基于GoLPP的人脸超分辨率算法实现与实验分析
2021-03-07杨海迎
杨海迎
(云南机电职业技术学院 云南省昆明市 650203)
1 实验环境及评判标准
1.1 实验平台
实验对于硬件的要求不是很高,我们在intel (R) Core i5 CPU,2G DDR3 的硬件环境下进行实验,在 Window 7 操作系统下即可实现本文的算法。由于图像数据量大,以字节型存储,综合各方面考虑,本文选用Matlab7.0 作为实验平台,采用Matlab 编程语言完成算法的实现。
1.2 人脸库说明与评判标准
本文实验在中科院的CAS-PEAL 人脸数据库[1]上进行。CASPEAL 人脸数据库包括1040 个人的正面图像,男性595 人,女性445 人,每个人有不同光照、表情、距离、附加物(眼镜)的正面图像,一共9954 张图像。本文采用均匀光照、正常表情下的正面无附加物人脸库Gallery 作为训练集和测试集,Gallery 总共有1040幅正面图像,我们随机挑选800 幅作为训练集,其余的240 幅作为测试集。在试验之前,首先要把训练集和测试集里的正面图像进行预处理,原始图像的大小为120×96,因为每幅人脸都是正面图像,并且包括头发、衣服等其他黑色区域,首先定位到眼睛区域,再通过水平投影和垂直投影找到眼睛的最复杂区域,即眼球中心,用白点标识。通过旋转、平移变换,让所有的图像的眼睛都在一条线上,裁剪出人脸区域并缩放成统一大小的人脸图像。本文经过预处理后的图像大小为112×96,裁剪后的人脸如图1所示。在本文中,下采样因子为4,下采样后的低分辨率图像的尺寸为28×24,GoLPP的迭代终止阈值ξ=0.001。

图1:图像预处理
在残差补偿的实验中,我们没有采用更多的人脸图像来训练,而直接使用训练集中的每一幅图像作为输入,用输入以外的其他训练图像来完成全局重建。本文采用均方差(Mean Square Error,MSE)来和峰值信噪比(Peak Signal to Noise Ratio, PSNR)作为算法性能的评判标准,MSE 的计算公式定义如下:

其中Ior为测试图像It对应的原始高分辨率图像,Ih为本文的重建图像,m 和n 分别为高分辨率图像对应的长度和宽度,在本文的实验中,m=112, n=96。从MSE 的定义可以看出,MSE 越小则重建结果与原始图像越接近。PSNR 则不同,PSNR 越大,则说明与原图越接近,PSNR 大于30 则说明失真很小,与原图基本上吻合。PSNR 的计算公式如下:
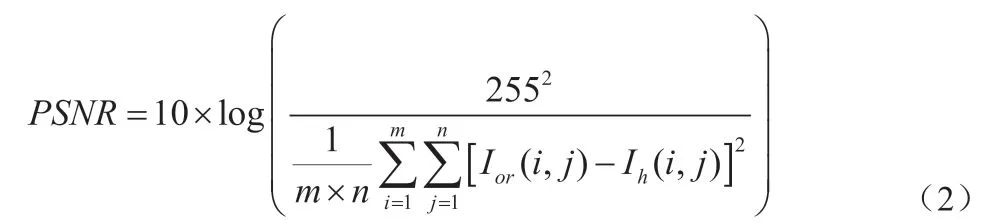
为了充分说明在GoLPP 上加上K 近邻限制的必要性,我们给K 取不同的值来验证。另外因为基于学习的算法很大程度上依赖于训练集,我们又在不同数目的训练集下做了试验,还分析了不同GoLPP 的特征数对实验结果的影响。
2 普通人脸实验结果分析
现有的人脸超分辨率算法大多都只考虑普通人脸图像(正常光照、中性表情、无附加物)的重建,本节也只考虑普通人脸的重建。为验证本文提出的算法的有效性,分别与Bicubic 插值、PCA 方法和LPH 方法做了比较。因为在GoLPP 的基础上加入了K 近邻限制,还对K 近邻的影响进行了分析。GoLPP 是一种降维方法,低维空间的维数(GoLPP 保留的特征数)如何确定,以及训练样本集大小对本文算法的影响,针对这两个问题,我们也做了进一步的分析。
2.1 实验结果对比
在CAS_PEAL 人脸数据库上,我们随机选取800 幅正常光照下的人脸图像作为训练集,其余240 幅作为测试集。实验中,高斯函数的方差σ=128,GoLPP 保留的维数dim=200,近邻数K=10,降采样因子γ=4,残差补偿过程中低分辨率残差块的大小为3×3,则对应的高分辨率残差块的大小为12×12。为了评判本文算法的优劣,我们与几种经典的方法做了比较。实验结果如图2所示。

图2:实验结果比较
从直观上看,Bicubic 插值的结果比较模糊,特别在眼睛、鼻子和嘴巴部位尤为突出,这是因为插值法只从输入图像中获取信息,而因为输入图像本身就已丢失了很多高频信息,所以插值法不能有效地补充缺失信息。PCA 是一种线性方法,不能够学习出人脸内部的非线性信息。PCA 方法重建的人脸图像在边缘和嘴巴区域都比较模糊,整幅图像都显得不够平滑,视觉效果不好。从肉眼上看,感觉Zhuang 的LPH 方法和本文提出的方法效果差不多, Zhuang 采用LPP 方法来提取人脸图像的潜在特征,LPP 的邻居图是人为预定义的,并不能保证这样构建的图是最优的,而本文的GoLPP 方法则是使用一个迭代的机制去求解最优权值,从而得到最优变换矩阵,从这个层面上说,本文的方法理应得到比LPH 方法更好的效果。图3 列出了Bicubic 插值、PCA 方法、LPH 方法和本文方法的PSNR 和MSE。

图3:MSE 比较
从图2 和图3 可以看出,本文的方法能够取得很好的重建效果。LPH 方法利用径向基函数在LPP 特征子空间重建全局人脸,本文采用加上K 近邻约束的GoLPP 提取潜在特征,然后用GRNN 得到全局人脸,残差补偿方法使用的都是基于邻域嵌入的方法。从实验结果可以看出,GoLPP 方法更为合理,它的权值分布是服从高斯分布的。PCA 方法不能有效发掘数据潜在的非线性结构,重建的效果有局限。Bicubic 插值方法得到的结果过于模糊。
2.2 K近邻的影响
出于时间效率方面的考虑,我们选取400 幅训练图像来完成这部分实验,其余640 幅图像用于测试。GoLPP 中初始权值的赋值参数σ=128,经过GoLPP 降维后,保留的维数为200。图4 分别列出了K=5、K=15、K=50、K=100 和K=400(不加K 近邻限制的GoLPP)得到的实验结果。

图4:不同取值的K 对应的重建结果
在人脸超分辨率重建中,过多的邻居只会导致重建的图像缺失自身特有的信息,当K=400 时,也就是全部图像都加入到邻居图的构建,虽然还是能够重建出人的相貌特征,但是却不够平滑,并且有冗余信息,导致图像的视觉效果很差,在K=100 和K=300 时也体现了这一点。也就是说基于GoLPP 在人脸超分辨率重建中,给邻居图的构建加上K 近邻约束是必要的,并且邻居数超过一定范围后只会导致效果变差。图5列出了随K值的增加MSE的变化过程。

图5:邻居数K 对实验结果的影响
从图5 可以看出,当K 取值介于[10,20]之间时,MSE 最小,而MSE 越小,说明结果图像与原图越接近。当K=400 时,MSE 为488,与原图相差太大,也说明了一个事实:GoLPP 用于人脸超分辨率中应该加上K 近邻限制,且K 的值不宜太大。在比较了K 取不同值对应的实验结果后,本文后面的实验均取K=10。
2.3 训练样本数的影响
基于学习的超分辨率算法很大程度上依赖于训练集的选取,一般情况而言,训练样本数越多,重建效果越好。本文也是在基于学习的方法上来完成超分辨率重建的,也避免不了这个问题,图6 给出了训练样本数分别为400、600、800、1000 时候的实验结果。

图6:不同大小的训练样本集的重建结果
图6 中,N 表示训练样本数,当N=400 是,重建的人脸略为平滑,但是重建效果也很不错,与N=500、600的差不多,到N>700 后,可以看到在亮度和一些细节上有些许改善,但也是不太明显。光从肉眼看,我们很难分辨出随着N 的增大,效果是否变好。图2.5 列出了随着训练样本数增大,所对应的PSNR 的变化情况。
PSNR 越大,说明重建图像失真越小,越接近原始图像。从上图我们可以看到,当训练样本数小于400 时,PSNR 值均小于28,并且随着样本数的增加,PSNR 上升很快。当N>600 后,PSNR 增幅明显减缓,并且在N=700 处有轻微下降。图7 说明,一般情况下,训练样本数越多,重建效果越好,但是当达到一定上限后,增幅将会变小。在本实验中,最佳训练样本数为800,当大于800 后,PSNR 值会有少许波动。本文提出的方法在训练样本数很小的情况下也能有效重建人脸图像,对训练样本数目不太敏感。
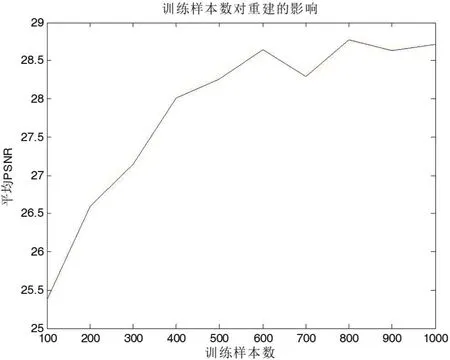
图7:训练样本数对重建结果的影响
2.4 GoLPP特征数的影响
基于PCA 的人脸超分辨率方法的重建结果会受到主成分个数的影响,GoLPP 也是一种降维方法,重建的结果也会受到保留的特征数的影响。假设GoLPP 保留的特征数为dim,表1 列出了GoLPP 保留的特征数对重建结果的影响。

表1: GoLPP 保留的特征数对重建结果的影响
当dim取值太小时,也就是GoLPP保留的特征数很少的情况下,重建的图像包含的细节特征不足,会丢失很多高频信息。而当dim太大时,GoLPP 保留的特征就会出现冗余,当达到一定的特征数后,更多的特征并不会改善实验结果,反而会加大计算量。从表1 可以看出,当训练样本数为400 时,GoLPP 保留的特征数大于160 后,重建结果就不会随着dim 的增加而改善了。图8所示是GoLPP 保留不同的特征数dim 对应的重建结果。可以看出,当dim=25 时,重建的人脸图像的边缘有模糊,在dim=50 的时候有有轻微的模糊,这种情况在dim=100 时就不太明显了。通过实验,我们发现特征数应该取160 以上,在本文算法的实现过程中,我们取dim=200。

图8:不同特征数的重建结果
3 鲁棒性分析
在现实生活中,很大一部分人是戴眼镜的,或者捕捉到的图像是带有表情的,目前大多数的人脸超分辨率算法都没有考虑眼镜和表情等情况。本文在800 幅中性表情、无眼镜的训练集上来尝试重建这两类人脸图像。
本文在CAS-PEAL 人脸数据库中挑选了20 幅戴眼镜的人脸图像来做测试,这20 个人都不在训练集中。因为我们的训练集里并不包含戴眼镜的图片,我们希望能够通过本文的算法重建出测试图像没戴眼镜时对应的高分辨率图像。
图9 给出了测试图像戴眼镜时对应的重建结果。由于基于学习的方法很大程度上都依赖于训练集,训练集没有眼镜,也就很难重建出眼镜来。PCA 和LPH 方法也有去眼镜的功能,但是因为PCA不能有效重建出人脸的非线性信息,重建的结果很不平滑,特别是在眼睛和轮廓部分。LPH 的重建结果比PCA 方法好很多,LPH 的核心算法是LPP,LPP 的转换矩阵并不能保证是最优的,对重建结果必然会造成影响,在轮廓部分还不够平滑。GoLPP 可以自适应地找出最优矩阵,所以本文提出的算法在眼睛恢复方面也是优于LPH方法和PCA 方法的。

图9:戴眼镜的人脸图像重建
在CAS-PEAL 人脸数据库中,有一部分人是有不同表情时候的照片的,我们在里面找了20 幅带表情的图像来进行测试,这20个人没有照片在训练集中。仍然是使用800 幅中性图像作为训练集,这800 幅图像都是中性表情。图10 给出了带表情图像的重建结果。可以看出,本文提出的算法还能有效重建带表情的图像,效果也是明显好于PCA 方法的重建结果,略好于LPH 方法。

图10:带表情的人脸图像重建
实验表明,本文提出的算法具有较好的鲁棒性,在训练集为中性表情、没有附加物的情况下,能够有效地去除眼镜,重建人脸的眼睛部分,并且能够有效地重建出带表情的人脸图像。
4 总结
本章首先介绍了实现本文算法的实验条件和实验结果的评判依据,并给出了相关的实验结果。通过一系列的实验分析了K 近邻、训练样本数和GoLPP 特征数对算法的影响,并给出比较合理的取值范围。实验表明,本文提出的算法能够适用训练集较小的情况,对表情和眼镜具有鲁棒性,比Bicubic 插值、PCA 方法和LPH 方法更能有效重建高分辨率人脸图像。
