一种基于多通道联合采样的彩图重建方法
2021-03-07夏德虎
夏德虎
(深圳市企鹅网络科技有限公司 广东省深圳市 518057)
传统信号处理过程受奈奎斯特/香农信号采样定律[1,2]约束,要求信号采样速率大于信号带宽的两倍,才能无失真的重构原始信号信息。随着信号带宽不断增加,信号采集,压缩,传输,解压缩,存储等环节都面临巨大压力。Donoho等人在2006年提出的压缩感知理论[3]指出,针对具备稀疏特性或经变换后具有稀疏特性的原始信号,当传感矩阵满足RIP(the Restricted Isometry Property)[4,5]特性时对信号进行变换采样,获得相对原始信号更低维的观测值(比原始信号少得多的值),能通过特定算法依据传感矩阵和观测值高概率的重构出原始信号。大量针对图像压缩感知的研究成果均以灰度图像为研究对象,然而彩色图像的压缩感知研究相对缺乏,尤其是专门针对彩色图像的深度学习重建研究模型。目前在比较彩色图像重建算法性能指标时,一般将现有基于灰度图像的算法模型在彩色图像多通道分别处理。这种方法忽略了三通道间像素的强相关性,在重建质量和重建速度上还有较大提升空间。这是本文试图从彩色图像采样矩阵及重构算法两方面着手研究的目的。
1 相关工作
深度学习在图像处理的巨大成功吸引了较多学者考虑将相应迭代优化方法和神经网络相结合。比如,在稀疏编码中,Grefor和LeCun提出了一种引入LISTA[6]快速计算最优稀疏编码近似值的算法,其中,用自学习的两个矩阵代替了ISTA[7]中预定义的矩阵。Mark通过扩展AMP[8]算法,提出可学习AMP网络用于解决稀疏线性逆问题。2016年Yang使用将ADMM模型和深度学习相结合针对核磁共振成像提出了一个ADMM-Net的模型[9]。Zhang等在2018年基于ISTA[7]算法也提出了ISTA-Net[10]及ISTA-Net+[10]通用压缩感知重建框架,性能得到大幅提升。Yao在ReconNet[11],基础上将网络层次增加到4层,并加入残差网络的设计,提出DR2-Net[12]图像压缩感知残差网络。2019年练秋生等提出MSRNet[13]多尺度卷积深度网络,增加卷积的感受野,进一步提升了压缩感知的重建效果。同年石武桢提出的基于卷积模块的CSNet*[14]也是端到端的深度网络。2020年Zhang提出将采样矩阵也进行自学习的端到端的压缩感知神经网络OPINE-Net[15],除了采样率,其他的所有参数全部由网络进行自学习,重建部分使用ISTA-Net[10]将重建效果得到了进一步提升。Chen等提出一种多阶段的渐进式网络重建方法MAC-Net[16],递进式融合每阶段的重建结果。Pang[17]等提出一种自监督贝叶斯神经网络,为无数据集的图像压缩感知重建提供了一种思路。Zheng等提出RK-CCSNet[18],利用多次 3×3 卷积进行不同采样率的降采样,并使用一种LRKB的网络单元进行图像重构。2020年石武桢提出应用于彩色图像的可迭代深度压缩感知模型ICSNet[19],分为采样网络和可迭代重建网络。采样网络采用了各通道独立采样,重建网络分为初始化重建和深度迭代重建,使用独立的滤波器对每个通道进行初始化。其模型基于32×32大小的图像块进行设计并使用96×96大小的图像块进行设计。2021年Zhang等提出AMP-Net[20],将近似消息传输算法[8]展开成深度学习模型,并集成deblocking模块消除压缩感知中的常见的块效应。
2 本文提出方法
基于数据驱动深度网络在压缩感知的成功应用,本节提出用于彩色图像压缩感知重建的深度残差卷积神经网络(Deep Residual Reconstruction Network for Color Image Compressive Sensing,简称DR2-CI-Net),其模型组成为采样子网络、初始化子网络和联合重建子网络,见图1。和大多数应用于图像的压缩感知深度学习模型一样,DR2-CI-Net基于图像块进行设计,这样能降低模型参数量,减少运行时所需内存并缩短运行时间。
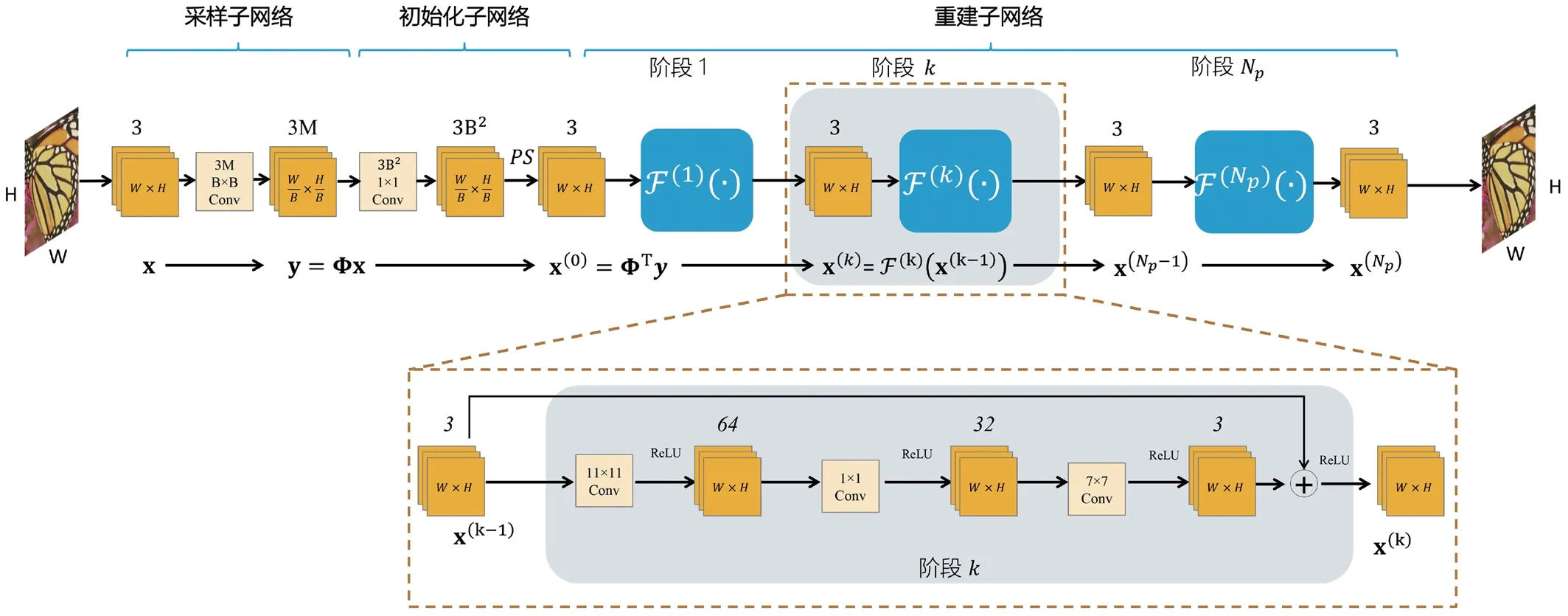
图1:DR2-CI-Net网络结构。其重建子网络由多层残差网络组成,每层由11×11,1×1,7×7卷积单元构成,卷积操作后输出和输入保持相同尺寸,每层输出结果和输入做加法合并然后进行ReLU(最后一层除外)。PS是对图像进行PixelShuffle[21]操作,将3B2维度的m×n数据转换为3通道的mB×nB的图像
采样子网络模拟信号采样过程,由模型自行学习采样矩阵网络权重。设模型基于图像块 B×B,B一般为33或32或其他数值。实际的自然图像尺寸可表示为 (kB-w)×(lB-h),k,w,l,h均为正整数。为了让模型的输入标准化,可通过填充0的方式将自然图像实际尺寸变为 nB×mB,即长W和宽H均为B的倍数,经模型采样,初始化重建得到同尺寸的图像,最后再将填充的部分进行裁剪丢弃,得到真实大小的原始图像。这样采样子网络的实际输入为x∈RnB×mB×3。用 N=B2表示单个图像块单通道展开的数据维度,采样率表示为R,用 M=RB2表示单个图像块单通道的观测值的维度。对于输入 x∈R3N×mn,观测值 y=Φx∈R3M×mn,观测矩阵 Φ∈R3M×3N。模型使用卷积层实现上述采样过程,卷积核大小设计为 B×B,步长为B,卷积核个数为 3M,padding为0,所以输入图像经过卷积层后,将输出 3M个m×n 大小的图像块,正好满足特定采样率的要求。举例说明,B取33,采样率为0.25,当m和n都为1时,输入x实际为单个 33×33×3图像块。卷积核大小为 33×33,步长为 33,卷积核个数为 3×332×0.25=816,padding为0,经过卷积之后,得到 816个1×1 的图像块,即得到了816个观测值。若m和n为2时,最终得到 816个2×2 的图像块,即得到了3264个观测值。可见,采样子网络通过1个卷积模块实现了对整张图像3通道的联合采样。
2.1 DR2-CI-Net网络模型
初始化子网络根据观测值进行信号的初始化重建。模型同样设计了1个卷积模块对观测值进行上采样,实现采样子网络的逆过程。输入观测值 y 可看作为3M个通道的 n×m 图像,需要得到3N个通道的 n×m 图像。因此,使用卷积层实现上述上采样过程,卷积核大小设计为 1×1,步长为 1,卷积核个数为 3N,padding为0,所以y经过卷积层后,将输出 3N个m×n 大小的图像块,表示为∈R3N×m×n。卷积层的网络权重参数直接来自采样子网络,可表示为ΦT∈R3N×3M。为了得到原始图像的结构,使用PixelShuffle[21]对做结构变换,因为 N=B2,所以reshape后可得到 x(0)∈R3×mB×nB的初始重建图像。
重建子网络将初始化子网络输出的初始化重建图像经过深度重建得到最终的重建图像。DR2-Net[12]的重建部分由多层残差迭代单元 Fr(·) 组成。其输入为1×33×33初始重建图像块 x(0),输出为1×33×33的图像重建块包含四层残差学习网络单元,每个网络单元包含三个卷积层。每一个网络学习单元,第一个卷积层使用11×11卷积核生成64个特征值;第二层使用1×1卷积核生成32个特征值,第三层使用7×7卷积核生成1个特征值,为保证重建过程图像尺寸保持不变,在卷积操作中引入padding。以上重建迭代单元因为基于卷积操作,因此很容易从适应单通道图像数据修改为适应三通道的卷积操作。
卷积层的设计详见表1,每一个迭代网络学习单元,第一个卷积层依然使用11×11卷积核生成64个特征值,将卷积核输入通道由1变为3即可,实际网络参数变为了原来的3倍;第二层保持不变,第三层还是使用7×7卷积核输出通道由1变为3,为保证重建过程图像尺寸保持不变,在卷积操作中引入padding。
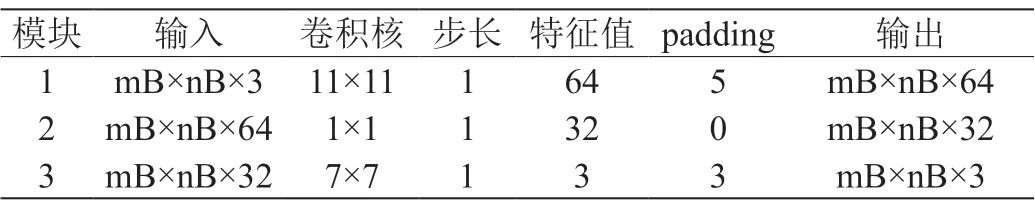
表1:DR2-CI-Net联合重建层迭代模块卷积核设计
联合迭代重建过程可表述为:
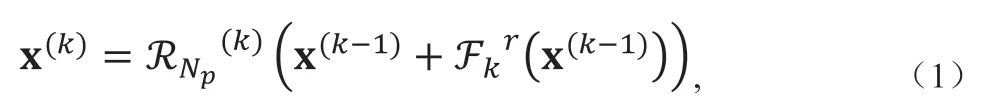
其中,Np指总的重建残差子网络层数,k表示当前重建子网络序号,Fkr代表第k层重建子网络,每一层的网络权重参数独立,指激活函数,
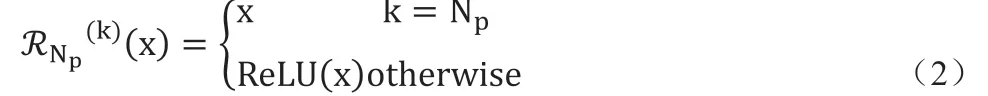
即除了最后一层不添加ReLU激活函数,其余重建子网络都将上层网络输出和本层网络重建结果相加后做ReLU处理。为了进一步提升迭代网络重建效果,进一步引入迭代层自学习贡献因子,让网络学习到当前层对最终重建图像的贡献因子,每次迭代子网络重建后的结果在和上一层合并时增加一个系数 λk,并由网络进行自学习,因此公式(1)可进一步变为:
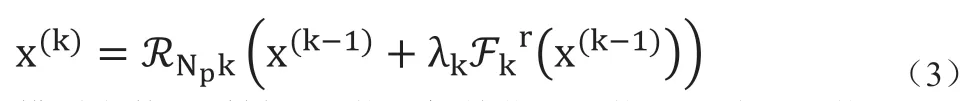
模型参数由采样子网络、初始化子网络及重建子网络三部分组成。采样子网络有三通道的联合采样矩阵 Φ 及用来加速学习的采样因子 α 。初始化矩阵无网络参数。联合重建子网络由 Np个迭代子网络的参数组成,每一层迭代子网络有该层对重建结果的贡献因子 λk,以及 F(k)映射变换的模块参数。因此模型参数组成为Θ={Φ,α,λk,F(k)}。以ratio=0.25,块大小为33为例,参数计算过程如下,详见表2。

表2:DR2-CI-Net模型参数计算说明,ratio=0.25,B=33,Np=9
2.2 损失函数设计
损失函数由模型输出和输入误差及观测矩阵正交性误差组成:
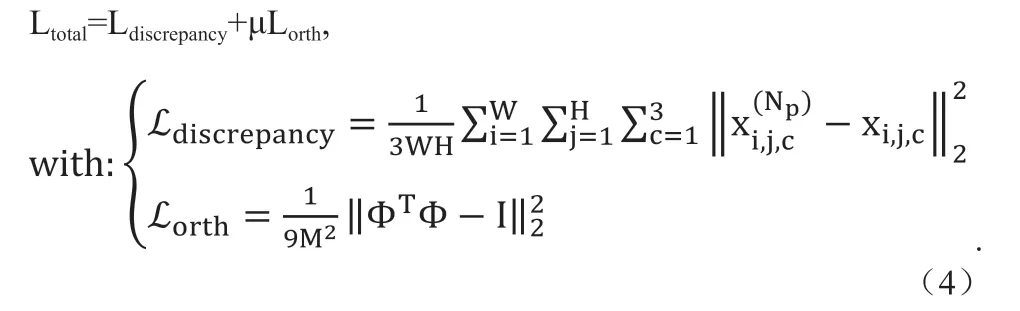
Ldiscrepancy是指重建后的图像和原始图像像素间的差异,这是主要的图像重建误差衡量指标。Np表示迭代重建子网络的数量,W和H分别对应图像的长和宽,表示模型最后输出的重建图像对应坐标上对应通道的像素值,xi,j,c表示原始图像对应坐标对应通道的像素值。Lorth是对采样矩阵的正交性约束,I∈R3M×3M为单位矩阵,μ 取0.01。
3 实验数据
3.1 模型训练
选取BSD500[22]作为训练集来源,选取其中训练集200张图像和验证集200张图像共400张图像,其中经过人工核实训练集编号为302003的图片和Set5[23]测试集中的图像woman_GT.bmp相同,故从样本集中删除该图片,最终形成399张图像作为总样本集。按照原图像加翻转、旋转90度、旋转90度加翻转、旋转180度、旋转180度加翻转、旋转270度、旋转270度加翻转共7种方式进行增强后每张图像由1个样本增强为8个样本。将每张图像按步长47,块大小96×96截取为360个图像块,再随机选取128000个图像块作为训练集,取名为trainset-96。本文的训练及测试环境为:CPU型号为intel Core i7-7700,GPU使用Nvidia GeForce GTX 1080 Ti,电脑内存32G。Python版本为3.6,Pytorch版本为1.7。
3.2 实验对比
本文首先按彩色图像重建效果客观评价指标PSNR和SSIM同其他非独立采样深度学习模型进行了比较。大量研究成果表明深度学习模型重建效果显著高于基于传统优化类算法,因此未将传统优化算法作为比较对象。本文选取了ReconNet[11]、ISTA-Net+[10]、OPINE-Net[15]、CSNet*[14]和ICSNet[14]几个深度模型进行了对比。这些网络模型都是基于图像块进行设计,前四个网络模型针对灰度图像进行特殊设计,ICSNet[14]针对彩色图像进行设计。对比结果见表3及表4,可看到基于CI-Net框架设计的三个压缩感知深度学习模型在重建图像PSNR和SSIM两个指标上相对于其他对比模型都有明显优势。ICSNet[14]、DR2-CI-Net同属于纯数据驱动的模型,重建质量和速度相当,DR2-CI-Net能取得最好的重建质量和重建速度。
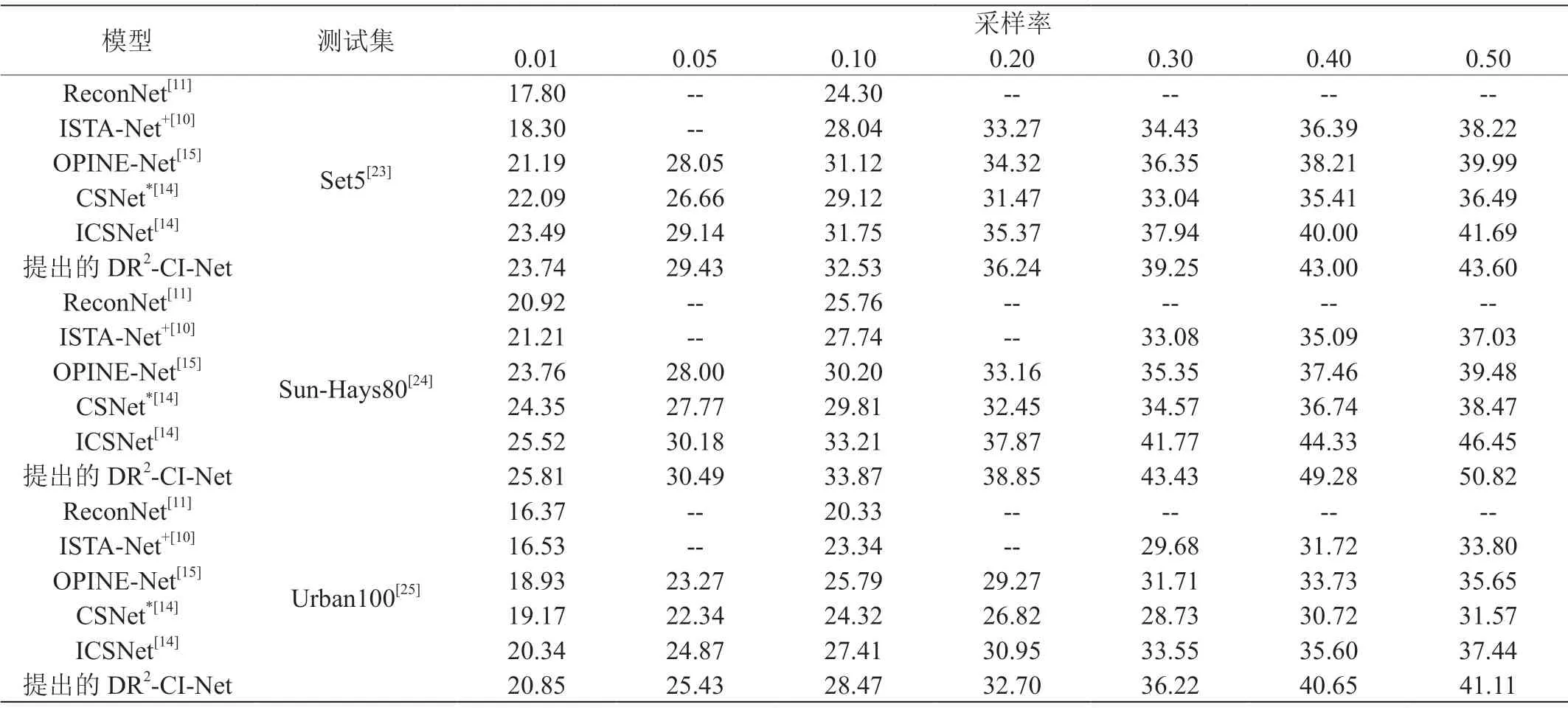
表3:不同模型的重建图像PSNR指标比较

表4:不同模型的重建耗时对比。结果均为相同GPU测试结果。测试集:Set5[23];ISTA-Net+[10]采用逐通道处理。各模型耗时仅计算深度学习模型的处理时间,不含图像预处理及基于块的合并等处理时间
3.3 重建结果的主观对比
选择不同场景的几个彩色图像在较低采样率下通过重建图像的主观横向对比。见图2在采样率为0.01的较为极端的情况下,ISTA-Net+[10]已无法分辨图像轮廓,且块效应非常明显。OPINENet[15]因使用自学习的采样矩阵及去图像块效应的设计,重建的结果主观上感受要好很多。CI-Net的三个网络模型重建结果明显更好一些,轮廓清晰,且图像细节也有较为准确的还原。当采样率继续提升到0.1后(图3),重建图像整体主观上已比较接近,在细节上依然存在较大差异,DR2-CI-Net表现更好。

图2:Set5[23]中butterfly图像在采样率为0.01时各种重建网络模型主观视觉对比

图3:Set5[23]中woman图像在采样率为0.1时各种重建网络模型主观视觉对比
4 结束语
DR2-CI-Net是由采样子网络、初始化子网络和联合重建子网络组成的应用于彩色图像压缩感知的端到端深度学习模型。采用多通道联合采样和联合重建,明显提升采样质量和重建效率。在图像采样、初始化和重建过程所有参数均由模型自行端到端进行学习。另外引入残差学习机制,通过叠加多层卷积神经网络模块,使得三通道联合重建变得更加高效。进一步,引入迭代层自学习贡献因子,让网络学习到当前层对最终重建图像的贡献权重,明显提升了彩色图像压缩感知的重建质量。
