基于标签分布学习的三维手部姿态估计
2021-03-07李伟强张静玉王旭鹏
李伟强,雷 航,张静玉,王旭鹏
(电子科技大学信息与软件工程学院,成都 610054)
(*通信作者电子邮箱1261707134@qq.com)
0 引言
准确的三维姿态信息在人机交互等领域起到至关重要的作用,是近几年计算机视觉领域的研究热点[1-3]。基于深度学习的算法可以有效地解决计算机视觉领域中的姿态估计问题[1-6]。其中,手部姿态估计是指计算机通过算法对输入图片或者视频中手部姿态进行分析和预测,从而确定手部在三维空间中的姿态信息,即各个关节点在三维空间中的位置分布。
传统的手部姿态估计算法大多基于RGB 彩色图像。其中,Zimmermann等[1]提出了一种从RGB图像中学习完整三维手势估计的方法;Panteleris 等[2]提出了一种从RGB 图像中实时获取手部姿态的方法,该方法首先估计手部关节在二维图片中的位置,然后,采用非线性最小二乘法将手的三维模型拟合到估计的二维关节位置,从而恢复手部姿态;Cai 等[3]通过引入一个深度正则化函数,提出了一种新的弱监督学习方法进行手部姿态估计。但是,基于RGB 图像的方法往往会受到光照强度变化的影响,很难适用于夜间光线较差或白天光照持续变化等情况。
随着低成本、高精度深度摄像机的逐渐普及推广,基于深度数据的手部姿态估计方法被提出。很多方法采用二维卷积神经网络(Convolutional Neural Network,CNN),从深度图中进行姿态的估计[6-11],并取得了一定的进展。Tompson 等[7]提出一种基于随机决策森林的算法,对连续手部姿态进行实时恢复,该方法有效地解决了时效性问题,但在准确性上还有待提高;Oberweger 等[8-10]以各关节点的初始估计位置为中心,使用主成分分析法降低输入数据的维度,采用卷积神经网络预测精确的手部姿态信息,同时,通过划分多个输入区域进一步提高手部姿势预测的准确性;Ge 等[11]提出了一种利用多视图投影对关节点位置的二维热图进行回归的方法,解决了二维热图未充分使用深度信息的问题。但是,二维卷积神经网络并不能充分提取三维的图像特征[10]。在此之后,三维卷积神经网络被提出,并应用于手部姿态估计。Ge 等[12]提出了一种三维卷积神经网络算法,解决了二维卷积神经网络不能直接从三维手势中提取特征的问题,但是该算法复杂度较高;Ge等[13]提出了基于PointNet[14]和PointNet++[15]的特征提取方法对关节点位置进行回归,可以直接处理点云数据,但没有解决手部关节点与手部特征之间高度非线性映射关系。针对手部关节点和手部特征之间的高度非线性映射关系,基于概率密度的模型被提出用以解决此类问题。Bouchacourt 等[16]提出了一种新的概率模型Disco,该模型能够从神经网络参数化的后验分布中有效采样,但是对于深度图的特征提取能力存在不足;Moon 等[17]提出了一种由体素到体素的深度学习网络模型,该模型降低了手部关节点与深度图之间的高度非线性映射关系,但是计算复杂度较高,且计算量随着分辨率增加呈立方增长。
为了解决非受限场景下的手部姿态估计问题,考虑到光照变化、遮挡和姿态幅度较大等情况,本文提出了一种基于深度数据的三维手部姿态估计算法。该方法直接处理点云数据,采用PointNet++提取手部的几何特征;通过学习标签在空间中的分布,解决手部特征和关节点位置之间的高度非线性问题,提高了关节点位置预测的准确性。
本文的主要工作如下:
1)面向非受限场景下的手部姿态估计问题,提出了一种端到端的深度网络模型,该网络以归一化的点云数据为输入,能够有效地提取高鉴别力的手部几何特征,计算复杂度较低;
2)为了提高姿态估计的准确性,该网络将标签分布学习应用于手部姿态估计,以解决手部特征和关节点之间的高度非线性问题。
1 三维手部姿态估计方法
给定的手部深度图A,三维手部姿态估计预测各手部关节点在世界坐标系下的位置信息。其中,J表示预测的手部关节点总数。令T={(Ai,Φi),i∈[1,M]}表示训练样本的集合,其中,M表示训练样本总数。
本文提出的方法由数据预处理、特征学习网络和标签分布学习网络三个模块构成,如图1 所示。数据预处理模块给出了手部三维点云数据的生成方法。特征学习网络采用PointNet++模型,因为PointNet++能够直接处理点云数据,并且已被成功应用于目标分类、检测和场景分割等任务。标签分布学习网络采用全连接回归手部关节点的空间概率分布。

图1 本文手部姿态估计方法整体框架Fig.1 Overall framework of the proposed hand pose estimation method
1.1 数据预处理
1.1.1 点云数据生成
深度传感器采集的是特定视角下手部的深度图像,而特征学习网络的输入是点云数据,所以需要将原始深度数据转换成三维点云数据[18]。手部三维点云数据的生成示意图如图1(a)所示。
对于深度图中的任意像素点(u,v) ∈D,将其转换为世界坐标系中的点p(x,y,z),如式(1)所示:

其中:(u0,v0)表示世界坐标系的中点;fx、fy是深度传感器的内部参数,分别为水平和垂直焦距;d是像素点(u,v)处的深度值,描述像素点到深度传感器之间的距离。
1.1.2 数据归一化
如图1(a)所示,深度网络要求输入数据的维度一致,本文使用下采样方法将点云数据中点的数量进行统一;三维手部姿态估计存在手部全局方位变化大的问题,本文采用定向边界框(Oriented Bounding Box,OBB)将原始点云进行旋转归一化处理,映射到统一的OBB坐标系。
下采样采用最远点采样[19]处理点云数据。该算法从初始点集P={p0,p1,…,pN}中任意选取一点pi,计算P中与该点距离最远的点pij加入到新的点集Psa中;然后,从P的剩余点中,选取与点集Psa距离最大的点放入集合Psa中(点到点集的距离为点到点集中每一点距离的最小值)。依此迭代,直至采样点的数量为N,采样后的点集为Psa={pi1,pi1,…,piN}。
定向边界框指的是紧密包围手部点云的一个有向长方体边界框。通过对所有输入点云的三维坐标进行主成分分析,计算出定向边界框的主方向,作为OBB 坐标系的三个坐标轴方向,最后通过定向边界框的最大边长确定OBB 坐标系的刻度。
根据式(2)将点云所在的世界坐标系映射到OBB 坐标系,然后将点平移到以均值为原点的坐标系中,并缩放至单位大小。

其中:pcam和pobb分别是点云在世界坐标系和OBB 参考坐标系中的三维坐标是世界坐标系中OBB 的旋转矩阵是点云图中采样的N个点在OBB 参考坐标系中的平均坐标位置;Lobb是OBB框的最大边长。
为保证输入和输出数据的物理意义相同,在训练阶段,各手部关节点的三维位置坐标也经过式(2)映射到OBB 坐标系中;在测试阶段,根据式(3)将OBB 坐标系中的各手部关节点的三维位置坐标变换回世界坐标系:
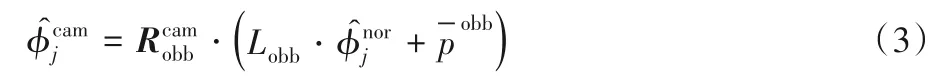
1.2 特征学习网络
特征学习网络采用PointNet++模型从点云数据中提取手部的特征,流程如图1(b)所示。整体上看,PointNet++包含三个分组采样层,每一层的采样、分组和特征提取如图2 所示。PointNet++以PointNet 为基础进行特征提取,并且能够提取局部的几何特征信息。本节将先介绍PointNet,再介绍PointNet++。

图2 PointNet++分组采样层Fig.2 Grouped sampling level of PointNet++
1.2.1 PointNet
PointNet由多层感知机和最大池化层组成,能够提取无序点云数据的特征。给定一个输入数据点集P={p0,p1,…,pN}∈RD,其中D表示点的维度,定义表示PointNet处理流程的函数f:P→R将点集P映射到特征向量,如下:

其中:g和h采用多层感知机网络;max 是最大池化层,最大池化层是一个对称函数,由于对称函数可以解决无序性问题,所以式(4)中的点集输入可以是无序的,不影响最终效果,并且可以逼近任何连续函数;h(pi)计算pi的高维特征向量。最终输出一个表示整个点集的特征向量,然而这个特征向量不能有效表示局部特征,由此引出可以表示局部特征的PointNet++。
1.2.2 PointNet++
为了提取点云数据的局部特征,PointNet++采用分层结构提取多层次的几何特征。PointNet++与PointNet 不同的地方在于采样和分组,采样时使用最远点采样方法,在进行点集映射时用分组集合G={g0,g1,…,gN}∈RD代替了直接使用点集P,其中gi={pi0,pi1,…,pik}是由pi点通过k近邻算法选取的周围的点表示的gi分组。
此外,对于分组后的点云数据依旧用PointNet 进行特征学习。如图2 所示,点集的某一层特征由两部分特征向量组成:D表示分组所表示的原始采样点的原始特征向量,C表示本层每个分组从上一层学习到的特征向量。如图1(b)所示,图中N1×(D+C1)中N1表示采样点个数,D表示本层采样点的原始特征向量,C1代表本层分组的特征向量。在学习过程中,同时学习了整体和局部的特征。
1.3 标签分布学习网络
使用标签分布学习网络计算关节点位置在三维空间概率密度分布,和直接计算关节点位置信息相比较,降低了非线性,这使得网络更加容易学习。
标签分布学习网络将特征学习网络的输出特征作为输入,通过网络得到关节点的空间位置分布信息,进而得出关节点所在位置。为了监督关节点在空间位置的分布,本文运用一种概率密度分布方法估计关节点的位置信息,将归一化后的点云数据所在空间进行网格化划分,将OBB 坐标系中的每个维度44等分,则整个空间被划分为443个空间立方体,关节点在三维坐标中每个空间立方体内的概率分布表示为:
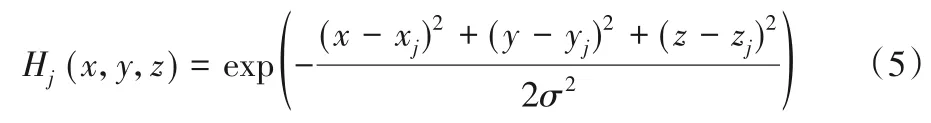
其中:(xj,yj,zj)是第j个关节点的真实位置,σ是高斯分布的标准差。为了加快神经网络收敛,本文没有使用标准的高斯概率分布,而是使用式(5)的表示方法,该方法的最大概率密度为1。为了减小网络的空间复杂度,本文假定H(x,y,z)在X、Y、Z 三个维度上是独立同分布的。因此,分别计算X、Y、Z每个维度上的概率密度分布。对式(5)进行化简得到式(6):
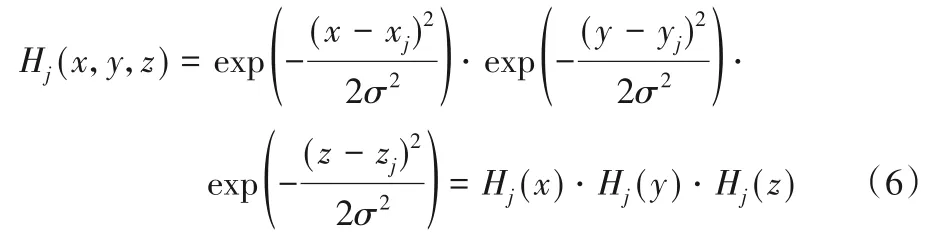
由此,概率密度可以表示为X、Y、Z三个维度上概率密度相乘。将每个维度的概率分布看作一个标签,关节点标签分布如图3 所示,该图分别选取了两个手部姿态的两个关节点的x、y、z标签概率分布情况,图中横坐标表示OBB 的某一维度被划分成的区域位置索引,图中明亮的格子表示相应区域的概率密度较高。
标签分布学习网络的最后一层采用全连接网络对标签的分布进行学习,全连接层分别包含1 024、2 048、3× 44 ×J个神经元。
本文采用均方误差作为损失函数引导网络进行学习,Loss如下:

其中:Hj和分别是第j个关节点概率分布的真实值和预测值。
在整个网络训练结束后,对各标签概率分布最大值所在的空间进行再次预估,根据该方格中点的坐标和该方格的概率H以及该方格周围方格的概率分布,计算预测值位置与该方格中点的偏差,最终确定预测的手部关节点坐标。

图3 手部关节点标签分布示意图Fig.3 Schematic diagram of hand joint point label distribution
2 实验与分析
为了验证本文提出的基于标签分部学习的三维手部姿态估计网络的有效性,在公共数据集微软亚洲研究院(Microsoft Research Asia,MSRA)手部姿态数据集[20]上进行了一系列实验。
2.1 数据集
MSRA[20]数据集使用英特尔的Creative Interactive Gesture深度摄像机采集数据,具有76 000多张手部姿态深度图像,最大分辨率为320×240。数据集记录了9 个不同人的17 个手势序列,每个手势序列大约包括500 张图像。在每幅图像中都进行了分割,包括J=21 个关节点的真实值记录。参考文献[20]的做法,在训练阶段针对8 个人的手势进行训练,训练集约包含8 500 帧图片;在测试阶段针对剩余1 人进行测试,测试集约包含68 000 帧图片,针对所有人重复该实验9 次,并求其平均指标。
2.2 实验配置
本文的实验环境为:操作系统为Ubuntu18.04,CPU 为Intel Core-i9(3.60 GHz),内存为32 GB,显卡为NVIDIA GTX2080TI 11 GB。点云采样、表面法线计算和分布学习的标签使用Matlab实现,神经网络使用PyTorch框架实现。
首先将深度图按照深度值进行裁剪后,按照最远点采样,采取1 024个点的点云数据,并进行OBB操作和表面法线计算并选定边界框,对于分层的PointNet++,使用最远点采样:第一层为512 个点,球查询半径为0.1;第二层为128 个点,球查询半径为0.2。标签分布采用对有向边界框进行44等分的方法,生成3× 44 ×J维度的标签分布,并将该标签分布作为神经网络的输出。训练时,使用Adam 进行优化,batch 大小为32,初始学习率为0.001,在50 个epoch 后,学习率下降至0.000 1,总共迭代60个epochs。
2.3 结果及性能分析
参考文献[21]的方法,本节在MSRA[20]数据集上与将本文方法与目前的主流方法进行客观评价,评价指标包括:平均距离误差和所有关节的最大误差低于阈值的帧比例。然后,对本文方法各部分的有效性进行验证,并分析了网络结构作用。最后,对本文方法的时间复杂度和空间复杂度进行了分析。
2.3.1 客观评价
将本文方法与Multi-view CNNs[11]、3D CNN[12]和Hand PointNet[13]的平均距离误差进行比较,结果如图4 所示。从图中可以看出,本文方法所有关节点的平均误差距离小于Multiview CNNs[11]、3D CNN[12]。本文方法的整体关节点平均距离误差为8.43 mm,误差相比3D CNN[12]的9.56 mm 和Hand PointNet[13]的8.5 mm 分别降低了11.82%和0.83%。在腕部(Wrist)、大拇指根部(Thumb R)、食指根部(Index R)、中指(Middle)、无名指根部(Ring R)、小拇指根部(Little R)的平均误差距离小于Hand PointNet[13]。其中腕部关节点误差由8.90 mm 下降至8.45 mm,下降了5%;食指根部关节点误差由6.96 mm 下降至5.83 mm,下降了16%;中指根部关节点误差由5.62 mm 下降至5.26 mm,下降了6%;无名指根部关节点误差由6 mm 下降至5.22 mm,下降了13%;小拇指根部关节点误差由7.68 mm 下降至6.3 mm,下降了18%。在大拇指指尖(Thumb T)、食指指尖(Index T)、无名指指尖(Ring T)、小拇指指尖(Little T)、小拇指根部的平均误差距离略高于Hand PointNet[13]。其中大拇指指尖关节点误差由13.59 mm 上升至13.71 mm,上升了0.8%;食指指尖关节点误差由9.75 mm 上升至9.86 mm,上升了1.1%;无名指指尖关节点误差由10.11 mm 上升至10.22 mm,上升了1.1%。由此可见,在大多数指尖关节本文方法比Hand PointNet[13]略差,这是由于Hand PointNet[13]具有指尖细化网络,对误差大的指尖关节点进行了进一步优化造成的。然而根据以上数据分析可以看出,指尖关节点的误差上升很小,本文方法在大部分关节点精度具有很大的提升。由此可以说明本文方法的优势。

图4 MSRA手势数据集上各方法的关节点平均距离误差Fig.4 Average joint distance error of different methods on MSRA hand pose dataset
将本文方法与Multi-view CNNs[11]、Crossing Nets[22]、3D CNN[12]、DeepPrior++[10]和Hand PointNet[13]在所有关节的最大误差低于阈值的帧比例上进行比较,结果如图5所示。从图5中可以看出,在阈值为0~29 mm时,本文的方法要优于对比方法,至此最大误差小于误差阈值帧的比例约为81%;在阈值大于29 mm 时,本文方法比Hand PointNet 表现略差。由此可见本文效果在大部分帧上的表现效果要优于对比方法;但在部分帧上仍存在着拟合效果稍差的现象,这主要是由于本文方法没有对误差较大的指尖关节点进行优化。

图5 MSRA手势数据集上各方法的最大误差小于误差阈值帧比例Fig.5 Proportion of frames with max error less than the error threshold of different methods on MSRA hand pose dataset
2.3.2 网络结构各组成部分的作用
为了验证本文所提网络结构各组成部分的有效性,进行以下实验(结果如表1):
首先验证了采样点数量对实验的影响:当分别选取初始点云数量为1 024、2 048 时,平均误差几乎没有变化,均为8.43 mm;在选取初始点云数量为512 时,平均距离误差由8.43 mm 增至8.49 mm,误差增长较小,由此说明了本文方法对于采样点数量具有鲁棒性。考虑到精度与时间复杂度,后面的实验均选取初始点云为1 024点。
其次,为了验证OBB 操作的有效性,设计了一个不含OBB 操作的实验进行对比,此时平均误差增至8.92 mm,增加了0.49 mm,由此可以说明OBB操作的有效性。
而后,为了验证了特征提取网络PointNet++的有效性,将PointNet++更换成PointNet,此时平均误差增至9.31 mm,增加了0.88 mm,由此验证了本文所用特征提取网络的有效性。
最后,为验证标签分布学习网络的有效性,将标签分布学习网络改为直接回归关节点坐标的方式,此时平均误差增至8.66 mm,增加了约0.23 mm,这是因为标签学习网络解决了关节点与深度图之间高度非线性映射关系。至此可以说明,本文各部分网络结构均有效果。

表1 MSRA手势数据集上验证网络结构各组成部分有效性的实验方法及结果Tab.1 Experimental methods and results for verifying effectiveness of each component of the proposed network on MSRA hand pose dataset
2.3.3 复杂度分析
本文方法完整的运行时间为12.8 ms,实际运行速度为61.3 fps(frame per second),其中预处理部分(包括数据采样、标签分布的生成与还原等)运行时间为9.31 ms,主体网络部分运行时间为3.5 ms,完整运行时间略高于Hand Pointnet[13]的11.5 ms(与本文方法运行环境一致),远远低于V2VPoseNet[17]的285.7 ms。本文网络模型参数数量为12.2 MB,远远低于3D CNN[12]的420 MB,略高于Hand Pointnet[13]的10.3 MB,这是由于本文使用了标签分布学习网络,复杂度略有增加,但是预测精度得到了提升。
3 结语
本文提出了一种基于标签分布学习的手部姿态估计方法,通过对点云数据进行最远点采样和OBB 操作进行归一化,再按照划分球体的方式进行分组,然后将点云数据通过PointNet++进行特征学习,并将学习到的特征进行标签分布学习,将预测值还原到原始坐标系下。通过这种方式,提高了特征学习能力,降低了深度图和手部关节点之间的高度非线性映射关系,提高了整个网络的预测能力。
