盗窃罪”可以帮助更准确的定位“被告人-被害人”的关系指示符。场景3,尽管实体“罗某某”不仅是“被告人-被害人”关系的目标实体,还是“其他关系”的源实体,本文模型依然能将这两个关系以及关系的关联实体对正确抽取出来。

表7 模型抽取结果示例
4 结论
针对涉案新闻中的重叠实体关系抽取任务,本文提出一种联合罪名预测的涉案新闻重叠实体关系抽取的方法,整体模型基于级联强化学习,通过在重叠实体关系抽取中融入罪名,解决涉案新闻中关系指示符定位不准确问题,有效提高涉案新闻句级文本中重叠实体关系抽取的准确性。在未来工作中,基于涉案新闻的数据特点,将致力于解决涉案新闻篇章级的重叠实体关系抽取。
