基于双域自注意力机制的行人属性识别
2021-03-07凯1
吴 锐,刘 宇,冯 凯1,
(1.武汉邮电科学研究院,武汉 430074;2.南京烽火星空通信发展有限公司,南京 210019)
(*通信作者电子邮箱WuRui_sh@163.com)
0 引言
行人属性识别任务的目标是识别图片中的行人所包含的属性,便于以结构化信息数据描述目标行人。在绝大多数的应用场景下,该任务被看作是对行人的所有属性标签进行二分类的多标签分类任务。该任务面临的主要挑战之一是属性识别所需的特征通常是局部的细粒度特征和行人的整体特征的结合,因为在低分辨率图像中一些需要识别的细粒度局部属性(如眼镜属性等)在行人图像中所占的面积往往非常小,需要通过细粒度特征才能识别出该属性是否存在;而某些抽象属性(如行人朝向属性等)则需要通过行人的整体特征来判断。因此为了能够更准确地识别出是否存在某个属性,显著性的局部特征和良好的整体特征都至关重要。同时,行人的某些属性的特征在空间上具有依赖性,在语义上通常是存在相互关联关系(如性别属性和短裙属性),可以利用这种关系提高属性间的识别效果。
本文利用深度神经网路,提出了一种基于由空间自注意力和通道自注意力机制组成的双域自注意力机制的行人属性识别模型,通过空间自注意力提取更可分辨属性的局部特征和捕获空间特征间的依赖性,这有利于属性识别的非局部相关特征;然后,使用通道注意力提取通道间语义的相关性,从而提升一些具有关联性的属性的识别效果。而且,本文将注意力特征和整体特征进行融合,可以使本文模型更好地识别不同粒度的属性。另外,本文采用加权损失函数和添加批归一化(Batch Normalization,BN)层的双重机制,缓解了数据样本不平衡所导致的少样本属性识别准确率低的问题。实验结果表明,本文所提出的模型可以有效地提升属性识别准确率。
1 相关研究
1.1 行人属性识别
传统的特征提取通常是基于手工设计特征提取方法。手工设计特征的方法通常是通过提取图像中的方向梯度直方图(Histogram of Oriented Gradient,HOG)特征[1]或统计颜色直方图[2]的形式作为图像的表征,需要针对应用任务的不同设计不同的滤波器或提取策略。近年来,深度学习在利用多层非线性变换进行自动特征提取方面取得了成功,特别是在计算机视觉、语音识别和自然语言处理等领域,取得了令人瞩目的成绩。Sudowe 等[3]提出的ACN(Attributes Convolutional Net)模型使用AlexNet网络对特征提取,对每个属性设置一个分类器的方式实现属性识别。Abdulnabi等[4]将行人属性当作多任务识别工作,提出的多任务卷积神经网络(Multi-Task Convolutional Neural Network,MTCNN)模型在共享特征池的基础上设立了多个任务,每个任务对应一个属性的识别工作。以上方法只提取了行人图像的整体特征,而行人属性识别可以看成一种细粒度的多标签分类任务,属性局部的特征显著性与识别的效果正相关。增强局部特征显著性可以通过分割行人图片提取局部特征的方式,如:文献[5-7]等先提取出行人各个躯干部位的局部特征,使用局部特征和局部特征间的依赖进行局部属性识别;文献[8]中将行人图像水平切割成多个区域,对每个区域特征进行编码-解码,从而使局部的特征更显著化,更有利于局部属性的识别。另一种方式则是利用注意力机制,通过特征对识别属性的重要性分配权重。典型方法有首次将注意力机制应用于属性识别任务的空间正则化网络(Spatial Regularization Network,SRN)[9],提出多向注意力机制的Hydraplus-Net[10],以及融合了局部特征方式和注意力机制方式的JVRKD(Join Visual-semantic Reasoning and Knowledge Distillation)[11]等。
1.2 注意力机制
在计算机视觉任务中,特征之间存在相互依赖关系,而卷积操作只是一种局部区域的操作,为了获得局部区域之外的特征,需要通过卷积层的堆叠以增大深层神经元的感受野,这会导致卷积神经网络设计的难度增加,从而导致基于该网络进行特征提取的模型的复杂度增加。受图片滤波领域的非局部均值去噪滤波算法[12]的思想的启发,Wang等[13]提出了Non-Local 网络用于对视频分类。文献[14]中则结合Transformer[15]和Non-Local 的思想,提出自注意力机制解决非局部特征依赖的问题。在图像分类和行人重识别任务中,文献[16]和文献[17]中也分别使用了自注意力机制。但文献[14-16]中的方法只针对特征的空间域提取依赖关系,没有使用通道间的关联性信息,而通道信息往往与语义的相关性较大,从文献[17]的分类效果中也得到了证明。因此,融合空间域注意力和通道域注意力的混合域注意力方法[18-20]应运而生。
2 本文模型
2.1 总体架构
本文模型的整体架构如图1 所示,在ResNet50[21]的基础上加入了用于行人属性识别任务的模块。
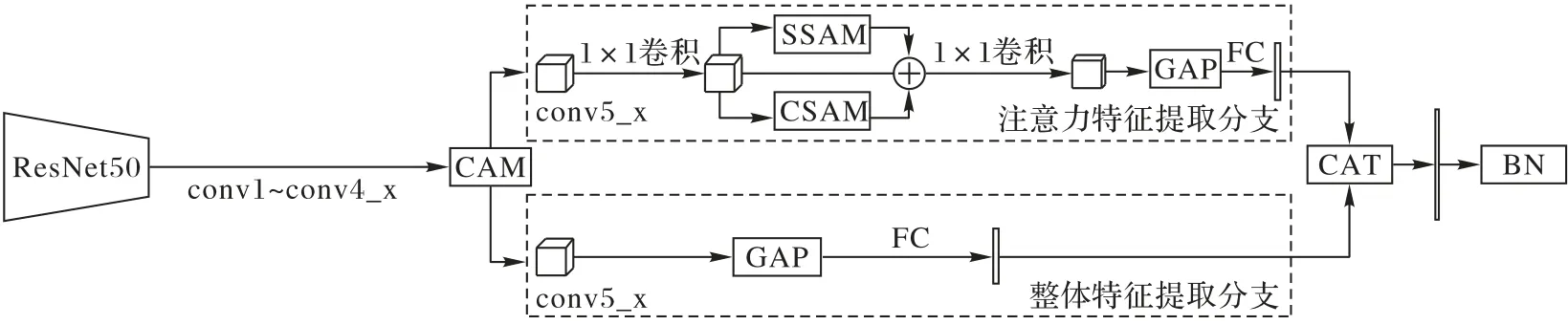
图1 本文模型的整体架构Fig.1 Overall architecture of the proposed method
首先,在基础特征提取阶段,使用ResNet50 的conv1、conv2_x、conv3_x、conv4_x(x 表示该层子序列的统称)模块作为特征提取网络,所提到的特征随后经过一个通道自注意力模块(Channel Self-Attention Model,CSAM),该模块的主要作用是整合提取到的中层特征,抑制非必要的特征,显著化利于行人属性识别的中层特征。
然后,网络被拆分为整体特征提取和注意力特征提取的双分支网络。双分支网络都使用ResNet50 的conv5_x 模块作为高层语义特征提取模块,且提取到的特征都分别通过全连接(Full Connection,FC)层进行降维至1× 1024 维,减少模型参数量以降低过拟合的风险。主要区别在于:
1)注意力特征提取分支主要偏向于提取具有关联性特征和更有利于属性识别的局部性特征。该分支主要由降维模块和注意力模块组成:降维模块包括2 个1× 1 卷积层(分别位于conv5_x 和注意力模块之间和注意力模块和全局池化模块之间)和1 个全连接层(位于该分支的输出端);注意力模块包括空间自注意力模块(Spatial Self-Attention Model,SSAM)和CSAM(详见2.2节)。SSAM 能够捕捉和显著化到空间中具有关联性的特征,CSAM 则捕捉具有通道抽象语义的局部特征,将两种注意力特征融合,优势互补,更有利于对具有关联性和局部细粒度性的行人属性进行识别。
2)整体特征提取分支主要偏向于对行人整体的特征进行提取。与ResNet50 的结构相似,该分支由conv5_x 模块提取得到14 × 14 × 2 048 维的特征直接使用全局平均池化(Global Average Pooling,GAP)的方式,从而使该分支提取到的特征包含行人的整体信息特征。
最后,将行人整体特征和注意力特征通过向量拼接(Concatenate,CAT)进行融合,经过BN 层对属性样本进行平衡化处理,再使用全连接层作为分类器,实现对行人属性的多标签分类。
2.2 自注意力模块
2.2.1 空间自注意力模块
空间自注意力模块的结构如图2 所示,首先将上一层得到的特征图X∈RC×H×W分别送入3 个卷积模块得到特征图三元组(Q,K,V) ∈RC×H×W,将Q和K进行维度压缩成RC×N的矩阵(N=H×W),经过转置相乘即可求得特征图间的相关矩阵特征S∈RN×N,经过Softmax权值对S的每个元素si,j归一化后,得到注意力系数矩阵Z∈RN×N,Z中的每个元素zj,i(式(1))代表区域j受元素i的影响程度。将Z和V乘积后的特征与输入特征X融合后得到空间注意力特征Y∈RC×H×W。

通过系数矩阵Z与维度压缩后的特征图V进行矩阵乘积得到注意力特征A∈RC×N,将A扩维重塑得到注意力特征图B∈RC×H×W。接着,在空间自注意力模块的最后阶段,利用一个可学习的参数λ融合注意力特征B∈RC×H×W和输入特征X∈RC×H×W,得到空间自注意力模块的最终输出Y∈RC×H×W,即

参照文献[12]的设定,在模型的开始训练阶段,参数λ的初始值设置为0;随着模型训练过程的进行,参数λ逐渐学习合适的值以更好地融合B和X。
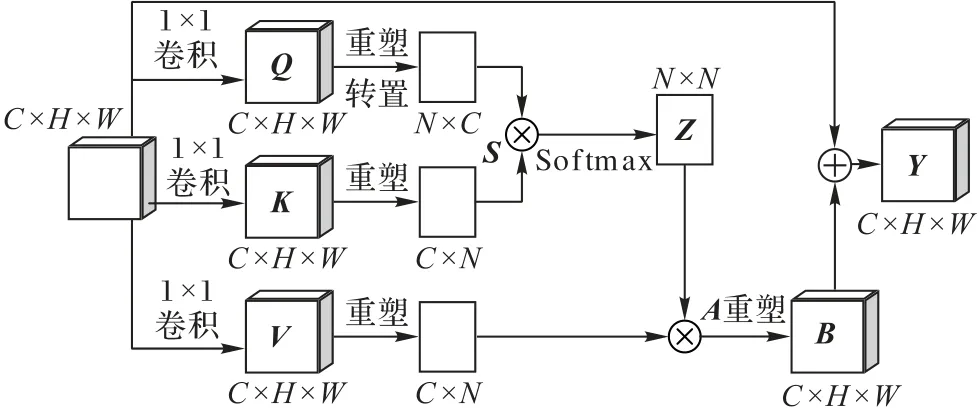
图2 空间自注意力模块结构Fig.2 Spatial self-attention module structure
2.2.2 通道自注意力模块
通道自注意力模块(如图3)的建模方式与空间注意力思想相似,输入特征X∈RC×H×W,将X进行维度压缩得到E,F,G∈RC×N,E和F转置相乘得到T∈RC×C,接着利用Softmax得到通道注意力系数矩阵U,但与空间注意力不同,得到的系数矩阵只关注通道间的影响程度,因此U∈RC×C。在通道自注意力模块中,生成E、F、G的过程中并没有经过卷积操作,从而能更好地保留通道图间的关系。

由U和G得到注意力特征图M∈RC×H×W。M再经过可学习的参数θ与原始输入X加权求和,得到通道域最终的输出O∈RC×H×W。


图3 通道自注意力模块结构Fig.3 Channel self-attention module structure
2.3 属性样本平衡
无论是PETA 还是RAP 数据集,都存在比较严重的属性样本不平衡的情况,这使模型在训练阶段的权重调整更偏向于包含多样本的属性,从而出现包含多样本的属性识别准确率高,而少样本属性识别准确率较低的现象。对多样本进行前采样和少样本过采样是图像多分类任务中常用的手段,但这并不适用于行人属性识别任务。因为在图像多分类任务中,对图像的标注通常是单标签,可以通过控制单个标签的数量平衡样本;但行人属性分类任务是一张图片对应一个包含多个标签值的长向量,不可以对标签向量中的某个标签单独进行数量控制,因此无法使用过采样或欠采样的方法控制样本平衡。
针对样本不平衡的问题,如式(5)所示,本文采用对损失函数进行加权的策略,让少样本的属性在训练过程中施加更大的影响。
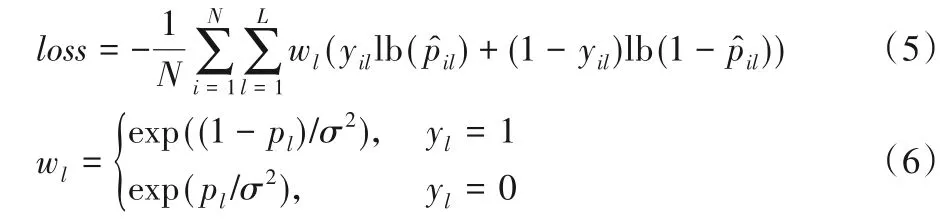
其中:N表示数据集的样本数;wl表示根据设计的策略对第l个属性的加权权重;yil表示行人xi的第l个属性的真实标签,存在为1,否则为0;σ为超参数,本文中设定为表示行人xi的第l个属性的预测概率。计算式如下:

此外,本文还在模型的特征提取后添加了一个批归一化(BN)层,通过BN 层参数的学习,进一步降低了样本不平衡的影响。通过对比实验证明(详见3.2 节),加权损失策略的加入,可以使基准模型在PETA 和RAP 数据集上的平均准确率(mean Accuracy,mA)值分别提高2.02 个百分点和1.94 个百分点,这表明通过加权损失的方式平衡样本可以使单个属性的识别准确率有所提升。BN 层的加入也可以使模型识别效果有小幅度地提升,mA 值分别提升了0.42 个百分点和0.26个百分点。
3 数据和实验设置
3.1 数据集和评价指标
为了测试本文模型的有效性,在两大公开的数据集PETA和RAP上进行训练和测试。
1)PETA 数据集[22]由从10 个小规模行人数据集收集的19 000张人图像组成。整个数据集被随机分为三个不重叠的部分:9 500个用于训练,1 900个用于验证,7 600个用于测试。由于属性样本不平衡现象的存在,一般选取35 个属性标注中样本比例大于5%的属性用于评测,35个属性如表1所示。

表1 PETA数据集的35个属性Tab.1 Thirty-five attributes of PETA dataset
2)RAP数据集[23]包含来自26个室内监控摄像头的41 585 张图像,每个图像都有69 个二进制属性和3 个多类属性。根据官方协议,整个数据集被分割成33 268 张训练图像和8 317 张测试图像,对其中的51 个二值属性进行了识别性能评价,51个属性如表2所示。
量化对比的评价指标使用通用的基于标签(Label-based)的平均准确率(mean Accuracy,mA)指标和基于实例(Example-based)的准确率(Accuracy,Acc)指标、精确率(Precision,Prec)指标、召回率(Recall,Rec)指标以及F1 值指标23]。
3.2 对比实验
本文做了两组实验对比:实验一对比了基准网络ResNet50和本文所提出的各个模块在两个数据集测试集上的指标效果;实验二则是将本文模型与当前的一些行人属性识别模型的量化评价指标结果进行对比。
3.2.1 实验相关设置
在本次实验中,输入到模型的图像大小为224 × 224,在将图像输入到网络之前,所有图像都通过减去平均值和除以每个颜色通道的标准差进行标准化。数据扩增上,只在训练过程中采用了随机翻转随机旋转的数据增强方法,测试时不使用任何的变换。为了获得更多的特征信息,所有的实验的基础网络ResNet50 均使用了ImageNet[24]训练的权重作为初始权重,且均去除了ResNet conv5_x的下采样操作,即conv5_x的输出特征图大小为14×14。优化网络的优化器采用随机梯度 下 降(Stochastic Gradient Descent,SGD),其中动量(Momentum)和权值衰减(Weight decay)参数分别设为0.9 和0.000 5。初始学习率为0.001,在Pytorch 框架下使用ReduceLROnPlateau 类以验证集损失作为标准调整学习率衰减,衰减系数为0.1。

表2 RAP数据集的51个属性Tab.2 Fifty-one attributes of RAP dataset
3.2.2 方法有效性实验
在本组实验中,本文通过在基准网络ResNet50 上分别依次添加权损失策略(wl)、BN 层和双域自注意力模块(Twodomain Self-attention Module,TSM),对比验证每个方法对属性识别的增益程度。在PETA 和RAP 数据集上的实验结果如表3 所示,表中加粗的内容表示该指标下的最好结果,下划线表示排在第二的结果。

表3 PETA和RAP数据集上各模块有效性对比 单位:%Tab.3 Effectiveness comparison of different modules on PETA and RAP dataset unit:%
由表3 可以看出,对损失函数根据样本数量的权重进行加权(+wl)后,在两个数据集上,mA指标分别比基准模型提高了1.57 个百分点和1.94 个百分点;加入BN 层(+wl+BN)也可以使模型的识别效果有小幅度的增益(mA指标增益幅度分别为0.42个百分点和0.26个百分点);在添加了BN层模型的基础上加入本文所提出的空间自注意力模块和通道自注意力模块,在两个数据集中可以使每个评价指标值都有所提升,mA指标分别提升了1.92 个百分点和1.85 个百分点,Acc 则有3.12个百分点和2.21个百分点的增幅。
总的来说,本文模型相较基准模型ResNet50,在PETA 和RAP 数据集上mA 指标分别提升了3.91 个百分点和4.05 个百分点,Acc 指标分别提升了3.92 个百分点和1.6 个百分点。在图4中,通过对比基准模型ResNet50和本文模型在PETA数据集的35 个属性和RAP 数据集的51 个属性分别的识别准确率,可以看出本文模型对绝大部分属性的识别效果都有所提升,特别是对基准模型识别准确率低的属性提升比较明显,而这部分属性通常是数据集中的少样本属性。其中,图4 的纵坐标表示识别的准确率,横坐标表示属性的编号,该编号与表1和表2的属性编号分别对应。

图4 基准模型和本文模型在PETA和RAP上各属性的识别准确率Fig.4 Recognition accuracy for different attributes by baseline and proposed models on PETA and RAP
3.2.3 与其他模型的对比
该实验对比了一些基于PETA 和RAP 数据集训练和测试的模型方法,主要有PGDM(Posed Guided Deep Model)[5],VSGR(Visual-Semantic Graph Reasoning net)[7]、HPNet(Hydra Plus Net)[10]、DeepMAR(Deep Multi-Attribute Recognization model)[25]、LGNet(Location Guided Network)[26]、MPAR(Multistage Pedestrian Attribute Recognition method)[27]、RCRA(Recurrent Convolutional and Recurrent Attention model)[28]和IA2Net(Image-Attribute reciprocally guided Attention Network)[29]。其中DeepMAR 只提取行人的全局特征,PGDM 和LGNet通过行人局部区域网络提取行人不同部位的局部特征,RCRA 和IA2Net将注意力机制运用在网络模型之中,MPAR 通过阶段训练和优化损失的方式对基准模型进行了更改。
通过与现有的行人属性识别模型作对比得出,本文模型在几项评价指标上的效果都非常具有竞争力,综合性能优于其他行人属性识别模型,具体如表4、5 所示,其中“—”表示该模型对应的文献中没有给出具体数据,粗体和下划线的意义与实验一设定相同。
3.3 注意力特征图可视化分析
为了观察空间自注意力模块和通道自注意力模块在识别行人属性时所主要关注的特征,了解每个自注意力模块对属性识别过程中起到什么作用,利用Grad-CAM(Gradient Class Activation Map)[30]方法对两个模块的输出的特征图的类别激活图进行可视化,如图5 所示,分别是使用模型识别行人是否有“HandBag”属性和“Female”属性,图中第一列Input 表示输入到网络中的图片,第二列CSAM 表示通道自注意力模块输出特征的类别激活图,第三列SSAM 表示空间自注意力模块输出特征的类别激活图。
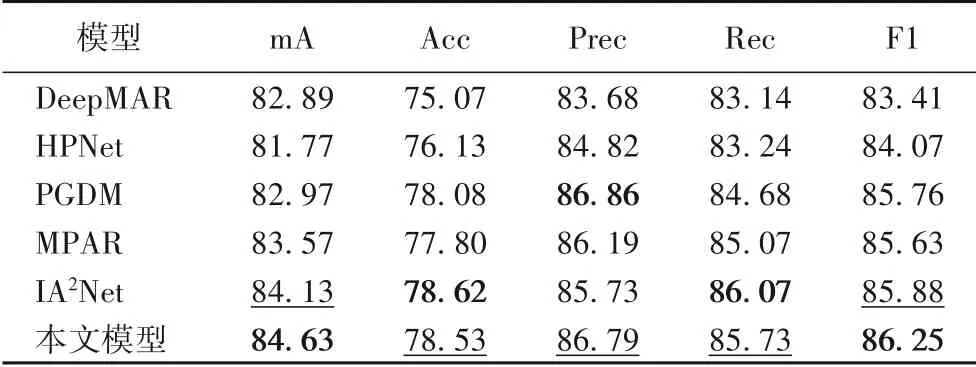
表4 PETA上不同模型效果对比 单位:%Tab.4 Effect comparison of different models on PETA unit:%
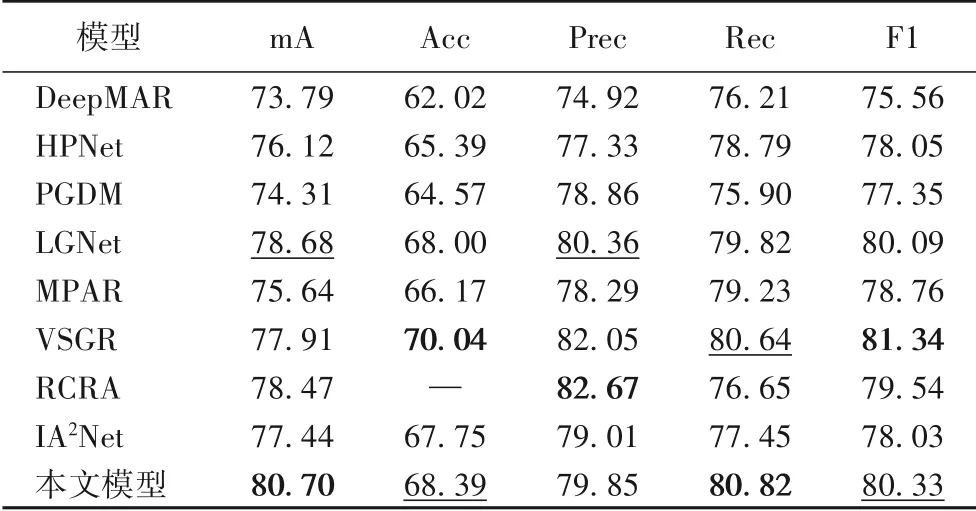
表5 RAP上不同模型效果对比 单位:%Tab.5 Effect comparison of different models on RAP unit:%

图5 识别HandBag和Female属性注意力模块的类别激活图Fig.5 Class activation maps of attention module to recognizing HandBag and Female attributes
对于HandBag 属性,通常只需要关注行人手部区域的特征即可判定是否存在该属性,与其他区域特征相关性不大。因此在图5(a)中,空间注意力和通道注意力都只关注了局部的特征。将两者特征融合可以使局部特征更显著,更利于HandBag属性的识别。
如图5(b)所示,与只需要关注局部区域的HandBag 属性不同,Female属性是非局部性质的抽象属性,往往需要结合多个语义特征来判定。在这种情况下,通道自注意力机制的关注区域处于行人头发和裙摆的局部区域,即关注长发语义特征和裙子语义特征,其中行人头发区域获得的关注度比裙摆区域获得的关注度更高;而空间自注意力机制所关注的区域更偏向于大范围的特征区域,即更偏向于通过行人服饰等特征判定是否是“女性”属性。通过将空间自注意力模块和通道自注意力模块提取到的特征进行融合,可以使两者进行优势互补,提高属性的识别准确度。
通过观察自注意力模块的可视化结果可以得出:1)对于只需要局部特征且与其他区域语义关联性弱的细粒度属性,空间自注意力模块和通道自注意力模块关注的特征都集中在该属性的局部区域,融合两个模块提取到的特征可以使局部特征更显著化;2)对于需要借助其他语义特征信息才能识别出的属性,空间自注意力模块关注的特征是大范围的、与属性空间关联性强的特征,通道自注意力模块关注的特征是局部的、与属性语义关联性强的特征,融合两个模块提取到的特征可以优势互补,获得更好的识别效果。
4 结语
针对行人属性识别任务中不同属性对特征粒度和特征依赖性需求不同的问题,本文提出了使用空间自注意力机制提取空间的依赖性特征,使用通道自注意力机制提取通道间特征的语义相关性信息,并将融合后的自注意力特征与行人的整体特征进一步融合,以满足不同粒度属性的特征需求,从而得到更好的属性识别效果。实验结果显示,本文模型在PETA和RAP 两大行人属性数据集中都可以提升属性的识别效果。不过由于空间自注意力是对特征图像素级的权重分配,需要计算每个像素间的相关性,导致该模块计算量较大,本文模型也为此只将其用于特征图尺寸较小的深层特征中;同样地,通道自注意力也需要计算每个通道间特征的相关性,计算量也比较大。因此,未来的研究可以围绕降低空间自注意力机制和通道自注意力机制的计算量上展开。
