基于动态和静态偏好的兴趣点推荐算法
2021-03-07王时绘
杨 丽,王时绘,朱 博
(1.湖北大学计算机与信息工程学院,武汉 430062;2.中国船舶重工集团公司第709研究所,武汉 420205)
(*通信作者电子邮箱yangli_lc@163.com)
0 引言
近年来,移动设备的日益普及和无线通信技术的进步促使了基于位置的社交网络(Location Based Social Network,LBSN)的快速发展。LBSN 将互联网网络空间与物理世界联系在一起,从而使用户可以轻松地基于智能设备通过发布签到、评论以及地点图像来分享他们的经验,帮助其他用户找到有趣的位置地点。兴趣点(Point-Of-Interest,POI)推荐服务不仅可以通过为用户提供具有吸引力的场所来使其受益,而且还可以促进相关企业进行有针对性的广告投放,显著提高企业效益。这类服务利用LBSN 中大规模用户-兴趣点交互式数据为用户提供丰富的推荐服务,也为工业界和学术界提供了一个很好的机会来获得对用户偏好和用户行为更深入的了解[1]。
近年来,已有大量基于时空序列模式的兴趣点推荐研究工作,精准挖掘了用户移动模式中隐含时空序列特征,然而这一问题并没有获得深入研究[2]。由于以下原因,兴趣点推荐仍然是一项具有挑战性的研究任务:
1)时空信息被认为是一种重要的信息类型,常常用于建模POI推荐系统中用户复杂的动态偏好。现有基于时空序列的兴趣点推荐模型中,主要利用循环神经网络(Recurrent Neural Network,RNN)模型或者马尔可夫链模型基于签到信息的时空序列特征来实现用户复杂动态偏好的建模。一阶马尔可夫链模型无法区分某些局部时空背景下用户的个性化签到,使得所有用户的签到行为最终建模为统一的签到位置序列模式,而基于n阶马尔可夫链模型的计算成本又极其高昂[3]。一些研究工作[4-6]偏好采用RNN 模型建模时空序列信息。但是,现有基于RNN 的兴趣点模型大多忽略了用户签到序列模式中的跳过行为,即签到行为的影响可能会跳过几个时间序列仍然影响用户正在进行的签到行为[7]。例如,游客在机场、酒店、餐厅,酒吧和旅游景点顺序进行签到。尽管在机场和酒店签到后不会立即去旅游景点签到,但它们与后面的酒吧、旅游景点之间存在着强烈的关联行为。另一方面,餐厅或酒吧的签到可能对景点的签到行为没有影响。
2)注意力机制已经在各种机器学习任务中展示了自身的有效性。在推荐系统领域,文献[8]中融合两个基于注意力网络用于建模用户之间的社交影响从而精准捕获用户的复杂动态偏好和一般静态偏好;文献[9]通过在门控循环单元(Gated Recurrent Unit,GRU)网络中加入注意力机制,来模拟音乐推荐中用户的短期兴趣。然而,上述这些常用的注意力方法大多是一阶的,它们无法捕获复杂签到序列之间的相互作用以及偏好引起的签到位置序列之间细微差别[10]。
在现实世界的推荐场景中,用户对兴趣点的偏好并不总是固定的,而是随着时间的变化而变化。然而,尽管用户的兴趣随时间变化,但仍有一些长期因素会影响用户的行为,这反映了他们的一般长期静态偏好。因此,现在大多数研究人员认为每个用户的偏好都由两部分组成:一部分是一般长期静态偏好,不会随着时间的变化而变化;另外一部分属于复杂的动态偏好,则很容易受到时空因素等的影响[11-12]。这就是为什么最近主流先进方法倾向于将一般长期静态偏好建模和复杂动态偏好相互作用结合在一起用于用户偏好精准建模的原因。
为了解决上述问题,本文提出一种基于注意力机制的动静偏好融合的兴趣点推荐算法CLSR(Combing Long Short Recommendation)。具体而言,首先利用一种混合GRU 神经网络实现了基于用户时空签到序列和签到跳过行为的复杂动态偏好建模,同时利用高阶注意力网络学习用户的一般静态偏好;然后基于2 个含有隐藏层的多层神经网络分别进行多层投影学习,以进一步学习和表示这些动态偏好和静态偏好的特征;最后,用户的复杂动态兴趣和一般静态兴趣都基于统一的框架融合,实现用户的偏好建模。基于2 个真实数据集的实验结果表明,本文提出的兴趣点算法优于主流先进的兴趣点推荐算法。
1 相关工作
1.1 兴趣点推荐算法
大多数兴趣点推荐模型模拟用户的长期偏好,这种偏好反映了用户偏好的固有特征,并且是静态的。基于因子分解的协同过滤方法[13]是实现这一目标的最有效方法之一。在现实世界中,用户对兴趣点的偏好并不是一成不变的,而是会随着时间而变化。因此,在推荐过程中获取用户兴趣的时间动态变化特征很重要。Cheng 等[14]提出了一个基于一阶马尔可夫链模型建模用户的POI签到行为。Zhao等[15]提出了一个名为STELLAR 的基于排序策略的成对张量因子分解框架。STELLAR 结合了细粒度的时间上下文信息(即月、周日/周末和小时),并最终带来了推荐性能的显著改善。Xie 等[16]提出了利用二分图的推荐方法,称为GE模型。该模型将兴趣点推荐的多个上下文因素在基于图模型的统一框架中实现融合建模提供兴趣点推荐服务。实际上,以上POI 推荐模型都依赖于基于浅层线性潜在因子的模型,并且严重依赖于人工定义随时间变化的时间演化模式,因此,它们很难捕获用户动态偏好的内在复杂关系。随着基于神经递归网络的方法基于许多时空数据得到了成功应用,一些开创性的研究工作将深度学习方法——RNN 模型用于基于时空序列模式的兴趣点推荐建模,并取得了不错的效果。Li 等[4]基于GRU 模型实现POI推荐中的时空序列建模;文献[3]则利用RNN 模型建模用户签到行为中的时间转变模式;而文献[11]则采用了递归神经网络模型用于POI 推荐中POI 签到时空序列轨迹的深度表示。
1.2 注意力机制
注意力机制起源于神经科学研究,通过经验证明人类通常关注输入的特定部分而不是所有可用的信息[17]。基于注意力机制的深度学习是人类视觉中的选择注意力机制与深度神经网络的结合产物,目前在计算机视觉、自然语言处理等领域取得了巨大成功,例如图像识别[18]和机器翻译[19],但它最近已被用于推荐任务[20-22]。Xiao 等[20]提出了一个注意力因式分解机模型,其中特征交互的重要性是通过注意力网络来学习的。Zhou 等[21]采用注意力网络来计算不同用户行为(如阅读评论、购物和订购)的权重,以对电子商务站点中的用户偏好进行建模。Chen 等[22]提出了一个细粒度的协同过滤框架用于提供推荐服务,注意力网络被用于学习这些组件的注意力得分以获得更好的项目表示。注意力网络还应用于顺序推荐[23]、基于评论的推荐[24-25]等。
相比较而言,本文提出的CLSR 算法与上述工作存在的区别有:
1)本文基于用户复杂动态偏好和一般静态偏好融合来精准建模用户的偏好。
2)鉴于用户签到行为中兴趣点与用户之间基于时空序列模式的复杂性,在建模复杂动态偏好过程中不仅仅考虑了用户的历史签到行为,还考虑了基于时序模式签到行为的跳过行为。唯有这样建模,才能更贴近现实场景。
3)在一般静态偏好建模过程中,本文提出基于高阶注意力网络来学习长期用户签到行为序列模式中依赖关系的重要偏好等细粒度特征。具体而言,将普通注意力机制通过高阶多项式进行高维度化,以更好地捕捉关联的细粒度表征。
2 问题形式化与预备知识
2.1 形式化问题描述
令U={u1,u2,…,u|U|}表示一组用户,而V={v1,v2,…,v|V|}表示一组POI,其中| ⋅|表示相应集合的基数。对于用户u,将其当前签到会话表示为Sessionu={(v1,action1),(v2,action2),…,(vϑ,actionϑ)},其中,vi是签到会话中的第i个兴趣点,actioni表示第i个签到动作,ϑ表示当前签到行为会话中的行为数。同时,本文考虑用户的历史会话中与之交互的兴趣点,并将它们表示为Historyu=在此,φ表示用户与兴趣点的历史互动中的签到数量。每个用户历史签到的集合基于V得到。鉴于用户对兴趣点签到的行为,本文的目标是给每一个用户推荐他(她)还没有访问过且感兴趣的兴趣点。
2.2 GRU网络
GRU 网络是RNN 的变体,由在时间步骤t具有对于状态ht有影响的前一个单位ht-1的隐藏状态的门控机制组成,具体如下公式:

其中:gt和st分别是更新和重置门;是候选隐藏状态;是各个单元的权重参数;σ和tanh 分别是Sigmod函数和激活函数;⊙是元素感知的内积。
3 CLSR兴趣点推荐算法
本文算法的框架如图1 所示。具体而言,首先,利用一种混合GRU 模型学习用户偏好复杂动态变化时序特征;同时基于注意力机制提出基于高阶注意力网络的因子分解模型学习用户一般长期静态偏好;然后采用基于两个多层神经网络实现多层投影学习用户的时序、兴趣点等更加精准的特征;最后采用统一端到端推荐框架融合动态和静态用户偏好。
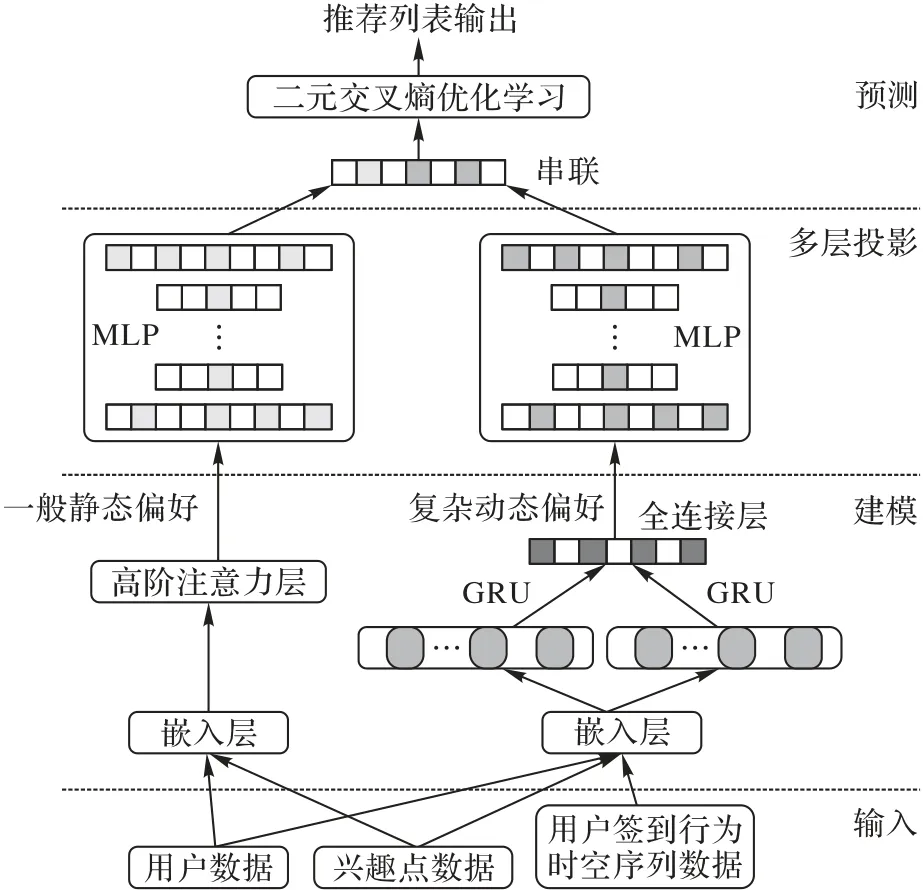
图1 CLSR算法的框架Fig.1 Framework of CLSR algorithm
3.1 嵌入层
将原数据表征为单个的向量,从而映射到相应的向量空间中,公式如下:

其中:u为标识映射后的结果,R表示潜在因子矩阵。经过嵌入层后,可以得到δ维的特征向量。
3.2 一般静态偏好建模
为模拟用户固有的或变化缓慢的一般静态偏好,采用了矩阵分解技术,它是学习一般静态偏好的最成功方法之一。受到文献[13]工作的启发,本文采用与用户交互的位置序列来表示用户的一般静态偏好:

其中ςj是签到actionj的权重得分。本文假定并非用户所有签到行为都对最终的推荐起到了同等重要作用,因此要为有些签到行为分配较高的权重,而为另一些签到行为分配较低权重。普通注意力机制无法捕获复杂的相互作用以及序列之间的细微差别,缺乏对细节性描述。为了更好捕获位置序列特征之间的复杂关系,受到文献[18]启发,基于高阶多项式的高阶注意力网络对比序列间的差异,提取更加重要的细粒度特征,同时实现权重按实际分布分配。具体而言,将普通注意力机制通过高阶多项式进行高维度化,能够进一步增强注意力表示知识的丰富性。

其中:Wa、Wb、Wc是注意力网络的权重参数;ai、bi、ci分别是第一阶、第二阶和第三阶注意力权重的中间结果;i是每阶需要计算的数目,如第三阶需要计算3 次,即c1、c2、c3进行点积运算,然后通过多项式组合得到高阶权重,再与原特征相乘完成权重的重新分配。本文提出的高阶注意力网络使用ReLU 作为隐藏层的激活函数,将高阶组合的特征投影到m中,得到如下公式:

其中,基于m,用Softmax 函数对得分进行归一化,得到本文提出的高阶注意力得分。同时,通过高阶注意力网络的优化与处理,一般静态偏好能够基于实际分布完成对位置序列等权重的重新分配,从而不再受制于固定的权重,使一般静态偏好建模拥有更好的鲁棒性。
3.3 复杂动态偏好建模
考虑基于GRU 网络建模用户签到行为以及签到行为中的跳过行为,将2个建模进行自适应融合构成混合GRU网络,从而精准捕捉用户偏好的动态变化性。
给定一个POI的序列,每个序列与签到时间相关联,本文计算相邻POI 之间的时间间隔为Δτt=τk-τk-1,k∈[1,|t|]。然后,基于式(1)~(4)得到新的候选隐藏状态。

同时,本文基于GRU 建模用户签到过程中的跳过行为。具体地,如图1 所示,在相邻时段中,在当前隐藏单元和相同相位的隐藏单元之间添加跳过行为建模,基于式(1)~(4),得到如下公式:

其中:β是跳过的隐藏单元的数量表示偏置向量。本文使用全连接层来整合上述2 个的输出。全连接层的输入包括在时间戳t处的隐藏状态(用表示)和从时间戳t-β+1 到t处的β递归跳过的隐藏状态,由表示。因此,基于式(11)~(16),全连接层的输出计算如下:


3.4 多层投影神经网络
利用多层投影神经网络的多层特性学习用户和位置之间的潜在特征,以进一步将用户特征投影到一个公共的低维空间中。在形式上,对于一个多层投影神经网络,设置zi(i=1,2,…,N)表示第i个隐藏层的输出,ξi和ιi分别表示第i层的权重和偏置向量,ReLU函数作为多层神经网络各层的激活函数,如果将输入向量表示为e,将最终输出的潜在表示向量表示为q,得到各层中的具体表示如下:

3.5 预测层
采用端到端的方式将两个多层神经网络的输出结果进行融合,各自学习到的交互函数的输出在预测层融合在一起。预测层的输出结果即为整个CLSR 模型的输出,并根据这个输出的结果,得到最终的推荐结果列表。预测层的输出为如下:

二元交叉熵损失函数是基于神经网络优化参数训练的一个很好的选择。因此,CLSR算法的目标损失函数如下:

本文采用Adam[26]对上述损失函数进行优化,从而得到最终输出推荐列表。
兴趣点推荐算法CLSR步骤描述如下:

4 实验与分析
为了验证本文模型的性能,主要在真实数据集下将本文模型与其他主流先进兴趣点推荐模型进行对比和分析。
4.1 实验数据集
实验在两个公开数据集Foursquare[27]和Gowalla[28]上进行,而且清除了Foursquare 数据集中少于10 条签到记录的用户和兴趣点(签到时间范围从2012 年4 月至2013 年9 月),而对签到数据分布在全球范围的Gowalla 数据集则清除了少于10条签到记录的用户和少于15条签到记录的POI。相关特征统计如表1 所示。在这两个数据集中,一个用户应该至少访问5 个不同的兴趣点。在本文的实验中,随机选择数据集的70%的数据集作为训练数据集,使用接下来的10%作为验证集,同时所有模型采用最佳超参数设置,其余20%作为测试数据集。

表1 过滤前后数据集的特性统计Tab.1 Statistical characteristics of datasets before and after filtering
4.2 评估指标
本文采用了准确率Precision(P@K)、召回率Recall(R@K)和归一化折损累积增益(normalized Discounted Cumulative Gain,nDCG)作为评估指标。其中,准确率和召回率的计算公式中是用户u的top-k 推荐兴趣点列表,而是用户u在测试集中的访问兴趣点列表,K表示兴趣点推荐的个数。

对于这两个评估指标,设置K=5,10,20进行实验。
对于目标用户u,其推荐列表排在位置vorder的兴趣点的nDCG值计算公式:
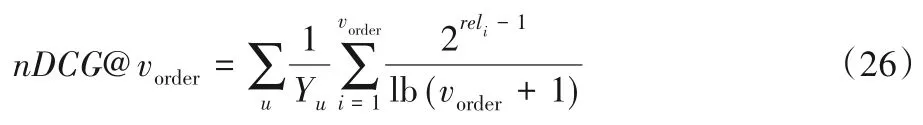
其中:Yu表示用户u的最大DCG 值;reli表示第i个兴趣点与用户的相关度,reli为1 表示相关,否则reli=0。实验设置推荐列表的长度vorder=5,10。
4.3 实验方案设计
为了验证本文算法的有效性与先进性,从以下方面对CLSR算法进行测试。
1)将本文提出混合GRU 的方法与以下三个主流的时序建模方法进行对比,从而验证本文提出考虑用户签到过程中的跳跃行为的有效性和先进性。
a)基于卷积序列嵌入的推荐方法Caser(Convolutional Sequence Embedding)[7]:此方法基于CNN 模型建模时空序列。将L个先前项目的嵌入矩阵视为“图像”,因此,基于CNN模型使用水平卷积层和垂直卷积层分别捕获点级和联合级序列模式。
b)基于前k个收益的循环神经网络序列推荐方法GRU4REC(Recurrent Neural Networks with Top-kGains)[29]:此方法基于RNN 模型建模时空序列。大多数采用RNN 模型建模时空序列模型都是以此模型为基础。
c)基于马尔可夫链融合相似度模型的序列建模方法Fossil(Fusing similarity models with Markov chains)[30]:此方法基于一种高阶马尔可夫链模型建模时空序列。
2)基于高阶注意力网络、普通注意力机制与没有注意力机制的三种情况对CLSR 的性能进行对比,从而验证本文提出的高阶注意力网络的有效性和高效性。
a)没有注意力机制(No-attention):代表在CLSR 算法中忽略掉高阶注意力网络;
b)普通注意力机制Vanilla(General attention)[8]:代表在CLSR算法中将高阶注意力网络替换成普通注意力机机制。
3)将本文模型与以下四个主流先进POI推荐方法进行对比,从而验证本文方法的有效性和先进性。
a)个性化马尔可夫链和用户位置受限的推荐方法FPMC-LR(Personalized Markov Chain and Localized Region)[14]:该模型提出了一种基于局部区域约束的扩展因子分解个性化马尔可夫链且考虑邻域位置的兴趣点模型。
b)基于时间和多级上下文注意力机制的下一个兴趣点推荐方法TMCA(Temporal and Multi-level Context Attention)[4]:该模型采用基于LSTM 的编码器-解码器框架来自动学习用户历史签到活动的深度时空表示,并集成了多个上下文因素;此外,该模型还使用多级上下文注意力机制来自适应地选择相关的签到活动和对应的上下文因素。
c)基于个性化排名度量嵌入的推荐方法PRME(Personalized Ranking Metric Embedding)[31]:是一种个性化排名度量模型,联合建模序列信息和个人偏好,通过将每个兴趣点映射到对象的低维欧氏空间,然后使用度量嵌入算法有效地计算马尔可夫链模型中的位置转换。
d)基于排名的地理分解兴趣点推荐方法Rank-GeoFM(Ranking based Geographical Factorization Method)[32]:是一种基于排名的地理分解方法,通过适合用户的POI 签到频率来学习用户兴趣点的嵌入;同时,时间上下文和地理影响都基于加权方案纳入了最终的推荐框架。
4)分析一般静态偏好建模组件(L-CLSR)、复杂动态偏好建模组件(S-CLSR)对于本文CLSR算法推荐性能的影响。。
5)讨论CLSR 算法不同组件的影响,以及多层投影神经网络的潜在维度和神经网络层数对于CLSR 算法推荐性能的影响。
4.4 实验设置
实验中所有算法都基于最优参数进行设置。GRU 网络的隐藏维度是32,嵌入维度为32。对于Foursquare 数据集和Gowalla 数据集,“跳过”的长度设置为6,从{0.001,0.01,0.1,1,10}中选择正则化系数,以获得最佳性能。梯度下降超参数学习率设定为0.001。使用含有4 个隐藏层的神经网络,4 个隐藏层都使用ReLU 函数作为激活函数。对于Fossil、Caser和GRU4REC,马尔可夫阶L为{1,2,…,9}。实验中CLSR 算法的多层投影神经网络的隐藏层的结构是(128,64,32,16),潜在维度是64。Adam 算法被用来优化CLSR 算法的参数。除了输入层和输出层,在每一层后采用dropout,速率设置为0.1到0.2。全连接层的dropout 的比例为0.5。本文模型通过在配置Nvidia GeForce GTX 1080 显卡的机器上运行PyTorch 实现。其他对比算法都参照各自参数的最佳设置。
4.5 实验结果分析
4.5.1 时空建模方法对比分析
从图2可以得到如下结论:
1)在两个数据集上,Spatio-SR 模型的所有指标均表现得更好。具体而言,首先Spatio-SR 模型显著优于传统基于高阶马尔可夫过程的方法Fossil,验证了神经网络方法的强大。这也与前面的讨论一致,即由神经网络模型提供的非线性变换操作能够实现更好的高级空间意图学习。此外,Spatio-SR 始终优于其他两种方法,这表明在Spatio-SR中采用混合GRU 模型是有效的。原因如下:本文基于混合GRU 模型对用户签到过程中典型的短期动态变化个性化签到现象及其跳过现象进行建模,很好地弥补了Caser 模型和RNN 模型在建模序列信息中无法精准捕获用户个性化签到时空序列信息的各种不足,这一点和文献[5,7]所指出的一致。
2)在两个数据集上,Fossil 的所有指标均表现最差,因为该方法对于最终长期时间变化和短期时间动态变化的融合仅仅采用了简单的线性加权,不足以捕获特征之间复杂的交互关系;同时高阶马尔可夫链模型随着阶数的增大,噪声和无用的相关信息也逐渐变多,从而影响了最终的性能。
3)Caser方法作为典型的基于CNN建模,采用将最近的项目序列嵌入到潜在空间的“图像”中,并将序列模式作为该“图像”的局部特征,从而采用基于联合卷积过滤器进行图像识别的方法捕捉局部特征。显然,相比RNN 而言,基于CNN 建模的优点在于其具有从某个区域学习局部特征以及不同区域之间的相互关系的能力,可以有效地捕获通常被其他基于RNN模型忽略的联合级序列之间依赖关系。但是如同文献[5]所指出的计算机视觉方法中基于CNN 模型对于图像局部特征建模中可能存在丢失重要序列信息的现象,这个现象也存在于时空序列建模中。因此,Caser性能优于GRU4REC模型。
综上,Spatio-SR 模型成功地学习了基于短期复杂动态时空变化的用户个性化偏好,从而使得本文提出的模型具有优越性能。

图2 在Foursquare和Gowalla数据集上不同方法的推荐性能对比Fig.2 Recommendation performance comparison of different methods on Foursquare and Gowalla datasets
4.5.2 高阶注意力网络性能对比分析
从图3 可以看出,对比高阶注意力机制和普通注意力机制,高阶注意力网络可以有效地提高CLSR 算法的性能,更好地应对普通注意力网络无法准确学习用户-POI 交互之间基于时空序列会话复杂关系的问题。此外,高阶注意力可以突出相关重要特征,并减少不相关特征的干扰,它可以捕获更加准确的用户和兴趣点特征,捕获用户兴趣点的动态交互的复杂性,从而提高模型性能,这与文献[33]的结论也是一致的。但是,值得注意的是,这样的高阶注意力网络架构也需要花费更多的时间,具有更加复杂的网络结构[33]。因此,本文也只采用了三阶注意力网络。此外,对比没有注意力网络而言,普通注意力网络对于最终性能的提高也有一定的作用,高阶注意力网络通过更加精准地建模不同特征之间的相关作用,达到了最终提高推荐性能的目的。。
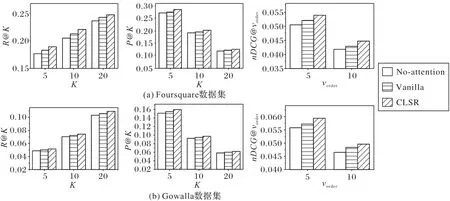
图3 在Foursquare和Gowalla数据集上本文提出的高阶注意力网络与其他注意力方法的推荐性能对比Fig.3 Recommendation performance comparison of the proposed high-order attention network and other attention methods on Foursquare and Gowalla datasets
4.5.3 兴趣点推荐算法性能对比
图4 展示了本文提出的CLSR 算法与多个不同主流先进POI 推荐模型的对比实验结果。可以得到如下结论:
1)CLSR 算法始终表现最佳,并显著提高了两个数据集上POI 的推荐性能。CLSR 算法的优势在于它通过动静偏好学习融合精准捕获用户真实偏好。CLSR 算法对于时空序列的建模方法体现了神经网络基于一种深层次非线性结构具有强大的获取用户和兴趣点深层次特征的能力,同时高阶注意力对于提高捕获用户长期兴趣偏好的作用不可小觑。
2)基于神经网络的方法优于基于非神经网络的传统方法。对于TMCA 而言,分层注意力结构和RNN 模型的结合的确对于POI 推荐性能的提高起到了帮助作用,但是,相比而言,基于用户的历史签到行为和近期的签到行为会话互动融合建模的CLSR算法对于最终性能的提高帮助更大。
3)PRME 和RankGeoFM 优于FPMC+LR,这说明在现实世界中,仅考虑签到序列中最近访问的位置远远不够。用户对于兴趣点的偏好预测应当取决于用户的历史签到信息、用户的访问时间信息和其他上下文相关信息。
4)PRME 和RankGeoFM 这两个模型的性能不相上下,一个可能的原因是PRME 和RankGeoFM 本质上都属于利用基于排名的优化策略,两个模型均通过利用未观察到的负采样学习相关模型参数,使得对比FPMC-LR 模型而言,缓解了数据稀疏性对最终性能的困扰。
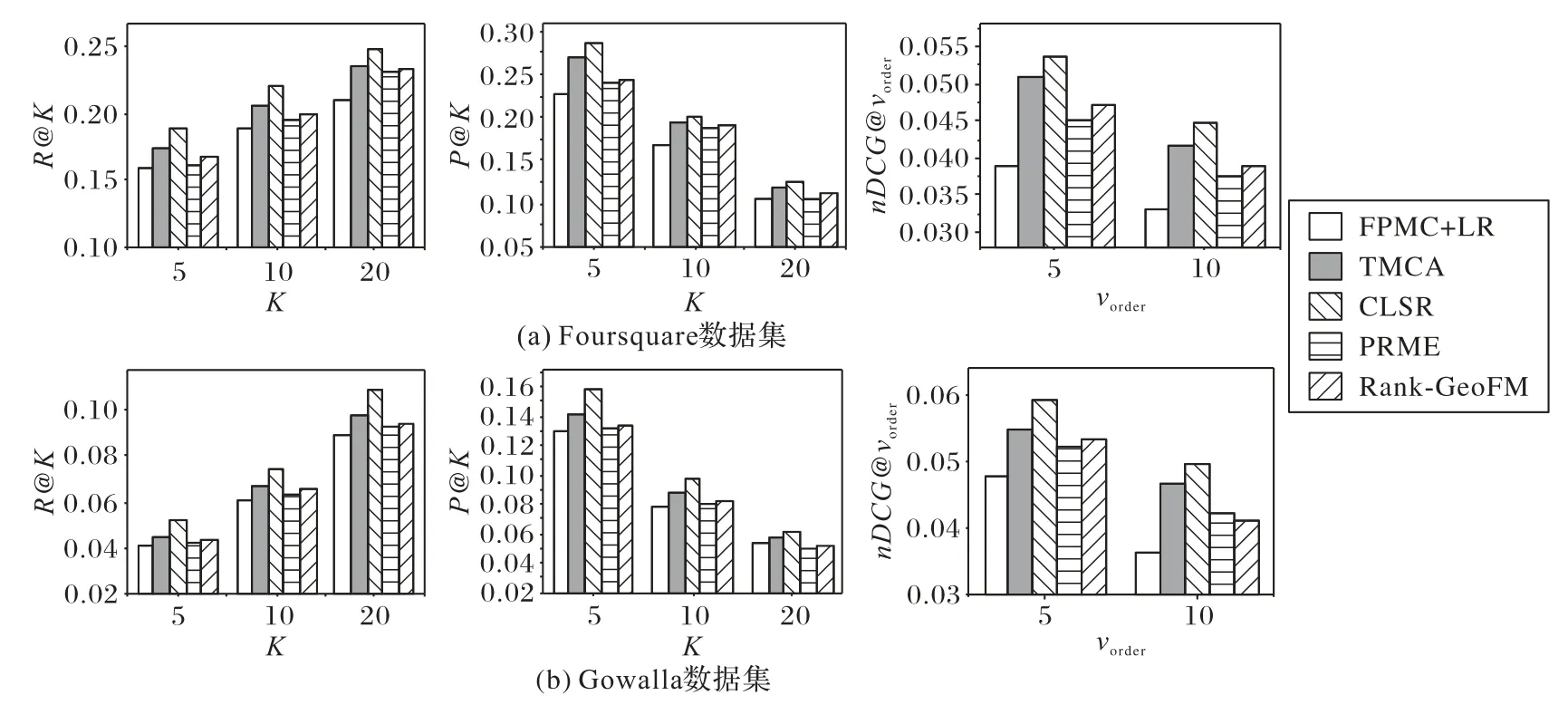
图4 在Foursquare和Gowalla数据集上本文CLSR算法与其他方法的性能对比Fig.4 Recommendation performance comparison of CLSR model and other models on Foursquare and Gowalla datasets
4.5.4 组件影响分析
图5展示了一般静态偏好建模组件(L-CLSR)和复杂动态偏好建模组件(S-CLSR)如何影响本文CLSR 算法的最终性能。当K值取5,10,20 时,准确率和召回率的变化趋势与图2~4 是一致的。对比分析基于Foursquare 和Gowalla2 个数据集的准确率和召回率可以看出,将上述2 个组件进行融合可以有效提升最终的推荐性能。

图5 在Foursquare和Gowalla数据集上CLSR算法与其他组件的推荐性能对比Fig.5 Recommendation performance comparison of CLSR model and other components on Foursquare and Gowalla datasets
4.5.5 潜在维度和层数影响分析
神经网络的深度是影响神经网络表达能力的重要因素。本节主要讨论多层神经网络层数对推荐质量的影响。令隐藏层数表示为dl,将dl从1变化到5,其他参数保持与第4.4节中描述的相同设置。图6 仅呈现了Foursquare 数据集上的实验结果,而在Gowalla 数据集上的实验结果显示出类似的趋势。一般而言,随着多层神经网络的隐藏层数从1 增加到5,最终推荐性能在逐步提高,这表明更深的神经网络层的确更有利于潜在特征学习。不过当层数dl>4 时,CLSR 算法性能并没有进一步的提高,因此,CLSR 算法的多层神经网络隐藏层的最佳层数为4。造成这个现象可能的原因是更深的神经网络使得CLSR 算法的多层神经网络具有更多需要训练的参数,这些参数在训练数据样本有限的情况下相对难以学习,导致推荐性能的下降。显然,多层神经网络中隐藏层不同层数可以影响最终推荐性能,但是推荐性能并不会随着层数的无限制增加而提高。

图6 CLSR算法中多层神经网络基于Foursquare数据集的层数影响分析Fig.6 Impact analysis of layer number of multi-layer neural network in CLSR model based on Foursquare dataset
CLSR 算法中的多层神经网络的潜在因子维度的变化对CLSR算法的鲁棒性也会产生不小的影响,原因在于潜在维度的大小会影响推荐模型优化过程中迭代的次数、算法的运行时间和占用的内存。图7 是K=5 时不同潜在因子维度对CLSR 算法影响的实验结果,其他K的取值呈现类似的趋势。从图7 可以看出,随着维度的增加,推荐模型的性能得到了提升。当维度在[60,100]时,两个数据集的准确率和召回率都变得稳定,没有因为维度的进一步变化而上下波动,而且显然潜在维度越大,准确率和召回率不总是会带来相应的提高,一个可能的解释就是维度过大则会导致推荐模型的过度拟合。因此,本文的实验CLSR 算法中多层神经网络的维度选择为64,从而平衡性能和计算成本,保证本文CLSR 算法获得稳定的最优性能。
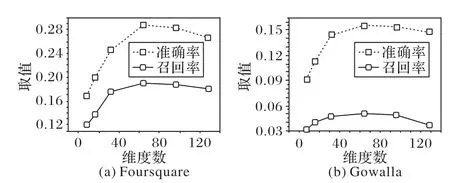
图7 CLSR算法中多层神经网络基于两个数据集的维度影响分析Fig.7 Impact analysis of dimension of multi-layer neural network in CLSR model based on two datasets
5 结语
兴趣点推荐作为位置社交网络的重要个性化服务,具有广阔的学术和应用前景。本文提出了一种称为CLSR 的兴趣点推荐算法,分别实现基于混合GRU 网络建模复杂动态偏好和基于高阶注意力网络的潜在因子模型建模一般静态偏好,然后二者集成到端到端的统一框架中用于POI 推荐。此外,本文采用2 个多层神经网络分别帮助在动态偏好建模和静态偏好建模过程中更好地学习相关特征实现更好的表征。实验结果验证了本文CLSR算法的有效性和效率。
对于将来的工作,希望将更丰富的上下文信息集成到本文提出的模型中,以进一步提升CLSR 算法性能。此外,将深度学习的最新方法,例如生成对抗网络、多头注意力网络等,进一步深入与兴趣点推荐算法相结合也是一个值得关注的方向。
