基于句法依存分析的图网络生物医学命名实体识别
2021-03-07李建华
许 力,李建华
(华东理工大学信息科学与工程学院,上海 200237)
(*通信作者电子邮箱jhli@ecust.edu.cn)
0 引言
在生物医学领域,每年都会新增大量的专利、期刊和报告等文献。这些文献中包含的实体信息可应用于药物设计和临床医疗,对于生物医学研究具有重大意义。随着自然语言处理技术的发展,生物医学命名实体识别逐渐成为研究热点。广义的命名实体识别针对文本中的特定实体,如人名、地理位置和组织名称等,而在生物医学领域,实体则特指药物名称、蛋白质名称、疾病名称和基因名称等。与通用领域的命名实体识别任务相比,生物医学命名实体识别由于命名规则多样、实体名称较长且包含关系复杂,面临着更多困难。
现有的生物医学命名实体识别方法主要分为:基于规则和词典的方法、基于传统机器学习的方法和基于深度学习的方法。基于规则和字典的方法常见于早期命名实体识别研究,主要通过设计规则模板、构建实体字典来识别实体,如Krauthammer 等[1]提出的基本局部比对检索工具(Basic Local Alignment Search Tool,BLAST),Hanisch 等[2]使用基于规则的方法识别基因和蛋白质实体等。这种方法虽然简单实用,但规则和词典的设计过程复杂耗时且容易产生错误。基于传统机器学习的方法对于特征选取的要求较高,需选取例如前后缀、大小写等人工特征来训练模型。Leaman 等[3]提出的tmChem 模型融合了多种人工特征,在化学命名实体识别取得了较好效果;Li 等[4]在条件随机场(Conditional Random Field,CRF)中融入词频和共现信息识别基因实体,进一步提升了模型表现。基于传统机器学习的方法进一步提高了实体识别的准确率,但由于过于依赖特征选取且识别策略单一,导致模型鲁棒性和泛化性能较差。基于深度学习的方法主要通过神经网络提取文本特征,在命名实体识别任务中获得了广泛应用。Rocktäschel 等[5]提出的ChemSpot 模型将CRF 与词典结合,学习了化学品名称的多种形式。Huang 等[6]提出的BiLSTMCRF 模型使用双向长短期记忆(Bidirectional Long Short Term Memory,BiLSTM)网络提取上下文特征,并通过CRF 学习实体标签间的转换概率以修正BiLSTM 的输出;李丽双等[7]提出的BiLSTM-CNN-CRF 模型则是在BiLSTM-CRF 的基础上使用卷积神经网络(Convolutional Nerual Network,CNN)提取字符级别特征,在生物医学命名实体识别中获得了良好的效果;Dang等[8]提出的D3NER模型在BiLSTM-CRF模型中引入语言学特征,对词向量进行优化;Crichton 等[9]在CNN 模型中融入多任务学习思想,使用多种不同标准和不同实体类型的数据集训练模型,提升了模型的泛化性能;Cho 等[10]通过N-Gram模型在词向量中融入上下文信息,进一步增强了模型表现。基于深度学习的方法在不依赖人工特征的情况下,在命名实体识别任务中获得了更好的表现。以上这些方法虽然均在一定程度上增强了模型在任务中的表现,但改进的思路大多是通过增加特征、优化词向量来丰富词与词之间的关联,没有从句法的角度考虑词与词之间的联系,效果有所局限。
句法依存分析是获取文本句法信息的重要方法,它以句子为单位构建依存分析图,揭示了词与词之间的依存关系,提升了模型在自然语言处理任务中的表现。现有的句法依存分析方法大多采用线性方式对句法依存分析图进行编码[11-12],不能充分地利用依存分析图中的句法信息。随着图网络技术的发展,将图卷积网络(Graph Convolutional Network,GCN)应用于句法依存分析的研究已经出现,例如:Bastings 等[13]利用GCN编码句法依存信息用于机器翻译;Marcheggiani等[14]使用GCN 学习文本句法结构,并将其与BiLSTM 结合应用于语义角色标注等。虽然句法依存分析在自然语言处理的多个领域已有应用,但在生物医学命名实体识别上的研究还未出现。
针对以上问题,本文提出一种基于句法依存分析的图网络生物医学命名实体识别模型。模型利用CNN 生成字符向量并将其与词向量拼接,送入BiLSTM 进行训练;其次,对语料进行句法依存分析,使用GCN 对句法依存分析图进行编码,并引入图注意力网络(Graph ATtention network,GAT)优化邻接节点的特征权重,得到模型输出。实验结果表明,本文提出的方法有效地提升了生物医学命名实体识别的准确率。
本文将GCN 应用于生物医学命名实体识别领域,通过图网络学习文本句法信息并使用图注意力机制增强实体识别效果,为后续的生物命名实体识别研究拓展了思路。本文的工作主要有:
1)现有的生物医学命名实体识别方法没有利用语料中的句法信息,效果有所局限,为此本文对语料进行句法依存分析,并使用GCN 对句法依存分析图进行编码,充分利用了文本中的句法信息;
2)引入图注意力机制优化句法依存分析图中邻接节点的特征权重,更好地聚合了邻接节点的特征,提升了模型的识别效果。
1 基于句法依存分析的图网络生物医学命名实体识别
1.1 句法依存分析
句法依存分析通过分析句子内的依存关系来获取文本句法结构,主张句子中核心动词是支配其他成分的中心成分,而它本身却不受其他任何成分的支配,所有受支配成分都以某种依存关系从属于支配者[15]。依存关系用依存弧表示,方向由从属词指向支配词。每个依存弧上有个标记,称为关系类型,表示该依存对上的两个词之间存在什么样的依存关系[16]。常见的依存关系有主谓关系(SBV)、动宾关系(VOB)和状中关系(ADV)等。
1.2 GCN
GCN 是卷积神经网络的一种,可用于编码与图相关的信息。给定一个具有n个节点的图,可以使用一个n×n的邻接矩阵A来表示图结构,若节点i到节点j有边,则令Aij=1。为了聚合节点自身的特征,需对邻接矩阵A进行自环操作,即令A对角线上所有元素都为1。其次,对A进行归一化处理,引入邻接矩阵A的度矩阵D,其中在一个具有l层的GCN 中,定义为输入向量为节点i在第l层的输出向量,图卷积的操作如下所示:

其中:W(l)是权重矩阵,b(l)是偏置项,σ是非线性映射函数。每个节点可以通过邻接矩阵聚合邻接节点的特征信息,并传入下一层作为输入。
1.3 模型架构
本文提出的模型框架如图1 所示,模型由词表示层、BiLSTM 层和图卷积层组成。首先利用CNN 生成字符向量,将其与词向量拼接,送入BiLSTM层训练;其次,以句子为单位对语料进行句法依存分析,并构建邻接矩阵;最后将BiLSTM的输出和构建好的邻接矩阵送入GCN 训练,并引入图注意力机制优化邻接节点的特征权重,得到模型输出。

图1 本文模型整体结构Fig.1 Overall structure of the proposed model
1.3.1 词表示层
词表示层的作用是将原始文本转换为向量形式,如图2所示。模型使用Glove(Global Vectors for Word Representation)将单词转化为向量,得到长度为200 维的词向量X1。将原始的单词按字母拆解,填充为长度为52的字母序列后送入CNN学习,经过卷积、最大池化操作后,映射成为30 维的字符向量X2。将这两部分向量拼接后,构成模型输入X=X1⊕X2。
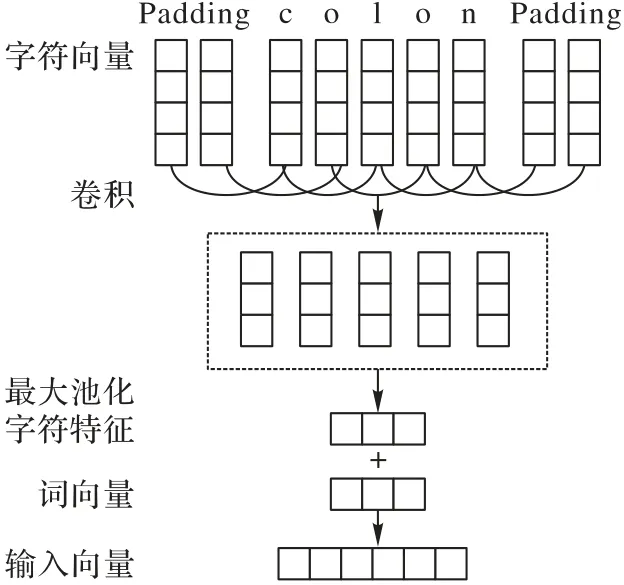
图2 词表示层Fig.2 Word representation layer
1.3.2 BiLSTM 层
BiLSTM 层由前向和后向LSTM 组成,主要用于提取文本中的上下文特征。Marcheggiani等[14]的工作指出,GCN的主要问题在于难以捕捉长距离节点之间的依存关系,将其与LSTM结合后可以很好地避免这一问题。因此,本文沿用这一思路,将字符向量和词向量进行拼接后,加入BiLSTM 中进行编码。LSTM的主要结构可以表示为:

其中:σ是sigmoid 函数;i、f、o和c分别是输入门、遗忘门、输出门和细胞向量;⊗是点乘运算;w、b代表输入门、忘记门、输出门的权重矩阵和偏置向量。
1.3.3 图卷积层
图卷积层的作用是对语料中的句法依存分析信息进行编码,其输入由两部分构成:一部分是BiLSTM 的输出,另一部分是根据句法依存分析构建好的邻接矩阵。本文使用Spacy工具库对数据集进行句法依存分析,以句子为单位构建依存分析图。将句子中的单词看作图中的节点,将单词与单词之间的依存关系看作图中的边。Spacy 以child 和head 描述单词与单词之间的依存关系,依存关系弧从head 指向child。得到一个句子的依存分析图之后,将其构建成邻接矩阵。假设一个句子由n个单词构成,需要构建一个大小为n×n的邻接矩阵。若单词i与单词j之间存在依存关系,且依存弧由i指向j,则相应的令。邻接矩阵构建好后,将会作为GCN 的部分输入。以句子“China’s achievements attract the world’s attention”为例,其依存分析图如图3所示。

图3 依存分析示意图Fig.3 Schematic diagram of dependency parsing
根据依存分析图得到的邻接矩阵,经过自环操作后转为:

经过归一化后,邻接矩阵转换为:

从上述矩阵可以看出,每个节点的出度经过归一化之后得到相同的值。这种操作为节点的邻接节点分配了相同的权重,忽视了节点之间依存关系的差异性。因此,本文引入图注意力机制[17],在GCN 的基础上,对邻接节点的特征聚和做出调整。其操作如下所示:


得到节点i的邻接节点注意力权重后,对邻接节点特征进行加权求和:

为了均衡注意力机制的输出,采用多头注意力机制执行相同的操作,拼接后得到输出,K代表注意力头数:

获得图卷积层输出后,使用softmax 函数得到模型分类结果。
2 实验过程与评估
2.1 数据集
本文在JNLPBA[18]和NCBI-disease[19]数据集中训练模型,数据集分布如表1所示。NCBI-disease数据集来源于793篇生物医学领域的摘要,主要包含疾病实体;JNLPBA 数据集包含DNA、RNA、Cell_line、Cell_type、Protein 五种实体,模型除了识别出实体,还需要给出实体的具体分类。数据集使用BIO 标注方案:B 代表Beginning,标注一个实体的开始部分;I 代表Inside,标注组成实体的中间部分;O 代表Outside,标注与实体无关的信息。

表1 实验数据集详细信息Tab.1 Details of datasets used in the experiment
2.2 评估标准
生物医学命名实体识别任务需要模型正确判定实体的边界并输出正确的实体类别。为了精确衡量实体识别效果,本文采用准确率P(Precision)、召回率R(Recall)和F1(F1 值)三种评测指标,具体公式如下:

其中:TP为正确识别的实体个数,FP代表实体边界判定错误或类别分类错误的实体个数,FN代表未识别出的实体个数。
2.3 实验设置
本文使用Glove将单词转换为200维词向量,利用CNN生成30维字符向量,将两部分向量拼接后形成230维特征表示;BiLSTM 隐藏层单元数设为200,Dropout率设为0.5;图卷积层单元数设为50,图注意力机制头数设置为6;获得图卷积层输出后,通过softmax函数得到最终分类结果。
实验运行环境为Keras 2.2.4,模型学习率设为5e -4,损失函数定义为多类交叉熵损失函数,优化器采用Nadam算法,模型经过100轮训练后达到收敛。
2.4 实验结果与参数分析
2.4.1 对比实验分析
为了验证本文方法的有效性,进行对比实验来说明各个模块作用,实验结果如表2所示。
为了说明字符向量在向量表征方面的优势,本文选择BiLSTM 进行对比实验。从表中可以看出,Glove+char+BiLSTM 模型相比Glove+BiLSTM 的方法,准确率平均提升了1.42个百分点,F1值平均提升了2.64个百分点。生物医学实体名称大多包含大小写和特殊字符,使用CNN 提取字符特征,能够帮助模型区分实体,提高实体识别率。实验结果表明,使用CNN 提取字符特征生成的字符向量,在与词向量结合后,提升了模型的准确率。
传统的生物医学命名实体识别方法不能很好地利用语料中的句法信息,而句法信息可以丰富实体与实体之间的关联,对于生物医学命名实体识别有重要意义。本文方法对语料进行句法依存分析,并使用GCN 利用这部分信息进行训练。对比Glove+char+BiLSTM模型和Glove+char+GCN+BiLSTM模型的实验结果可以发现,后者相比前者的准确率平均提升了3.80个百分点,F1值平均提升了2.68个百分点。实验结果表明,使用GCN可以很好地利用句法信息,增强模型表现。
GCN 使用归一化操作处理邻接矩阵,为每个节点的邻接节点赋予相同的权重,忽视了节点之间依存关系的差异性。本文在GCN 的基础上引入了图注意力机制改善这一问题。对比Glove+char+GCN+BiLSTM 模型和Glove+char+GAT+BiLSTM 模型的实验结果可以发现,后者相比前者的准确率平均提升了1.60 个百分点,F1 值平均提升了2.01 个百分点。实验结果表明,引入图注意力机制可以更好地聚合邻接节点的特征,提升模型性能。

表2 不同方法在NCBI-disease和JNLPBA数据集上的评价指标对比 单位:%Tab.2 Comparison of evaluation indexes of different methods on NCBI-disease and JNLPBA datasets unit:%
2.4.2 与现有其他方法对比
各模型在JNLPBA 数据集上的表现对比如表3 所示。Tang 等[20]在生物医学命名实体识别中融入词表示特征;Li等[21]提出在模型中结合使用句子向量和双词向量;Wei 等[22]在BiLSTM-CRF 模型中引入注意力机制,获得了71.57%的准确率和73.50%的F1 值;Dai 等[23]在BiLSTM-CRF 模型中使用预训练词向量模型ELMO(Embeddings from Language MOdels,ELMO),获得了74.29%的F1 值。以上方法均没有利用语料中的句法信息,效果有所局限。本文模型使用CNN提取字符特征,帮助模型识别包含特殊字符的实体,在不使用人工设计特征的情况下,提升了实体识别率;其次,本文使用GCN 学习语料中的句法依存分析信息,增强了词与词之间的关联。GCN在归一化操作后会为每个节点的邻接节点赋予相同的权重,忽视了节点之间依存关系的差异性。针对这一问题,本文还引入了图注意力机制优化邻接节点的特征权重,让模型更好地聚合邻接节点特征。实验结果表明,本文模型的F1 值比Dai 等[23]提出的模型高出了2.62 个百分点,相比于Wei 等[22]提出的模型,其准确率提高了5.99 个百分点,F1 值提高了3.41个百分点,获得了更好表现。
模型在NCBI-disease 数据集上的表现对比如表4 所示。Leaman 等[24]提出的DNorm 模型使用CRF 结合多种人工设计特征;Lu 等[25]提出的TaggerOne 模型通过正则化方法降低实体识别错误率;Dang 等[8]提出的D3NER 模型在BiLSTM-CRF模型中引入语言学特征对词向量进行优化,取得了85.03%的准确率和84.41%的F1 值;Wang 等[26]在BiLSTM-CRF 模型中融入多任务学习思想,同时学习多种生物医学实体类型,取得了85.86%的准确率和86.14%的F1 值。以上这些方法的思路大多是通过融合特征或优化词向量来提升模型效果,没有从句法的角度考虑词与词之间的关联。本文模型利用GCN学习文本的句法依存信息,并引入图注意力机制优化邻接节点的特征权重,充分地利用了语料中的句法信息。实验结果表明,相比Wang 等[26]提出的模型,本文模型的准确率提升了1.43 个百分点,F1 值提升了1.66 个百分点;相比D3NER 模型[8],准确率提升了2.26 个百分点,F1 值提升了3.39 个百分点,取得了良好的效果。

表3 不同模型在JNLPBA数据集上的评价指标对比单位:%Tab.3 Comparison of evaluation indexes of different models on JNLPBA dataset unit:%

表4 不同模型在NCBI数据集上的评价指标对比 单位:%Tab.4 Comparison of evaluation indexes of different models on NCBI dataset unit:%
实验结果表明,本文模型通过GCN 编码句法依存分析图,充分地利用了语料中的句法信息,在生物医学命名实体识别任务中获得了更好的表现。
2.4.3 实验参数分析
表5 为模型在不同词向量嵌入维度中的性能表现。从表中可以看出,低维度的词嵌入模型准确率较低,因为过低的嵌入维度不能很好地区分单词与单词间的语义,而过高的词向量维度会导致图卷积层参数过多,难以训练,降低模型性能。经过实验后,确定合适的词向量维度为200。

表5 不同嵌入维度的F1值 单位:%Tab.5 F1 scores of different embedding dimensions unit:%
表6 为模型在不同图卷积层数下的性能表现。可以看出,图卷积层数为2 时,模型准确率最高,相比于1 层图卷积,其准确率和F1值均得到了一定的提升;图卷积层数为3后,准确率和F1 值反而有所降低。这是因为图卷积层的堆叠层数过多时,会出现过平滑问题[27],使得邻接节点的特征表示越来越趋同,实体识别率下降。

表6 不同图卷积层数的F1值 单位:%Tab.6 F1 scores of different graph convolutional layers unit:%
3 结语
本文提出了一种基于句法依存分析的图网络生物医学命名实体识别方法。模型以句子为单位对语料进行句法依存分析,通过图卷积网络(GCN)学习语料中的句法依存信息并引入图注意力机制优化邻接节点特征权重。实验结果表明,本文方法有效地利用了语料中的句法信息,提升了生物医学命名实体识别的准确率。未来会根据句法依存分析图的特点,尝试多种GCN的变形,作出进一步改进。
