基于RISC-V架构的强化学习容器化方法研究 *
2021-03-01徐子晨王玉皞
徐子晨,崔 傲,王玉皞,刘 韬
(南昌大学信息工程学院,江西 南昌 330031)
1 引言
随着登纳德缩放定律和摩尔定律的终结,标准微处理器性能提升的减速已成为了既定事实,体系结构在新的黄金时代需要寻求新的前进方向[1]。加州大学伯克利分校提出了RISC-V(RISC Five),即第五代RISC架构。RISC-V并非是精简指令集简单的版本迭代,和前代相比它最大的优势在于开源和模块化,允许用户基于特定需求添加定制化拓展指令集。RISC-V由于其高度的灵活性在工业界和学术界均受到广泛关注,推出了一系列支持乱序执行的微处理器,如伯克利弹性乱序处理器BROOM(Berkeley Resilient Out-of-Order Machine)等[2-4],将会应用在可穿戴设备、智能家居、机器人、自动驾驶和工业装置等领域的计算设备中[5],在边缘微设备的应用中具有广阔的前景。
机器学习的研究在近些年来的被关注度越来越高,尤其是在深度学习领域,各种深层网络模型层出不穷,在计算机视觉、语音识别和自然语言处理等领域的应用也越来越密集。构建一个深度神经网络的工作流程通常包括以下几步:(1)收集和准备训练数据;(2)选择并优化深度学习算法;(3)训练并调整模型;(4)在生产环境中部署模型。机器学习可分为监督学习、无监督学习和强化学习,近年来,深度强化学习Deep RL(Deep Reinforcement Learning)在自动驾驶、连续控制等领域的表现优异[6],但深度强化学习中的智能体训练时间长、计算力需求大,已成为限制深度强化学习进一步发展的瓶颈之一。强化学习的训练过程中带有大量的循环,适合在支持乱序执行的RISC-V处理器上进行加速。因此,在基于RISC-V指令架构的平台上构建深度强化学习模型,探索潜在的计算加速具有十分重要的意义。
深度学习模型的快速部署和推理应用是RISC-V架构面临的一个新挑战。目前传统的基于Python的深度学习框架(TensorFlow、PyTorch和MXNet等)尚不支持RISC-V指令架构。欲在RISC-V平台上执行一个深度神经网络模型的推理过程,研究人员往往需要构建复杂的交叉编译工具链,修改深度学习库中特定的机器源代码,自定义指令集拓展[7],不利于模型快速部署和优化。我们希望在RISC-V平台上探索一种快速部署模型方式,为深度强化学习应用的加速提供新思路。
快速部署的解决方案首推虚拟化技术。传统的虚拟化技术通过虚拟机监视器VMM(Virtual Machine Monitor或称为Hypervisor)实现,允许在宿主机设备上运行多个异构的体系结构应用,为用户提供抽象、虚拟的硬件环境。使用Hypervisor实现的虚拟化产品有VMware Workstation和Virtual PC等。Hypervisor提供了良好的跨平台兼容性,但在RISC-V架构上直接使用虚拟化技术有以下几个问题:(1)每个虚拟机都需要运行一个完整的操作系统和大量的应用程序;(2)资源占用多;(3)运行响应慢[8]。在实际开发环境中,我们更关注自己部署的应用程序。其次,端设备上的硬件资源可能有限,用户需要使用在操作系统层面实现的更加轻量级的虚拟化技术,在提供高质量的虚拟环境的同时,降低对系统性能的影响。在云计算框架中,面向轻量级软件虚拟化,Pahl[9]提出了容器化的解决方案。容器化技术通过命名空间(Namespace,表示一个标识符的可见范围)为每个容器提供特定的命名空间,对进程实现隔离,相对于传统的虚拟机,容器化技术具有更少的系统占用,更快的启动速度和更高的资源利用率。Docker是目前最为常用的容器技术,在容器的基础上从文件系统、网络互联到进程隔离等进行了进一步的封装,极大简化了容器的创建和维护,使得 Docker 技术比虚拟机技术更为轻便、快捷。但是,Docker尚不支持RISC-V架构,使用容器技术在RISC-V平台上实现模型的快速部署是一个亟待解决的问题。
本文针对强化学习这一领域,对基于RISC-V架构的端设备上的强化学习容器化方法进行研究。首先,通过采用容器化技术减少上层软件构建虚拟化代价,去除冗余中间件,定制命名空间隔离特定进程,有效提升学习任务资源利用率,实现模型训练快速执行;其次,利用RISC-V指令集的特征进一步优化上层神经网络模型,优化强化学习效率;最后,实现整体优化和容器化方法系统原型,并通过多种基准测试集完成系统原型性能评估。在原型系统实现里,本文使用QEMU(Quick Emulator)模拟器仿真的RISC-V指令架构作为实验平台,叠进式设计、实现和测试多种强化学习优化算法,讨论模型在RISC-V平台上的可移植性和性能表现。
本文的结构如下:第2节讨论RISC-V上虚拟化相关的工作;第3节提出了一种RISC-V架构下的容器化方法;第4节对初步的实验结果进行评估;最后一节总结目前得到的结论以及工作的不足之处。
2 相关工作
2.1 虚拟化技术
虚拟化技术是在一台主机上运行多个进程,将硬件资源(包括计算机的硬件资源、存储设备和网络资源等),抽象为虚拟逻辑对象的技术。虚拟化技术包括平台虚拟化、硬件虚拟化和应用程序虚拟化等,平台虚拟化技术允许在宿主机设备中运行多个异构的体系结构应用,通过虚拟机监视器VMM为用户提供抽象、虚拟的硬件环境。Popek等人[10]为将系统软件视为VMM定义了3个基本特征:(1)保真。VMM上的软件的执行与硬件上的执行相同,除非定时影响。(2)性能。绝大多数虚拟机指令由硬件执行,而无需VMM干预。(3)安全。VMM管理所有硬件资源。VMM通过内核代码的二进制翻译实现虚拟化,在宿主机和虚拟机之间添加一层中间层,将宿主机处理器的指令代码转换、翻译成目标处理器的指令,捕获文件执行时所需的系统调用。VMware Workstation、Virtual PC和QEMU等均采用这种方法实现硬件的虚拟化。Adams等人[11]对x86架构下的软硬件虚拟化技术进行了比较,得出硬件VMM的性能通常比纯软件VMM的性能低的结论。硬件虚拟化技术不具备性能优势的原因主要有2个:(1)它不支持内存管理单元MMU(Memory Management Unit)虚拟化。(2)它无法与用于MMU虚拟化的现有软件技术共存。Shuja等人[12]根据ARM架构下移动虚拟化的硬件支持的最新进展,调查了基于软件和硬件的移动虚拟化技术,并介绍了CPU、内存、I/O、中断和网络接口等在移动设备中虚拟化面临的挑战和问题。他们的研究最后提出,在资源受限的移动设备上实施基于CPU的虚拟化解决方案会占用大量CPU周期和内存空间,而使用静态二进制转换实现虚拟化的解决方案开销更低。针对资源有限的边缘设备必须使用资源有效的技术来解决上述问题。Bernstein[13]介绍了Docker和Kubernetes,前者是一个开源项目,可以实现Linux应用程序的自动化快速部署,后者是一个用于Docker容器的开源集群管理器。
2.2 基于RISC-V架构的加速和优化
在RISC-V平台上有关深度学习的工作大多是将深度学习的计算负载(卷积、激活和池化等)从RISC-V处理器转移到专用的硬件加速器上[7,14,15],采用软硬件协同设计的方法加速深度神经网络模型推理计算。这种方法通常需要根据特定用途设计专用的硬件加速器,同时需要相应的自定义函数库、编译器等工具链。
在RISC-V平台上部署模型最简单的方法是直接在RISC-V上编译深度神经网络模型,但由于硬件资源和模型性能存在限制,实际开发中通常采用交叉编译的方式来部署模型。Kong[16]提出了一个可以在RISC-V硬件平台(FPGA、QEMU模拟器等)上部署深度神经网络模型的计算框架RISC-V 人工智能框架AIRV(AI on RISC-V),允许在RISC-V平台而不是硬件加速器上运行深度神经网络模型的推理过程。此外还证明了相比于直接在RISC-V平台上编译网络模型,在x86平台上交叉编译RISC-V目标架构的深度神经网络模型具有更高的资源利用率。Louis等人[7]在RISC-V 指令集中的V矢量拓展模块基础上增加一层软件结构,修改了TensorFlow Lite C/C++库函数,此外还为RISC-V指令集交叉编译了TensorFlow Lite源码,并在RISC-V模拟器Spike上进行了验证。这种方法支持在RISC-V平台上部署多种网络模型,实验结果表明,使用这种方法可以将向处理器提交的指令数减少至直接编译方法的1/8。Vega等人[17]提出一种RISC-V I/O虚拟化RV-IOV(RISC-V I/O Virtualization)的硬件,解决了部署Rocket内核时的资源限制问题。Rocket Chip是一个开源的System-on-Chip设计生成器,可生成支持RISC-V 指令集的通用处理器核心,并提供有序核心生成器(Rocket)和无序核心生成器(BOOM)[18]。RV-IOV使用I/O虚拟化技术将Rocket内核与主机解耦,从而可以利用ASIC或更大规模的FPGA实现内核。
2.3 深度强化学习
强化学习RL(Reinforce Learning)和监督学习、无监督学习都是机器学习任务的一种,与监督学习和无监督学习任务相比,强化学习强调智能体(Agent)在与环境(Environment)的交互中学习,利用评价性的反馈信号实现决策的优化[19]。强化学习的主要过程为:智能体在环境中学习,根据环境的状态(State),执行动作(Action),并根据环境的反馈(Reward)做出更好的决策。强化学习的马尔可夫决策过程可以表示为:
M=〈S,A,Ps,a,R〉
(1)
其中,S表示有限状态集合,s表示某个特定状态,s∈S;A表示有限动作集合,a表示某个特定动作,a∈A;转移模型:T(S,a,S′)~Pr(s′|s,a):根据当前状态s和动作a预测下一个状态s′,这里的Pr表示从s采取行动a转移到s′的概率;奖励R(s,a)=E[Rt+1|s,a]表示Agent采取某个动作后的即时奖励,它还有R(s,a,s′)和R(s)等表现形式,采用不同的形式,其意义略有不同。
强化学习可以分为基于值函数的强化学习和基于策略的强化学习。基于值函数的强化学习算法包括Q-learning和Deep Q-learning等,基于策略的强化学习算法包括策略梯度等[20]。
3 RISC-V容器化方法
本文提出了一种RISC-V容器化方法,在其原型系统设计中,使用QEMU作为容器化引擎,定制命名空间隔离特定进程,在操作系统级别实现容器化。图1展示了原型系统的整体架构,左边是传统的使用Hypervisor的虚拟机架构,右边是容器化架构。原型系统使用QEMU模拟RISC-V处理器内核作为实验硬件平台,在RISC-V处理器上运行Linux系统,并安装QEMU。

Figure 1 Architecture of the prototype system
QEMU是一个具有跨平台的特性、可执行硬件虚拟化的开源托管虚拟机,可通过纯软件方式实现硬件的虚拟化,模拟外部硬件,为用户提供抽象、虚拟的硬件环境。QEMU既可实现全系统硬件虚拟化,也可在User Mode下通过为每个容器提供特定的命名空间实现容器化设计。在 User Mode 下,QEMU不会仿真所有硬件,而是通过内核代码的TCG(Tiny Code Generator)模块对异构应用的二进制代码进行翻译和转换。异构文件在执行时,通过binfmt_misc识别可执行文件格式并传递至QEMU。binfmt_misc是Linux内核的一种功能,它允许识别任意可执行文件格式,并将其传递给特定的用户空间应用程序,如仿真器和虚拟机。QEMU将注册的异构二进制程序拦截、转换成本地指令架构代码,同时按需从目标架构系统调用转换成宿主机架构系统调用,并将其转发至宿主机内核。TCG 定义了一系列IR(Intermediate Representation),将已经翻译的代码块放在转换缓存中,并通过跳转指令将源处理器的指令集和目标处理器的指令集链接在一起。当Hypervisor执行代码时,存放于转换缓存中的链接指令可以跳转到指定的代码块,目标二进制代码可不断调用已翻译代码块来运行,直到需要翻译新块为止。在执行的过程中,如果遇到了需要翻译的代码块,执行会暂停并跳回到Hypervisor,Hypervisor使用和协调TCG对需要进行二进制翻译的源处理器指令集进行转换和翻译并存储到转换缓存中。图2为TCG的工作示意图。

Figure 2 Tiny Code Generator translation process
4 性能评估和分析
4.1 实验设计
实验设计使用 QEMU 模拟的RISC-V64位指令架构4核处理器,内存为2 GB,主频为1.7 GHz,安装Linux系统和QEMU。图3展示了在RISC-V处理器上部署深度神经网络模型的流程。本节设置了3组对照实验:(1)交叉编译;(2)Hypervisor虚拟机;(3)容器化方法。首先在x86平台上构建强化学习RL模型,实验(1)使用交叉编译的方式[7, 16]部署深度学习网络模型。部署过程中需要对每个模型单独配置环境,修改强化学习库函数,构建交叉编译工具链。实验(2)使用Hypervisor虚拟机的方式,使用QEMU在RISC-V平台上进行全系统模拟,在虚拟机上安装基于x86架构的操作系统,配置强化学习模型训练环境。实验(3)采用本文提出的容器化方法,使用QEMU User Mode在容器化的进程中执行基于x86架构的模型,模型文件需将运行所需的依赖库封装至二进制可执行文件,实现模型训练快速执行。
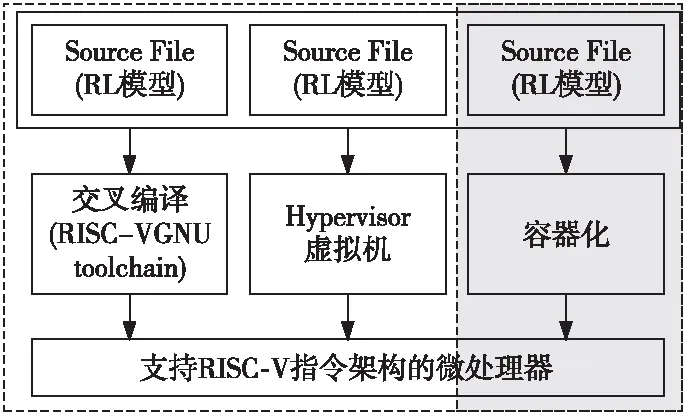
Figure 3 Three processes for deploying a deep neural network model on a RISC-V platform
4.2 强化学习算法
强化学习在自动驾驶、连续控制等领域的表现甚至可以和人类相媲美[6]。图4展示了在实验过程中使用强化学习算法解决连续控制领域的经典问题——Cart-Pole模型:木棍在一个可移动的小车上竖立,通过学习决定小车的位置,使木棍在小车上竖立的时间尽量长。本节在x86平台上使用PyTorch[21]构建深度神经网络模型,在Gym[22]环境中模拟Cart-Pole模型的训练,并部署在RISC-V实验平台上。基准测试集中的强化学习算法包括:(1)随机代理(Random Policy);(2)交叉熵(Cross-entropy);(3)策略梯度(Policy Gradient)[20],叠进式设计、实现、测试了多种强化学习优化算法,完成原型系统的性能评估。

Figure 4 Cart-Pole model
使用随机代理训练的模型不会收敛,只是记录执行一定步数后的奖励(Reward)总和,木棍会在小车上作随机方向运动,无法在小车上保持竖直。交叉熵算法可以实现一个稳定收敛的模型,基本思想是:使用当前策略(从一些随机的初始策略开始)对事件进行采样,并使用本文策略将最成功的样本的负面对数可能性最小化,恰好等于最小化交叉熵。具体做法是:首先,在环境和模型上运行N个轮次(Episode),每个轮次都是从开始到结束执行一次算法,计算每个轮次的奖励总和并确定一个奖励边界(如70%);其次,舍弃所有低于边界值的轮次;最后,在剩余的轮次中进行训练;重复上述步骤直到对结果满意为止。基于策略梯度的训练和基于交叉熵的训练相比,在轮次的分割中具有更细的粒度。策略梯度的基本原理是通过反馈调整策略:在得到正向奖励时,提高相应动作的概率;得到负向奖励时,降低相应动作的概率。策略梯度具有以下优点:(1)更好的收敛性;(2)适合高维度或连续状态空间;(3)不必计算复杂的价值函数。
4.3 实验结果
本节首先进行了交叉编译、Hypervisor虚拟机和容器化方法的性能比较实验。图5展示了随机代理、交叉熵和策略梯度算法在3种部署方式下的不同性能表现,比较了强化学习模型在3种方式下的模型训练时间。其中,交叉编译方式运行的模型训练时间最短;Hypervisor虚拟机方式运行模型的时间最长,和交叉编译方式相比大约增加了100倍以上的模型训练时间;容器化方法的模型训练时间居于二者之间,比交叉编译方式约增加了10倍以上的模型训练时间。
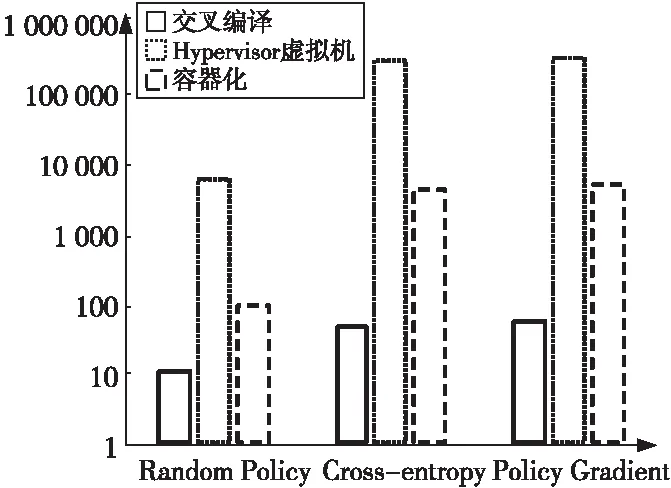
Figure 5 Performance comparison of different algorithms under three processes
图6展示了随机代理、交叉熵和策略梯度算法在3种方式下部署模型需要修改的代码行数。在所有的算法中,交叉编译方式除了对模型本身文件进行修改外,还需要修改深度学习模型依赖库(如Numpy,Scipy和Gym等)中的函数,修改代码数量最多;使用Hypervisor虚拟机方式只需对模型本身文件进行修改,所需修改的代码量最少;容器化技术需要将深度学习模型文件和所需依赖库进行封装,无需对库函数进行修改,和Hypervisor虚拟机相比增加了约40%的代码。
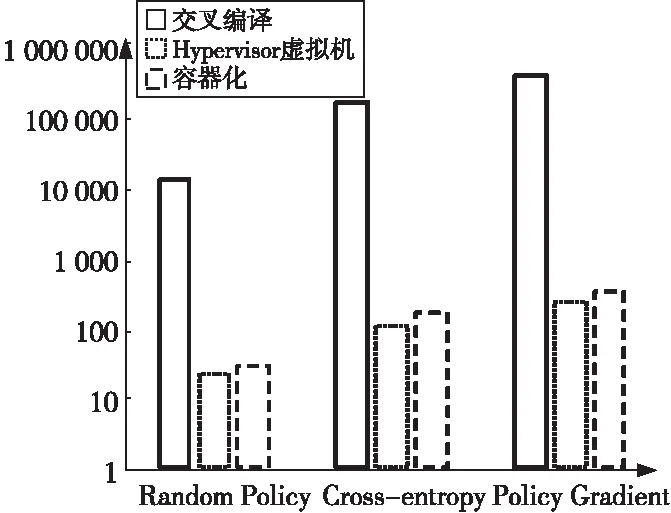
Figure 6 Number of code lines to be modified when deploying model
本节进一步对端到端的模型训练和运行时延进行了分析,如图7所示。3种部署流程下建立模型的时间相同,部署到RISC-V指令架构的实验平台的过程中,交叉编译的方式耗费时间最多,Hypervisor虚拟机方式耗费的时间最少。和虚拟机方式相比,容器化方式在模型部署过程中多耗费了约30%的时间开销;和交叉编译方式相比,减少了约85%的时间开销。

Figure 7 Comparing the total time to build the model,deploy the model in RISC-V,and train the model under three workflows
4.4 评估分析
图8综合了图5~图7的实验结果,其中,X轴表示模型部署时间,Y轴表示模型训练时间,气泡大小表示模型部署包括的代码数量。从图8中可以看出,容器化方法在3个指标上均处于中间位置。和交叉编译的方式相比,容器化方法付出了约10倍的性能代价,减少了85%的模型部署时间和95%以上的代码数量;和虚拟机的方式相比,仅增加了约30%的模型部署时间和约40%的代码数量,减少了100倍的模型训练时间,大幅提升了模型性能。

Figure 8 Consolidated experimental
初步的实验结果表明,使用交叉编译方式部署模型虽然可以得到最高的模型性能,但部署周期最长,这是因为在移植模型的过程中需要对库中所有特定的机器源代码进行修改;在设置完毕虚拟机环境后,Hypervisor虚拟机方式可以大幅减少模型部署时间的消耗,但每次模型训练都需要运行完整的虚拟机,加载工作环境,和交叉编译方式相比会带来额外的资源占用;容器化方式和传统RISC-V架构下交叉编译深度神经网络模型的方法和使用Hypervisor虚拟机的方式相比,仅付出相对较小的额外性能代价,在近似的部署时间内,可实现更多、更复杂的深度学习软件框架的快速部署和运行。因此,容器化方式及其优化方法是解决基于RISC-V架构的软件及学习模型快速部署的一种有效方法。
4.5 不足与展望
在容器化的流程中,需将模型文件和依赖的库函数一同封装成镜像文件,但目前的封装方式较为粗糙,复杂模型打包后的镜像文件占用了GB级别的磁盘空间,我们将逐步完善整体工作流程,对模型实现更细粒度的封装,进一步减少资源占用。
强化学习的计算包含大量的循环过程,通过指令的乱序执行可以大幅提高指令的并行性,提高计算效率。未来会使用支持乱序执行的RISC-V处理器核心对强化学习的计算过程进行优化。
5 结束语
使用虚拟化技术可以解决跨平台的模型快速部署和运行问题。但是,传统的虚拟化技术,例如虚拟机,对原型系统性能要求高,资源占用多,运行响应慢,往往不适用于RISC-V架构的应用场景。
本文首先通过容器化技术减少上层软件构建虚拟化代价,去除冗余中间件,定制命名空间隔离特定进程,有效提升学习任务资源利用率,实现模型训练快速执行;其次,利用RISC-V指令集的特征,进一步优化上层神经网络模型,提高强化学习效率;最后,实现整体优化和容器化方法系统原型,并通过多种基准测试集完成系统原型性能评估。容器化技术和在传统RISC-V架构上交叉编译深度神经网络模型的方法相比,仅付出相对较小的额外性能代价,就能快速实现更多、更复杂的深度学习软件框架的部署和运行;与Hypervisor虚拟机方式相比,基于RISC-V的模型具有近似的部署时间,并减少了大量的性能损失。初步实验结果表明,容器化方式及其优化方法是解决基于RISC-V架构的软件和学习模型快速部署的一种有效方法。
目前在RISC-V平台上对各种虚拟化方案性能方面的研究仍有待进一步探索,未来将会对深度神经网络模型进行量化、减枝等操作,针对特定领域对模型进行专门优化,形成基于RISC-V架构的深度神经网络模型构建、镜像打包、容器化技术部署的完整流程。
