多种群NSGA-Ⅱ改进算法的大规模柔性作业车间调度问题*
2021-03-05陈自豪陈松航
陈自豪,陈松航,陈 豪
(1.福建省复杂动态系统智能辨识与控制实验室 泉州装备制造研究所,福建 泉州 362200;2.中北大学 电气与控制工程学院,山西 太原 030051)
0 引 言
柔性作业车间调度问题(flexible job-shop scheduling problem,FJSP)可以被描述为每个工件的每道工序只能在一台机器上加工,并且只能加工一次,每道工序可以对机器进行选择,且加工时间确定。FJSP本质上是一种对资源进行优化配置的策略,是一类NP-hard问题。
遗传算法(genetic algorithm,GA)由于其简单通用、鲁棒性强、适于并行处理问题等特点被广泛应用于求解FJSP。张国辉等人[1]改进了种群初始化的方法,应用全局搜索、局部搜索与随机搜索相结合的策略,提升了算法的收敛速度。Pezzella F[2]在遗传算法框架中整合多种选择和和交叉策略,改进种群初始化方法验证了遗传算法求解FJSP的有效性。陈辅斌等人[3]通过引入免疫平衡原理改进了NSGA-Ⅱ算法的选择策略与精英保留策略解决了算法收敛性能不足的缺陷。Wan M[4]在遗传算法中整合多种选择策略并使用并行机制处理基因序列对个体进行编码改善了算法性能。FJSP中传统基准实例规模一般都不超过20×50,基准实例已不能满足对实际生产过程的算法模拟。
本文针对FJSP基准实例的特点与规则编写脚本生成大规模测试集来模拟大规模FJSP问题,提出了一种多种群NSGA-Ⅱ改进算法来求解,并通过大规模基准实例验证了该算法的可行性和有效性。
1 问题描述与建模
1.1 问题描述
本文研究的是FJSP中代表性的偏柔性作业车间调度问题(partial flexible job-shop scheduling problem,PFJSP),部分工序可以选择工厂中的任意一台机器进行加工,剩余部分的工序就只能选择在一些特定机器上进行加工[5]。
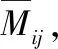
1.2 大规模数据集描述
FJSP问题的一个传统基准实例的片段如下
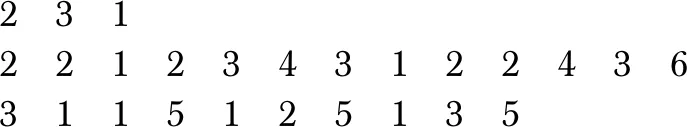
……
每组数据的第一行首数字代表工件数,第二个数字代表机器数,第三个数字表示每一道工序平均可供选择加工的机器数。第一行即表示:2个工件,3台机器,每道工序平均有1台机器可以选择。
第二行开始每行表示一个工件。第二行即表示:第一个数字2代表加工第一个工件有两道工序,第二个2代表加工工序1有两台机器可供选择,接下来(1 2),(3 4)分别表示工序1在机器1上加工用时为2,在第3台机器上加工用时为4,以此类推[6],直至结束。
根据上述数据特点,采用Python语法和关键词对大规模数据生成脚本进行描述如下。
设置初始变量:m个工件,n台机器,numOjob每个工件的工序数 for i in range(m):
for j in range(NumOfJob):
for k in range(random.randint(1,n)):
数据对=(机器号,对应加工用时)
return数据对=random.randint(1,n)+数据对
return每个工件的加工数据=工序数+数据对
return所有工件的加工数据(没有第一行)
1.3 模型构建
在求解FJSP的过程中,需要一些常用的指标。根据工厂的实际需求,使用了3个贴近生产成本的指标来构建模型。
最大完工时间最小:每个工件从开始加工时刻到最后一道工序完成时刻的耗时便是完工时间 ,所有工件中加工耗时中最大的那个时间就是最大完工时间[7]。最大完工时间体现车间生产效率,是FJSP最根本的评价指标,也是FJSP研究中应用最广泛的评价指标之一。即
(1)
机器最大负荷最小:在求解FJSP时,因机器选择问题会造成机器负荷不平衡,从而无法提高机器利用率而产生效率瓶颈。为克服由于调度方案不同而引发的机器负荷不平衡问题,也为提高每台机器的利用率,采用机器最大负荷为评价指标,如下
(2)
总机器负荷最小:在求解FJSP时,不同机器加工同一道工序耗时有差异,这会使总的机器负荷会随着调度方案的变化而波动。依据工厂实际需求,保证其他指标不降低的情况下,减少所有机器的总消耗降低成本。即
(3)
根据实际车间生产中目标值f1、f2、f3对生产效率产生影响的大小,设定三个目标值f1、f2、f3的权重值ω1,ω2,ω3分别为0.5,0.3,0.2来构造评价函数F如式(4)所示,使用评价函数F来评价算法在求解FJSP问题中所得到最优解的优劣
F=ω1f1+ω2f2+ω3f3
(4)
2 多种群NSGA-Ⅱ改进算法
2.1 基于工序和机器的分段编码策略
求解FJSP这类离散问题时,优秀的编码是算法求得最优解的前提与保证。FJSP编码即要有加工工序的先后顺序编码,也要包含每道工序可供选择加工机器编码,因此选择融合工序和机器的分段编码方式[8]。
基于工序和机器的分段编码由工序编码段与机器编码段两部分组成:工序编码段决定每道工序的加工顺序,机器编码段决定工件的某道工序由哪台机器来加工。如图1所示染色体编码表示有3个工件共8道工序。
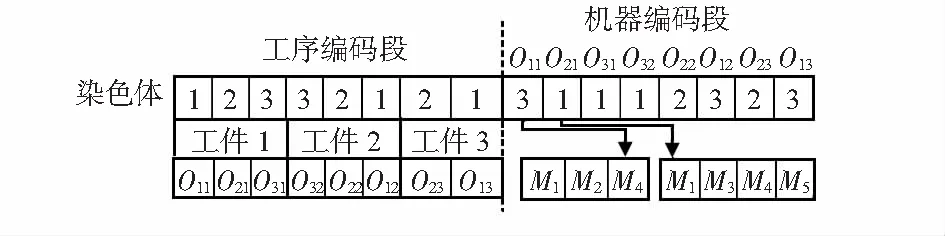
图1 染色体编码
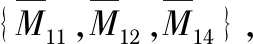
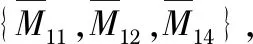
2.2 随机式选择与启发式选择初始化
针对FJSP的特点,采用随机式选择与启发式选择相结合的方法,既加快了运行时间又避免了算法因为过早的收敛从而陷入局部最优。随机式选择:加工工序的机器在可选机器集中随机选择一台。启发式选择:工序的加工机器在可选机器集中选择加工时间最短的那台机器。
通过实验对比,在随机式选择、启发式选择的多种比例中选择了效果较好的1∶1比例,即种群中50 %的个体随机式选择,50 %的个体启发式选择。
2.3 基于工序与机器的分段交叉与对应变异
工序部分的交叉:基于工件优先顺序的交叉(precedence preserving order-based crossover,POX)得到的子代总是可行的,可以比其他的交叉方式获得更好的结果[9]。POX交叉如图2,具体执行步骤如下:1)将工件集J={J1,J2,…,Jn}随机分成两个非空子集Jobset1和Jobset2,如Jobset1={2,3}和Jobset2={1,4};2)将父代1属于Jobset1的所有基因位置对应的复制到子代1中,将父代2中属于Jobset2的基因去掉,然后将剩余的基因依次放入子代中。
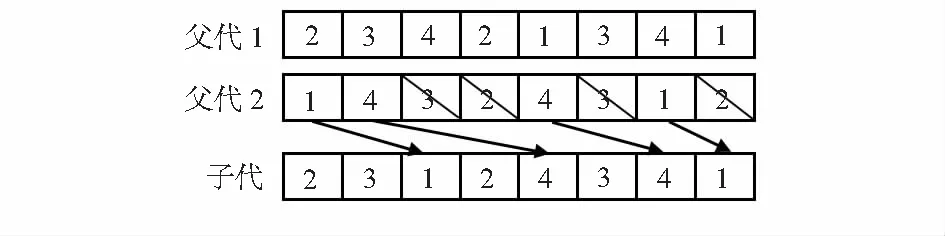
图2 POX交叉
A 种群机器部分交叉:为了保持机器部分的基因顺序不变,采用均匀交叉如图3。具体步骤如下:1)工序长度I的区间(1,I)内随机产生一个整数r,并在区间(1,I)中随机采样r个互不相等的数;2)按照步骤(2)产生的整数,将父代1和父代2中对应整数位置的基因复制到子代1和子代2中;3)将父代1和父代2剩余的基因依次复制到子代2和子代1中,并保持位置与顺序。
B种群机器部分交叉:同步概率比较的交叉方式如图3。
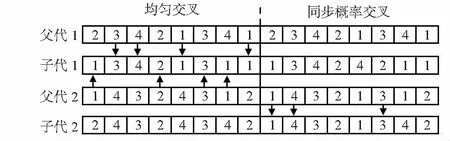
图3 机器部分交叉
1)随机产生工序长度个[0,1]之间的随机数;2)记录子代1、2中随机数小于交叉概率的工序号;3)如果子代2中的工序号与子代1中交叉概率的工序号相同,就记录下该子代2的顺序位置,将该位置替换为父代2上相同位置的基因。
图4所示为两条父代染色体进行工序机器对应变异。1)在工序长度的区间内随机产生两个整数1,3;2)子代1复制父代2工序部分位置1和位置3的基因,机器部分同理;3)子代2复制父代1工序部分位置1和位置3的基因,机器部分同理。此种方式不随机突变的原因是避免产生不属于解集中的不可行解。
图4 工序与机器的对应变异
2.4 算法基本流程
多种群NSGA-II改进算法,算法流程如图5所示。
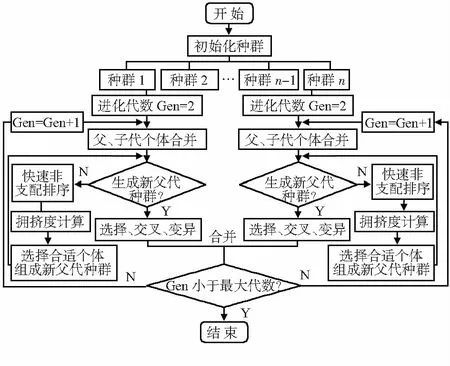
图5 改进多种群NSGA-Ⅱ的流程图
3 算法性能测试
实验数据采用生成大规模数据集脚本产生3数据集集:100×10,100×30 ,100×50其中n×m表示n个工件m台机器,为测试算法的有效性,本文将测试结果与传统的NSGA-Ⅱ(NSGA-Ⅱ)以及单种群NSGA-Ⅱ改进算法(INSGA-Ⅱ)结果进行比较。将每种算法各自运行10次结果进行归一化通过构造评价函数Vi得到 10次结果中的的最优解,设定权重值ω1,ω2,ω3仍为0.5,0.3,0.2,函数Vi如式(5)所示。式中ω1,ω2,ω3为目标值f1,f2,f3的权重,f1max,f1min,f2max,f2min,f3max,f3min为算法运行10次中指标f1,f2,f3的最大值与最小值
(5)
算法的参数为:种群规模为100;迭代次数为100;交叉概率为0.8;变异概率为0.1。
记录3种算法10次实验中的最小Vi值既最优解。表1为NSGA-Ⅱ、INSGA-Ⅱ、IMNSGA-Ⅱ在3数据集上的对比结果。比较实验结果中评价函数F值,本文提出的多种群NSGA-Ⅱ改进算法均优于两种对比算法,其中FJSP的最关键评价指标最大完工时间f1在3个数据集中均领先对比算法。对比实验表明,本文提出的算法更适用于大规模FJSP并在大规模测试集上得到验证。
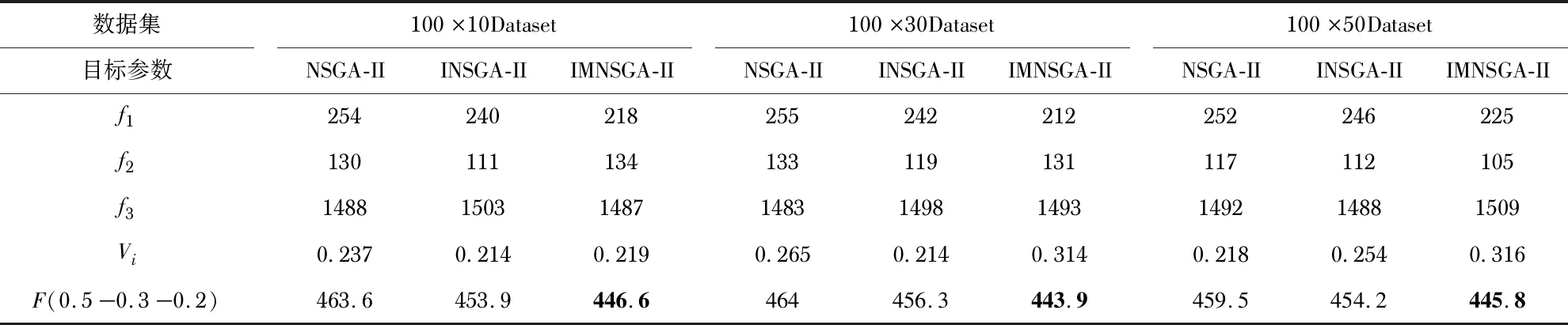
表1 不同数据集对比结果
4 结束语
依据实际车间生产对调度问题的需要,构建以最小化最大完工时间、最小化关键机器最大负荷、最小化总机器负荷为指标的调度模型,来对车间生产过程进行调度优化。提出了多种群NSGA-II改进算法,改进其编码与解码、种群初始化、交叉和变异方式,并在种群初始化过程中使用多种群策略并在不同种群中使用不同的交叉方式,尽可能提升子代的差异化程度,避免算法“早熟”收敛。最后在生成的大规模数据集上验证了所提出算法的有效性与可行性。
