基于宽度学习系统的电动汽车用户台区相属辨识
2021-02-28李红玲吴杰康蔡志宏王瑞东
李红玲,吴杰康,蔡志宏,王瑞东
(广东工业大学 自动化学院,广州 510006)
0 引 言
随着全球能源互联网的不断推进和“碳中和”倡议的持续发酵,电力行业面临着新的机遇和挑战。新的发展、新的诉求对电力营销、调度、配网等环节的发展也提出了更高的要求。智能电网是近些年来电力工业最重大的变革与创新,也是智慧城市建设的重要组成部分之一[1]。同时,智能电网的快速发展也对配电侧的精细化管理提出了更高的要求[2]。然而配电台区普遍存在线损计算异常等问题,导致台区运行、规划等多个高级应用难以推进,难以对整个台区实现智能化管控,会对用户的安全用电造成直接的影响[3]。终端用户难以和台区管控的配电变压器准确配对是该问题的主要成因。因此,提出精准且高效的台户关系辨识方法,对实现智能配电网台区管理运行的“信息化、自动化、精准化”具有重要意义,且台区的运行和优化管理,对供电企业的发展与管理起着重要的作用。
根据配网台区发展进程,台区用户的相别辨识方法可以分为传统方法、通信信息方法和大数据分析方法。传统方法主要依靠人工记录、整理,据火线走向进行相别辨识,部分区域配网线路错综复杂导致辨识过程费时费力且辨识结果准确率不高。通信信息方法通过在台区用户部署相应电子仪器,对仪器中电力载波信号或脉冲电流信号进行分析比对,从而实现台区用户的相别辨识,具有较高的准确率。但仪器本身的运营维护费用较高,在一定程度上增加了电网运营成本。且邻近台区或者周边环境对电信号的干扰,使台区间信息易出现混叠、交叉等问题,导致台区用户相属辨识的准确率有所下降。
大数据分析方法得益于智能装置及大数据技术的发展,通过大数据技术分析数据的变化趋势,配网的拓扑结构与数据的变化趋势息息相关。成本低廉的海量数据可为电力公司提供众多核心信息用以分析资产管理优化、分台区管理和台区用户相别辨识等问题。利用大数据分析方法对配网实际场景的线变关系进行了分析、校验。依据量测装置所采集的电压数据,一方面通过对台区用户智能电表中电压数据波动趋势的相似性分析,利用灰色关联分析来实现用户归属台区及相别的辨识[4],某些情况波动趋势相似性存在重叠,难以辨别所属相别;另一方面采用FastICA技术对电压时序数据进行独立成分分析(independent component analysis,ICA)及特征提取,对特征数据进行K-means聚类分析,从而实现台户辨识[5],但所需数据量过于庞大,辨识耗时较长。针对台区线变不匹配问题,文献[6]提出了一种考虑异常点的台区用户相别辨识方法,通过局部异常因子算法剔除非分析台区的用户数据,并采用改进K-means算法对属于分析台区的用户进行相别辨识,取得了不错的效果。就邻近台区数据信号互相干扰的问题,文献[7]提出了一种基于大数据的改进灰色关联分析的智能台区识别方法,通过关联度来判断电能表的台属性,排除邻近台区数据干扰,实测证明该方法能有效提高台区识别的精准度,但是复杂情况下精准度有待提高。
目前台区用户相属辨识大部分针对普通用户,忽略了电动汽车的不断融入对用户相属辨识的影响。针对上述问题及现有辨识方法所存在的缺陷,该文提出了一种基于宽度学习系统(broad learning system,BLS)的电动汽车用户台区相属辨识方法。首先,建立电动汽车随机参数的概率密度函数,利用拉丁超立方抽样技术(latin hypercube sampling,LHS)对电动汽车概率密度函数进行抽样,形成考虑电动汽车充电的用户电压模型;接下来,搭建台区相户拓扑结构,利用皮尔逊相关系数来准确区分研究台区用户和非研究台区用户;最后,基于某研究台区纯电动汽车用户数据和混合用户数据,通过宽度学习系统辨识研究台区用户的相属,对比支持向量机(support vector machine,SVM)、线性判别(linear discriminant, LD)以及最邻近分类(K-Nearest neighbor,KNN)算法等传统辨识方法,证实了该文方法在台区相户识别方面具有更高的实用价值和准确性。
1 计及电动汽车充电的台区相户拓扑结构
随着物联网产业的发展[8]和低碳环保理念的倡导,电动汽车行业开拓了广阔的市场,越来越多的家庭开始响应政府号召,选择用电动汽车作为代步工具。然而,电动汽车的充电行为会影响用户电压特征,进而影响台区相户辨识的准确性。考虑上述因素,根据建立的电动汽车负荷模型,更新用户电压,重建台区相户拓扑结构。
1.1 电动汽车负荷模型
电动汽车负荷模型建模方法主要包括单一建模、物理学建模、统计学建模。融合多台电动汽车的差异,考虑起始充电时间、日行程量等常规因素,采用统计学建模方法[9]对电动汽车负荷进行建模,进而更新用户电压数学模型。假定1天中电动汽车并/离网时刻、充电功率是相户独立的随机变量,模型建立包括以下两步:
1.1.1 建立离/并网时刻、日行程量的概率密度函数
并/离网时刻是指电动汽车在1天中起始接入/脱离电网的时刻。基于美国联邦公路局的美国家用车辆调查结果(national household travel survey,NHTS)[10],近似认为离/并网时刻服从正态分布,日行程量服从对数正态分布[11],进行拟合处理后,分别得到如下的离/并网时刻、日行程量的概率密度函数:
(1)
(2)
(3)
式中:f0、fi、fk分别是离网时刻、并网时刻、日行程量的概率分布函数;μ0、μi、μk分别是离网时刻、并网时刻、日行程量的期望;δ0、δi、δk分别是离网时刻、并网时刻、日行程量的标准差。
1.1.2 拉丁超立方抽样
LHS的主要原理[12]就是将取值范围为[0,1]的概率密度函数进行分区段打乱抽样,得到样本数据,分为以下两步:
1)样本抽取。定义Yk为任意第k个随机变量,将Xk的累积概率分布函数定义为
Yk=ζk(Xk)
(4)
设样本总数为n,以概率密度函数的取值范围为[0,1]的纵轴为基准,进行N等份分区处理,第m个分区所对应的Yk的样本值定义为
(5)
结合式(4)和式(5),经过反函数计算,得出任意一个随机变量的第m个区段样本值,表达式如下:
(6)
将k个随机变量的N个样本值xk,m组合成样本矩阵Xk×N。
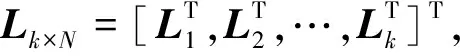
(7)
式中:pk,j表示相关性矩阵中第k行第j列的元素(k≠j)。
根据式(6)和原次序矩阵L,更新第m个区段抽样样本的对应样本值x′:
(8)
式中:lk,m为次序矩阵第k行第m列的元(k≠m)。
1.2 用户电压模型更新
用户通常的用电对象是指家用电器、照明装置等,由于小区的智能化、环保化发展,电动汽车成为每家用户不可或缺的交通工具。考虑到电动汽车放电的复杂性和不确定性,仅考虑电动汽车的充电行为。用户的原始电压必然会受到电动汽车充电行为的影响。
根据上节的理论介绍,假定有680辆电动汽车,设定μ0=8.91,δ0=3.23,μi=17.46,δi=3.42,μk=2.97,δk=1.15。拟合得到电动汽车各随机参数(离/并网时刻、日行程数)的概率密度函数,结果如图1所示。根据拉丁超立方抽样,抽取特定样本数量的离/并网时刻,根据离/并网时刻从而知道电动汽车充电时间、充电功率存在时间段,即电动汽车有效充电时段会影响用户的电压,对台区相户辨识起到一定的影响作用。电动汽车产生的电压差定义为
(9)
式中:P表示电动汽车的充电功率;R+jX表示线路阻抗。
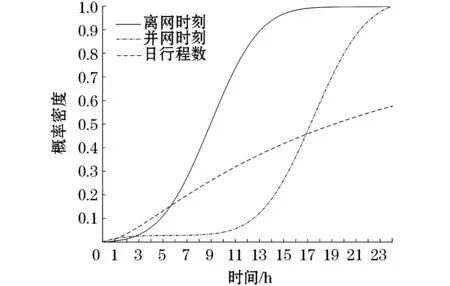
图1 电动汽车各随机参数的概率密度函数Fig.1 Probability density function of each random parameter of electric vehicle
将电压差映射到用户电压上,表达式如下:
U′=U-ΔU
(10)
式中:U是初始不受电动汽车影响的用户电压。
1.3 台区相户拓扑结构
低压配电网终端由变压器、配电箱和配有智能电表的用户端组成。一般每一个表箱都由三相进线,由表箱分出A、B、C三相连接各个电动汽车用户,一个表箱下可能存在单相用户,也有三相用户,该文台区相户关系辨识只涉及单相用户。相与相之间电压互不影响,每一相只受该相下所接用户的用电情况影响,具体的台区相户拓扑结构如图2所示。
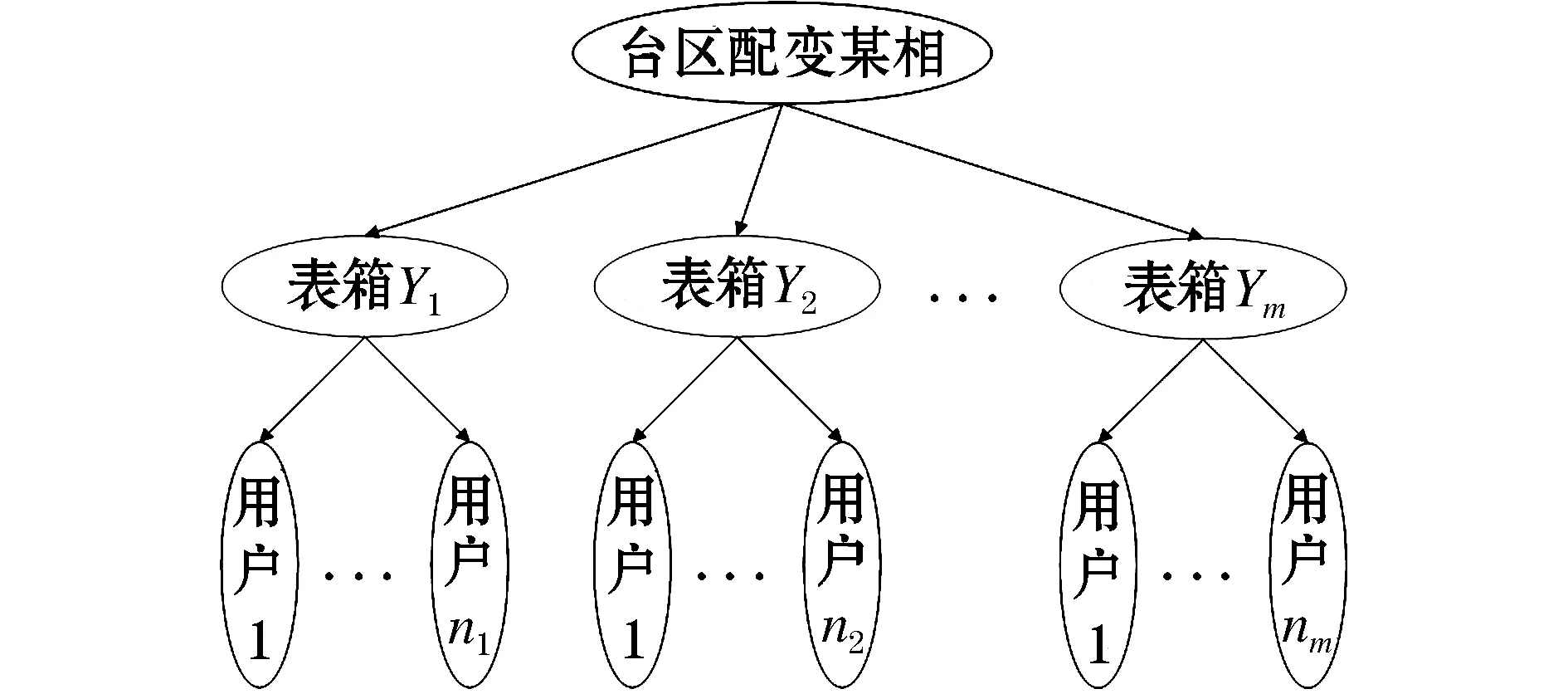
图2 台区相户拓扑结构Fig.2 The topological structure of the station area
台区相户等值电路如图3所示,M3点为变压器某相低压侧。通常低压侧的电压与用户用电功率、高压侧档位和负荷功率有关。高压侧的档位分别为±5%和0。由潮流计算可得M3点的电压为
(11)
VM3=VM1-ΔV
(12)
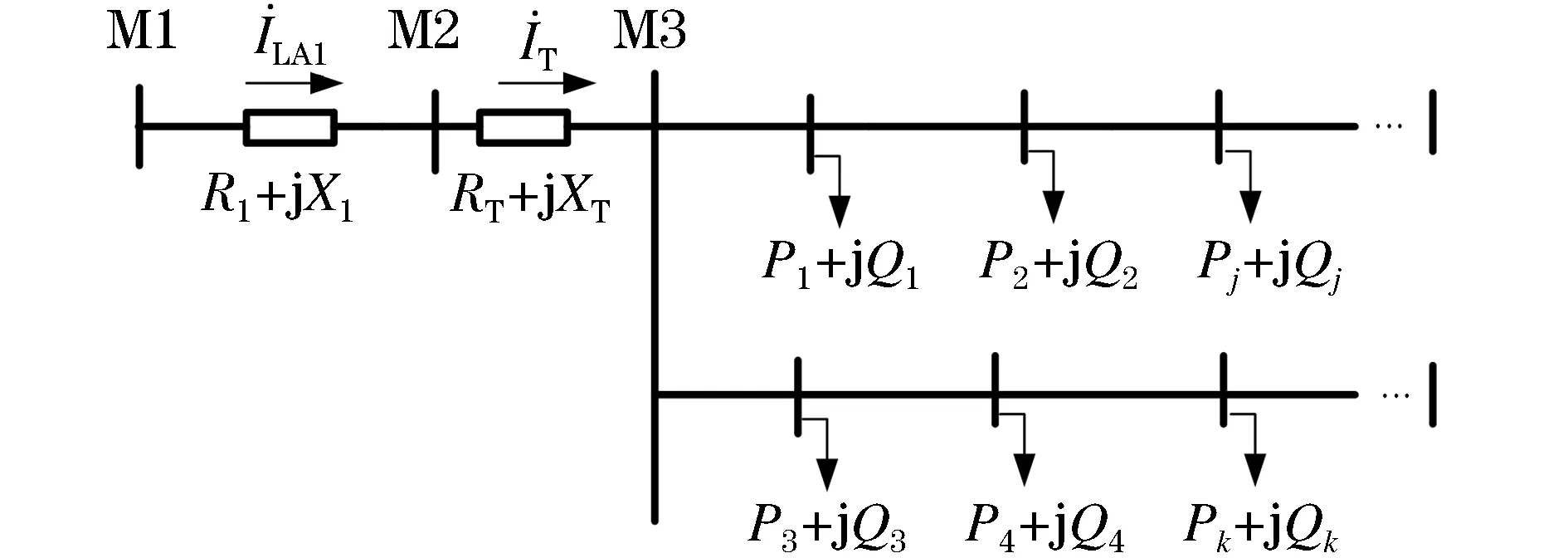
图3 台区相户等值电路图Fig.3 Equivalent circuit diagram of station area
电力系统中的台区是指一台配电变压器的供电范围,具体包括台区变压器及其下所属的所有用户。其中,低压台区属于用户供电的最终环节,电动汽车的充电行为会直接导致用户电压发生波动,从而会对台区相户辨识造成一定的干扰,易导致相户辨识发生偏差现象。
2 基于宽度学习的电动汽车用户台户辨识
2.1 用户台区相关性分析
由于某一台区下的不同相的用户群之间存在电压特征区分程度不明显的问题,并且传统的人工收集数据方法容易混淆相属用户电压,导致不属于本相的用户也被归类为该相。引入皮尔逊相关系数[13],用来衡量用户电压与台区相属电压的相似度。利用已获得的电压数据,可以先应用皮尔逊相关系数范围判断该用户是否属于该台区下的用户,否则标记为异常用户。用户台区相关性分析能够提高台区相户辨识的辨识度。
用皮尔逊相关系数的关联强度来表示两者之间的关联程度,关联系数的范围大小分别表示用户与台区三相之间的关联度。皮尔逊相关系数计算方式如下:
(13)
式中:E(·)表示求该向量的期望值;cov表示求两个向量的协方差;ρ(V,Xi)取值范围[-1,1],小于0时为负相关,大于0时为正相关,当且仅当V与Xi有严格线性关系时取±1。通过表1相关系数范围判断变量之间的相关强度。
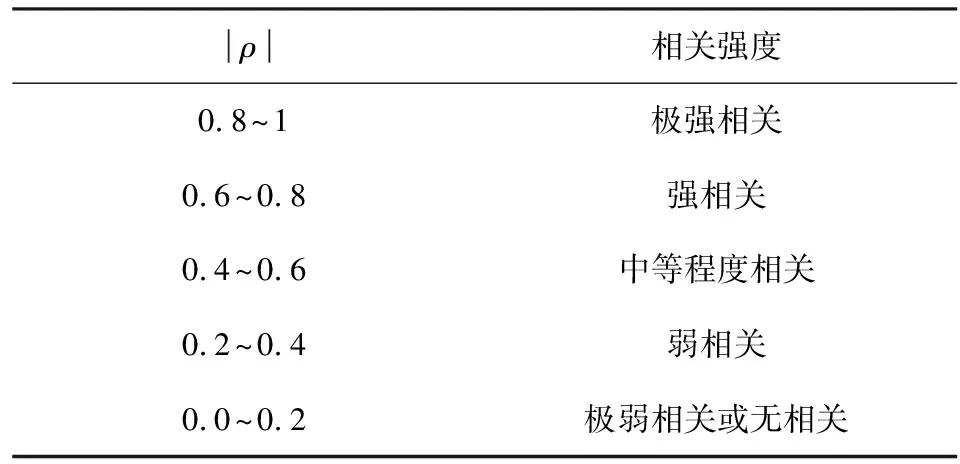
表1 Pearson相关系数相关强度Table 1 Pearson correlation coefficient correlation intensity
经上述皮尔逊相关系数计算,得到A、B、C三相相关系数范围分别为0.31~0.98、0.51~0.98、0.44~0.94。
2.2 宽度学习系统
宽度学习系统是近几年陈俊龙教授及其学生提出的浅层增量式神经网络。BLS是基于Yoh-Han Pao教授提出的随机向量函数链接神经网络(random vector functional link neural network,RVFLNN)基础上提出的,融合了动态逐步更新算法(增量学习)[14-15]。与传统深度网络不同之处在于提高精度的方式是增加网络的“宽度”而不是增加网络的“深度”。该文所采用的网络结构(如图4所示)不含增量学习部分。
BLS的建模思路为:首先,输入数据的映射特征作为网络的特征节点;其次,特征节点经过随机权值和偏置增强为增强节点;最后,特征节点与增强节点作为最终输入,输入与输出之间的权重通过岭回归的伪逆算法求解得出。
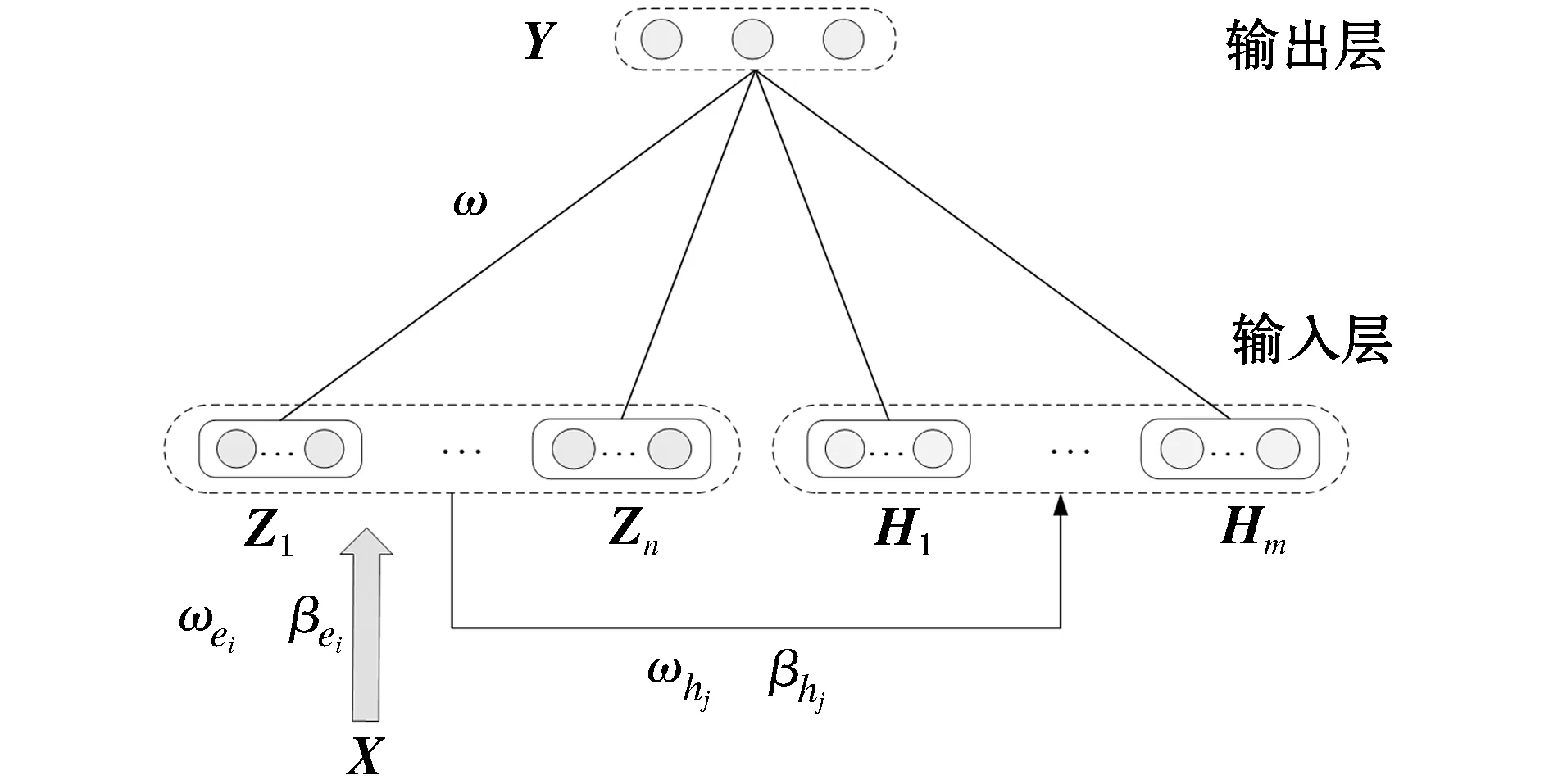
图4 BLS的网络结构Fig.4 Network structure of BLS
如图4所示,输入层包括两部分:特征节点和增强节点。假设有N个样本,每个样本维数为M,构成输入数据集XN×M=[X1,X2,…,XN]T,输出矩阵Y∈RN×C。将含有k个神经元的第i组特征节点定义为
Zi=ζ(Xεei+βei)i=1,2,…,n
(14)
式中:ζ(·)是激活函数;ωei和βei分别表示随机产生的权值和偏置。
为减少特征节点相互之间的可线性表示性,利用稀疏自编码器进行稀疏表示和微调处理。n组特征节点组合表示为
Zn=[Z1,Z2,…,Zn]
(15)
将含有r个神经元的第j组增强节点定义为
Hj=ξ(Xωhj+βhj)j=1,2,…,m
(16)
式中:ξ(·)是非线性激活函数;ωhj和βhj分别表示随机产生的权值和偏置。m组增强节点组合表示为
Hm=[H1,H2,…,Hm]
(17)
将特征节点Zn与增强节点Hm组合成最终输入数据,记为A=[Zn|Hm]。利用岭回归求解出输入层与输出层之间的权值ω,求解表达式如下:
ω=(ATA+λE)-1ATY
(18)
式中:λ是正则化系数;E是单位阵;T表示转置,记A的伪逆为A-1=(ATA+λE)-1AT。
2.3 基于BLS的电动汽车用户台户关系辨识建模
该文利用Pearson相关系数剔除非研究台区的用户数据,确保台区之间数据不存在混淆的情况,对辨识不产生干扰。考虑电动汽车对用户电压的影响,更新用户电压,引入宽度学习系统,新用户电压作为网络的初始输入,利用随机权值和偏置进行特征提取,生成特征节点和增强节点,通过岭回归的伪逆求解出输入-输出的权重,在权重的作用下得到辨识结果输出。该文所述辨识方法的流程图如图5所示,具体步骤如下:
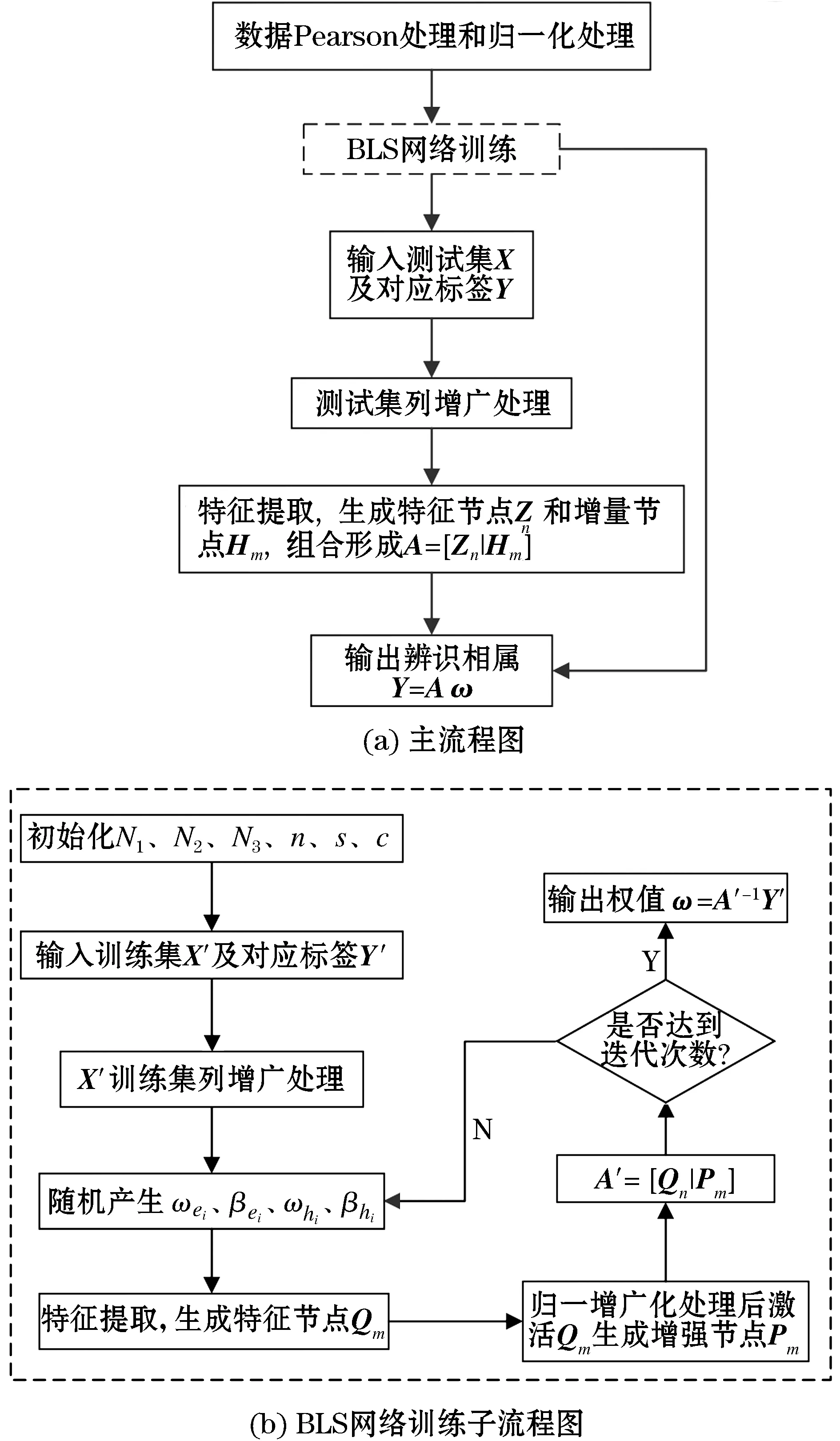
图5 辨识方法的流程图Fig.5 Flow chart of the identification method described
1) 根据研究台区已有的用户数据,首先,利用式(13)进行Pearson相关系数计算,剔除非研究台区的用户数据;再进行归一化处理,归一化式如下:
(19)
2) BLS网络训练。
①初始化单位窗口特征节点数N1、单位特征节点窗口数N2、增强节点数N3、迭代次数n以及增强节点的正则化参数s和缩放尺度c;
②划分训练集X′a×b及对应标签Y′和测试集Xc×d及对应标签Y;
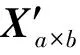
④随机产生权值和偏置ωei、βei、ωhj、βhj;
⑤特征提取,根据式(14),得到特征节点Qn;
⑥对特征节点进行增广和归一化处理,引入非线性激活函数ξ,结合式(16)得到增强节点Pm;
⑦特征节点与增强节点的组合形成最终输入数据A′=[Qn|Pm];
⑧达到迭代次数,根据式(18),结合岭回归算法理论计算出输入-输出权重ω。
3) 输入测试集数据,数据进行增广处理。
4) 特征提取,根据式(14)和式(16),形成特征节点Zn和增强节点Hm,整合成最终输入数据A=[Zn|Hm]。
5) 利用网络训练中的输入-输出权值,输出辨识相属Y=Aω。
3 实例仿真分析
该文研究的对象是某新兴小区的某台区下某台配变A、B、C三相的相户关系辨识。该配变下有A相用户29户,B相用户25户,C相用户30户,总共有84户用户,每家用户都配有一辆电动汽车。
3.1 电动汽车对用户电压的影响
根据1.1节所述的电动汽车负荷模型,利用离并网时刻得到充电时间,假定电动汽车充电功率P=30 kW,输电线路阻抗为0.36+0.18j Ω,结合式(9),同时考虑A、B、C三相电动汽车的充电行为的随机性和延时性,得到由电动汽车产生的电压差如图6(a)所示,原始用户电压(无电动汽车)与电动汽车用户电压对比图如图6(b)所示。
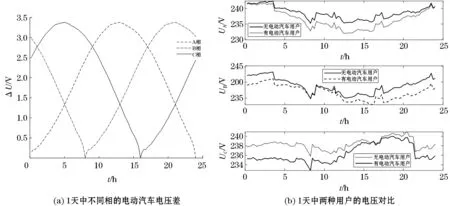
图6 用户电压受电动汽车的影响分析图Fig.6 Analysis diagram of user voltage influenced by electric vehicles
由图6(a)可知,由电动汽车产生的电压差在0.1~3.5 V之间,A、B、C三相的电压差的高峰值具有延时性,A相的高峰期大概在1天中的14点,B相延迟到21点左右,C相的高峰时刻大概在5点左右。从图6(b)可以看出,不论是A、B、C三相的哪一相普通用户,与电动汽车用户之间的电压差在4 V以内,对用户电压起到一个降低的作用,一定程度上削减了用户电压与配变电压的关联程度。
3.2 基于BLS的电动汽车用户台户关系辨识
利用Pearson相关系数即式(13),对初始用户数据进行筛选。再根据2.3节所述的基于BLS的电动汽车用户台户关系辨识模型建立步骤,利用MATLAB编写模型程序,设定增强节点的正则化参数c=2-30、增强节点的缩放尺度s=0.8、单位窗口特征节点数N1=41、单位特征节点的窗口数N2=35、增强节点数N3=1 100和迭代次数n=10。训练集采用60组电动汽车用户,每相各20组,对应的标签为配变各相的电压及相属标号。剩下的用户电压作为测试集。
定义混合用户包括有电动汽车用户和无电动汽车用户。为保证测试集数据的统一性,将测试集中无电动汽车用户随意替代每相中某些电动汽车用户,从而构成混合用户。为突出所述辨识方法的准确性和优越性,利用SVM、LD以及KNN 3种传统分类方法[16-18],基于相同的训练集和测试集进行辨识,训练集的准确率均为100%,训练结果如图7所示。
图7 SVM/KNN/LD训练集的训练精度Fig.7 Training accuracy of SVM/KNN/LD training set
测试集数据包括纯电动汽车用户和混合用户,为了使配变三相的辨识对象一致,混合用户中的非电动汽车用户A、B、C三相等分。该文所述辨识方法和3种分类方式的辨识结果如表2所示。

表2 辨识准确率Table 2 Analysis of identification results 单位:%
由表2结果可知,纯电动汽车用户的辨识准确率均为100%,对于混合用户的辨识准确率除了该文所述的BLS辨识方法均有所下降。虽然SVM和KNN针对混合用户的辨识准确率均为91.7%,但是根据测试集辨识结果(表3):SVM和KNN均无法辨识A、B相的非电动汽车用户,仅能准确辨识C相的非电动汽车用户,并且误判结果一致。两者的训练时间相差不是很明显。准确率为95.8%的LD只

表3 测试集辨识结果Table 3 Test set identification results
是无法辨识B相的非电动汽车用户。而对于BLS的辨别方法,无论是纯电动汽车用户还是混合用户,其准确率都是100%,能够有效、准确地辨识用户相属。
4 结 语
1) 该文所用的用户数据来源于实际小区的用户数据,电动汽车电压根据负荷模型进行仿真得来,具有一定的可靠性。
2) 随着环保理念的不断深入,家庭用户用电动汽车替代传统燃油汽车成为必然趋势,该文研究对象选择电动汽车用户,符合未来配电网台户关系发展的趋势。
3) 所提出的基于BLS的台区相属辨识方法不仅可以用于“相属-电动汽车用户”之间的辨识,还能用于“相属-用户”之间的辨识,普及性很高。
4) 所述辨识方法与SVM、KNN、LD这3种传统的分类方法进行对比,该文所述方法在2种情况下均能有效、准确地辨识。
5) 该文仅考虑电动汽车接网充电情况,没有考虑到电动汽车充电行为受电价影响,忽略了充电过程存在的放电行为。该模型的泛化能力有待进一步提高。
