基于自注意力机制与知识图谱的序列推荐算法*
2021-03-05刘纵横汪海涛
刘纵横,汪海涛,姜 瑛,陈 星
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引 言
推荐系统研究工作主要可以归纳为两个主要的研究内容。一种为一般推荐方法,这些工作侧重于挖掘用户和项目之间的静态相关性,这些工作通常由传统协同过滤以及变体[1]来表示,其大多数从静态视图中挖掘用户—项目的特定关系,而忽略了随时间形成的用户交互序列隐含着用户兴趣的衰减以及偏好的动态变化。另一种内容是基于序列模式挖掘为用户推荐下一个感兴趣项目,诸如递归神经网络(RNN)[2]和卷积神经网络(CNN)[3]的神经网络模型是解决序列推荐的流行选择。但是,当这两种模型应用到推荐时,都存在些许缺点。受限于用户记录的长度的限制,它们无法在整个用户的历史交互记录中学习项目—项目之间内在联系,难以保存用户完整的上下文信息,进而导致推荐的准确度不高。受近期注意力机制在自然语言处理[4]研究与发展的影响,将自注意力机制应用到序列推荐可以完整的保留用户的上下文信息。
在上述序列推荐算法中,项目相似性的计算往往占有重要的地位。现有的序列推荐算法往往只关注项目之间的顺序相关性,而忽略了项目属性、内容之间的联系。知识图谱[5]的引入能将项目之间隐含的联系更好地嵌入到项目向量中。知识图谱是一种结构化的知识图,图中的节点表示现实世界中的实物,其中蕴含着丰富的结构化知识。其中基于DeepWalk[6]图嵌入的方法在推荐系统研究中扮演着重要的角色,在提高推荐系统的准确性和可解释性上提供有效的支持。
基于上述原因,本文提出一种新的解决方案,称为基于自注意力机制与知识图谱的序列推荐算法,命名为Att-KG。将知识图谱应用到解决项目相似性不准确问题,将自注意力机制用于解决学习序列上下文信息等问题,两者的结合有效地提高了个性化推荐的准确性和可解释性。
1 本文算法
算法的整体流程图如图1所示。

图1 算法整体流程图
1.1 项目嵌入
本文提出一种结合知识图谱结构信息的改进Item2vec[7]来捕获项目的相似性。同时将项目的协作信息与项目属性信息结合起来生成项目向量,所得向量能很好的揭示项目之间的相似性。
1.1.1 知识图谱抽取序列
首先构建知识图谱,然后使用Node2vec[8]算法思想构建随机游走序列,以电影特征为例,其中的实体包括影片、导演、演员类型等,基于电影信息构建如下的知识图谱,如图2所示。
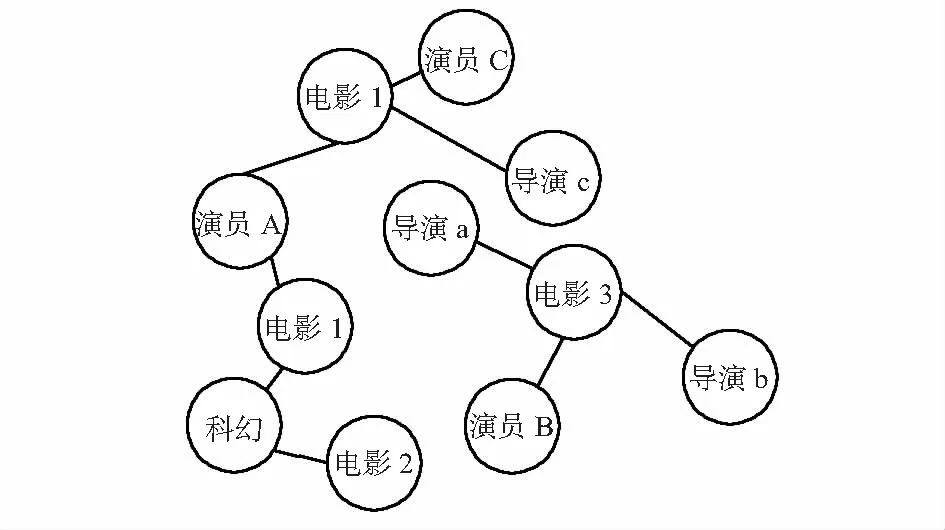
图2 电影知识图谱
本文使用Node2vec的深度游走策略获取得项目序列作为下一步Item2vec的输入,更好捕获项目之间的相似性。通过知识图谱的序列抽取得到序列集合Hk={s1,s2,…,sn},其中Sk={x1,x2,…,xn}。
1.1.2 项目向量生成
将知识图谱抽取的序列集合与现有的用户交互序列集合合并,作为Item2vec的输入,最终得到项目的嵌入向量。具体来说,给定来自用户交互序列集合H={S1,S2,…,Sn}以及知识图谱得到的序列集合Hk={s1,s2,…,sn},Item2vec技术的Skip-gram模型旨在最小化以下目标
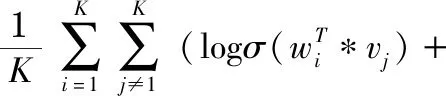
(1)
式中K为序列Su的长度,p(xj|xi)为SoftMax函数,wi和vi对应于xi的目标和上下文表示的潜在向量,σ(x)为Sigmod函数,E为每个正样本绘制的负样本数量,方便优化模型。最后,通过传统的梯度下降训练Item2vec,对于每个用户u,可以生成具有嵌入项的交互序列Pu={v1,v2,…,vT},vj为项目xj的d维潜在向量。
1.2 偏好学习
在获得高质量的项目嵌入后,使用自注意力机制来学习用户的交互序列,捕获用户的个性化偏好,注意力模块输入包括Query,Key和Value三个部分。自注意力机制的输出是值的加权和,算法实现中的相似性矩阵由Query和Key决定。在本文的推荐算法上下文中,Query,Key和Value都是相同的数据矩阵,并由用户的历史交互记录组成,用户的历史交互记录表示为如下的矩阵
(2)
式中Xu为用户u的历史交互记录形成的矩阵,矩阵每一行表示项目嵌入得到的d维项目。矩阵的行数L表示用户的历史交互记录长度,本文中用户u的Query,Key和Value在时间步t处等于Xu。
首先,基于Transformer[4]模型,本文的推荐算法通过位置嵌入以保留用户的序列信息。具体的实现步骤,使用由两个正弦信号组成的两个时间嵌入函数,为用户交互序列提供时间信息,定义如下
TE(t,2i)=sin(t/100002i/d)
TE(t,2i+1)=cos(t/100002i/d)
(3)
式中t为用户交互的时间戳,即是时间步长,i为项目的维度,将时间嵌入信息添加到Query和Key中用户保留用户的序列交互信息。
然后,本文通过使用共享参数的非线性变换将Key和Query映射到同一空间
Q′=ReLU(XuWQ),K′=ReLU(XuWK)
(4)
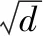
其次,本文保持Value等于Xu不变,与其他情况不同,其中的Value通常用线性变换映射所得,在后续的实验中发现在算法中不使用线性映射是有益的。最后,将相似性矩阵与Value相乘形成注意力模块的最终加权输出
au=SuXu
(5)
式中au∈RL×L为一个的矩阵,本文采用平均嵌入的方法来表示用户的单个注意力以及用户偏好,也考虑选用其他的聚合操作(例如,Sum,Max和Min),将在后续实验中评估其有效性。其中mu表示的是学习后的用户上下文信息,表示用户的偏好向量,即预测用户的下一项向量vt=mu。
1.3 模型的学习
将连续项目嵌入作为网络的输入,自注意力网络能学习用户的个性化偏好向量,可以生成下一个项目表示vt的预测,这是一个d维向量。在全局学习阶段,本文使用均方误差(MSE)损失函数从整个连续交互H集合中学习自注意力网络,可以定义为
(6)
式中ζ为MSE[9]函数,vt为目标用户u在下次访问时访问的项目表示,|Su|为相互作用序列Su∈H,|H|为序列的数量。本文使用Adagrad优化损失函数[10]。
2 实 验
2.1 基线方法
POP,项目被交互次数多就被推荐给用户,是在Top-N推荐中常见的基线方法。Item-based k-NN,经典的协同过滤算法,为用户推荐与交互历史项目相似的前k个项目。Matrix Factorization (MF):是一种广泛使用的矩阵分解方法,通过随机梯度下降优化成对排序目标函数。FPMC[11],方法将矩阵分解机与马尔可夫链结合起来用于下一项推荐,所提出的方法捕获用户偏好和用户顺序行为。
TransRec[12]模型应用了将嵌入转换为顺序推荐的思想,将用户视为关系向量,并假设下一个项目由用户最近的交互项目加上用户关系向量确定。GRU[1]使用了标准的GRU将用户交互的项目和其对应的动作一起嵌入学习用户的交互模式,最后输出用户下一个可能的交互项目。Caser[13],模拟用户过去与分层和垂直卷积神经网络的历史交互,建模用户的偏好。
在所有的基线方法中,Casert和GRU分别是基于CNN和RNN的神经网络的方法,TransRec是基于项目嵌入的方法,其他方法为经典方法和序列推荐方法。
2.2 数据集与环境介绍
本文采用真实世界中的数据集进行实验。
MovieLens数据集是来自真实世界中的用户评分电影数据集,包含用户对电影的评分,本文使用MovieLens数据集的三个版本做实验数据集,即MovieLens—100K,MovieLens—1M,MovieLens—10M。
MovieTweetings为从Twitter上收集的电影评分数据集,为推荐系统中较新的数据集,且为实时更新的数据集,本文使用的子集于2018年12月下载。
为了实验结果的可靠性,对数据集做如下预处理。首先过滤掉与用户交互次数小于5 的项目。采用数据集随机划分,90 %作为训练集,10 %作为测试集。数据集中,本文将评分信息变为隐式反馈信息,重点讨论隐式反馈做推荐。
2.3 评估指标
使用命中率HR和平均倒数排名MRR两个评估指标评估个性化的下一项推荐质量,使用前50来计算命中率,定义如下所示
(7)
式中U为用户的集合,M=|U|为用户集的数量,Ru为用户u实际交互的项目在下一项相似项目中的排名。Ru≤50则为1,否则为0。平均倒数排名表示模型对项目的排名,直观地,在实践中更优选择排名更高。本文两个评价标准中,HR@50起主导作用。
2.4 实验结果与分析
表1为7个基线方法在4个数据集上的实现结果,观察到Att-KG在所有数据集上始终获得最佳的性能,这确定了本文所提出方法的有效性,在主要评价指标HR中最高能提升7.74 %,平均提高5.62 %。本文所提出的方法不仅在MovieLens-100K和MovieLens-1M这样的密集数据上表现良好,而且在MovieLens-10M和MovieTweeing等稀疏数据上也表现良好。主要归功于知识图谱和自注意机制的有效设计。
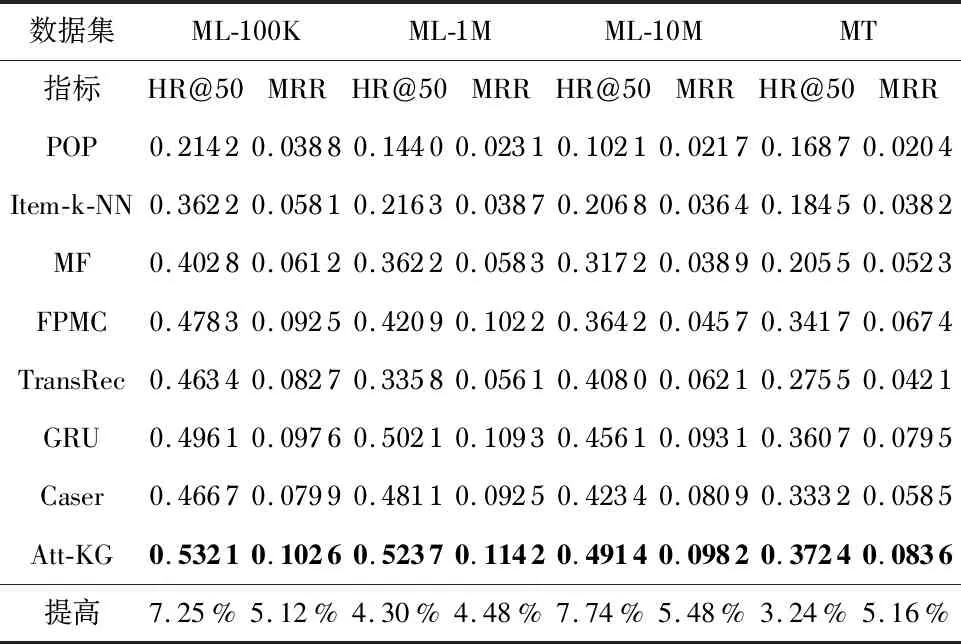
表1 Att-KG与基线方法的性能比较
本文对影响实验结果的因素做进一步分析,验证所提出算法的有效性,实验结果如表2所示。

表2 不同影响因素Att-KG的HR@50
其中NoAtt-KG表示无自注意机制推荐,Att表示无知识图谱的推荐,Sum,Max,Min表示自注意机制不同的聚合策略,实验结果分析如下:
1)自注意力机制的加入确实提高了推荐的性能,无注意力机制的加入,推荐系统仅利用用户的历史项目的平均向量做推荐。系统无法建模历史项目之间的内在联系,无法挖掘用户的历史交互记录中隐藏的序列信息。证明了添加注意力机制的序列推荐算法的有效性。
2)添加知识图谱的嵌入能给推荐系统带来积极的影响,添加知识图谱的项目嵌入,能将项目之间的协作信息以及知识图谱获取的属性信息嵌入到项目向量中,在计算项目相似性时更准确,获得更好的推荐性能。
3)使用均值的聚合策略表现出最优的性能,其他三种聚合方法表现不甚理想,使用均值的聚合策略可以保留更多的信息,对预测用户的偏好更加有利。
3 结 论
提出了一种新颖的序列推荐算法,用于下一项推荐。算法结合了自注意力机制与知识图谱,在项目嵌入方面结合知识图谱获得高质量的项目向量。在序列推荐建模方法,改进了RNN和CNN难以保存长序列上下文信息等问题。将自注意力机制用于序列推荐建模,不仅能很好的建模用户的上下文信息,也能提高系统运行的速度,对顺序推荐建模有良好的效果。
