基于MATLAB文字识别算法设计
2021-03-07杨鸿廖浩然李江廖洁锋
杨鸿 廖浩然 李江 廖洁锋
摘要:作为文本识别的重要组成部分,它在现实生活中的应用越来越广泛。本文主要研究了图像文本识别方法、传统方法和深度学习方法,并利用Matlab进行了识别。因此,我们对图像识别的研究有了更深的认识。字符识别技术是利用计算机自动识别和处理纸张上的字符,并将它们转换为可识别信息的技术。由于它的广泛应用,这项技术正变得越来越重要。在现代科学研究、军事技术、工农业生产、医学、气象天文学等诸多领域,文本识别技术解决了许多实际问题。本文主要考虑和研究了基于Matlab的图像文本识别方法,能够快速准确地识别输入图像,提取图像中的高级语义信息。了解图像文本识别的原理以及高级语义图像的分类和检索具有重要的研究价值。
关键词:MATLAB;文字识别;字符分割
一、设计背景
随着计算机科学的飞速发展,基于图像的多媒体信息迅速成为重要的信息媒介。在图像中,文本信息包含丰富的高级语义信息。提取这些词对于理解、索引和搜索图像的高级语义非常有帮助。文本提取可以分为两类:动态图像文本提取和静态图像文本提取。其中,静态图像文本提取是动态图像文本提取的基础,具有广泛的应用范围和基础研究。因此,本文主要讨论了静止图像的文本提取技术。静态图像中的人物可以分为两类:一类是图像中场景中的人物,称为场景人物;另一种是在影像后期制作中加入文字,称为人工文字,如图所示。由于文本的位置、大小、颜色和形状的随机性,通常很难对文本进行检测和提取。然而,人工汉字在字体上比较标准化,尺寸有限,容易识别。它们比前者更容易检测和提取,并且因为它们能够解释和总结图像的内容,所以它們适合于在图像中索引和搜索关键词。研究图像中的场景特征比较困难,这方面的研究成果和文献也不是很丰富。本文主要讨论了图像中人工特征的提取技术。
人们在日常生活和工作中需要处理大量的文本信息,这是一项劳动密集型的工作。然而,通过探索文本识别方法,我们可以提高工作效率,降低劳动强度。因此,文本识别技术发展迅速。字符采集、信息分析与处理、信息分类与识别是字符识别技术的主要步骤。信息采集是将纸张上的文字信息转化为电流信号,然后自动输入计算机。信息的分析和处理主要包括对电信号的去噪、偏移、厚度和大小的处理。信息分类识别是对处理后的文本信息进行分类识别并输出识别结果。利用Matlab软件编写Matlab语言进行字符识别和处理,阐述了字符识别的原理,用于文献检索、邮件和包裹分拣、商品代码识别、商品仓库管理等。
字符识别。识别的问题是从仅包含单词的图像中识别机器可读的字母序列。该问题的难点之一是输出空间是可变长度序列。在一般的图像分类中,输出空间的维数是固定的。此外,诸如字体、照明、颜色和比例等问题也使得识别变得困难。
字符识别活跃在生活的各个角落,如照片翻译、手机照片识别等。,大大方便了我们的日常生活,提高了我们的工作效率。相信随着人工智能(AI)的进一步发展,图像-文本识别技术将会有更广阔的应用前景。工业图像的字符识别也已经渗透到我们的日常生活中。与腾讯的OCR字符识别相比,它已经应用于现实生活的很多方面,如身份证识别、名片识别、快递号码识别等。
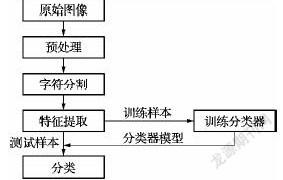
二、总体方案设计
1.数字图像预处理
由于采集到的图像数据包含了大量的信息,不需要进行计量检定。为了提取有用的真实信息,增强相关信息的可检测性,最大限度地简化数据,需要进行预处理。首先,为了去除大量杂乱的信息,需要去噪和滤波;由于数字的识别与颜色无关,如果是彩色照片,则需要先将其变灰,然后进行二值化。此外,它还涉及位置分割和图片大小归一化。
2、字符分割
分割图片时,主要根据两种情况进行划分。一个是灰度是相同的。如果图片中存在一些平衡的灰度值,并且一些灰度值具有相同的平衡背景,则可以通过设置适当的阈值来达到切割目的。另一方面,如果图像中的物体背景不能通过灰度值来区分,但是通过一些特征变化可以将属性值转换成灰度值,那么结合阈值设置的方法可以对图像进行裁剪。
3、特征提取
图像为二维信号,使用全部图像数据进行直接分类是不可取的,因此,一般都通过某种特征提取算法,将图像表示为一个长度为n的向量{x1,x2,...,xn},对应于n维空间中的一个点,特征提取之前需要将分割得到的不同子图像规格化为相同的大小。数字识别领域有两种特征提取算法。基于统计的特征提取和基于结构的特征提取。前者包括点密度、矩和特征区域,后者是指与轮廓有关的信息,如圆、端点、拐点等,反映了数字的几何结构,但抗干扰能力较弱。
4、选取分类器模型
最小距离分类器:选用笔画密度总长度特征来进行第一层的粗分类。在这种方法中, 被识别模式与所属模式类别样本的距离最小。假定c个类别代表模式的特征向量用R1, …, Rc表示, x是被识别模式的特征向量, |x-Ri|是x与Ri (i=1, 2, …, c) 之间的距离,如果|x-Ri|最小, 则把x分为第i类。最近分类器:结合网格特征和方向特征完成第二层的分类和匹配。最近邻分类器是基于最小距离分类的扩展,它以训练集中的每个样本为准则,在训练集中找到与待分类样本最近的样本,然后根据该样本进行分类。
参考文献
[1]张华萍,黄辰.文字识别技术研究[J].物联网技术,2018,8(08):17-19.
[2]田瑶琳.基于RGB分割的含数字水印图像的文字识别[J].福建电脑,2019,35(04):62-64.
[3]张国林.基于汉字识别的碎纸片拼接复原模型研究[J].科技广场,2014(01):62-64.
[4]唐玲,刘磊.基于matlab的计量手写体数字自动识别[J].工业计量,2020,30(01):43-45.
500783