大型企业集团财务合并报表系统的性能研究
2021-03-07关宏昊
关宏昊
(国能网信科技(北京)有限公司 北京市 100001)
1 合并报表系统建设的背景
企业集团财务合并报表系统能提供直观的趋势预测、预警分析等功能,在为管理者提供决策依据方面发挥着越来越重要的作用。
原神华集团是大型央企企业集团,独立核算单位超过1000家,合并层级6级,账务数据量每年3000多万条,合并报表的编制难度在大型企业集团中属于较高级别。2013在基于并账法的理论研究成果和信息化手段,成功自研了基于SAP的BIX合并报表系统,提升了企业内部管理效率。但随着系统核算单位、用户数量、报表数量及账务数据的不断增长,系统性能问题尤其生成报表的性能问题逐渐显现,经过多次系统调优不能完全解决。
2019年原神华集团和国电集团重组为国家能源集团后需要形成完整一体的全集团合并报表系统。根据估算全集团独立核算单位超过3000家,合并层级达到8级,账务数据量每年超过亿级。原合并报表系统已不能满足合并后系统的功能、性能要求,急需启动新的财务合并报表系统的研发项目。
本论文将结合国家能源集团新财务合并报系统建设的实例,从系统性能角度以生成报表的实现技术、方案为重点,旨在使所有读者对该系统的设计、实现、部署等方面有准确而全面的理解。
2 系统的结构
2.1 系统架构
2.1.1 应用架构
应用架构描述财务合并报表系统涉及的主要应用功能组织结构与具体功能内容。系统功能设计如图1所示。
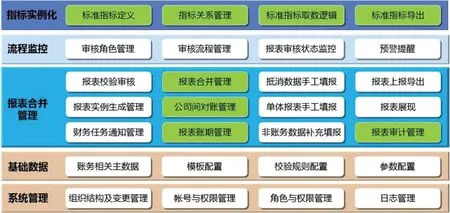
图1
2.1.2 部署架构
平台部署满足高负载、提供更好的用户体验及快速问题恢复的需求。因此采用分布式、应用集群相结合的部署模式。整体环境拓扑图如图2所示。
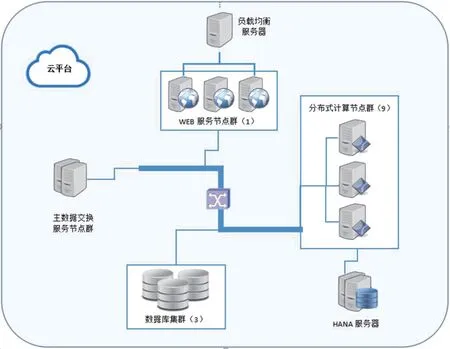
图2
2.2 技术实现路线
项目中融合了分布式计算、分布式存储、分布式服务等前沿技术。
财务合并报表系统的研发语言以JAVA、NodeJS为主,开发框架以SpringBoot为主。采用Express作为node.js Web应用框架,前端采用DHTMLX框架。
采用分布式计算,以Spark作为分布式计算引擎,提供数据计算服务,将计算分析结果在系统中展现。
采用分布式服务,提供数据校验微服务、数据计算微服务、数据汇总微服务。微服务支持容错,每个数据节点都有备份,有节点失效仍能保证系统运行。集群中的微服务节点都是对等的,多机可以同时服务。
采用Kafka消息技术实现分布式服务之间异步通讯。
以JSON、XML作为数据接口标准,以WebServiceRESTful作为基础服务描述标准。
3 基于性能优化的设计方案
3.1 原系统存在性能问题的主要功能
(1)报表编辑效率低,尤其大表。如分布资产负债表约4000个单元格,右键编辑一个单元格需要6分钟。
(2)报表生成,集团合并报表要60分钟以上,单体公司合并报表25-40分钟。用户并发量大时系统明显卡顿,严重影响报表出具工作。
(3)报表检验,集团用户报表检验20分钟左右,单体用户5分钟左右。
其中最关键的用户需求就是生成报表的速度,原系统每月底月初4个工作日大约生成报表40万张,账务数据3千万。新系统根据估算用户数量翻2-3倍,出具报表周期根据集团要求由4天缩短为2.5天,生成报表每周期约160万张,账务数据亿级以上。可见系统的性能要求大幅提升,好的实现方案和性能设计是系统成功的关键。
3.2 数据获取方案
分别对MDX和HanaView技术路线进行测试和验证,从多角度进行评估,为财务合并报表选择数据集成方案。
3.2.1 MDX方案
基于BCS/BW系统提供的QUERY服务,通过MDX进行数据传输和交互,进行查询数据解析。完成数据对接、取数方案实施和配置工作。
3.2.2 HanaView方案
基于Hana系统提供的视图数据源,通过sql进行数据查询提取,完成取数方案实施和配置工作。
3.2.3 结论
通过对两种技术方案的接口执行效率、实施配置、可扩展性、外部支撑等POC测试结果,结合项目组技术顾问、业务顾问的内部意见征集,一致认为基于HanaView数据获取方案更适于系统的数据集成工作。
3.3 财务报表设计器方案
基于SpreadJS在线表格编辑器,用户可基于Excel模板定制报表样式,支持线上、线下编辑模式,即时编辑保存。支持多数据源、多层设计、拖拽设计所见即所得的报表设计方式。逻辑公式语法设计:支持取数、分组汇总、if条件、sum|count|max|min等汇总方式、自定义变量等。
3.4 报表生成方案
报表生成是整个系统的核心功能,也是之前系统主要性能瓶颈功能。项目组依据在报表项目上的经验积累,创新性提出多项技术应用于系统开发。
3.4.1 分布式数据处理
分布数据处理使数据处理可以相对均匀的分布在每台分布计算节点,提高系统处理能力。并且在系统数据处理能力遇到瓶颈时通过增加分布计算节点提高处理能力。系统现在分布式计算节点群是9台虚拟机服务器。
3.4.2 队列排队
系统采用任务队列机制,进行报表生成、报表检验、报表下载等功能操作时生成工作任务并进入队列排队执行。避免突发大并发访问导致性能问题,是系统可靠性的重要保证。
3.4.3 高效数据处理引擎
系统采用V8数据处理引擎,V8引擎是一个JavaScript引擎实现,相比其它的JavaScript的引擎转换成字节码或解释执行,V8将其编译成原生机器码,并且使用了如内联缓存(inline caching)等方法来提高性能。V8支持众多操作系统,同时也具有很好的可移植和跨平台特性。
3.4.4 基于相同数据源公式并行执行
财务合并报表系统有报表450余张,每张报表都有几十个到几千个单元格,每个单元格都按照业务逻辑根据语法设计定义了复杂的取数逻辑。每账期用户都会选择具有权限的报表批量多次生成报表。报表生成时每个计算单元都进行SQL请求,会有大量的并发请求,影响HanaView的性能。经过语法分析,大量公式可合并成基于相同数据源公式并行执行、一次性读取,有效减少SQL大并发请求,节省查询时间和返回数据量,减少系统I/O开销。
3.4.5 智能数据分批技术
系统从HanaView取账务数据是将数据切割分组读取。但由于模型中没有分批依据字段,造成取数不均、单一批次执行过慢,从而造成报表生成过慢。通过智能数据分批技术,自动分析和识别取数列和条件获取最小范围数据,使账务数据均匀获取。
3.4.6 按业务逻辑合并
获取账务数据后,分布计算服务节点(9台服务器)以Spark作为分布式计算引擎并行处理各类功能逻辑计算。
4 性能对比分析
依据性能优化设计方案,系统实现后对比分析,如图3所示。
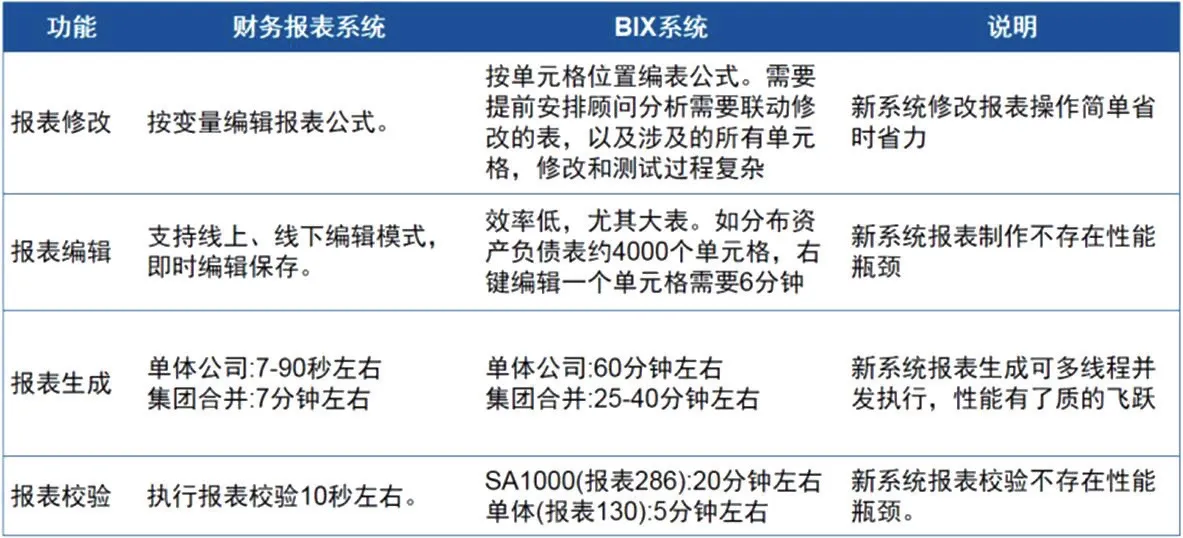
图3
5 结论
在国家能源集团智慧化战略及发展战略总体引领下,成功搭建了基于账并、表并的大型财务报表合并系统。利用分布式数据处理、智能数据分批、相同数据源公式并行执行、高效数据处理引擎等创新技术,全面解决了原系统存在的性能问题,高效实现全集团各级单位出具财务报表,各级单位决策支持的响应速度大幅提升。同时为大型企业集团合并报表系统的建设提供了一个实例,也为大型合并报表系统性能改进提供方法思路与经验借鉴。
