基于大数据分析技术的数字图书馆信息检索模型设计
2021-03-07郭惠
郭惠
(山西旅游职业学院计算机科学系 山西省太原市 030031)
1 引言
在最近几年中,随着我国科学技术水平的不断提高,出现了数字图书馆,在知识经济中,数字图书馆是一个重要的载体,数字图书管理具有非常强的科技竞争实力。通过运用大数据分析技术,促使数字图书馆不再存在空间、时间、地域等方面的约束与限制,人们在任何时间、任何地方都能够通过数字图书馆获取自己所需的信息资源。为满足用户对图书信息检索、查询的需求,本文提出了基于大数据分析技术的数字图书馆信息检索模型,以期能够在我国数字图书馆检索领域中发挥一定的作用,能够实现语义信息检索的目的。
2 模型的构建
2.1 数字图书馆信息领域本体的建立
数字图书馆信息领域本体的建立方法为:
2.1.1 单本体法
通过利用单本体法,所有本体能够对共享词汇集进行提供。全部信息源只有与所有本体进行紧密联系,才能够获取相同的语义。通过选用单本体法,能够对某一特定区域进行具有针对性的映射。值得注意的是,对于单本体法,它的使用前提条件就是无论信息源发生何种变化,均不会影响单本体。
2.1.2 多本体法
在多本体法中,需要对各种信息源进行详细描述,并且确保所有的本体都有属于自己的词汇集,对于信息源,当发生变化时,本体结构只会出现比较小的变动,本体结构并不会受到太多的影响,充分展现出多本体方法的优势特点。
综上所述,在实际中,需要根据领域本体的具体要求,对单本体方法、多本体方法进行合理选择,用户可以在数字图书馆信息资源中快速搜索到自己所需的文献资料。
2.2 用户查询信息处理
针对数字图书馆信息区域的本体,在对其进行构建以后,需要对用户的查询信息进行有效处理,针对文本形式,应选用相同的方法来对进行详细分析,然后在文档数据库中,对用户查询信息进行有效储存,通过对数字化文档元数涵义进行分析后可知,根据MAR标准原则,有效提取文档数据库中的文档信息。利用XML,提取元数库内存在的元数据组织,以实现数据信息的共享。其中,文档元数据提取流程示意图,如图1所示。
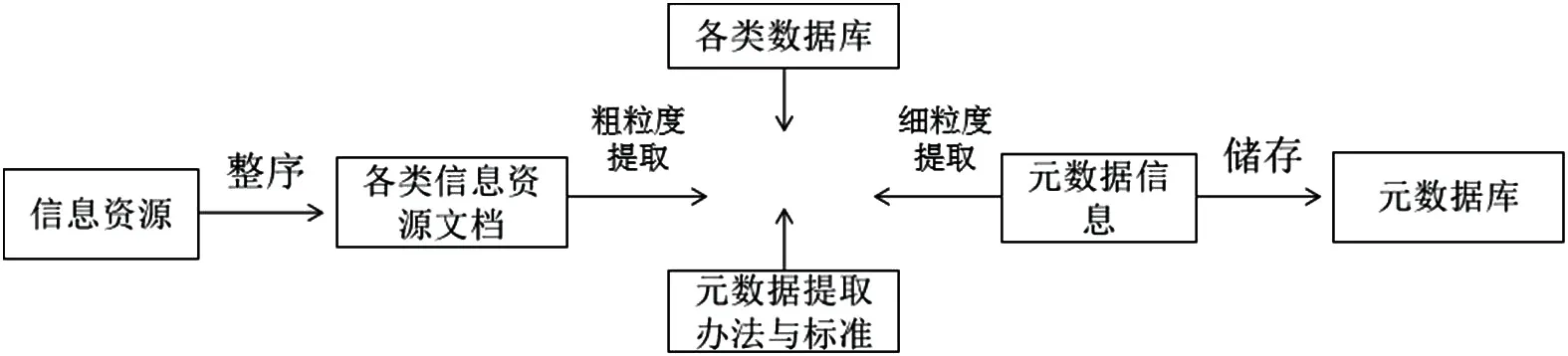
图1:文档元数据提取流程示意图
在遵守MARL元数据提炼原则条件下,需要对所有的数据库信息进行有效提炼,并进行进一步深度细化处理,然后有效提炼出所有的文档信息元数据。值得注意的是,针对XML,由于它不能够有效描述予语义,因此需要建立健全概念模型。针对一些工具,为能够对元数据建立工作量进行减少,需要选用主题词、语义字典等来对其进行有效简化处理。
2.3 检索数字图书馆信息
处理全部的用户查询信息以后,应构建数字图书馆信息检索模型,具体操作过程为:
(1)针对全文中出现的单词,应选用智能算法来对其进行有效处理,然后对候选术语长度、候选术语出现频率、候选术语出现次数总和进行精准计算。其中,运用到的计算公式为:

在以上公式中,C-Value代表智能算法;A代表候选字符串;f代表出现频率;Log代表字符串的总长度。
(2)候选术语列表获取成功之后,应对可以接受的精度进行有效计算,对加权因子的权重进行有效计算。其中,加权因子的计算公式为:

在该公式中,w代表词汇;n代表术语总数;t(w)代表术语的数目;weight(w)代表加权因子。
(3)建立模型层次架构,如表1所示。

表1:数字图书馆信息检索模型层次架构
在表1中,第1层次:应用层,即入口集合,为方便用户在各种功能界面中获取需要的信息,需要对人工智能服务技术进行充分利用;第2层次:服务层,旨在为用户提供智能信息检索服务、个性化信息推送服务等优质服务,该层为数字图书馆信息检索模型中的重要内容;第3层次,支持层,可以采集、检索、分类、储存等图书馆信息,在数字图书馆信息检索平台中,具有引擎的作用;第4层次,资源层,在数据库中,资源层是重要支撑,发挥重要的作用。其中,本文建立的数字图书馆信息检索模型,如图2所示。
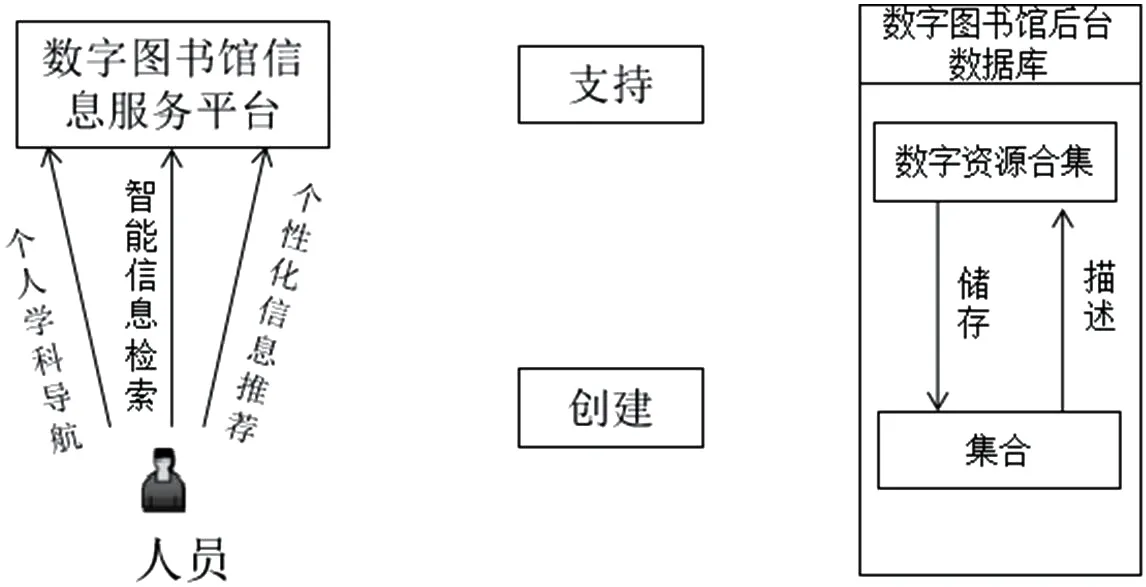
图2:数字图书馆信息检索模型
该模型的基本工作原理为:
(1)将概念检索技术作为重要基础,建立相应合理的领域本体。
(2)严格遵守MARL元数据标准,并以此为重要基础与条件,运用大数据分析技术,对信息源数据进行充分收集,然后构建相应科学的元数据库。
(3)检索界面应能够灵敏接收到用户的各种查询请求,能够及时处理检索的各种需求。
(4)科学排序领域本体的语义相似度,按照相似度由大及小的顺序进行有序排列。
2.4 仿真结果分析
选取550篇不同领域相关的本文资料,对本文建立的新模型的可行性进行验证。在本次仿真过程中,分别利用传统检测模型、新建模型,对检索匹配结果进行检测,包括检索精准率、检索召回率、检索平均权重等。其中,传统检索模型、新建模型的检测结果,分别如表2、表3所示。
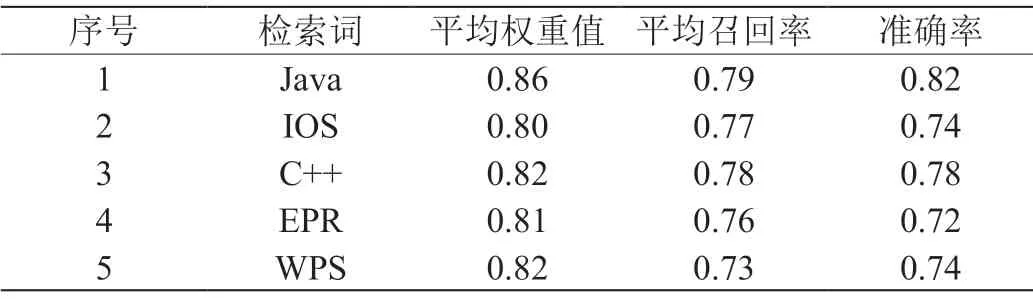
表2:传统检索模型的检测结果
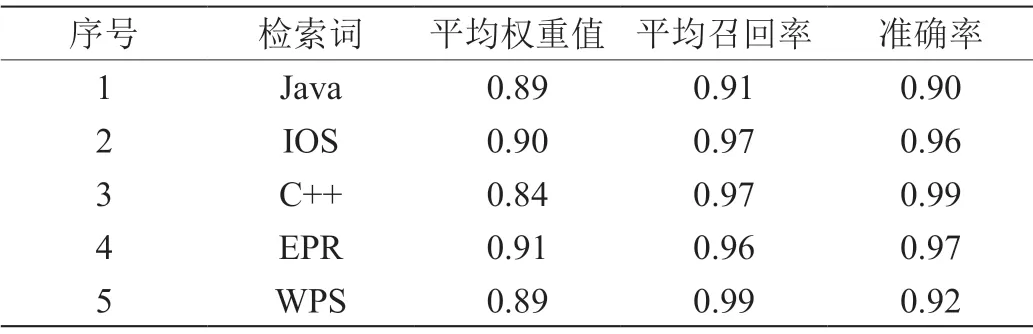
表3:新建模型的检测结果
通过分析表2、表3后发现,利用新建模型获取的检索效果要优于传统检索模型的检索效果。通过深入分析,主要原因为:
(1)与查询SaaS领域之间存在密切关系,可以得到高精准度的检索结果;
(2)与检索的角度之间存在密切关系,通过使用新建模型来进行检索时,应先对全部的检索词的语义进行有效处理。
3 结论
综上所述,本文构建了一个基于大数据分析技术的数字图书馆信息检索模型,旨在解决传统数字图书馆信息检索模型中存在的问题。在新建模型中,大数据分析技术发挥着极为重要的作用,与传统检索模型相比,大数据分析技术具有更为丰富的使用功能与使用价值,用户可以智能化搜索图书馆信息。本文对基于大数据分析技术的数字图书馆信息检索模型设计进行了深入研究,以期能够对有关工作人员起到一定的参考作用。
