Study on the Prediction System of Shrimp Field Distribution in the East China Sea Based on Big Data Analysis of Fishing Trajectories
2021-03-06GUANHuanhuanandZHAOXueli
GUAN Huanhuan, and ZHAO Xueli
1) Management College, Ocean University of China, Qingdao 266100, China
2) College of Information Science and Engineering, Ocean University of China, Qingdao 266100, China
Abstract In recent years, China has paid more and more attention to the development of marine economy and the management and protection of fishery resources. The management departments at all levels regulate and manage the fishing behavior of fishing vessels through the data of fishing trajectories. In this paper, the distribution of shrimp farms in the East China Sea is predicted by studying the trajectories and behavior patterns of shrimp boats in the system of fishing trajectories. At the same time, a set of shrimp farm distribution management system based on Back Propagation algorithm is established. It can monitor the trajectories of fishing boats and the distribution of shrimp groups in real time, which effectively improves the work efficiency and management mode of the management department. It also plays a positive role in regulating the behavior of fishing boats at sea.
Key words BP algorithm; big data; shrimp farm distribution; fishery management
1 Introduction
The East China Sea is the most important operating area of China’s marine fisheries. Due to its geographical location, the continental shelf of the East China Sea has been affected by the Kuroshio warm current, Yellow Sea cold water mass, and low-salinity system along the coast.Therefore, the East China Sea provides a high-yield habitat for various economically important species, such as fish, shrimp, and crab (Luet al., 2013). Approximately 1000 species of shrimp live in the East China Sea region,which is rich in the resources (Chen, 1994). Currently, the main fishing method of fishermen is natural fishing,which has great blindness and randomness (Huet al.,2016). China’s fishery economy has developed rapidly,but with serious negative impacts. Overfishing has damaged the ecological chain and caused a severe decline in marine resources (Xavier, 2014). Therefore, managing and maintaining fishery resources and strengthening the supervision of fishing areas is necessary (Smithet al.,2001). Accurate prediction of fishing grounds is also important for fishery managers because it can ensure that the correct waters and locations of fish are identified during an operation, provide a necessary reference for fishermen to operate at sea, and forecast the gathering places quantities. In recent years, with the development of machine learning and artificial intelligence, many researchers have combined these technologies with fishery information to predict fish schools (de Souzaet al., 2016). Many methods for machine learning exist. Most of the existing fishery situation analysis and forecasting systems are based on monthly models. Most systems are based on algorithms that include artificial neural networks, random forests, radial basis kernel functions, and univariate nonlinear regression models. Yuanet al. (2011) considered five marine environmental factors, namely, month,longitude and latitude, sea surface temperature (SST), sea surface height (SSH), and chlorophyll, and employed a radial basis kernel function-based neural network (RBFN)to predict fisheries in the Southwest Atlantic; the mean square error (MSE) of the constructed model is 0.037.Wanget al. (2015) combined fishing boat track data with ocean data (SST, SSH, and chlorophyll concentration chl-a) and constructed a monthly model to predict the distribution of fishing grounds based on artificial neural networks; the MSE of the experimental results was 0.62.Chenet al. (2009) combined squid fishing data with the SST and surface temperature gradient, and employed the arithmetic mean (AM) model and geometric mean (GM)model, respectively, to establish an integrated habitat suitability index based on surface temperature factors; the forecast accuracy of the model is 70%. To improve the forecast accuracy of the Scomber japonicus fishing grounds in the East China Sea and Yellow Sea, Gaoet al.(2016) proposed a fishing ground forecast model that was based on a boosted regression tree. The area under the curve (AUC) value of the forecast model obtained using the verification model was 0.897. Zhouet al. (2018)combined environmental factors with fishing data to build a model based on the Bayesian classifier for the prediction of the southern fishing grounds open in the South China Sea; the average forecast accuracy of the model was 68.525%. Existing fishing ground forecast systems are monthly models that lack real-time performance and cannot update data in a timely manner. In this study, the track data of the fishing boat and the environmental factor(chlorophyll) are combined to construct a daily model for predicting the distribution of fishing grounds based on the Back Propagation (BP) algorithm. The machine learning model constructed in this study can accurately predict the fishing area, which not only improves the timeliness of a forecast but also combines the machine learning algorithms with fishery production to provide a basis for the management and the protection of marine fishery resources.
2 Data and Method
2.1 Data Source and Processing
The datasets applied in this study are chlorophyll data and fishing boat track data. The time range of all datasets is 2015–2017. The spatial range of chlorophyll data is 15˚N–45˚N, 105˚E–145˚E, with a resolution of 4 km × 4 km. Chlorophyll-containing planktonic algae are the most important primary producers in the ocean. Their photosynthesis products are the material and energy bases of the entire food chain, which determine the rise and fall of marine organisms (Shiet al., 2017). The vertical distribution of chlorophyll-a(chl-a) concentration in the ocean is extremely nonuniform and its distribution characteristics and influence mechanisms are important basic issues in marine ecology research (Yuet al., 2018). Therefore, chlaconcentration has important economic impacts on the development of fishery resources and mariculture in coastal and marine environments (Nyomanet al., 2008).In the winter or spring, when the weather is abnormally cold and chlorophyll concentrations are extremely low,marine fishery resources are scarce and the catch decreases substantially (Robinsonet al., 2016). A correlation exists between the chl-adistribution and the shrimp population distribution; therefore, the use of chlorophyll data to predict shrimp population distribution is highly feasible.
The fishing boat dataset includes the ship number, time(year, month, and day), fishing location (longitude and latitude), ship speed, and ship heading. The spatial range of the fishing boats is 25˚–35˚N, 120˚–130˚E. First, the original fishing boat dataset was categorized, and the time and fishing location were converted to a standardized format. In this study, the forecast results of the model are verified based on the fishing track data of the fishing boats. The behaviors of the fishing boats can be distinguished according to the boat speed. The speed distribution histogram in Fig.1 indicates that the fishing boats have two types of behavior, namely, fishing and navigation, with a threshold of 15. As shown in Fig.2, the track points with a ship speed less than or equal to 15 are the fishing points, and the navigation track data of the fishing boats are eliminated. In this study, the fishing points of the fishing boats are the shrimp distribution points. The fishing data of all fishing boats are integrated in chronological order and statistically analyzed on a daily basis to obtain the general distribution of fishing grounds over a month. Predicting the distribution of fishing grounds in distant seas that are unreachable by fishing boats is not very practical. Therefore, the forecasted space is only the longest distance that the fishing boats can reach plus a spatial redundancy of 0.5˚ latitude and longitude (The track of all fishing boats suggests that the fishing grounds shifted to the east.). This experiment applies September,October, and November 2015–2016 as the training set and September, October, and November 2017 as the test set to verify the forecast accuracy of the model.

Fig.1 Histogram of speed distribution.
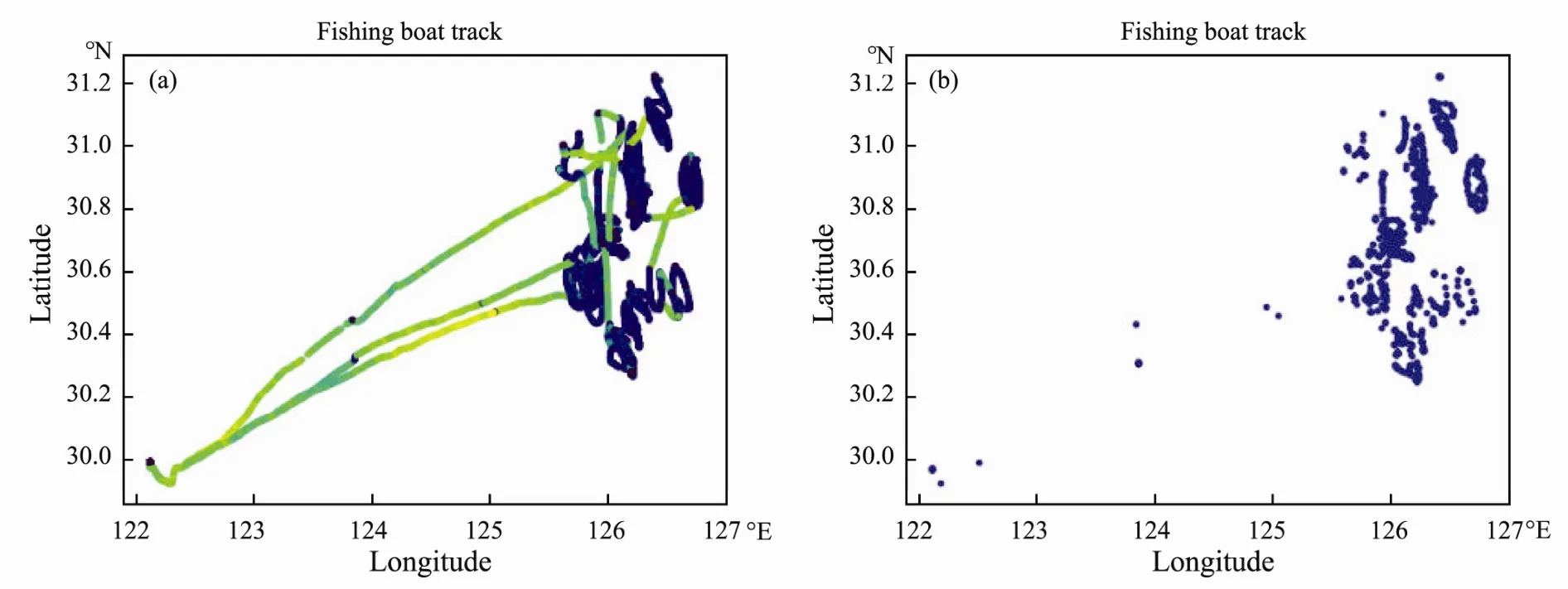
Fig.2 Track point display diagram (a) complete track of fishing boats and (b) track of fishing boats at a maximum speed of 15.
2.2 Research Method
An artificial neural network is an information processing technology that is similar to the human nervous system (Xieet al., 2011). It is a powerful and extensively employed machine learning algorithm that is extensively employed to implement functions such as classification,clustering, fitting, forecast, and compression. A BP neural network is the most prevalent neural network; it is generally composed of an input layer, a hidden layer, and an output layer. The structure of a BP neural network is shown in Fig.3.

Fig.3 BP neural network structure.
X1toXNare inputs, andY1toYMare outputs. The sample data (including input and output values) are used to train the BP neural network. After inputting information in the model, if the output layer does not reach the expected output in the sample data, the errors between them will propagate backward, and the weights are modified layer by layer and then reinput for calculation and comparison until the errors reach the established conditions. The BP neural network can simulate nonlinear systems and has excellent predictive power.
The network structure of the BP algorithm is a forward multilayer network that was proposed by Rummelhartet al.(1986). The BP algorithm is an inverse learning algorithm for multilayer networks. The basic idea of the algorithm is that the learning process consists of two processes: forward propagation of signals and backward propagation of errors. During forward propagation, input samples are passed from the input layer, processed layer by layer by the hidden layers, and then passed to the output layer (Wei, 2014). If the actual output of the output layer does not match the expected output, then the stage of the back propagation of errors begins. In this stage, the output errors are passed back to the input layer, layer by layer, through the hidden layers in a certain form, and the errors are distributed to all units of each layer to obtain the error signal of each layer unit, which is used as the basis to correct the weight of each unit. The process of adjusting the weights of each layer for the signal forward propagation and error back propagation is carried out repeatedly (Ximet al., 2001). The process of constant weight adjustment, which is the process of network learning and training, is continued until the error of the network output is reduced to an acceptable level or until the preset number of learning times is reached.
The learning process of the BP algorithm is described as follows:
1) Select a set of training examples, where each sample consists of two parts: input information and expected output result.
2) Consider one sample from the training sample set and enter the input information into the network.
3) Calculate the output of each layer node after neural processing.
4) Calculate the error between the actual output of the network and the expected output of the network.
5) Back calculate from the output layer to the first hidden layer, and adjust the connection weight of each neuron in the network according to a principle that can reduce the errors.
6) Repeat steps (3) to (5) for each sample in the training sample set until the errors of the entire training sample set establish the requirement.
The BP algorithm has a solid theoretical foundation, a rigorous derivation process, a clear physical concept, and universality; therefore, it is a suitable algorithm for training forward multilayer networks (Maet al., 2017). The following settings are applied in this experiment, which is a binary classification problem 10 hidden layers; 32 input features; and output of 0 or 1. The hidden layer uses the rectified linear unit (ReLU) activation function; the output layer uses the sigmoid activation function; the optimization function uses Adam; and the number of iterations is 100. The learning rate is 0.001, which automatically decreases by half according to the change in the loss value, and the minimum value is 0.00001.
3 Results and Analysis
In this study, the fishing grounds in offshore waters are predicted by neural networks that use chlorophyll concentration as a parameter. Accurate prediction of the shrimp fishing ground distribution is conducive to the standardized management of fishing boats by fishermen and real-time monitoring of illegal operations of fishermen. The distribution of fishing grounds in the offshore waters can be determined by studying the track data of fishing boats, which has great significance to the management and maintenance of fishery resources. This experiment uses the MSE and accuracy (ACC) to evaluate the estimation accuracy of the fishing ground distribution predicted of the BP model.
Fig.4 shows the MSE and ACC of the fishing ground distribution from September to November 2017 predicted by the BP model. As shown in Fig.4, the BP model constructed in this experiment can accurately predict the daily fishing ground distribution, which has high practical value for fishery managers and fishermen. The average ACC and MSE were 80.6% and 0.197, respectively, in September 2017; 76.2% and 0.265, respectively, in October 2017; and 77.9% and 0.225, respectively, in November 2017. The forecast accuracy fluctuates relatively slightly over time each month, and the model can accurately predict the general distribution of fishing grounds,which indicates that chlorophyll has an important influence on shrimp resources in the study area. The forecast accuracy in September is generally low, and the daily accuracy fluctuates greatly. When the fishing ground is divided according to the fishing track of the fishing boats,only the points passed by the fishing boats are considered the fishing area, while the remaining points are regarded as the point where the fishing ground does not exist.However, the possibility of fishing grounds in places that are not visited by fishing boats is also high, which weakens the effect of the environmental factors that are input in the model due to the assumption of non-fishing ground data and causes a large deviation in the forecast accuracy.In addition, a forecast error occurs every month because errors in the actual values can occur when plotting the distribution of training fishing grounds. In data processing of the fishing track points and navigation track, both cannot be completely differentiated due to the limitation of the dataset attributes. As a result, the navigation track points of low-speed fishing boats are also regarded as fishing points; thus, the model cannot be well fitted during training, which reduces its prediction capability.
Error occurs in the real value when determining the training fishing ground distribution. When distinguishing the fishing track points and navigation trajectories during data processing, they cannot be completely distinguished due to the limitations of the data set attributes. The track points of fishing boats that travel at low speed are also regarded as fishing points; thus, the model cannot adequately fit during training; thus, the forecast ability of the model is reduced.

Fig.4 Daily ACC and MSE predicted by the model from September to November 2017.
Fig.5 shows the actual and predicted fishing ground distribution maps for the same four randomly selected days (7, 15, 24 and 30) of each month from September to November 2017. As shown in Fig.3, the predicted area basically contains the actual fishing ground distribution,and the total distribution trend is similar. Generally, the locations of the forecasted fishing ground show agreement with the actual operation locations, and the movement of their locations with time is consistent with the actual situation, which indicates that the prediction of fishing grounds by the model is spatially reasonable. The figure reveals that the predicted area is larger than the actual operation area. The open sea areas that fishing boats cannot reach but where fishing grounds exist provides an option for fishermen to catch shrimp in the future. However, some individual days have large errors,which is related to not only the errors of the data of these particular days but also the model, which tends to apply training data that contain more features in the prediction of the fishing ground distribution. Since some important environmental factors (temperature, salinity, and water surface height) are not included in the input features of the model (Yeet al., 2012), the forecast results of the model have errors. Therefore, when selecting a machine learning algorithm for fishery forecasting, the selection of features is also very important.
4 Algorithm Application
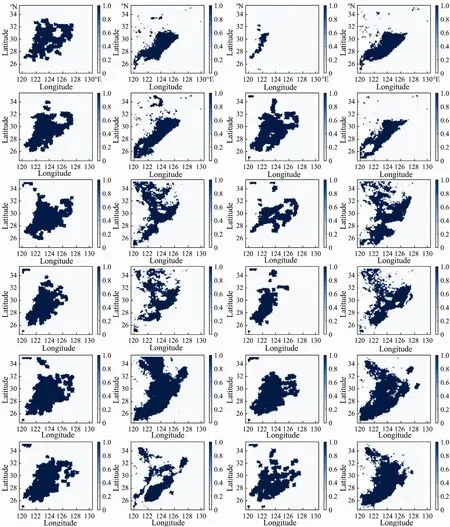
Fig.5 Comparison of actual operation areas and forecast areas on day 7, 15, 24, and 30 of each month from September to November 2017. I and III are the actual operation areas of the fishing boats, and II and IV are the model forecast areas.
In this study, a ‘fishery resource management system’is designed based on the constructed model for use by fishery managers. This system integrates machine learning algorithms with practical applications and provides functions such as file editing, fishing ground distribution forecasting, and fishing boat alerting. The interface design is simple, and the main functions are highlighted to ensure a user-friendly system. This system allows users to select the corresponding chlorophyll file as an import to the system, which then converts the original chlorophyll file to an input file that can be employed by the model.The chlorophyll input file is run by the model to obtain the forecasted daily distribution of fishing grounds. The system also provides a fishing boat alarm function. When the fishing boat is located far from the forecasted sea area,the system will send an alarm to remind the user and simultaneously display the position of the fishing boat that is located far from the forecasted sea area, which enables the user to quickly locate the fishing boat during search and rescue.
1) Click the ‘File’ button in the menu bar of the system.The user selects the chlorophyll file for import, and the system imports the original chlorophyll file into the system. Click ‘Convert File’ to convert the user input file to the input file required by the model. File import and conversion enables data processing, which is convenient for non-computer professionals as the original file does not have to be converted to a fixed format file required by the model in advance.
Fig.6 File import and conversion.
2) Click the ‘Forecast fishing ground’ button in the menu bar of the system. The concerted input file is run by the system to obtain the daily forecasted distribution of fishing grounds. The user can select the date to view the specific forecast results. Users can view the distribution of fishing grounds in the next few days to improve their work efficiency based on the forecasted sea area. These data provide a basis for fishery managers to manage marine resources; implement scientific, effective, and sustainable management and development of marine fishery resources; rationalize fishing to reduce the impact of overfishing; and ensure the healthy and stable development of fishery resources (Michaelet al., 2008).

Fig.7 Forecasting fishing grounds.
3) When a fishing boat is out of range of the forecasted fishing grounds, the system will issue an alarm and display the location of the fishing boat. The fishing boat alarm function can remind managers to determine whether to rescue the fishing boat when it exceeds the forecasted operation range, which enables them to go out to sea in a timely manner to help the fishermen, effectively safeguard the fishermen, and assist the management staff in strengthening the management of fishing boats.

Fig.8 Fishing boat alarm system.
5 Conclusions
The fishing data of the middle and upper layers of the East China Sea are characterized by remarkable regional differentiation. The forecasting of the general distribution of shrimp populations based on chlorophyll concentration provides a basis for fishery management personnel to rationally manage fishery resources, can rationally control the fishing ground resources and reduce the impact of overfishing. An accurate forecast of the fishing ground distribution has great significance to fishermen by reducing the time for them to find fishing fields in the sea to improve the work efficiency and obtain higher returns.The marine dataset and the track data of the fishing boats are integrated with machine learning to build a daily model, and the machine learning algorithm is used to improve the forecast accuracy. The experimental results reveal that chlorophyll is an important factor that affects the distribution of shrimp resources. with a high correlation between the two. In the past, the forecasting of fishing field distribution was based on the combination of environmental factors and the catch per thousand hooks of a fishing boat. The catch per thousand hooks requires special personnel to record, and data acquisition is not convenient. In this study, the track data of fishing boats and marine environmental factors combined to forecast the distribution of fishing fields in the East China Sea. This method is more versatile, the data requirements are lower,and no complicated calculation is necessary. The model constructed in this study uses day as the unit, and hence,is in real time. In addition, daily chlorophyll and fishing boat track data are easily obtained. Based on previous information, fish ground information in the next few days can be obtained, which has high practical value for the fishery economy. Accurate forecast of fishing grounds not only facilitates excellent management and maintenance of the fishery resources but also has an important role in the management of fishing boats. When a fishing boat loses contact, it is likely to appear in the forecasted fishing ground for fishing operations, which introduces great convenience for its rescue and management.
杂志排行

Journal of Ocean University of China的其它文章
- Evaluating the Accuracy of ERA5 Wave Reanalysis in the Water Around China
- Numerical Study of the Three Gorges Dam Influences on Chlorophyll-a in the Changjiang Estuary and the Adjacent East China Sea
- Parametric Stability Analysis of Marine Risers with Multiphase Internal Flows Considering Hydrate Phase Transitions
- Multi-Waves, Breathers, Periodic and Cross-Kink Solutions to the (2+1)-Dimensional Variable-Coefficient Caudrey-Dodd-Gibbon-Kotera-Sawada Equation
- Application of Improved Multi-Objective Ant Colony Optimization Algorithm in Ship Weather Routing
- Effect of Temperature on the Release of Transparent Exopolymer Particles (TEP) and Aggregation by Marine Diatoms(Thalassiosira weissflogii and Skeletonema marinoi)