融入BERT的企业年报命名实体识别方法
2021-03-02张靖宜贺光辉刘亚东
张靖宜, 贺光辉, 代 洲, 刘亚东
(1. 上海交通大学 电子信息与电气工程学院, 上海 200240; 2. 南方电网物资有限公司, 广州 510641)
命名实体识别作为自然语言处理领域中的一项重要技术,与关系抽取[1]、事件抽取[2]、问答系统等其他自然语言处理任务的基础相关.其主要负责准确、自动识别指定语料中实体(专有名词或有价值的短语)的边界并划分实体类别.对企业年报进行命名实体识别可获得企业的基本信息和财务数据,为企业评价系统提供数据支撑,有助于企业掌握行业发展现状和趋势、规划发展方向、评估合作伙伴等.因此,准确识别企业年报中的命名实体是建立企业评价系统的重要途径.
目前,命名实体识别方法包括:基于规则和字典、统计机器学习和深度学习.其中,基于规则和字典的方法需要手动建立知识库和字典,耗时长且移植性差.基于统计机器学习的方法应用较广泛,如隐马尔科夫模型(HMM)、条件随机场(CRF)、最大熵模型(ME)等,但以上方法需要人工设定特征模板,对语料库的依赖性较大且对特征选取要求较高.与基于统计机器学习的方法相比,基于深度学习的方法能自动获取语料特征,命名实体识别的性能更好.由于命名实体的标签之间的依赖关系较强,所以Huang等[3]将双向长短时记忆网络(BiLSTM)和CRF结合,所得模型能够利用过去和将来的信息更好地挖掘上下文关系.Chiu等[4-5]将BiLSTM和卷积神经网络(CNN)结合,所得模型能够更好地利用前、后缀的字符级特征,减少人工构造特征.Cho等[6]提出了门控循环单元(GRU),其比长短时记忆网络(LSTM)少一个门,结构更简单,训练速度更快.王洁等[7]将字向量作为输入,利用BiGRU-CRF模型提取会议名称的语料特征,发现与LSTM相比,GRU的训练时间减少了15%.Bharadwaj等[8]在BiLSTM-CRF模型的基础上融入注意力机制,使模型更关注于对当前输出贡献大的字符.Cao等[9]提出利用对抗迁移学习框架进行命名实体识别,通过提取不同任务中的共享词边界信息并利用自注意力机制,学习句子中任意2个字符之间的依赖关系.Vaswani等[10]提出了利用自注意力机制快速并行的一种包含编码器和解码器的转换器(Transformer)模型.Devlin等[11]提出了能够更好获取字符、词语和句子级别关系特征的基于转换器的双向编码器表示(BERT)预训练语言模型.
对企业年报进行识别的难点主要如下:① 专业财务术语、企业名称实体繁多.其中,如净利润、营业收入等财务术语的专业性较强;企业名称包括以“有限公司”“集团”等为尾的全称和仅包含企业名称关键信息的简称;② 数值信息多且数字实体的识别难度大,如“公司2011年末总资产和归属于上市公司股东的所有者权益分别为 170 704.67 万元和 156 542.08 万元”,需要正确识别出财务术语对应的数值信息及其单位;③ 财务数值相对于上年变化趋势的描述方式多变,如下降10%、同上年持平等;④ 企业年报语料库规模较小,仅为1998年人民日报语料库的19.28%.
针对以上问题,提出BERT-BiGRU-Attention-CRF融合模型.在基础模型BiGRU-CRF上引入BERT预训练语言模型,并在大型语料库上进行预训练学习语义特征,补足企业年报语料库的特征,克服语料库规模小的问题.同时,BERT利用Transformer模型提升自身模型的抽取能力,能够更好地明确实体边界.此外,在BiGRU-CRF模型中引入注意力机制,便于理解句子结构,从而充分挖掘上下文的语义信息,进一步提升实体的识别性能.
1 企业年报数据集的构建
目前,关于企业年报的命名实体识别方法的研究较少,且缺乏实验测试所需的典型数据集,因此本文利用网络爬虫技术抓取企业官方年报,自行构建和标注该领域的数据集.具体构建步骤如下:
(1) 数据预处理.利用正则表达式从每份年报中自动提取出“企业经营概况”标题下的语段.
(2) 实体类别确立.构建企业评价系统需要从企业年报中获取企业的基本信息和经营状况.其中,基本信息包括年份和企业名称共两类实体;通过阅读企业年报和利用词频-逆文档频次(TF-IDF)算法[12]提取关键词的方式,选取与“利润”和“收入”相关的财务指标概括企业的经营状况.自行标注的实体共7大类,如表1所示.

表1 企业年报实体Tab.1 Entities of enterprise annual report
(3) 标注体系.实验采用的标注体系为BIO.其中,B代表实体的起始位置,I代表实体中除起始位置的其他部分,O代表非实体部分.需要预测的实体共15小类,标注示例如表2所示.

表2 标注示例Tab.2 A example of labeling
2 BERT-BiGRU-Attention-CRF模型
本模型由BERT预训练语言模型、BiGRU网络、注意力机制和CRF层构成.首先,把输入字符的字向量、文本向量和位置向量之和作为BERT的输入.利用BERT获取上下文语义信息,把融合语义后的输出向量输入到BiGRU网络进行编码,前向GRU网络学习未来特征,反向GRU网络学习历史特征.然后,将挖掘得到的全局特征,即t时刻的隐藏状态(ht)作为输出,并利用注意力机制补足局部特征,预测出输入文本序列与标签之间的关系.最后,利用CRF进行解码预测标签之间的合理性关系,输出最佳标签序列,模型结构如图1所示.

图1 BERT-BiGRU-Attention-CRF模型结构Fig.1 Structure of BERT-BiGRU-Attention-CRF model
2.1 BERT预训练语言模型
BERT预训练语言模型将深度学习的思想融入语言模型中,可将词表征为向量形式, 从而获取词语之间的相似度[13].在双向Transformer编码器(见图2)的基础上,该模型提出了“掩码(Masked)语言模型”和“下一句预测模型”.Masked语言模型通过对语料中15%的信息进行遮盖,最大程度地使模型在每1个词上都能够学习到全局语境下的表征,从而令BERT获得的相关词向量更贴合语境.具体遮盖方法为80%的遮盖信息替换为[MASK];10%的遮盖信息替换为任意词;剩余10%的遮盖信息保持不变.同时,BERT也借鉴了Skip-thoughts中的句子预测方法[14],可以学习句子级别的语义关系:为每个预测样例选择1个句子对A和B,让模型预测A和B是否先后近邻,从而将“下一句预测”问题转化为二分类问题.其中,50%的B为A的下一个句子,标记为“IsNext”;剩余50% 的B为语料库中的1个随机句子,标记为“NotNext”.具体编码过程如下所示.

图2 Transformer编码器结构Fig.2 Structure of Transformer encoder
首先,将输入序列X=(x1,x2, …,xT) 经过词嵌入(EL)和位置编码(PE)加和后作为Transformer编码器的输入:
Xe=EL(X)+PE(X)
(1)
式中:Xe为经过词嵌入和位置编码后的输入序列.位置编码提供每个字符的位置信息, 以便Transformer理解句中字词的顺序关系.词语在句子中的位置不同可能导致语义不同,因此需要对序列中词语的位置进行编码:
(2)
(3)
式中: pos为词语在句子中的位置;dmodel为PE的维度.
为了提取多重语意含义,输入向量需要经过1个多头自注意力机制层:
(4)

(5)
式中:dk为输入向量的维度.利用注意力权重对字向量进行加权线性组合,使每个字向量都含有当前句子内所有字向量的信息.
然后,对上一步的输出做一次残差连接(X1)和层归一化:
X1=Xe+Attention(Q,K,V)
(6)
(7)

最后,将经过残差连接和层归一化处理后的信息输入到前馈神经网络中,重复进行一次残差连接和层归一化后输出.
2.2 BiGRU神经网络
GRU是LSTM的变体.相比于由3个门函数(输入门、遗忘门和输出门)构成的LSTM,GRU仅由2个门函数构成,即更新门(输入门和遗忘门的结合体,决定过去传递到未来的信息量)和重置门(决定过去信息的被遗忘量).2个门控机制能够保存长期序列中的信息,决定哪些信息能够作为门控循环单元的输出.此外,GRU具有模型精简、计算速度快、参数少等优势,在小样本数据集上的泛化效果更好.GRU的具体结构如图3所示,表达如下:
(8)

图3 GRU结构Fig.3 Structure of GRU
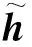
2.3 注意力机制层
BiGRU网络在获取语料局部特征上存在不足.因此,本文利用注意力机制学习句子中任意2个字符之间的依赖关系,获取句子的内部结构信息.注意力机制使命名实体识别模型更专注于挖掘与当前时刻输出相关的输入信息和局部信息.利用注意力机制对BiGRU层输出的特征向量(hj)进行权重(atj)分配,计算得到t时刻BiGRU和注意力机制层共同输出的特征向量(ct),并作为最后的输出:
(9)
式中:etj为对齐模型;v、w和m为权重向量.
2.4 CRF层
BiGRU层虽然可以学习上下文之间的特征信息,选出最大概率值的标签作为输出,但是不能获取输出标签之间的依赖关系,可能导致2个相同标签相互接连.而CRF具有转移特征,能够考虑输出标签之间的顺序性.因此,选择CRF作为BiGRU和注意力机制的输出层.
(10)
式中:pi,yi为第i个位置标签输出为yi的概率;Ayi,yi+1为从标签yi转移到yi+1的转移概率.对于每一个X′,得到所有可能的标签序列的分数,则归一化结果和损失函数分别为
(11)
ln(p(y|x′))=s(X′,y)-
(12)
最后,利用维特比(Viterbi)算法[15]得到最佳预测标签序列:
y*=argmax(s(X,y))
(13)
Viterbi算法利用动态规划算法解决CRF的预测问题,可以寻找概率最大状态路径.
3 实验与分析
3.1 数据集及标注体系
实验搜集了近5年的企业年报,涵盖 2 927 家公司,共 13 129 份.经过数据清洗和预处理后,按照6∶2∶2的比例将其划分为训练集、测试集和开发集.表3为企业年报数据集的详细结构,表4为数据集中实体类别个数分布.
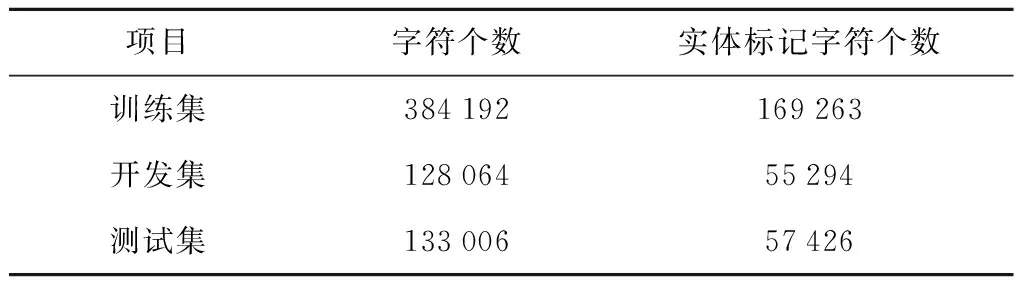
表3 企业年报数据集结构Tab.3 Dataset structure of enterprise annual report
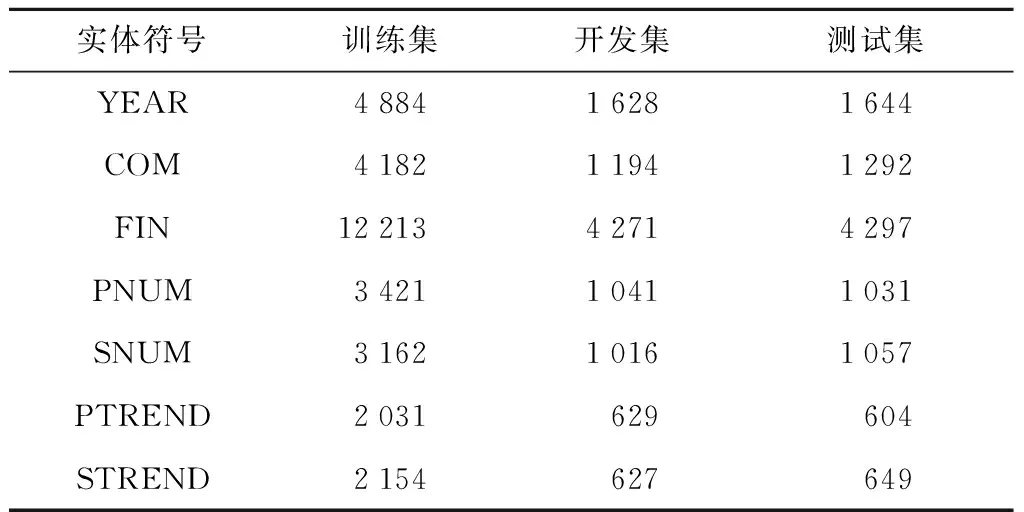
表4 实体类别个数分布Tab.4 Number distribution of entity categories
3.2 实验环境和参数设置
在Python 3.7.3和Tensorflow 1.13.1框架下进行模型的训练和测试.实验利用BERT-Base模型,其含有12个Transformer层,768维隐层和12头多头注意力机制.GRU网络的隐层设为128维.注意力机制层设置为50维,最大序列长度设置为256.优化函数采用Adam,学习率设置为5×10-5,dropout层设置为0.5.
3.3 评估标准
实验利用精确率(P)、召回率(R)和F1值共3个指标评价7大类实体的命名实体识别效果,3个评价指标的计算方法如下:
P=a/b
(14)
R=a/c
(15)
F1=2PR/(P+R)
(16)
式中:a为正确识别实体数;b为识别实体总数;c为所有实体总数.
4 实验结果与分析
BERT-BiGRU-Attention-CRF模型对不同实体的识别效果如表5所示.其中 “年份”“企业名称”“财务术语”“利润类/收入类数值”实体有较高的P、R和F1值.模型对“利润类/收入类数值同上年变化趋势”实体的识别性能相对较差,主要是由于该类实体表达形式较复杂,包括纯文字表达、文字和数字组合表达等,且描述变化趋势的文字表达形式多样.对此,可以通过深入的划分实体、融合词典特征和改进模型等方式,令实体学习更多语义特征.
为了验证BERT-BiGRU-Attention-CRF模型在企业年报命名实体识别中的优异性,在同一数据集上,分别对CRF、 BiGRU-CRF、BiGRU-Attention-CRF和BERT-BiGRU-CRF模型进行实验,对比结果如表6所示.此外,利用雷达图显示不同实体在不同模型上的F1值,如图4所示.由图4可知,BERT-BiGRU-Attention-CRF模型在7大类实体上的F1值都处于较高水平,说明该模型在企业年报领域的识别性能高于其他模型.
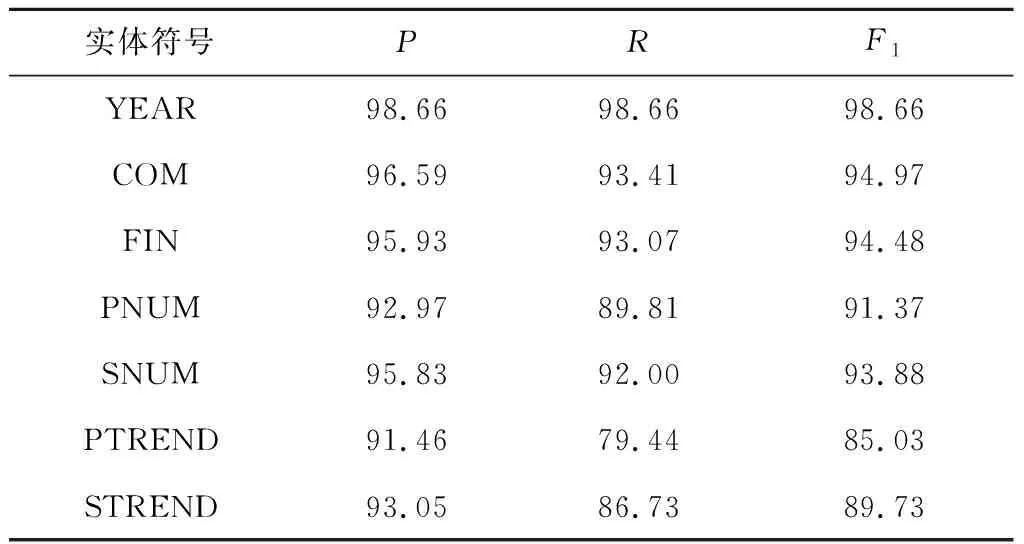
表5 不同实体识别效果Tab.5 Recognition effect of different entities %

表6 不同模型实验结果Tab.6 Experimental result of different models %

图4 不同实体在不同模型上的F1值(%)Fig.4 F1 values of different entities in different models (%)
不同模型结合不同实体的具体分析如下:
(1) CRF模型是基于统计的命名实体识别方法,由于CRF是在分词的基础上通过设置特征模板获取语料的特征,所以对“企业名称”“财务术语”“利润类/收入类数值”和“利润类/收入类数值同上年变化趋势”这4类属于未登录词的实体识别效果较差,其F1值均在68%以下.
(2) 相比于CRF模型,BiGRU-CRF模型整体的F1值提高了12.3%,且对未登录词实体的边界划分更准确.这是因为未登录词实体的构成较复杂、词长较长,CRF特征模板只能在有限的窗口范围内进行提取,而BiGRU网络可以更好地利用上下文的语义特征,如更善于区分 “净利润”和“归属于母公司的净利润”这类易混淆词语、识别出更多完整的企业名称和简称.
(3) 相比于BiGRU-CRF模型,BiGRU-Attention-CRF模型的F1值提高了2.38%.句子中不同的字词和上下文的关联程度不同,而注意力机制可以关注更多的局部特征,特别是和当前输出有关联的信息,如识别句“实现净利润13亿元”中的“利润类数值”实体,词语“净利润”与实体的关联程度大于词语“实现”,则注意力机制会更关注 “净利润”和实体之间的关系.
(4) 相比于BiGRU-CRF模型,BERT-BiGRU-CRF模型的F1值提高了6.96%;相比于BiGRU-Attention-CRF模型,BERT-BiGRU-Attention-CRF模型的F1值提高了6.18%,具体反映为“收入类数值”和“利润类数值同上年变化趋势”2类实体的F1值分别提高10.38%和25.31%.这2类实体和上下文之间的关联较强,且表达方式较灵活,如在字词级别方面,“数值”实体中单位的表示方式有元、万元、亿元等;在句子级别方面,“数值同上年变化趋势”实体有文字-数字结合(涨幅/增长/下降+百分比)和纯文字描述(创下新高、扭亏为盈)共2种表达方式.此外,融入BERT模型的企业年报命名识别方法更能够结合语义找到数值和财务术语的映射关系,尤其适用于同时包含2个数值的句字,如“营业收入和主营业务收入分别为13万元和10万元”.综上可知,BERT通过在大型语料库上学习获得更多语义特征,可以对企业年报这一小规模语料库进行特征补足;其利用双向Transformer结构进行基于上下文语境的深度双向语义理解,提高特征抽取的能力和边界不明显且表述灵活实体的识别效果.此外,BERT能够学习字符级、词级和句子级关系特征,可以更全面地理解句子语义.
5 结语
企业年报命名实体识别为企业评价系统的建设提供了基本企业信息和经营情况的数据支撑.本文提出了BERT-BiGRU-Attention-CRF模型.在基础模型BiGRU-CRF上引入BERT预训练语言模型,以获得与上下文有关联的双向特征表示,更加深刻地理解语义,克服了企业年报语料库规模小、实体专业性和映射关系强的问题.然后,采用注意力机制改进BiGRU-CRF模型,使模型可以选择性地关注重要信息,提高信息的有效关注率.自建企业年报语料库的识别结果表明:BERT-BiGRU-Attention-CRF模型能够较好地识别企业年报中的实体,可以达到95.45%的精确率和91.99%的召回率以及93.68%的F1值,能够满足应用需求.在后续研究中,将扩大语料库规模,进一步完善并规范企业年报的实体标注,提取更多有价值的实体,并在保证性能的基础上,对模型结构进行简化.
