融合运动特征和深度学习的跌倒检测算法
2021-03-07曹建荣吕俊杰武欣莹杨红娟
曹建荣,吕俊杰,武欣莹,张 旭,杨红娟
(1.山东建筑大学信息与电气工程学院,济南 250101;2.山东省智能建筑技术重点实验室(山东建筑大学),济南 250101)
(*通信作者电子邮箱junjielv123@163.com)
0 引言
跌倒是老人伤害死亡的首要因素,现阶段对老人异常检测的研究工作主要集中在跌倒检测上。现有的跌倒检测方式主要有基于可穿戴式、基于环境式、基于计算机视觉三种。可穿戴式跌倒检测使用的传感器类型有加速度传感器、压力传感器、音频传感器等,这种方法由于外界噪声的各种干扰和系统本身的稳定性等原因导致误报警问题一直得不到很好解决;而且可穿戴式传感器需要老人长期佩戴,舒适感差。基于环境式摔倒检测系统需要预先把传感器(红外线、超声波等非视觉传感器)布置在人体活动环境里,不需要随身携带,可以解决舒适感差的问题,但是价格昂贵、干扰较大[1-4]。计算机视觉的跌倒检测则无需穿戴,不会影响人体活动,具有实时性好、成本更低、检测准确度更高的特点。Foroughi 等[5]利用椭圆来近似表达人体,把椭圆的长短轴的标准差作为特征,并把人体的投影直方图与头部位置作为一个特征,然后使用深度学习方法对这些特征分类,再根据特征判断出人体的状态。Miaou 等[6]利用全景相机来采集视频图像,利用背景差分法来提取目标特征,利用最小外接矩形来包围目标人体,并利用矩形的宽度高度判断是否跌倒。Rougier等[7]利用人体形状来做跌倒检测,先利用混合高斯模型(Gaussian Mixture Model,GMM)算法进行目标检测,再利用阈值法进行跌倒检测。沈秉乾等[8]利用分级法进行人体检测:第一级通过宽高比判断是否为直立状态;第二级通过支持向量机(Support Vector Machine,SVM)分类判断是蹲下还是跌倒状态。马露等[9]提出一种改进的FSSD(Feature Fusion Single Shot Multibox Detector)跌倒检测方法。Gammulle 等[10]将卷积神经网络(Convolutional Neural Network,CNN)卷积层和全连接层学到的特征信息输入长短期记忆(Long Short-Term Memory,LSTM)网络中,接着学习这些空间特征的时序相关性,最终输出人体行为识别数据。Núñez-Marcos 等[11]利用RGB计算光流信息,并利用VGG16对光流信息进行分类和跌倒检测。申代友等[12]提取人体的多个关节点位置,根据多个连续帧之间人体关节点的运动变化特征判定老人是否发生跌倒行为。袁智等[13]提出了一种由两路CNN 融合组成的双流卷积神经网络(Two-Stream CNN)的跌倒识别方法。
由以上可知,基于计算机视觉的检测方法需要进行两步:1)目标提取;2)对提取目标进行判断。利用背景差分、高斯混合等前后景分离的方法对运动状态目标进行提取具有一定的局限性,因为当人体运动缓慢或者人由运动状态变为静止后会造成目标丢失,而且当有其他非人类运动时会造成目标混淆,将非人体运动误判为人体运动。利用阈值法或分级法进行人体跌倒判断只利用了人体的运动信息而没有利用图像本身的内容特征,利用CNN 或SVM 分类进行跌倒判断虽然利用了图像本身的信息,但丢失了运动信息,在光照变化时会对准确性产生一定影响。针对上述问题,为了适应在视频监控中的人体目标检测,对YOLOv3 主干网络进行裁剪,根据全局密集残差网络特征提取的优势和人体跌倒视频监控中运动目标分析的实际情况,提出了局部密集型残差网络结构,并将局部密集型残差引入特征检测主干网络;然后分析了跌倒过程中人体运动目标在时间序列上的变化情况,提取了表示人体摔倒过程中的运动特征信息,接着针对视频序列中的每一帧的运动图像描述,设计了一个八层的CNN 自动提取运动图像描述特征信息,利用全连接层具有特征融合的特性,将运动特征信息引入到图像描述特征信息中进行融合。
1 人体目标检测
1.1 二分K-means提取候选框
YOLOv3 中Grid cell 预测的三个初始候选锚框(anchor box)的维度(宽、高)通过K-means 聚类方法确定[14-16]。K-means 算法随机选取K个质心作为初始质心的处理方式会使初始聚类中心选到同一个类别上,导致算法陷入局部最优状态。传统K-means 算法度量函数采用欧几里得距离,M维空间中两个向量X、Y之间的欧氏距离公式如下:

采用式(1)度量函数会影响模型对小框的预测结果,为此采用以下改良的度量函数:

其中:d表示候选框与真实框中心坐标之间的距离;RIOU表示候选框与真实框两者之间面积的交集与并集的比值,即交并比(Intersection over Union,IOU)。
与K-means算法不同,二分K-means加入了用于度量聚类效果的误差平方和(Sum of Squared Error,SSE)评价指标作为分类依据,能够加速分类且收敛于全局最小点,减小分类误差,故本文用二分K-means 算法对样本目标框维度进行聚类,步骤如下:
步骤1 由式(4)初始化聚类中心C;由式(1)算出每个初始矩形框到初始聚类中心C的距离d;

其中:N是样本候选矩形框的数目,hi是第i个候选矩形框的高度,wi是第i个候选矩形框的宽度。初始距离中心C由所有视频帧样本候选框的长宽求均值确定。
步骤2 将初始样本候选框利用K-means 算法分成两个簇。
步骤3 利用式(5)计算每个簇的误差平方和(SSE),选取最大误差平方和的那一簇利用K-means进行二分类。

其中:ki是第k个簇的第i个样本,ck是第k个簇的聚类中心;表示第k个簇的聚类中心所表示的矩形框与第k个簇中第i个样本所表示矩形框的面积比值。
步骤4 重复步骤3直到达到所需K个类。
图1 是二分K-means 和K-means 算法的IOU 对比,横坐标K表示样本集需要分为几类(簇),纵坐标表示IOU 变化。从图1 中可以看出,K取不同值时,二分K-means 聚类所得的交并比要优于K-means聚类的交并比,利用二分K-means能够更好地对目标维度进行聚类,获得与真实框更加接近的IOU。
1.2 特征提取
1)YOLOv2 的主干网络是darknet-19,由卷积层(19 层)和最大池化层(5 层)交替组成,网络结构简单,且算力资源消耗较少,但最大池化的加入使信息特征在前向传递时会逐层丢失,导致检测精度下降。
2)Huang 等[17]在CVPR2017 上对残差网络ResNet 进行了改进,提出了一种具有密集连接的卷积神经网络DenseNet,该论文获得了当年的最佳论文。该方法将每一层与前面所有层进行通道连接,并作为下一层的输入。由于连接了前面所有层的信息,因此可以减轻梯度消失现象,网络结构变得越来越紧密,它的第n层输出为:

其中:xn表示[x0,x1,…,xn-1]将0 到n-1 层输出的特征图进行级联,Hn表示网络非线性变换。这样的全局密集型连接方式会造成信息的冗余,因此本文将全局密集连接改为局部密集连接,即将每一层的前面三层直接连接输入层与损失层而非连接前面所有层的输入层与损失层。
3)YOLOv3 主干网络darknet-53 提取特征时,网络结构较深,增加网络深度即增加检测时间,本文只检测人体这一类目标,其检测目标明确且类别少。
综合以上三点,本文设计了如图2 所示的人体目标检测特征提取网络。

图2 人体目标检测特征提取网络Fig.2 Feature extraction network of human body object detection
图2 所示网络以darknet-19 为基础,借鉴YOLOv3 网络和DenseNet结构,在darknet-19主干网络中引入局部密集型残差结构,提出了darknet-21 主干网络,实现了网络多层特征的复用和融合,避免了全局DenseNet 引起的特征冗余,满足人体特征提取的快速性和精确性。去掉darknet-19 中的最大池化层,用卷积层进行2 倍下采样方法代替原最大池化层的下采样,这样能够缩小特征图尺度以提取细腻特征信息传递给后续卷积层。为了方便与检测层相融合连接,去掉darknet-19最后一层卷积层,保留其余各卷积层;在darknet-19 的第2 层卷积层后添加两层卷积层以构建一个局部密集型残差模块,由此构成由21 层卷积层顺序连接的主干网络。借鉴密集型残差思想构建局部密集残差模块,通过恒等映射、局部跳跃连接其前层卷积输出特征信息,将其直接传递给后面某层输出,以进行信息融合。
2 运动目标特征分析
本文提出了基于几何运动特征与CNN 融合的人体跌倒分类器,结合人体运动形态学先验特征和CNN卷积特征进行室内人体跌倒检测。
2.1 运动目标特征
视频帧中根据人体跌倒过程中的倾斜方向不同可分为横向跌倒和纵向跌倒两种情况,图3和图4分别为人体横向和纵向跌倒过程的运动特征示意图,图(a)、(b)、(c)分别表示跌倒过程中的三个状态,图中水平方向定义为X方向,垂直方向定义为Y方向,通过对跌倒过程中人体的不同姿态进行分析得到矩形宽高比、质心高度、躯干倾斜角三个运动状态特征。

图3 横向(水平)跌倒运动特征示意图Fig.3 Schematic diagram of horizontal fall motion features

图4 纵向(垂直)跌倒运动特征示意图Fig.4 Schematic diagram of vertical fall motion features
1)矩形宽高比。
将目标框的四个顶点按顺时针方向依次命名为R1(x,y),R2(x,y),R3(x,y),R4(x,y),利用四个顶点的坐标由欧氏距离公式可以计算出目标框的宽度W和高度H:
不同的照射数目,90%等剂量线所覆盖PTV剂量分布状况一样,靶区剂量的分布受照射野数目的影响不大,90%体积的PTV接受最低剂量是50 Gy。靶区以外卷入正常组织的5野布野比9、7野布野多,其中9野布野最少,脊髓保护5野低于7、9野。
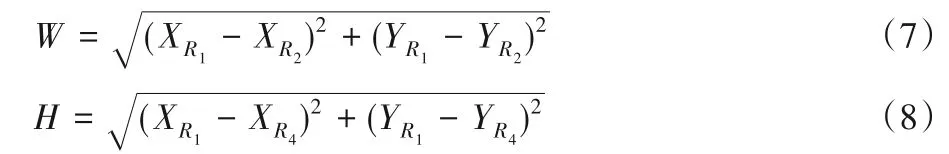
无论是横向跌倒还是纵向跌倒,当视频帧中的人体正常站立时,W<H;当人体由站立逐渐跌倒时,W的值会逐渐增大,H的值会逐渐减小,如图3(c)所示,当人体横向跌倒时,W>H;如图4(c)所示,当人体纵向跌倒时,目标框宽度W小于等于目标框高度H。为了更好地描述不同倾斜方向导致跌倒过程中目标框宽度与高度的变化情况,本文用目标框宽度W与高度H的比值Q作为人体跌倒(横向、纵向)判断的一个特征:

2)人体质心高度。
当人体由站立状态逐渐摔倒的过程中,人体的质心是逐渐变化的,将人体目标框的对角线进行连接,则交点即为人体的质心Z,如图3、4 所示,找出R3(x,y)和R4(x,y)横纵坐标的较大值,经过较大值在水平方向画一下水平线L,将质心Z与水平线L的垂直距离记ZL,用ZL来描述人体质心的变化情况。当人体由站立状态逐渐摔倒时,ZL的值会逐渐减小,因此,运动质心高ZL的变化可以作为人体跌倒判断特征。
3)人体躯干倾斜角。
如图3、4 所示,当人体处于不同的状态时,人体躯干与视频帧图像水平方向会呈现不同的角度,对于目标框顶点R3(x,y)和R4(x,y),由几何关系可以确定人体躯干倾斜角θ:
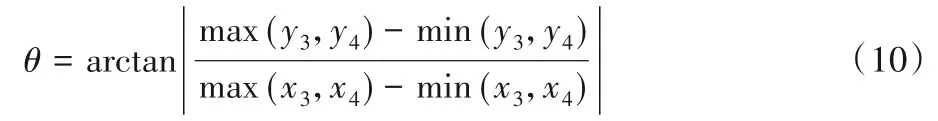
为了更好地说明以上三个特征的运动变化情况,从跌倒检测公开数据集Le2i中分别提取横向、纵向跌倒各90 帧片段进行分析,图5(a)表示横向跌倒各运动特征的变化情况,图5(b)表示纵向跌倒各运动特征的变化情况,图中横轴对应视频片段的视频帧序列号,其中0~29帧表示站立,30~59帧表示下蹲,60~89 帧表示跌倒,纵轴分别代表对应视频序列号的各个运动特征的值。

图5 横、纵向跌倒运动特征变化Fig.5 Changes of horizontal and vertical motion features
由图5 可以看出,无论是横向跌倒还是纵向跌倒,站立与跌倒动作之间人体矩形宽高比、人体质心高度、人体躯干倾斜角都具有很好的区分度,人体下蹲曲线处于站立、跌倒两个动作之间,与站立、跌倒两个动作有明显的区别,因此下蹲与站立、下蹲与跌倒都能较好地进行区别。综上分析,矩形宽高比、质心高度、躯干倾斜角三个运动状态特征能够表征人体运动姿态变化。
4)运动特征向量。
通过上述分析可知,人体躯干倾斜角θ、质心高度ZL和人体宽高比Q可作为人体运动状态识别的特征,基于这三个特征构建人体运动状态向量M=[θ,ZL,Q]。为了与CNN 特征提取后的特征进行更好的融合,将人体运动特征向量重复一次变为6 维特征M'=[θ,ZL,Q,θ,ZL,Q],为了避免特征融合后参数过拟合,利用Sigmoid 激活函数将特征向量变为0 到1之间的数值,变化后的特征向量为:

其中,σ为Sigmoid激活函数。
2.2 运动目标特征
1)网络结构。
手工提取的人体运动特征能够表示运动信息,CNN 能够自动提取图像的静态特征,本文将人工提取的运动特征与CNN 特征进行融合,将两种不同维度的特征映射到同一特征空间。图6 所示为融合运动特征CNN 算法的流程:特征融合网络首先利用CNN 从输入视频帧中提取图像颜色、纹理、轮廓等特征进行全面学习;然后加入手工提取的人体运动特征,利用全连接层将这两种维度的特征进行融合,在网络参数反向传播优化过程中,人工运动特征能够优化CNN 参数的学习,在CNN 中融入运动特征成分,最终形成一个全面的特征表达,以便能够更好地对目标行为进行描述。
CNN 网络特征提取的具体过程为:将视频帧输入到CNN模型中,经过卷积层1,卷积层1 为64 个3×3 的卷积核,维度(3,3,3,64);接着进入到2×2 的池化层1,其维度为(1,2,2,1);之后进入第二个卷积层,卷积层2 为96 个3×3 的卷积核,维度为(3,3,64,960),再进入第二层池化,维度为(1,2,2,1);之后进入第三个卷积层,卷积层3 为256 个3×3 的卷积核,维度为(3,3,96,256);再进入第三层池化,维度为(1,2,2,1);之后进入第四个卷积层,卷积层4为64个3×3 的卷积核,维度为(3,3,256,64);再进入第四层池化,维度为(1,2,2,1);之后进入第五个卷积层,卷积层5 为32 个3×3 的卷积核,维度为(3,3,64,32);卷积层6 为32 个1×1 的卷积核,维度为(1,1,32,1),经过拉伸操作,进入CNN 全连接层1得到169维的CNN 特征向量,然后经过CNN 全连接层2得到6维的CNN 特征向量;将6 维的CNN 特征向量与经过Sigmoid 激活后的6 维人体运动特征进行拼接得到1 个12 维的向量;然后将12 维的特征向量经过一个具有3 个节点的全连接神经网络进行特征融合,最后输出分类预测结果。

图6 融合运动特征CNN算法流程Fig.6 Flowchart of CNN algorithm fusing with motion features
2)代价函数。
上述融合CNN 跌倒检测模型输出有3 个节点,分别代表站立、跌倒中、跌倒三个类别。交叉熵是分类问题中比较经典的代价函数,它刻画了两个概率分布之间的距离,但是原始神经网络的输出并不符合概率分布,因此为了使用交叉熵作为评价函数,本文将原始神经网络输出的最后一层加入Softmax函数,用Softmax 函数作为输出结果的类别置信度,这样就会生成符合概率分布的输出结果。

式中:m为训练中每次batch的大小,n为输出类别数。
为了增加输出不同类别之间的距离,对传统代价函数进行了优化,定义了输出类间代价函数:

式中:λ表示类间损失因子,xi表示全连接层输出的第i个样本,cyi表示所有同一类别yi的所有样本的中心值。
综上,本文定义的总目标优化函数L是:

3 实验结果分析
本文训练过程在GPU 服务器上完成,操作系统为Ubuntu16.04;硬件平台CPU E5-2630 V4@2.2 GHz,两个显卡为GTX1080TI(11 GB×2),内存128 GB;软件平台采用OPENCV3.4.3、Python3.6.3、CUDA、cuDNN、Pycharm,使用TensorFlow深度学习框架进行训练。
从公开数据集Le2i选取10 段人体跌倒的视频,每段视频包含约240 帧图像(分辨率为320 × 240,视频速率为每秒24帧),将白天光照充足下的视频片段编号为1~5,将夜晚室内灯光干扰情况下的视频片段编号为6~10,每段视频均包含实验者正常站立、下蹲和跌倒的三种姿态。首先将视频帧送入改进的YOLOv3 模型中进行人体目标检测;然后提取人体运动目标特征(躯干倾斜角、人体质心高度、矩形宽高比),将人体目标图像与人体运动目标特征向量输入到本文融合运动特征的网络模型中输出识别结果;最后对跌倒行为的识别结果视频帧进行保存,作为跌倒检测准确度的判断标准。图7 为融合运动特征CNN 检测结果,可以看出,在不同光照影响下,人体从不同方向跌倒,本文算法都能较好地完成跌倒任务的检测。

图7 融合运动特征的CNN跌倒检测结果Fig.7 Fall detection results of CNN fusing with motion features
3.1 不同跌倒检测方案对比实验
为了检测本文方案的准确性,设计对比检测实验,分析改进YOLOv3 进行人体检测的优越性和融合人体运动特征神经网络跌倒检测方案的准确性。实验结果如表1所示,分析表1的实验数据可知,当人体在视频中由运动变为静止状态时,背景差分、混合高斯、VIBE 方法对目标检测产生丢失,会导致跌倒检测帧数较低;HOG 检测能够检测到静止的人体,但基于方向梯度信息进行人工特征提取需要人工进行Gamma 校正,Gamma取值不具有普适性,因此HOG 平均跌倒检测帧数虽然比前背景分类方法好,但是跌倒检测帧数仍不理想。基于阈值的跌倒判断方法只要满足一个条件就判断为跌倒,基于分级的跌倒判断方法是对多个判断条件进行灵敏度分级,按照灵敏度级别由高到低依次根据条件进行跌倒判断,这两种方法虽然判别简单,但误判率较高。SVM 与CNN 方法进行跌倒判断的误判率能够较全面提取到图像的特征信息,检测效果优于分级法与阈值法,但是丢失了图像人体运动信息。总体来说,基于融合运动特征CNN 方案的检测准确率平均值达到98.3%,误判率为1.7%,这种方案能够满足老人跌倒检测的需要。

表1 不同跌倒检测方案结果对比Tab.1 Comparison of results of different fall detection schemes
3.2 光照干扰对比实验
由上述分析可知基于改进YOLOv3 人体检测融合运动特征的CNN跌倒检测具有较好的检测效果。在实际环境中由于天气或灯光等客观原因会使摄像环境发生变化,为了验证光照对检测效果的影响,分别在正常光和干扰光条件下进行了5组对比实验,结果如表2所示。其中光照条件为正常光是指白天室内正常天气光照下录制条件,灯光干扰条件是晚上室内打开白炽灯进行干扰的录制条件。从实验结果可知,加入灯光干扰后,跌倒检测的准确率、误判率并没有很大的影响,在不稳定光照影响下,本文方法进行跌倒检测并不会产生太大的误差,不会对最终跌倒检测的准确率和误判率产生影响,说明本文跌倒检测算法对光照干扰的影响具有较高的鲁棒性。

表2 光照干扰对比实验Tab.2 Comparison experiment of lighting interference
3.3 噪声干扰实验
上述实验的跌倒检测视频帧只有跌倒过程一类运动,但是在实际监控视频中往往会有其他的日常运动、类跌倒运动干扰跌倒检测,这些日常活动和类跌倒运动对于跌倒检测任务而言属于噪声运动。为了验证本文算法在有噪声运动下的准确率和误判率,选取六种常见的噪声运动:日常运动(行走、上楼、下楼),类跌倒运动(弯腰捡东西、坐下起立、蹲下起立)进行了相关实验。
本文首先从Le2i数据集中选取一段120 帧的跌倒视频序列;然后由3 名志愿者依次完成上述6 种噪声运动,共得到18个噪声运动视频帧;分别从18 个噪声运动视频帧中选取有代表性的30 帧噪声帧,将选取的18 种噪声运动视频帧分别与Le2i 选取的120 帧跌倒运动混合,共得到18 组带有噪声帧的混合数据,每组混合数据的总帧数是150帧。表3为未加入噪声帧与加入噪声干扰帧的对比实验结果。由实验结果可知,加入日常运动干扰噪声帧后,准确率并没有受到太大影响;但是误判率增加,特别是对于混入上下楼梯、弯腰捡东西等噪声尤为明显,弯腰捡东西的三次实验中有两次误判率达到5.4%;噪声干扰检测平均准确率为97.1%,误判率为3.25%,相比无噪声干扰的准确率与误判率都有所下降,但检测结果依然能够满足老人跌倒检测的需要。

表3 噪声干扰对比实验Tab.3 Comparison experiment of noise interference
4 结语
本文提出了一种融合运动特征的CNN 跌倒检测方法,首先利用改进的YOLOv3 进行人体目标提取,有效解决传统前背景分离方法对视频帧中静止目标产生的目标追踪消失、目标混淆等问题;接着分析了人体运动特征,并将人体运动特征融入CNN,与不同的跌倒检测方案进行了对比实验,并且在光照、混合日常运动干扰下进行了实验。实验结果表明,本文提出的融合人体运动特征的CNN 检测方法对人体跌倒行为的判断具有较高的准确率,且对光照影响、日常常见的噪声干扰运动具有较高的鲁棒性。
目前,本文实验只是针对已经录制好的视频进行检测,而且检测背景环境比较简单,在实际检测中人体的运动状态千变万化更为复杂,下一步的工作是把本文的方法移植到NVIDIA 嵌入式板卡Jetson Nano中,分析其在实际情况下的检测结果,并进行优化改进。
