基于改进的一维卷积神经网络的异常流量检测
2021-03-07杭梦鑫张仁杰
杭梦鑫,陈 伟,张仁杰
(南京邮电大学计算机学院,南京 210023)
(*通信作者电子邮箱chenwei@njupt.edu.cn)
0 引言
随着网络科技的快速发展,网络涉及人类社会的各个方面,网络安全问题也越来越受到人们的关注。《2018 年中国互联网安全报告》指出,2018 年网宿云安全平台共监测拦截了75.46亿次有针对性的爬虫攻击事件,9 578.88亿次分布式拒绝服务(Distributed Denial of Service,DDoS)攻击事件,9.53亿次Web应用攻击,相较2017年呈翻倍式增长。2018年思科发布的新的视觉网络指数(Visual Networking Index,VNI)[1]中预测,到2022 年,互联网连接设备预计将达到285 亿,约为全球人口的3倍,全球互联网用户将占全球人口的60%,全球IP流量将超过互联网元年(1984 年)到2016 年底这32 年间的流量总和,将增加三倍以上,每年将产生4.8 ZB 的网络流量。因此,维持网络的安全运行需要引起重视。异常检测是网络安全的研究重点,其中网络流量异常检测通过对流量数据的分析,可以检测出网络中是否存在攻击。
但是传统的机器学习方法对特征的依赖度很大,良好的特征取决于研究者的经验,选取不同的特征对检测的准确度有很大的影响。而卷积神经网络(Convolutional Neural Network,CNN)具备良好的表征学习能力,能自主学习特征,实现低级特征到高级特征的抽象提取。因此,近年来CNN 常被应用于异常流量检测。
本文对传统的CNN 结构进行了改进,提出了一种基于改进的一维卷积神经网络(Improved one-Dimentional Convolutional Neural Network,ICNN-1D)的异常流量检测方法(Abnormal Flow detection Method based on ICNN-1D,AFMICNN-1D),在流量检测中,无须人为设置关键参数与提取特征。传统的CNN 大多用于图像识别等,因为图像中每个相邻的像素之间关系紧密,可以通过池化操作获取图像的边缘信息和背景信息,但相邻的流量特征之间并没有相关性,池化操作反而会损失信息。因此本文ICNN-1D在每一次卷积之后没有池化操作,以尽可能保留完整的流量信息;另外,ICNN-1D使用全局池化(Global Pooling,GP)和一层全连接来代替传统多层全连接分类操作,能大大减少训练参数,缩短训练时间,减少过拟合现象的发生。
1 相关工作
目前,已有许多机器学习算法应用于异常流量检测,利用不同的机器学习算法降低误报率,检测异常的网络行为。入侵检测技术是计算机网络安全的重要组成部分,1980 年由Anderson[2]首次提出。Shon 等[3]提出了一种将遗传算法和支持向量机(Support Vector Machine,SVM)相结合的异常检测分类器,对真实环境数据集有广泛的适应性;赵夫群[4]提出了一种用于网络入侵检测的最小二乘支持向量机(Least Squares Support Vector Machine,LSSVM);Jha 等[5]使用马尔可夫(Markov)模型研究网络异常检测;Bamakan等[6]使用支持向量分类(Support Vector Classification,SVC)对网络入侵进行分类;Pan 等[7]提出了一种混合机器学习技术,它结合了k 近邻(k-Nearest Neighbor,kNN)和SVM 来检测攻击。传统的机器学习方法在网络流量异常检测中十分有效,并且有一定的准确率,但实验过程中的调优较为困难,而且需要人为选择特征,构造样本特征效率低,检测性能取决于参数调优和选择特征的质量。
为了解决上述问题,研究人员引入了深度学习技术。近几年来,深度学习广泛应用于语音识别、图像识别和自然语言处理领域。由于深度学习可以从原始数据中提取高级特征,因此许多领域都在积极利用深度学习方法,部分学者也开始将深度学习方法与异常检测领域相结合。Salama 等[8]引入深度置信网络(Deep Belief Network,DBN)、深度神经网络(Deep Neural Network,DNN)用于提取特征,利用SVM 作为分类器对流量进行分类;Alom 等[9]使用受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)训练了一个深度置信网络,在NSL-KDD训练数据上具有97.5%的准确率;Javaid等[10]结合稀疏自编码器(Sparse Autoencoder)的编码层(用于特征提取)和softmax 函数(用于类的概率估计),设计了一种“自学习”分类机制对NSL-KDD 进行分类;Khan 等[11-12]利用基于CNN 的残差网络(ResNet)和GoogleNet 模型进行恶意软件检测;Kumar等[13]通过建立CNN模型,检测基于模式识别的恶意代码;贾凡等[14]实现了一种基于CNN 的入侵检测算法;Bontemps 等[15]提出了一个基于长短期记忆(Long Short-Term Memory,LSTM)网络的异常检测系统,报告了该方法中的β参数变化会引起预测错误和虚假警报;王伟[16]针对传统基于机器学习方法的异常检测需要手动提取特征的问题,将流量转化为灰度图,利用深度学习的方法实现了流量特征的自动提取和流量识别;何文河等[17]提出了一种改进的反向传播(Back Propagation,BP)神经网络算法用于异常检测,但是收敛速度很慢。
基于传统机器学习的异常检测方法通常需要人工选择流量特征,而特征工程一般都要求研究者有相关的专业背景,同时也应具备较为丰富的机器学习经验。特征选择的优秀与否,会直接影响到最终检测的性能。另外,基于深度学习的方法虽然在样本识别能力和性能上有了一定的提升,但是在网络训练过程中会存在过拟合问题,且参数众多,训练时间较长,检测精度和效率都需要进一步提升。
CNN 是一种经典的深度学习算法,与其他深度学习算法相比,它的优势就是在于它共享相同的卷积核,能明显减少参数数量和计算时间。因此,本文提出了一种基于CNN 的异常流量检测方法,将原始网络流量特征经过预处理后作为输入数据进行训练。此外,与其他基于CNN 的异常流量检测方法不同,本文方法在卷积之后不再采用池化操作。实验结果表明,与现有池化操作的方法相比,本文方法具有较好的检测效果。
2 相关原理
2.1 CNN
传统的CNN 模型结构是“卷积-池化-全连接”。在卷积神经网络中,一个卷积层可以包含很多个卷积面。假设输入是一个M×N的图像,用矩阵x表示,卷积核是大小为m×n的矩阵w,偏置是b,卷积后结果中的每一个元素就是图像中对应卷积核大小的区域与卷积核进行内积加上偏置得到的,那么:

其中:*代表卷积;g(·)代表激活函数。一般情况,g(·)为校正线性单元(Rectified Linear Unit,ReLU):

在卷积神经网络中,下采样过程也称为池化过程,主要有两种池化操作:平均池化和最大池化。平均池化公式如下:

其中:C代表卷积面;λ、τ代表对卷积面进行块大小为λ*τ的下采样。
经过多层卷积-池化之后,通过全连接层对抽象出的高级特征进行分类:

其中:W代表全连接层权重;X代表经过卷积池化的特征图(feature map)转化为向量之后作为全连接层的输入;b为全连接层的偏置。经过计算之后,softmax 函数将结果的每一个元素值限制在[0,1]内,且和为1。
2.2 池化层
池化层也叫下采样或欠采样。池化操作的目的是特征降维,压缩数据和参数数量,避免发生过拟合。对于图像而言,它将输入的图像分为大小相同的若干个矩阵区域,然后对每一个矩阵区域求其最大值(最大池化)或者平均值(平均池化),从而减小了数据的空间大小,参数量和计算量也会减少,避免了过拟合。图像经过最大池化提取到纹理信息,经过平均池化可以提取到背景信息,但流量特征进行池化反而会损失信息,影响检测性能。
2.3 全局池化
在传统的卷积神经网络中,卷积层通过池化(一般为最大池化)后,通常会将结果压平,送入两个及以上的全连接层,再使用softmax 函数计算样本关于每个类别的概率值。样本的类别即为求得的最大概率值。但是,多个全连接层面临一个问题:参数众多。例如,将特征向量送入网络模型,在经过最后一次卷积之后,得到一个W×H×C的特征图。设定全连接层神经元个数为M,那么全连接层共需要W×H×C×M个参数。这使得整个网络参数多,计算速度慢,参数更新复杂,效率低下,甚至造成过拟合。
Lin 等[18]提出了一种新型的深度网络结构“网中网”(Network In Network,NIN),提出了一种新策略,即在卷积后采用全局平均池化得出分类结果。经过多次卷积之后最终得到与样本类别数相同个数的特征图(W×H×Label),其中Label代表样本类别数。对每一个特征图求均值,最终得到1× 1×Label的矩阵,转化为一维向量之后得到该样本数据的分类结果。简而言之,全局池化就是使得池化的滑动窗口大小和特征图的大小相等,一个特征图输出一个值。全局池化相较全连接层的优点在于全局池化没有参数设置,只需求整个特征图的均值或最大值,极大缩短了训练时间;同时,也不需要根据优化算法进行调参,能很好地避免过拟合的现象发生;另外,全局池化能够汇聚空间信息,所以对输入的空间转换具有更好的鲁棒性。全局池化分为全局平均池化(Global Average Pooling,GAP)和全局最大池化(Global Max Pooling,GMP),GMP 只提取每个特征图中最重要的区域,而GAP 会对特征图中每一个区域进行考虑,求均值。
3 基于ICNN-1D的异常流量检测
异常检测是网络入侵检测的主要研究方向。异常流量是在网络中偏移正常流量的情形,正常流量会随着网络的环境、用户的操作发生变化,因此,异常流量要根据同一网络状态下的正常流量作出判断,寻找出不正常的预期行为。在流量检测中,异常流量的某些特征值必定会与正常流量的特征值有区别。例如,在CIC-IDS-2017 数据集中,分布式拒绝服务(Distributed Denial of Service,DDoS)攻 击 的Bwd Packet Length Std 特征与其他类别流量相比具有较大差异。正常流量与其他攻击流量(除拒绝服务攻击(Denial of Service,DoS)该特征值大部分为0,而DDoS 攻击流量具有较大的数值。由此可见,每一种攻击的某些特征都会与其他攻击及正常流量有区别。因此,通过对流量特征进行不断的学习,就可以对网络流量进行分类,识别出正异常流量。
本文提出了一种基于改进的一维卷积神经网络的异常流量检测方法(AFM-ICNN-1D)。输入数据是流量特征向量,每个特征之间不具备相关性,多次池化会造成局部信息的损失,影响检测的效果,因此,本文方法在卷积之后不采用池化操作;另外,在全连接层之前加入全局池化层,并且采用了跨层聚合,减少参数,缩减训练时间。实验结果表明,该方法可以快速、有效地识别出日常的网络攻击。
3.1 设计思路
考虑到对流量特征进行池化会造成信息损失,同时传统CNN 的全连接层因参数众多而导致训练速度慢,也会产生过拟合的问题,本文方法除去了传统CNN 结构中卷积之后的池化操作,并采用前文提到的全局池化方法来缓解多层全连接分类参数众多、易过拟合的问题。本文ICNN-1D 具有如下特点:
1)每次卷积后不做池化操作,保存最后一层卷积得到的特征图;
2)采用跨层聚合的思想,多次卷积之后的结果分别进行全局平均池化和全局最大池化,将得到的两个结果通过keras中的concatenate方法进行合并,重构得到一个特征向量;
3)使用全连接层结合softmax得到分类结果,与真实值比较计算损失值,通过Adam 优化算法,迭代更新权值和偏置,直至收敛。
3.2 AFM-ICNN-1D整体结构
AFM-ICNN-1D 的整体结构如图1 所示,主要包含3 个步骤:
步骤1 数据预处理。此步骤主要是标准化数据值,由于特征值的数量级不一致,会影响检测性能及分类结果,所以将每个特征取值范围映射到[0,1]区间。
算法1 数据预处理算法。


步骤2 训练。根据最后预测的结果与真实值计算损失,通过反向传播不断迭代更新参数直至收敛。另外,在训练过程中利用先验经验结合实验结果修改一些超参数以提高检测性能,获得较高的准确率和召回率。
ICNN-1D 包含2个卷积层(conv1d1、conv1d2),2个全局池化层(gap1、gmp1)和1 个全连接层dense1。为了网络具备适度的稀疏性,使用ReLU 作为激活函数,在全局池化结果合并后使用的dropout 按一定概率暂时将一些神经元从网络中移除,避免过拟合现象的发生。
算法2 AFM-ICNN-1D的检测分类算法。

每一条网络流量记录的特征值构成一维向量,因此本文采用一维卷积神经网络。
在训练阶段,首先,数据标准化之后,将训练集送入ICNN-1D 进行训练。每次训练从训练集中随机选取一个固定大小的块(batch)作为输入。输入数据维度为特征值个数(n_features),通道(channel)为单通道。
其次,input经过conv1d1、conv1d2 两次卷积,利用卷积层对数据进行特征提取。每次卷积的输出结果在激活函数ReLU 的作用下作为下一层的输入数据。卷积后特征图中每个元素运算公式定义为:

其中:i代表卷积后特征图元素的位置,j代表该层卷积的卷积核序列号,c代表卷积核长度,m代表特征图的长度,b为偏置,g()为式(2)的ReLU函数。
然后保存卷积结果,分别送入全局平均池化和全局最大池化(gmp1、gap1),得到1×k个特征图,k表示保存卷积结果中特征图的个数。
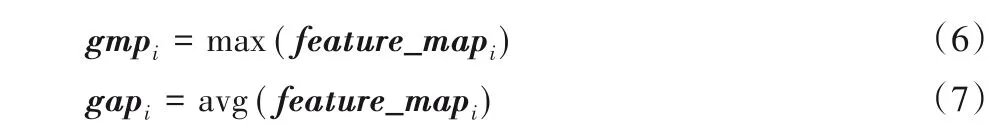
其中:i代表第i个特征图,max()、avg()分别对该特征图中的数值求最大和平均。
在全局池化后合并结果并压平,得到2×k维数据集合进行分类操作,输出该流量在各个类别概率值,概率最大值代表的类别即为该流量在AFM-ICNN-1D 中的预测类别。最后,根据真实值与预测值计算损失误差,迭代更新参数,直至收敛,得出一个训练模型。
步骤3 测试。在进行训练(步骤2)之后得到一个检测模型,使用测试数据集来检测其性能,根据真实值与预测值计算出评估指标值,判断性能是否优秀。如果测试结果表明该性能较优,则停止训练,AFM-ICNN-1D 由此得到;否则,将继续步骤2,重复训练。

图1 AFM-ICNN-1D结构Fig.1 Structure of AFM-ICNN-1D
3.3 方法的有效性与优势
本文方法使用ICNN-1D 构建模型,能有效地避免人工选择特征的繁琐,直接将数据集每条记录预处理后的原始特征作为模型输入,让网络自主提取。由于流量特征之间不具备关联性,卷积之后不使用池化操作很好地保留了流量的局部特征。在分类阶段,ICNN-1D没有采用多层全连接进行分类,而是在全连接之前跨层聚合全局池化的结果,再使用一层全连接。与传统基于CNN 的方法相比,AFM-ICNN-1D 能大大减少训练参数,缩短训练时间。
4 实验设计
4.1 CIC-IDS-2017数据集
本文实验使用的数据集是CIC-IDS-2017,该数据集包含了正常流量和常见攻击。数据捕获从2017 年7 月3 日(星期一)上午9 点开始,截止到2017 年7 月7 日(星期五)下午5 点。星期一只捕获到正常流量,星期二至星期五捕获到9 种攻击,分别为暴力破解FTP(FTP-Parator)、暴力破解SSH(SSHParator)、心脏出血漏洞(Heartbleed)、Web 攻击(Web Attack)、渗透(Infiltration)、僵尸网络(Botnet)、端口扫描攻击(PortScans)、DoS 和DDoS。数据集中每一条记录均有78 个特征值。由于采用5天的数据量较多,因此,选取周一50%的正常流量,以及周二至周五捕获到的异常流量作为本文实验的数据集。
4.2 数据预处理
在特征向量中,不同的特征一般具有不同的量纲和数量级。这种情况会造成每个样本不同特征值之间大小差异很大,从而影响到网络模型性能,数量级大的特征会明显影响到分类的结果。例如,在本文采用的数据集中,Flow Duration 特征值范围在[-1,119 999 993],FwdPacket Length Max 的特征值范围在[0,23 360],这两个特征具有不同的数量级。因此,需要采用标准化处理,消除数量级不同对实验结果产生的影响,同时加快计算处理。
本文实验采用了去均值方差归一化处理方式,使用sklearn 中StandardScaler 模块对数据进行预处理,将数据归一化到均值为0、方差为1的正态分布的正负数之间。均值方差归一化计算公式如式(8)所示。

式中:X代表每一组特征值,Xmean代表该组特征的平均值,σ代表该组特征的标准差。
4.3 实验环境与超参数设置
本文实验训练和测试均在Windows 系统环境下进行,使用keras搭建网络模型,采用Tensorflow-CPU进行计算,实现本文提到的AFM-ICNN-1D。
在机器学习或深度学习中,研究者需要在学习之前根据自己的经验和专业知识设置一些参数,选择一组相对最优的超参数训练出模型,这些参数不会根据优化算法进行迭代更新,称为超参数。
经过多次实验调整参数,本实验选择了以下超参数训练出一维卷积神经网络:
1)学习率:它决定着损失函数(loss)能否在合适的时间收敛到最小值。因为过小的学习率会造成收敛速度十分缓慢,而过大的学习率可能造成梯度在最小值附近来回震荡,从而无法达到收敛。经过多次小范围的调整,本文实验的学习率设置为0.01时,网络效率较优。
2)mini-batch:假设训练集含有100 条数据,将这100 条数据分成10 个块,那么其中每一个块称之为一个mini-batch。模型训练中,每次取出一个mini-batch,计算损失,根据优化算法,更新网络权重和偏置。如果mini-batch 的值太小,则无法运用到矩阵库的快速运算,从而学习变得缓慢;如果值选择太大,不能很好地更新权重。因此,需要选择一个折中的值,使得运算速率、权重更新最优化。本实验中mini-batch 设置为100。
3)epoch:网络每次训练完全部训练集称为一个epoch 周期。如果epoch 设置太小,会使得网络没有充足的数据和时间去训练得到最优参数;如果epoch 设置过大,会使得网络训练过拟合,造成测试准确率较低。由于本文实验训练数据较多,epoch设置为5,训练效果较好。
一般来说,为了得到较优的准确率,研究者一般会将网络模型设计得较深,以得到更高级的特征。但层数越深,参数越多。从理论上说,参数越多,模型拟合程度越好,但也越容易出现过拟合。根据多次实验,本文实验的卷积核大小、卷积核个数、卷积层数分别设置为3、64、2。
4.4 评估指标
本实验采用精确率(precision)、召回率(recall)、F1-Score及ROC(Receiver Operating Characteristic)曲线来作为评估性能的指标。
混淆矩阵是评估指标,也是本文采用的指标的基础,通过混淆矩阵计算出4 个基础指标:真正类(True Positive,TP)代表被正确分类的正例数量;假负类(False Negative,FN)代表将正例错分为负例的数量;假正类(False Positive,FP)代表将负例错分为正例的数量;真负类(True Negative,TN)代表正确分类的负例数量。

表1 ICNN-1D结构与参数Tab.1 Structure and parameters of ICNN-1D
在混淆矩阵计算出基础指标后,可以获得本文所采用的4个指标。
精准率P即分类结果预测为正例的样本中实际为正例的比例。计算如下:

召回率R即真实值为正例中预测正确的比例。计算如下:

F1-Score 是综合精确率和召回率两个指标所产生的值,它的范围是[0,1],1 代表性能最好,0 代表性能最差。计算如下:

ROC 曲线是由真阳性率(True Positive Rate,TPR)和假阳性率(False Positive Rate,FPR)绘制而成,FPR 和TPR 分别为x、y轴。TPR 代表在所有正例中正确分类的比重,FPR 代表在所有负例中被错误分为正例的比重。ROC 曲线越接近左上角,代表分类性能越好。
5 实验结果与分析
5.1 CIC-IDS-2017池化对比实验
在训练过程中,设置epoch 为5,损失值逐渐减少直至收敛,训练集和验证集F1值高达97%以上。在测试集进行分类后输出10维的混淆矩阵,如表2、3所示,该矩阵对角线的数值为各类别样本被预测正确的比重(精确到小数点后两位)。表2 是有池化层的卷积神经网络预测的结果,可以看出,几乎每一类别预测准确率都在87%以上,DoS 和DDoS 相对相低;表3 是没有池化操作的卷积神经网络预测的结果,可以看出,与有池化相比,该网络的预测准确率都达到了94%以上,效果更佳。
在CIC-IDS-2017 测试集中,每一个类别的预测精准率和召回率都在94%以上,同时,F1值几乎都接近97%。通过这三个指标可以看出本文提出的AFM-ICNN-1D 对CIC-IDS-2017数据集的检测性能较好。为了更加直观地评估该方法的检测性能,根据测试后的结果绘制了关于误报率和召回率的曲线图,即ROC 曲线图。ROC 曲线越接近左上角说明分类越准确,检测性能越优秀。从CIC-IDS-2017 测试集ROC 曲线(图2)可以看出,本文提出的方法对CIC-IDS-2017 数据集10分类测试的ROC拟合程度较好。

表2 测试集混淆矩阵(有池化操作)Tab.2 Test set confusion matrix(with pooling)
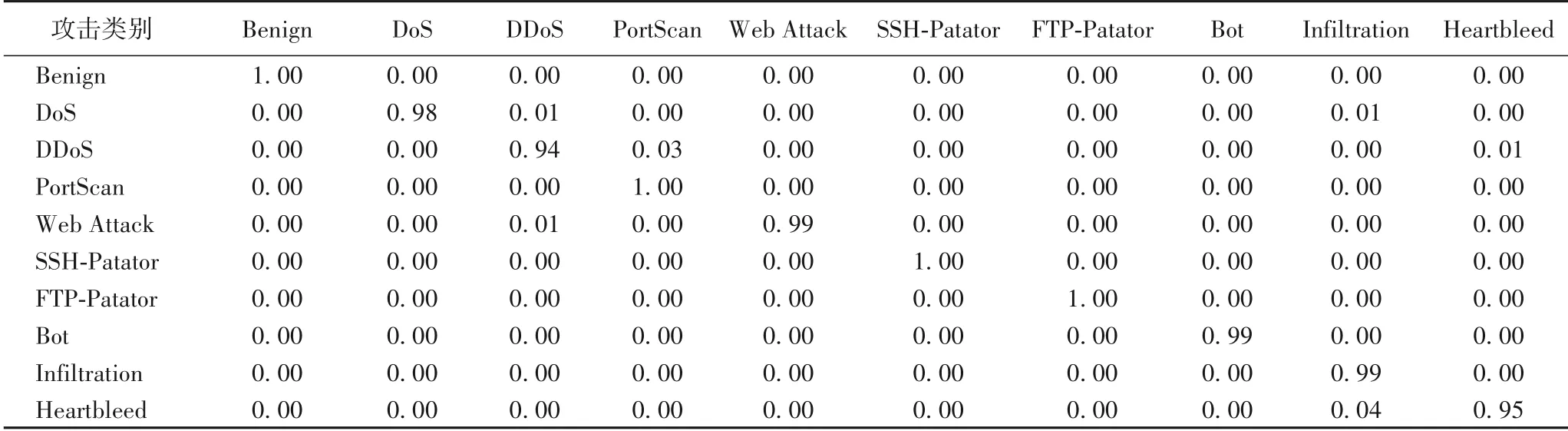
表3 测试集混淆矩阵(无池化操作)Tab.3 Test set confusion matrix(without pooling)

图2 CIC-IDS-2017测试集上的ROC曲线Fig.2 ROC curves on CIC-IDS-2017 test set
5.2 CIC-IDS-2017全局池化与多层全连接对比实验
将AFM-ICNN-1D 与基于两层全连接模型(dense100-dense10)异常流量检测方法(AFM-Dense100-Dense10)进行对比,dense100-dense10具体结构与参数如表4所示。
dense100-dense10在卷积后采用两层全连接,第一层全连接有100 个神经元,第二层神经元个数为数据集的类别个数,即10,其余超参数设置与ICNN-1D 一致。ICNN-1D 共有13 898 个参数,相较于dense100-dense10,减少了约97%。经实验,AFM-ICNN-1D 的训练时间需要35 min 47 s,而AFDDense100-Dense10 则需要57 min 43 s,相比较而 言,AFMICNN-1D 减少了约40%的训练时间。与AFM-ICNN-1D 的实验结果相比,AFM-Dense100-Dense10 的测试效果(表5)不佳,个别类别的识别准确率仅达到40%左右。可见,AFM-ICNN-1D 在时间和测试准确率方面与AFD-Dense100-Dense10 相比都具有较好的表现。

表4 dense100-dense10网络结构与参数Tab.4 Network structure and parameters of dense100-dense10
5.3 AFM-ICNN-1D与其他异常流量检测方法对比
将本文方法与kNN、随机森林(Random Forests,RF)、ID3算法、Adaboost 迭代算法、多层感知机(Multi-Layer Perceptron,MLP)、朴素贝叶斯(Naive-Bayes)和二次判别分析(Quadratic Discriminant Analysis,QDA)在CIC-IDS-2017 数据集上进行比较,结果如表6,可以看出AFM-ICNN-1D具有较好精准率、召回率及F1值。由表6 可知,传统机器学习中kNN、RF、ID3 算法也同样具有较好的检测结果,但是,为了降维和提高准确率,机器学习方法需要进行特征选择;而本文方法在特征选择这一方面具有较好的优越性,可以使用卷积自动将低级特征抽象为高级的特征,节省时间与人力。另外,本文方法在多分类的检测上也具有较好的结果。
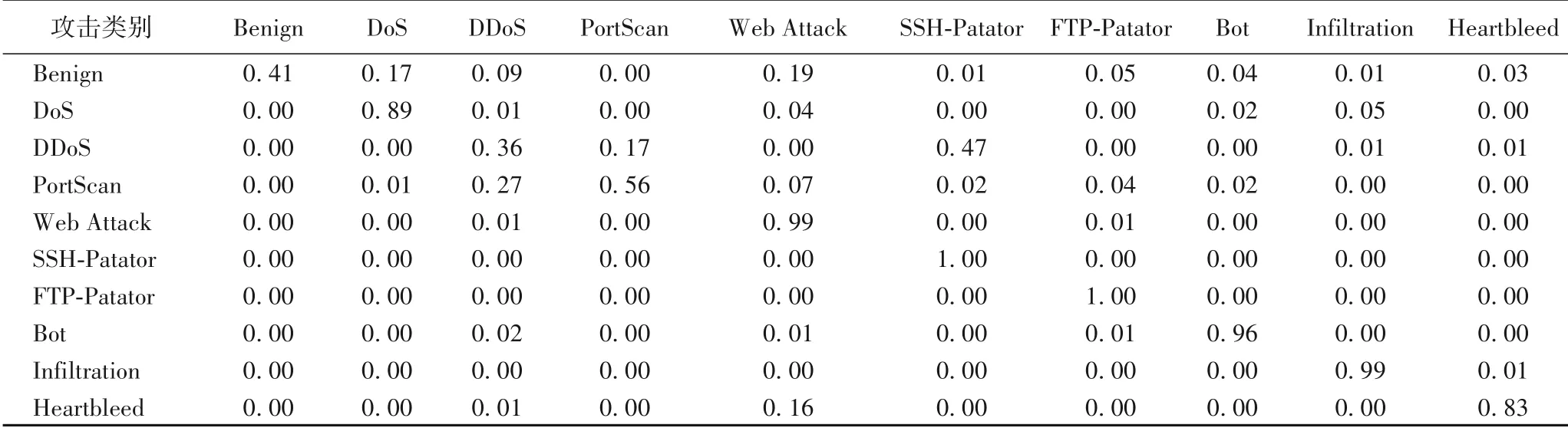
表5 测试集混淆矩阵(AFD-Dense100-Dense10)Tab.5 Test dataset confusion matrix(AFD-Dense100-Dense10)

表6 各异常流量检测方法的P、R和F1值Tab.6 Precision,recall and F1-Score of abnormal flow detection methods
5.4 NSL-KDD分类结果评估
为了验证本文方法的通用性,本文还使用了另一个网络安全领域常用的数据集NSL-KDD 进行测试,由于NSL-KDD数据集中含有字符特征,需将其进行数值化处理。同样,在训练时,epoch仍为5,模型达到最优,准确率(accuracy)达到96%以上。由表7 可见,本文提出的AFM-ICNN-1D 方法对NSLKDD 数据仍然具有很好的性能。Normal、DoS、远程用户攻击(Remote-to-Login,R2L)、提权攻击(User-to-Root,U2R)和端口攻击(Probe)这5 个类的精准率分别为95.6%、99.3%、97.4%、97.0%和93.3%,同时各个类的召回率和F1-Score 指标也都达到90%以上。由此可见,AFM-ICNN-1D 对于CICIDS-2017 和NSL-KDD 这两个数据集的检测性能都较好,本文的检测方法具有较好的通用性。

表7 本文方法在NSL-KDD数据集上的P、R和F1值Tab.7 Precision,recall and F1-Score of the proposed method on NSL-KDD dataset
6 结语
深度学习能从原始数据中自动抽象提取高层特征,学习样本的内规律和层次,对海量高维数据具有较高的适应性,很好地解决了传统机器学习中特征工程的问题,因此本文提出了基于改进一维CNN 的异常流量检测方法AFM-ICNN-1D。本文方法与基于传统CNN 结构的方法区别在于未采用卷积后的池化操作,另外,在全连接层前使用全局池化,并利用跨层聚合将结果作为全连接层输入。实验结果表明,本文的AFM-ICNN-1D 方法具有良好的检测性能,与基于两层全连接模型的检测方法相比,该方法的参数量更少,且训练时间较短。
将来仍有两项工作要做:首先,需要提高检测精度及方法的泛化能力,尝试修改CNN 模型的结构以达到目标;其次,由于检测时间也是异常流量检测的关键,因此在提高检测精度的同时还应强调该方法需要满足检测时间的要求。此外,还将考虑如何将该方法运用到在线流量检测中。
