爬虫技术在分布式能源站负荷预测中的应用
2021-03-06白红涛牛振涛董得志李镇东
白红涛 彭 苗* 牛振涛 董得志 李镇东
(1、国家电投集团湖北分公司,湖北 武汉430063 2、国家电投集团科学技术研究院有限公司,北京102209)
分布式能源系统(Distributed Energy System,DES)是我国能源发展重点战略之一[1]。它是近年兴起的利用小型分散设备建设在靠近用户端(需求侧)提供能源的新型能源利用方式[2],能够有效的缓解能源危机和环境问题[3]。由于其具有负荷微量化和碎片化的优势[4],在工业园区[5]、商业楼宇[6,7,8]、交通[9]等一些特定领域一直稳健发展[10]。同时由于互联网技术的应用领域不断拓展,一种以“互联网+智慧能源”为代表的综合智慧能源由此产生。它与分布式能源站的结合,不但能够充分满足用户多样化用能需求,实现用能互补,而且达到更高效用能的目的。要建立一种分布式能源站综合智慧能源系统,负荷预测起着至关重要的作用。
对于负荷预测的研究不计其数。研究的方法通常有:支持向量机[11]、重构最小二乘支持向量机[12]、K-Means 聚类算法和改进增量型极限学习机(II-ELM)相结合[13]、贝叶斯网络[14]等;研究的特征变量通常有:每天的最高温度,最低温度、平均温度、相对湿度和降水量、历史负荷数据、休息日与工作日、气象因素、日期类型、实时电价、经济与政策因素等。
本文结合湖北省某分布式能源站的实际情况,提出了一种以历史的负荷数据和影响负荷的温度、湿度、日期类型、季节类型等因素作为输入变量,运用BP 神经网络算法对能源站未来的电、热、冷、热水、蒸汽、光伏负荷进行智能预测的方法。
1 分布式能源系统
本文研究对象为湖北省某分布式能源站。该系统由燃气内燃机2 台、烟气热水型溴化锂2 台、电制冷4 台、燃气真空锅炉3 台、燃气蒸汽锅炉2 台、156kwp 屋顶光伏构成。
该分布式能源站以“天然气+光伏发电”分布式能源系统为核心,提供电、冷、热及生活热水。典型的工艺过程是天然气进入燃气发电机组发电,经发电机主控柜与市电并网(光伏发电直接在0.4kV 低压并网),运行时应优先使用自发电匹配负荷,若不足以市电补充;在发电过程中产生的余热(形式为烟气等)回收进入余热型溴化锂机组,成为空调供应的动力源。运行时应优先使用余热供应空调,不能满足的空调负荷采用“电制冷机+燃气锅炉”补充供应。
本分布式能源站系统运行时应根据能源价格、负荷变化等确定余热机组、调峰设备和水泵、冷却塔等主辅设备的启停及运行工况,以实现最大限度的节能和经济运行。由于能源价格是已知的,因此,准确的负荷预测对生产计划的制定起着至关重要的作用。本文提出了运用BP 神经网络方法以历史的负荷数据和影响负荷的温度、湿度、日期类型、季节类型等因素作为输入变量的预测模型,对能源站未来的电、热、冷、热水、蒸汽、光伏负荷进行智能预测。
2 数据流程设计
2.1 气象数据采集
气象因素是本算法的特征变量,同时气象尤其是天气预报数据常见于互联网,于是利用互联网爬虫技术获取气象数据成为主要手段。网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。当前,由于Python 语言能够高效的完成爬虫程序[16]。所以Python 爬虫技术变得越来越普遍。Python是一种编程语言,于1989 年底由Guido van Rossum 发明[15],1991 年公开发行第一个版本。
本文使用Python 爬虫的方式向内嵌式计算机提供命令,实现网络爬取数据的快速存储、解析与输出功能。
2.1.1 爬虫过程
本文以Anaconda3 为平台编写Python 程序。通过引用time模块,获取网络爬取数据的时间以及设定程序的运行时间;引用serial 模块,控制嵌入式计算机串口的开关以及数据的读取、输入和输出;引用requests 模块,向服务器请向服务器发送请求并从服务器返回所有资源;引用re 模块,通过正则表达式选择所需变量天气类型,温度、湿度等数据信息;引用MYSQL 模块,将数据从内嵌式计算机读入MySQL,实现数据的转存,方便数据的使用;引用json 模块,将爬取数据由字符串形式转为字典形式,便于数据的查找与读取。
该爬虫程序遵守Robots 协议,Robots 协议是国际互联网界通行的道德规范,用来告知爬虫程序哪些页面可以被抓取,哪些页面不可以被抓取[17]。
2.1.2 爬虫框架


其中,url 是所要爬取数据所在的网页链接,本文主要抓取湖北省麻城市的天气数据,则url 为湖北省麻城市天气信息所在的网页链接。Headers 是请求头,应对很多网站采取的“反爬虫”措施,所以利用Python 申请访问源码前修改请求头,使得网络爬虫程序不容易被识别。encoding="utf-8",输出中文形式,防止输出结果出现乱码。本文使用try, except 结构,具有容错性,防止URL 连接不上或者网络不通等异常情况使得程序无法正常运行,使得代码更强健。
weather=re.search ('hour3data=.*}]];varhour3week',w.text)[0][10:-14].replace("[","").replace("]","")
运用正则表达式进行源码数据的筛选,提取所需要的天气数据的信息,在此正则表达式中筛选获取的麻城天气预报网络源码从hour3data 开始到varhour3week 结束的文本格式的内容保存为天气数据。
ser.write(weather.encode("utf-8"))
将天气信息的数据写入嵌入式计算机。
ser.close();
如果上面的程序运行出现错误则关闭串口,防止程序陷入死循环。
为了数据的使用便捷,本文将网络爬虫得到的数据由嵌入式计算机导入MYSQL 中。具体的操作过程如下:
首先,利用Python 代码ser=serial.Serial('/dev/ttyAMA0',9600);ser.open ()。使用嵌入式计算机的GPIO 口连接并打开串口。
其次,在MYSQL 里创建一个数据库,并运用Python 代码连接创建好的数据库,具体代码如下:
mydb =mysql.connector.connect(host=dbhost,passwd=dbpass,
database=dbname)
mycursor=mydb.cursor()
其中dbhost="localhost",即使用主机数据库地址;dbpass 为主机数据库密码,dbname 为数据库名,通过Python 模块MYSQL中的connector.connect 方法连接到数据库,使用cursor() 方法创建一个游标对象,将查询结果进行保存,便于以后的使用。然后,运用正则表达式按需求筛选并逐条查找所需的数据。
最后,调用mycursor.execute()方法将筛选的数据按照一定的格数输入MYSQL 中。则实现了数据的获取与整理,为数据的使用做好准备。
2.2 获取历史负荷数据
根据湖北省某分布式能源站的运行情况,由DCS 采集数据点(如:系统时间、季节、各设备的输出功率、冷热媒水温度、流量等),并利用寻优引擎计算得到用户负荷数据。
由于采集的数据与各算法的输入需求有所差别,在调用模型算法之前,需对数据进行预处理,具体包括数据筛选、电热负荷计算、负荷预测数据处理。具体如下:
①数据筛选对系统采集信号出现的坏点进行过滤,消除错误数据对模型训练以及负荷预测的影响,保证计算精度。
②用户热负荷不能直接采集,需利用流量及冷热媒水温度进行二次计算。
③负荷预测算法使用的是小时级的历史数据,在数据库中需针对预测模块新建的点表,利用引擎按1 小时为周期的采集负荷的历史数据并计算均值,写入新点表。
④历史数据按照时间序列存储。
从历史库中采集预处理后负荷历史数据(时间跨度至少为100 天),结合其对应的日期类型、季节类型、气象数据用以训练预测模型。利用训练完成的预测模型,结合天气预报的数据计算未来各时间点的电、热、冷、热水、蒸汽和光伏负荷。
3 负荷预测
本文选取的负荷预测的核心方法是BP(Back Propagation)神经网络算法。本文首先对湖北省某分布式能源站的天气类型、日期类型、季节类型等进行量化处理,然后对天气类型、日期类型、最高温度、最低温度、平均温度、最高湿度、最低湿度、平均湿度和历史负荷值进行归一化处理,再运用BP 神经网络对电、热、冷、热水、蒸汽、光伏负荷进行预测。最后计算负荷预测的精度,检验预测结果的优劣。
3.1 BP 神经网络原理
BP(Back Propagation)神经网络是由输入层、输出层和隐含层构成的一种多层前馈神经网络,学习过程由信号的正向传播与误差的反向传播两个过程组成[18]。
信号的正向传播过程主要为:输入样本数据从输入层传入,由各隐含层内部的处理函数逐层处理之后,再由隐含层传向输出层。如果输出层的输出结果与预期的输出结果相差较大,则转向误差反向传播过程。误差的反向传播过程为:将输出结果的误差以一定的形式由隐含层向输入层反向传播,并将输出结果的误差分给各层单元,从而获得各层单元的误差信号,此误差信号就是修正的各单元的权值。BP 神经网络不断训练学习,由梯度下降法运用调节学习速率不断调整各单元的权值和阈值[19]。直到网络输出结果误差减小到可以接受的范围,或进行到预先规定的学习次数为止,得到最终各单元的权值矩阵。
本文采用的BP 神经网络的调节学习速率公式如下:

式中η(k)表示第k 步的学习速率,E(k)表示第k 步的误差。学习速率能够调节权值和阈值的大小。也就是首先验证训练出的结果误差是否比前一次误差小,如果训练后的误差比前一次误差小,则加大学习速率可以更快到达误差极小值点;如果训练后的误差比前一次误差大,说明经修正后误差跳过了误差极小值点,那么就需要降低学习速率。
对应的BP 神经网络的算法流程图1 所示。
3.2 应用分析
本文对湖北省某分布式能源站的电、热、冷、热水、蒸汽和光伏负荷进行预测。首先,对湖北省某市的天气类型、日期类型、季节类型等进行量化处理,然后,对天气类型、日期类型、最高温度、最低温度、平均温度、最高湿度、最低湿度、平均湿度和历史负荷值进行归一化处理,去除量纲的影响。最后,计算未来各时刻的负荷值和负荷预测的精度,评估负荷预测效果。
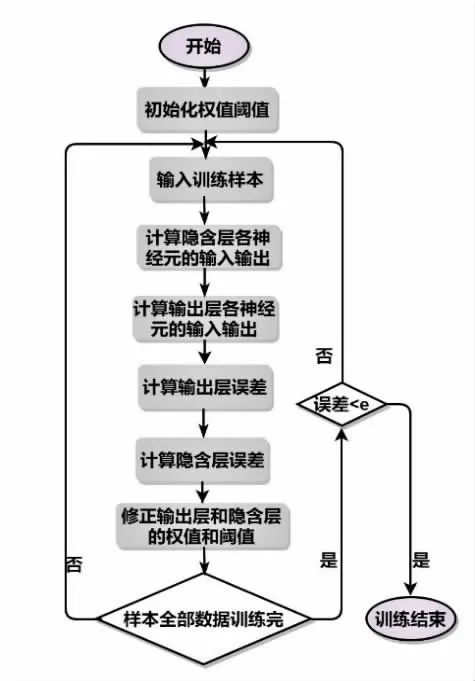
图1 BP 神经网络的算法流程图
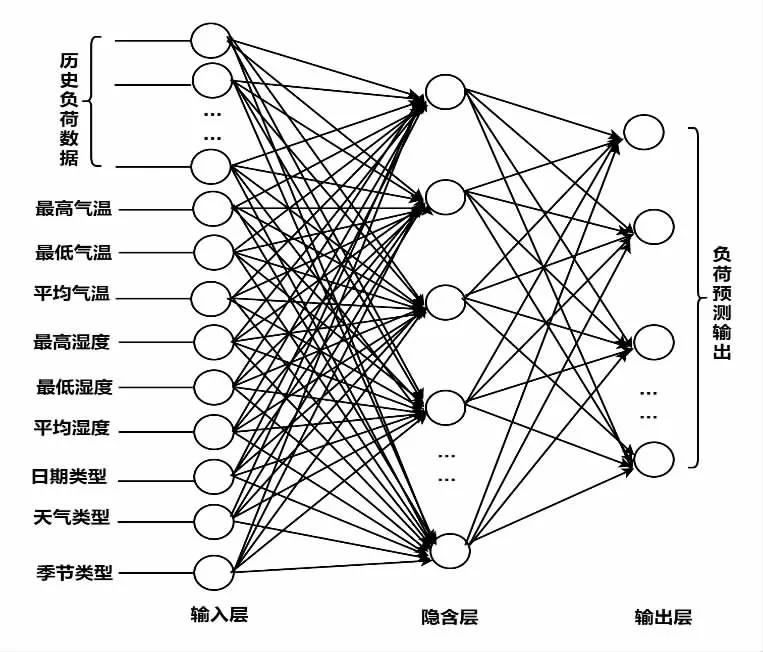
图2 BP 网络负荷预测模型
负荷预测的过程主要分为两个基本过程,负荷离线学习过程和负荷在线预测过程。负荷离线学习过程主要是运用BP 神经网络方法对归一化后的历史负荷值和影响负荷的因素:天气类型、日期类型、最高温度、最低温度、平均温度、最高湿度、最低湿度、平均湿度和历史负荷值进行训练学习,得到模型的权值矩阵;然后转到模型的滚动预测过程,将离线学习过程得到的负荷矩阵作为在线学习的BP 神经网络的初始权重,根据最近两天的负荷值和影响负荷的变量运用BP 神经网络模型提前24小时对系统电、热、冷、热水、蒸汽以及光伏发电的负荷做预测。再利用新采集的数据再对模型进行滚动学习,优化模型,提高负荷预测的精度,使得负荷预测的预测误差控制在10%以内,为能源供应量提供条件并实现负荷智能预测的目的。
本文运用的BP 神经网络进行负荷预测的拓扑图如图2 所示。
以湖北省某分布式能源站的夏季负荷为例,运用BP 神经网络进行负荷预测得到的电,热、冷、热水、蒸汽、光伏负荷的实际值和估计值的折线图结果为(图3-8):
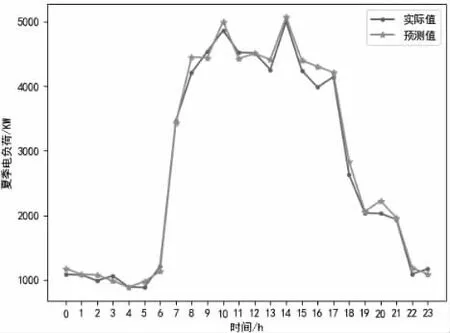
图3 夏季电负荷实际值和预测值
设负荷的实际值是yi,负荷预测的预测值为,其中i=1,2,…n。则负荷预测每个点误差的计算公式:
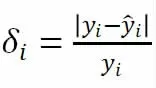
负荷预测误差的计算公式为:
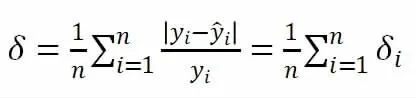
以夏季为例,计算得到:
电负荷预测误差百分值为4.57%;冷负荷预测误差百分值为1.62%;热负荷预测误差百分值为2.28%;热水负荷预测误差百分值为6.86%;蒸汽负荷预测误差百分值为5.91%;光伏负荷预测误差百分值为2.46%。
4 结论
本文通过爬虫的方式采集天气变量的数据,降低了负荷预测的成本。将网络采集的数据保存到嵌入式计算机中,使数据通过串口通讯实现由外网向内网传输,确保数据的安全性。又由于嵌入式计算机的便携可移动性,方便数据的使用;同时价格便宜,降低了存储成本。
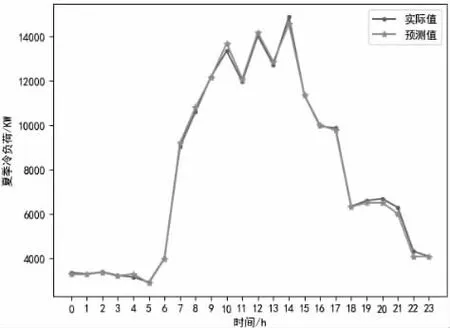
图4 夏季冷负荷实际值和预测值图
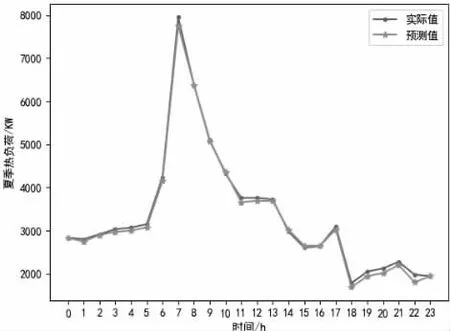
图5 夏季热负荷实际值和预测值图
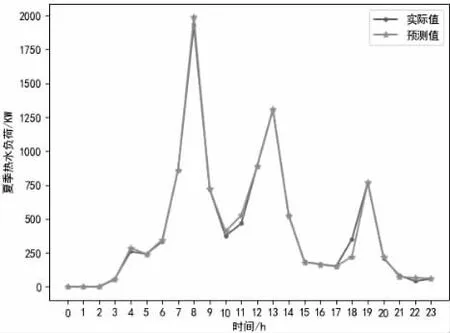
图6 夏季热水负荷实际值和预测值图
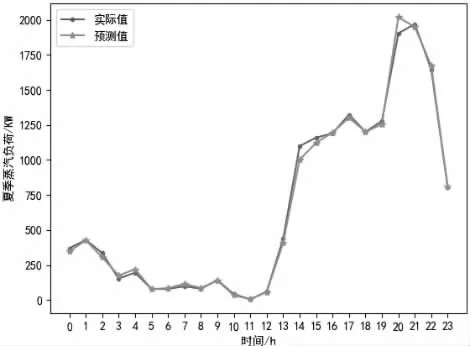
图7 夏季蒸汽负荷实际值和预测值图
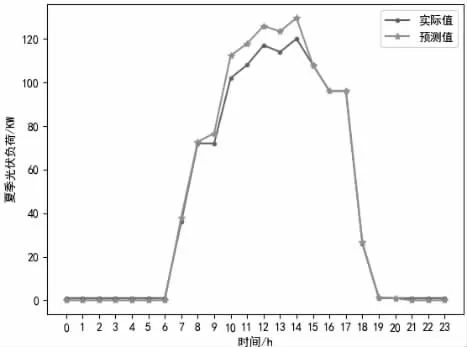
图8 夏季光伏负荷实际值和预测值图
通过运用BP 神经网络算法对湖北省某市分布式能源站的负荷进行预测,经多次实验数据分析验证,得到湖北省某市分布式能源站的电、冷、热、热水、蒸汽和光伏负荷的负荷预测误差均在10%以下。由此可知,运用BP 神经网络对负荷进行预测得到负荷预测的精度较高且模型复杂度低,对湖北省某分布式能源站的用能需求规划与系统优化调度具有重要的意义。
