基于深度学习的低剂量CT 去噪研究
2021-03-06张世杰
刘 红 张世杰
(1、四川大学视觉合成图形图像技术国防重点学科实验室,四川 成都610064 2、江苏一影医疗设备有限公司,上海200000)
CT(Computed Tomography),即电子计算机断层扫描,它是利用精确准直的X 线束、γ 射线、超声波等,与灵敏度极高的探测器一同围绕人体的某一部位作一个接一个的断面扫描,具有扫描时间快,图像清晰等特点,可用于多种疾病的检查[1]。然而,CT图像在拍摄的过程中会产生高剂量的辐射,这会对病人的身体健康产生极大的威胁,因此目前通常会通过减少拍摄剂量来降低对病人身体的伤害。但研究发现采用低剂量拍摄到的CT 图像通常都会有噪声,噪声的产生会影响到CT 图像的质量,这会严重影响到医生对病人病情的诊断。因此低剂量CT 去噪就成为了目前重要的研究方向,而降低了拍摄剂量会导致CT 图像带有明显的噪声和伪影。目前,领域内的研究者们针对出现的这些问题也提出了一些方法,主要包括投影域处理方法、迭代重建方法和后处理方法。
投影域处理方法,对探测器接收到的投影数据进行去噪处理,然后通过滤波反投影进行CT 图像的重建。这种方法效率高,适合临床应用,但是同时又对设备的依赖性高。
迭代重建方法根据投影图像的统计特性,利用函数关联投影图像和重建图像,通过在目标函数中融入先验信息,采用迭代的方式进行图像重建。迭代法图像重建算法通过对此迭代计算获得人体每个部位CT 值,获得的图像质量较好。
后处理算法直接对设备拍摄得到低剂量CT 图像进行操作,去噪后可以得到标准剂量CT 图像,所以它的目的主要是去除图像中的伪影与噪声。虽然通过处理后,CT 图像的质量能够得到良好的改善,但是在图像中仍然存在着过渡平滑和误差的问题。由于CT 图像的噪声都是分布不均与的,所以这些问题还需要很好的解决。
近年来,深度学习在图像处理领域取得了显著成就,如人脸识别,图像去噪等,这给低剂量CT 图像去噪提供了很好的解题新思路。目前已有多种深度学习低剂量CT 去噪方法,如Hu Chen 等提出的RED-CNN[2]是一种基于残差连接的编解码网络,对临床数据和公开集数据均取得较好效果,Qingsong Yang 等提出WGAN-VGG[3],利用生成对抗网络(GAN[4])WGAN[5]理念及VGG[6]作为感知损失进一步提升低剂量CT 去噪效果。这些性能优异的深度学习方法均需要利用对齐的低剂量CT 数据和标准剂量CT 数据进行训练(成对的低剂量CT 数据和标准剂量CT数据必须具有除噪声外完全相同的结构,如图1),对于头部等刚性部位对齐数据相对容易获取,而对于胸腹部,由于呼吸心跳的影响很难得到对齐的数据。
1 相关工作
目前几种深度学习低剂量CT 去噪方法的提出证明了深度学习方法对低剂量CT 去噪的有效性,目前的方法大多只能采用对齐数据进行训练,这大大限制了深度学习方法的应用范围,CycleGAN[7]是一种风格转换网络,采用了两组生成器和判别器,可以利用非对齐数据进行训练。由于CT 数据是一种医学高精度数据,原始的CycleGAN 无法完成低剂量CT 去噪。
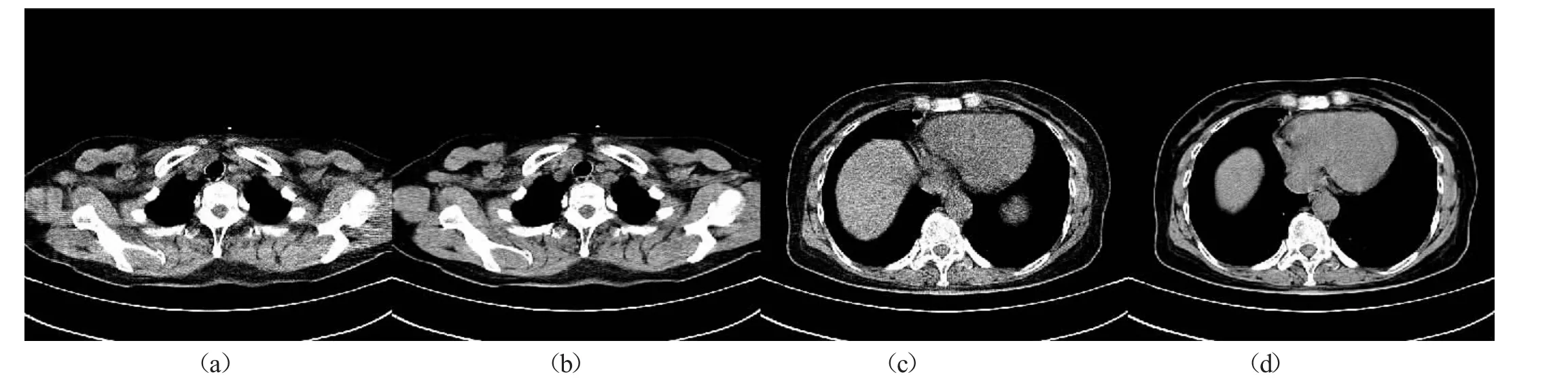
图1 (a) (b)为对齐数据和(c)(d)非对齐数据
本文提出了一种基于CycleGAN 深度学习生成对抗网络的低剂量CT 去噪网络,采用CycleGAN[7]架构,通过设计选用更加高效的生成器、判别器、损失函数获得新的深度学习卷积神经网络,实现了采用非对齐的低剂量CT 数据和标准剂量CT 数据进行训练的目标。
2 方法介绍
本研究通过收集临床数据,设计深度学习卷积神经网络并提出新的损失函数,再利用收集到数据验证提出方法的有效性。
2.1 数据收集及处理
实验采用胸腹部数据对方案验证研究,胸腹部数据包括11个人胸腹部不同部位数据。其中低剂量CT 数据数量为658,标准剂量CT 数据数量为657,所有数据分辨率均为512×512,其它参数如Thickness 均为5,低剂量CT 数据的Kvp 为50,标准剂量CT 数据的Kvp 为240 等。训练随机选取其中10 人作为训练集,剩余1 人作为测试集。
医学图像采用高精度的dcm 格式进行保存,具有16 位65536 阶灰度。为了保证图像精度并适应深度学习卷积神经网络的数据需求,将数据归一化并转为16 位mat 格式。
由于CT 图像集数量较小,通过对原始图像从左到右,自上而下滑动切割出尺寸为64*64 图像作为训练集,为保证切割出图像为有效人体部位而非黑色背景,切割时距离上下边界均为64 像素的中间部位,滑动间隔为32 像素。滑动切割后得到99495 对低剂量CT 数据和标准剂量CT 数据并输入网络训练。
2.2 深度学习网络
2.2.1 生成器
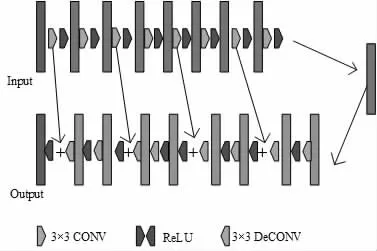
图2 生成器结构图
生成器用于将低剂量CT 数据去噪重建生成标准剂量数据,生成器的性能直接决定了生成图像的质量。研究选用生成器采用8 层3*3*64,步长为1,padding 为VALID 卷积层和8 层3*3*64,步长为1,padding 为VALID 的反卷积层构成,从每两层卷积层与其对应反卷积层进行残差连接。如图2 所示。
2.2.2 判别器
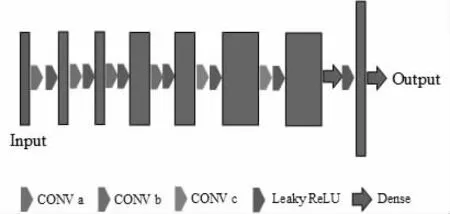
图3 判别器结构图
判别器用于判断生成器生成的数据质量好坏,并对生成器进行反馈,生成器根据反馈实时调节生成方向。判别器与生成器相辅相成,如果判别器性能过于强大,对生成器生成的数据每次都评价很低,生成器可能会将正确的方向误认为错误,无法正确生成数据;如果判别器性能太弱,对生成器生成的不好数据反馈也会很好,同样不利于生成器生成图像,选用适用于生成器的判别器可以提高网络的新年,研究采用判别器网络包括6 层卷积层和2 层全连接层。所有卷积层卷积核尺寸均为3×3,利用leakyReLU 函数进行激活,卷积层前两层CONV a 卷积核数为64,中间两层CONV b 卷积核数为128,最后两层CONV c 卷积核数为256。两个全连接层输出分别位1024 和1,网络结构如图3 所示。
2.2.3 感知损失
感知损失由VGG 网络改进而来,由13 层卷积层以及紧随其后的激活层和4 层最大值池化层构成。所有卷积层和池化层padding 均为SAME。前两层卷积层尺寸为3*3*64,然后采用relu 激活函数激活后通过一个步长为2,尺寸为2*2*64 的最大池化层进行池化。第三、四层卷积层尺寸为3*3*128,然后采用relu 激活函数激活后通过一个步长为2,尺寸为2*2*128 的最大池化层进行池化。第五、六、七层卷积层尺寸为3*3*256,然后采用relu 激活函数激活后通过一个步长为2,尺寸为2*2*256 的最大池化层进行池化。第八、九、十层卷积层尺寸为3*3*512,然后采用relu 激活函数激活后通过一个步长为2,尺寸为2*2*256的最大池化层进行池化。最后三层卷积层尺寸同样为3*3*512,然后采用relu 激活函数激活。所有卷积层步长均为1。
2.2.4 损失函数
整个网络由两个生成器和两个判别器构成,两个生成器分别由G 和F 表示,G 代表将低剂量CT 数据生成标准剂量CT 数据的生成器,F 代表将标准剂量CT 数据生成低剂量CT 数据的生成器。两个判别器分别由DX和DY表示,判别器DX用来判断数据是否为低剂量CT 数据,DY用于判断数据是否为标准剂量CT 数据,网络的整体损失函数如下:
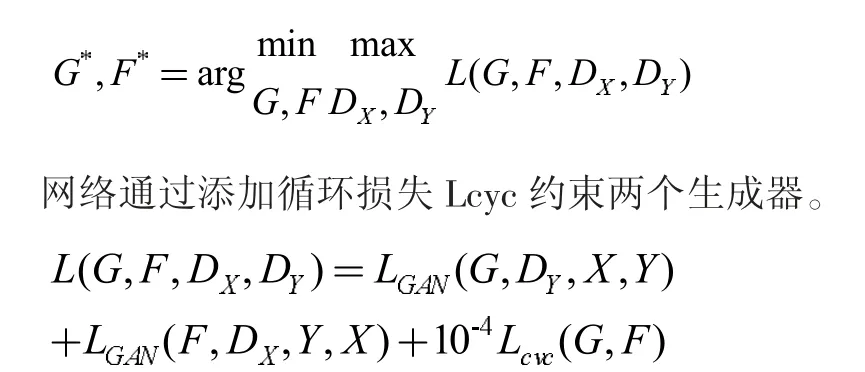
循环损失如下,将通过两个生成器后的数据与原数据进行比较来检测两个生成器性能,网络添加感知损失进一步加强循环损失。
3 结果
3.1 训练环境
训练主要硬件如下:
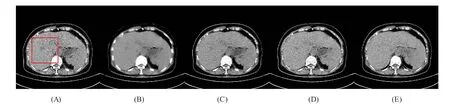
图4 测试集效果(A)低剂量CT 数据(LDCT)(B)RED-CNN (C)WGAN-VGG (D)提出的网络 (E)标准剂量CT 数据(NDCT)

图5 测试集效果局部效果(a)LDCT (b)RED-CNN (c)WGAN-VGG (d)提出的网络 (e)NDCT

3.2 效果
由于数据为非对齐数据,无法采用SSIM或PSNR 等传统评测指标对数据结果进行评估。研究结果由两名相关医师进行评估并获得良好反馈。下面通过几个不同部分展示深度学习卷积神经网络的效果,并与RED-CNN 和WGAN-VGG 进行对比,展现算法采用非对齐数据进行训练时的优势。
图5 数据为图4 数据中红色矩形截取到数据,从图中可以看出RED-CNN 生成数据较模糊无法达到理想的去噪效果;WGAN-VGG 仍有明显噪声,同样无法完成去噪任务;提出的网络生成的图像噪声明显降低,并且与标准剂量CT 数据图像质量非常接近,达到了采用非对齐数据训练进行低剂量CT 去噪的目的。
4 讨论
CT 作为现代医学诊断的有效手段,获得了非常广泛且成熟的应用。由于CT 拍摄时产生的辐射对人体的伤害也是不可忽视的,并且降低拍摄剂量又带来图像质量下降的问题,所以如何提高低剂量拍摄的CT 图像质量成为热门研究。
随着深度学习的发展及其在图像方面表现出的优异性能,研究人员采用深度学习卷积神经网络的方法对低剂量CT 去噪进行了一系列研究。其中RED-CNN 和WGAN-VGG 的提出,获得了良好的低剂量CT 去噪效果,证明了卷积神经网络进行低剂量CT 去噪的有效性。但是目前网络仍有问题需要解决,必须采用大量对齐数据进行训练,现实状况下这种数据较难获得。本文提出一种可以利用非对齐数据进行训练的低剂量CT 去噪网络, 通过对收集到的临床11 个人的数据进行训练和测试,证明了提出的网络的有效性。
由于提出的网络结构较为复杂,训练速度较慢,接下来将通过优化网络提高训练速度及对低剂量CT 图像的去噪效果。
