增量跨模态检索方法
2021-02-28江朝杰杨良怀范玉雷
江朝杰,杨良怀,高 楠,范玉雷
(浙江工业大学 计算机科学与技术学院,杭州 310023)
1 引 言
随着互联网和智能设备的高速发展,多模态数据每日呈百亿量级增长,其中包括文本,图像和视频等,多种异质数据源交叉融合呈现.面对海量的多模态数据,在各种大数据应用中迫切的需要高效准确的跨模态检索技术.跨模态检索的主要挑战是解决不同模态之间的语义鸿沟.为了解决这个问题,主流的解决方案是学习一种对应关系,利用该对应关系将不同模态数据映射到一个同维度的公共子空间内,并通过它们在公共子空间内的距离表达数据之间的相似性.近几年研究者们在跨模态检索任务中取得了较大进展[1].但是在许多实际检索应用中,其数据源总是不断增量迭代的,如何从新类别样本中学习,利用新增数据集对检索系统进一步更新和完善,提升检索系统性能是面临的一个新问题.
为使模型能够适应新数据的检索,这就要求跨模态检索模型具有可扩展性,同时兼容旧数据集的检索效能.但目前大多数跨模态检索模型缺乏可扩展性,并且针对现有模型的微调会导致对旧样本数据集的灾难性遗忘,导致在旧数据集上的检索性能下降[2].若采用旧数据和新数据整合后重新训练模型的方案,将会导致计算成本和数据存储开销不断增加.因此,本文采用基于增量学习的跨模态检索方法来实现模型的可扩展性.
通过增量学习实现跨模态检索模型可扩展性有以下优点:1)无需更新旧样本数据集的哈希编码;2)同时支持新、旧类别样本的检索;3)节省模型训练成本.增量学习是指模型自适应地从不断到达的数据流进行学习,且通常是在有限的资源开销下进行模型扩展.其挑战在于平衡新知识与旧知识之间的关系,防止发生灾难性遗忘,即如何在学习新知识的情况下不遗忘旧知识[2].
目前大多数研究通过知识蒸馏(Knowledge Distillation,KD)的增量学习方法保留对旧数据集的检索性能.Hinton[3]等在2015年提出知识蒸馏技术,其通过从教师网络中提炼出学生网络来简化深度网络的训练过程,该方法将教师网络中有用的信息迁移至学生网络上进行训练,将学生网络和教师网络之间的共同概率分布输出差异性指标即两者之间的KL散度作为目标函数,从而使得增量模型保留了旧模型中的关键参数.
在跨模态检索中,由于存在不同模态成对样本数据,因此如何维系不同模态成对样本在知识蒸馏网络中的相似性成为一个难题.本文利用不同模态成对样本间在某些维度上的一致性输出概率分布来维系两者之间的相似性.在跨模态检索模型中将不同模态数据通过映射函数投影到公共子空间内,得到不同模态相同维度的特征表示.其中不同模态成对样本特征表示共享语义标签信息,因此其特征表示在某些特定维度上保有相似性,本文将此维度称为语义保留维度.为了使跨模态检索模型在扩展的过程中仍支持旧样本数据集的检索,采用知识蒸馏来保留不同模态成对样本间在语义保留维度上特征分布的一致性;同时为了使增量数据生成的特征表示在子空间内保有真实的语义分布,需要将增量数据集中标签之间的关联程度信息加入到模型训练中.
本文研究目的是如何在跨模态检索模型扩展中有效防止灾难性遗忘,并使所生成哈希编码中包含更多的标签关联语义信息.因此提出了增量跨模态检索方法ICMR.主要贡献如下:1)构建跨模态知识蒸馏网络,学习教师网络(跨模态检索模型)中成对模态样本特征表示在语义保留维度上的输出概率分布,保留在旧样本数据集上的检索性能;2)在生成不同模态哈希编码特征表示时,将统计得到的新旧标签共现概率矩阵作为监督信息作用于哈希编码的生成约束,用以标识样本之间关于新增类标签的相似可信度.
2 相关工作
在机器学习中,增量学习一直是一个长期存在的问题.在深度学习开始之前,人们一直在利用线性分类器、弱分类器集成,最近邻分类器等来开发增量学习技术[4,5].应对检索系统增量迭代的需求,近年来基于增量学习方法的研究成为热点.
按照是否使用旧数据集,可将增量学习分成两类.第1类方法不需要旧数据集,仅使用新增类样本参与模型扩展.Jung[6]等提出了一种领域迁移学习,试图通过冻结最后一层网络层并且阻止特征提取层中共享权重的变化来保持旧样本数据集检索的性能.James[7]等提出在利用新数据集训练网络时,限制重要权重改变来保留旧数据集检索的性能.但该方法中新旧任务可能在这些权重上发生冲突.Li[8]等通过知识蒸馏与微调组合的方法来保持旧样本数据集检索的性能,通过学习而不遗忘的方法来克服灾难性遗忘.Konstantin[9]等通过知识蒸馏逐步学习目标检测器.
第2类方法需要部分旧数据集.Rebuffi[10]等提出只需使用部分旧数据而非全部就能同时训练得到分类器和数据特征实现增量学习,减轻新旧类别之间的不平衡.Wu[11]等从数据不平衡和对新类别样本的预测偏差角度研究增量学习,使用平衡的验证集和偏差校正层来缓解遗忘问题.
然而,以上方法均局限于单一数据模态,不能处理不同模态类型之间的不一致分布和成对样本间的复杂语义关系.Qi[12]等提出了跨媒体终身学习(CMLL)方法,它是我们所知第1个在跨模态检索领域中研究增量学习方法的方案,通过域内的分布对齐和域间的知识蒸馏,在充分保留原有数据关联效果的同时,利用知识迁移促进新增数据的关联学习,实现跨媒体检索.Chen[13]等提出解决可扩展的跨模态哈希检索方案,称为可扩展跨模态哈希(extensible cross-modal hashing,ECMH).ECMH方法基于跨模态哈希(CMH)模型进行扩展.ECMH通过精心设计的“弱约束增量学习”算法,仅使用新数据集来扩展模型;其核心思想在增量学习中通过语义选择性保留的方式维持不同模态成对样本间的语义相似性.Mandal[14]等提出了用于跨模态检索的增量哈希方法,称为GrowBit,通过增加不同模态数据的特征编码位数以更好的表示新数据包含的语义信息;此后,他们又提出了一种新颖的增量跨模态哈希算法,称为ICMH[2],它可以适应于新增样本的检索任务,所提出的方法用于计算新数据集的哈希编码特征表示,使其保留数据集本身的语义关系,它包括两个连续的阶段,即学习哈希码和训练哈希函数.
然而以上这些方法皆忽略了挖掘样本类别标签存在的关联信息.很显然新增数据集的样本分布受标签语义的约束,标签之间的关联程度在一定层面上表示了样本的相似程度,因此加入有效的标签关联程度信息能够使基于增量学习的跨模态检索系统精准率更高.
本文的目标旨在解决跨模态检索系统的可扩展问题,通过增量学习方法动态的学习增量数据集包含的语义信息,使得生成不同模态的哈希编码特征更具有判别性,满足了节约计算成本和提升检索精度的要求.
3 基于跨模态检索的增量学习方法
本节主要介绍基于跨模态检索的增量学习网络架构.
3.1 基本定义
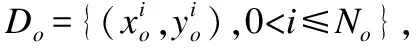
3.2 特征学习与表示
对于图像模态数据,采用预训练VGG16神经网络模型提取特征,其中包括5个卷积层,3个全连接层以及5个池化层,全连接层fc7作为图像特征输出层.对于文本模态数据,采用Google-News数据集预训练的word2vec模型来提取词级别的文本特征.不同模态通道通过新增多层感知机网络以生成相同维度的哈希编码来解决可扩展问题.将跨模态模型中图像、文本模态通道分别用特征映射Gx(x;θ)和Gy(y;θ)为每一个图像/文本样本生成一个同维度特征表示,特征表示矩阵分别为X和Y,其中对于图像特征矩阵X而言,矩阵列是样本数目索引,矩阵行上是特征向量的数值,文本特征矩阵Y与X是同型矩阵.所提ICMR会将旧参数θo更新为θn,相应得到两个版本的特征表示矩阵:使用旧模型生成的图像特征为Xo,文本特征为Yo;使用增量网络模型生成的图像特征为Xn,文本特征为Yn.用旧模型生成新样本特征表示的通道用n|θo表示,用增量学习模型生成新样本特征表示的通道用n|θn表示.
3.3 基于跨模态的增量学习网络
可扩展的跨模态检索模型目的是使得更新后的模型同时适应旧样本和新样本数据集的检索任务,在保持旧样本数据集的检索效能的同时支持新样本数据集的检索.ICMR核心思想之一是不同模态成对样本在特征分布空间中语义保留维度上的输出概率分布是相似的,因此应当在模型更新中保留相似的语义分布信息,使得扩展后的模型能够适应旧数据集的检索任务;另一个核心思想是为了使得生成不同模态的哈希编码能更贴近原始数据集的分布,因此将统计得到的标签项关联程度信息加入到模型训练当中.
如图1所示,居上部分是预训练的跨模态检索模型,本文选用Jiang[15]在2016年提出的Deep Cross-Modal Hashing(DCMH)跨模态哈希检索模型作为预训练的跨模态检索模型,其经过旧数据集预先训练,将其作为本文构建跨模态检索模型的教师网络,通过约束教师网络中语义保留维度上的输出概率分布一致性来指导学生网络进行学习.其中图像模态通道和文本模态通道分别生成同维度的特征,灰色标记代表了语义保留维度,在语义保留维度上通过跨模态知识蒸馏损失指导各自增量网络模块学习;居左右部分将不同模态样本在增量学生网络的映射特征作为输出,将经由激活函数softmax的特征用于分类损失约束;居中部分不同模态特征输出经激活函数sign生成哈希编码,其中将统计得到的新旧标签项之间的共现概率矩阵作用在哈希编码的生成学习当中.整体网络架构的目标函数由3个损失函数组成:
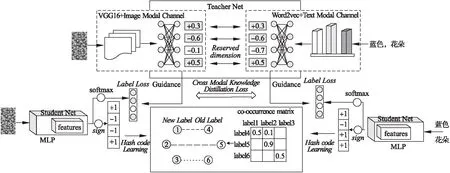
图1 增量跨模态检索方法结构图
(1)
其中θx为增量模型的图像通道参数,θy为文本通道参数.采用了基于跨模态的知识蒸馏损失Ld,将原有跨模态检索模型对旧样本数据集的检索性能迁移到增量模型当中.类别误差损失Lc,使模型从新样本中学习新类别的语义信息.Lh作用在哈希编码的生成,目的是使得生成哈希编码特征表示更贴近新样本数据集的真实语义分布.其中基于纺织品的增量数据集如图2所示.

图2 新增样本类数据集示意图(下滑线字代表新增类标签)
3.3.1 基于跨模态的知识蒸馏损失
为了得到成对样本特征表示间的语义保留维度分布位置,首先需要通过预训练的跨模态检索模型分别生成不同模态的特征表示集合Xn|θo和Yn|θo,将经过激活函数sign的特征在每一个维度上计算相似性,若相等或相应维度上的差值小于某个阈值,则代表成对样本特征在这个维度上的分布概率相似.根据上述定义维度对齐矩阵Mα:
(2)
α表示相应维度上的差数绝对值不能高于这个阈值,因为不同模态生成的特征维度上的差值太大表示了其包含的语义信息相似程度较低.其中Mα[i,j]表示第i个不同模态成对样本特征在第j维度上的相似性,其中1表示相似,0代表了不相似.
蒸馏学习要求学生网络学习教师网络的输出概率分布,如果更新后的模型参数θn和原有模型参数θo具有相似的输出概率分布,那么代表了可扩展跨模态检索模型一定程度上保留了旧模型检索性能.针对不同模态的样本实例,首先使用预训练的跨模态检索模型将成对样本集映射到公共子空间内,不同模态数据集分别生成特征矩阵集合.然后使用维度对齐矩阵Mα作为特征向量选择器,使得增量模型输出的特征在语义保留维度上其输出概率分布与原模型保持一致.
KL 散度是一种衡量两个概率分布的匹配程度的指标,两个分布差异越大,KL散度越大,定义如下:
(3)
在知识蒸馏中p(x)是学生网络目标分布,q(x)是教师网络去匹配的分布,如果两个分布完全匹配,那么DKL(p‖q)=0.
跨模态蒸馏学习中需要在softmax中增加温度参数T.在原有的跨模态检索模型中包含了数据结构信息以及映射函数参数,当T值较大时,相当于用很高的“温度”将关键的分布信息从原有的模型参数中分离,然后在同样的温度下用增量学生模型融合蒸馏的方法学习教师网络的特征输出概率分布,最后恢复温度,让两者充分融合.
(4)
T是一个调节函数,通常为1;T的数值越大则所有类的分布越平缓.修改后的softmax也被称为软目标(soft target).应用在蒸馏网络中的学生和教师模块中,那么不同模态输出分别为Xsoft和Ysoft.
为了使得不同模态通道增量网络输出与旧模型中的特征映射层网络在语义保留维度上保持相似的输出分布,本文构建基于跨模态的知识蒸馏网络,其基于跨模态的知识蒸馏损失Ld定义:
(5)
其中∘代表了矩阵乘积,不同模态通道的KL散度度量矩阵和维度对齐矩阵Mα乘积.
3.3.2 新增类别的分类损失
为了使不同模态数据投影到公共子空间之后分布特征包含新增类别语义信息,在蒸馏网络的学生模块中构建分类误差学习.在学生网络模块中不同模态通道分别构建多层感知机MLP.将不同模态公共子空间内的特征作为输入,利用交叉熵损失进行分类训练.分类误差损失需要将类标签集合one-hot编码化,因此拆解后的样本旧标签项one-hot编码集合为Lo∈[0,1]No×k,其中k表示旧标签项数目.样本新标签项的one-hot编码集合为Ln∈[0,1]Nn×(m+k),其中Nn是新增数据集的大小,m是新增类标签项数目.其误差为:
(6)
pi代表了不同模态特征类别的概率分布,ci代表了当前新数据集中实例的类别标签,Xi代表了图像数据集的第i个实例特征,Yi代表了文本数据集的第i个实例特征,N是训练批次样本集的大小.
3.3.3 蒸馏网络总误差
蒸馏网络的学生模块经过软目标可以学习跨模态教师模块软化的概率分布,硬目标则是样本的真实标注.total loss设计为软目标与硬目标所对应的交叉熵的加权平均.其中软目标交叉熵的加权系数越大,表明迁移诱导越依赖教师网络的贡献,有助于让学生网络更轻松拥有教师网络的检索性能,但训练后期需要适当减小软目标的比重,让真实标注信息帮助提升检索新样本的能力[3].
LKD(Wstudent)=αT2Ld+(1-α)Lc
(7)
其中α是权值参数,标识蒸馏损失和分类损失所占权重.在基于跨模态的蒸馏学习网络中,不同模态的学生网络参数由分类损失Lc和跨模态知识蒸馏损失Ld加权训练而成.
3.3.4 哈希码的学习
Mandal[16]等在2017年提出了基于语义保留的跨模态哈希生成的方法,通过保持数据样本之间的语义相似性,从而使得生成的哈希码保有原始数据集之中存在的真实语义分布信息.通过样本标签之间相似性度量构建“亲和度”矩阵S,成为哈希编码生成的监督信息,约束不同模态哈希编码的语义关系.
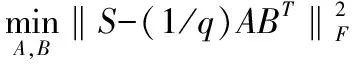
s.t.A∈{-1,1}N1×q,B∈{-1,1}N2×q
(8)
其中q是哈希编码的长度,A和B分别是不同模态的哈希编码,亲和度矩阵S由样本集之间的多标签one-hot编码内积得到,样本数N1=N2.目的是使得生成的不同模态间的哈希编码整体相似性接近其类别相似性,从而得到接近“真实”语义结构关系的特征分布.
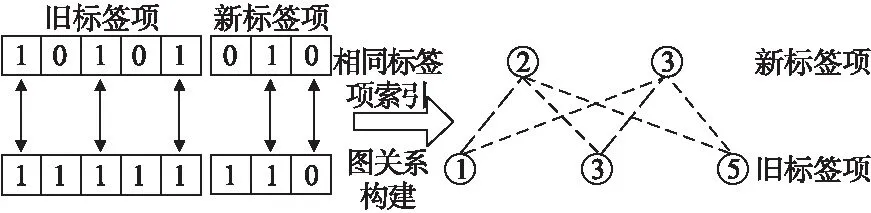
图3 拆解新旧标签项分层相似图嵌入
将不同模态样本的特征表示经由sign激活器生成相应的哈希编码.
(9)
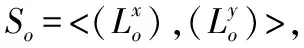
假定新增样本集大小为Nn,其中旧数据集标签项数目为k,新增数据集的标签项数目为k+m.共现矩阵可以统计出分类标签同时出现的次数,其基本思想是:统计两个分类标签同时出现的概率,如果概率越大,其相关性就越紧密,关联度越高),构建共现矩阵的基本步骤为:首先将每一份样本的新增类标签分隔开并转换成列表,同时建立关于新增类标签的字典,建立空矩阵用于存放标签的共现矩阵,然后计算新增类标签项与旧类标签项之间的共现频次,最后可取出标签之间的共现频次用于新标签相似性程度的标识.
在机器学习中,点互信息PMI通常用来衡量两个变量之间的相关性,基本思想是统计两个词语在文本中同时出现的概率,如果概率越大,其相关性就越紧密,关联度越高.已知A标签和B标签的累计出现频次和共现频次,其PMI值等于log((共现频次/A标签的累计出现频次)*(共现频次/B标签的累计出现频次)).log取自信息论中对概率的量化转换.
(10)
利用统计出的新旧标签共现频次计算得到共现概率矩阵为:
(11)
其中Li来自于样本新标签项集合,Lj来自于样本旧标签项集合,m和k分别属于新旧类标签项个数.
我抬头看着杨公子,他的眼中似乎有些许泪光,他转过头不再看我。那一刻,我明白了,他心中一定曾经有个意中人。
在哈希码的生成约束中,本文拆解样本新旧类标签,通过计算新旧标签共现概率矩阵约束样本关联程度,以此使得生成哈希编码特征分布更贴近真实语义关系.
(12)
其中k代表了旧标签项的数目,m代表了新增标签项数目,q代表了哈希编码的长度.Sco表示了新旧标签共现概率矩阵,其中新标签项作为行,旧标签项作为列.μ表示关于新旧标签项的样本集相似矩阵所占权重.
基于跨模态检索的可扩展网络模型要求能够在保留旧数据集语义信息的同时适应增量样本数据集的检索效能.本文通过构建双通道跨模态蒸馏误差Ld和类别误差Lc以及哈希编码生成约束误差的Lh来实现其要求.其流程如算法1所示.
算法1.ICMR.
输入:新增图像数据集x、新增文本数据集y,标签集C
输出:不同模态通道学生网络参数θx和θy
1. 初始化跨模态通道θo以及增量网络θn,不同模态迭代batch样本集大小为q,迭代次数为p;
2. 拆解新旧标签项进行统计分析,得到新旧标签共现概率矩阵Sco;
3. Repeat:
4.Xn|θo,Yn|θo=G(x;θo),G(y;θo)
5.Xn|θn,Yn|θn=G(x;θn),G(y;θn)
6. 根据公式(2)得到维度对齐矩阵Mα;
7. 根据公式(5)通过计算跨模态知识蒸馏损失Ld;
8. 根据公式(6)计算类别误差损失Lc;
9.Hx=sign(Xn|θn),Hy=sign(Yn|θn);
10. 通过样本新旧类标签项计算类相似矩阵Sn和So;
11. 根据公式(12)计算哈希编码生成约束损失Lh;
12. 根据公式(1)通过随机梯度下降更新参数θx,θy;
4 实 验
在本节中,使用纺织品面料数据集、Flickr25K数据集以及Pascal-sentences数据集来评估本文提出方法的性能,并将其与近年来最先进的几种算法进行对比.
4.1 数据准备
纺织品数据集从绍兴轻纺城图来旺网站采集30000张图像,主要是纺织品的图样图案.采集数据的主要方法是利用HTML/XML解析器BeautifulSoup进行网页解析和数据集下载,并按照规定格式进行数据整理.图像的注释描述中包含着相应的短语描述及类别标签.其中真实标签属性有32种,包括时装、男/女装等.为了实现增量样本迭代,本文将32项的标签集分为26项的旧标签集和6项的新标签集.将包含任一这6项标签集的所有样本当作新增样本集,其余的作为旧样本集,整理后的新旧类样本比为 4352∶25648.
Flickr25K数据集[17]包含25000个图文对,每个实例被24个类别标签标记,文本数据被表示为1386维度的词袋向量(BOW),图像特征由预训练模型VGG16预训练模型提取,其特征向量为4096维.本文将新旧标签项拆分为6∶18,整理后的新旧类样本比为8200∶16800.
Pascal-sentences数据集[18]分为20类,其数据集被广泛地应用于多标签分类的衡量标准,总共包含1000张图片,每张图片对应着5条文本描述,共有5000个图文对.数据集类标签包含4个大类:人、动物、车辆、室内.每个类别包含的样本数量相等,因此选用其中4个类别样本作为增量样本集,整理后的新旧类样本比为1000∶4000.
本文仅使用新增类样本数据集用以训练增量网络模型,样本同时拥有新旧类标签项.关于算法1的参数,本文设定迭代批次大小q=128.迭代次数为p为300次.学习速率初始值等于0.01.其中μ和α权值默认值为0.5.
4.2 方法比较
增量模型的设计是基于原有模型的扩展,本文选用DCMH跨模态哈希检索方法作为对比实验的基准模型,该方法是基于深度学习的跨模态哈希检索方法的开始.本文将所提出的增量模型ICMR与DCMH进行联合训练的方法进行实验.本文仅使用增量数据集对实验进行训练,选用近两年提出的跨模态增量网络模型与基准模型进行组合可得ECMH_DCMH[13],GrowBit_DCMH[14],ICMH_DCMH[2]以及本文提出方法ICMR_DCMH.在以下实验中,我们使用平均精度均值(MAP)和精确率召回率(PR)曲线来评估不同的方法.
为了表现增量模型在新旧数据集上的检索任务的对比,分别将DCMH方法和ICMR方法在新旧类样本集上进行检索精准度计算,在旧数据集上检索表示为Old Tasks和在增量数据集上检索表示为New Tasks.在方法比较中,将图像用V表示,文本用T表示.
评价标准:对于不同的数据集检索效果评价,可在图像检索文本(V→T)以及文本检索图像(T→V)上由查询集到被检索数据集合的检索效果来评价.本文使用的是平均精度均值(MAP)来度量检索的性能.
(13)
其中M是检索集中相关实例的数目,prec(r)表示top r 检索集中的检索精度.rel(r)是一个非0即1的函数,代表与不同级别r的相关性指标.PR曲线是以精准率和召回率这两个变量做出的曲线,其中recall为横坐标,precision为纵坐标.表示在不同级别的检索召回率下的准确率.
4.3 对比与评估
如上所述表1给出了所有方法在增量Flickr25K数据集和增量纺织品数据集以及Pascal-sentences数据集的两个跨模态检索任务和哈希编码从16到64位的MAP值.表2给出了DCMH深度跨模态哈希方法以及本文增量方法ICMR在新旧检索任务上的对比,图4给出了Flickr25K数据集和纺织品数据集对比实验的PR曲线图.其中对比实验哈希编码特征统一为32位.
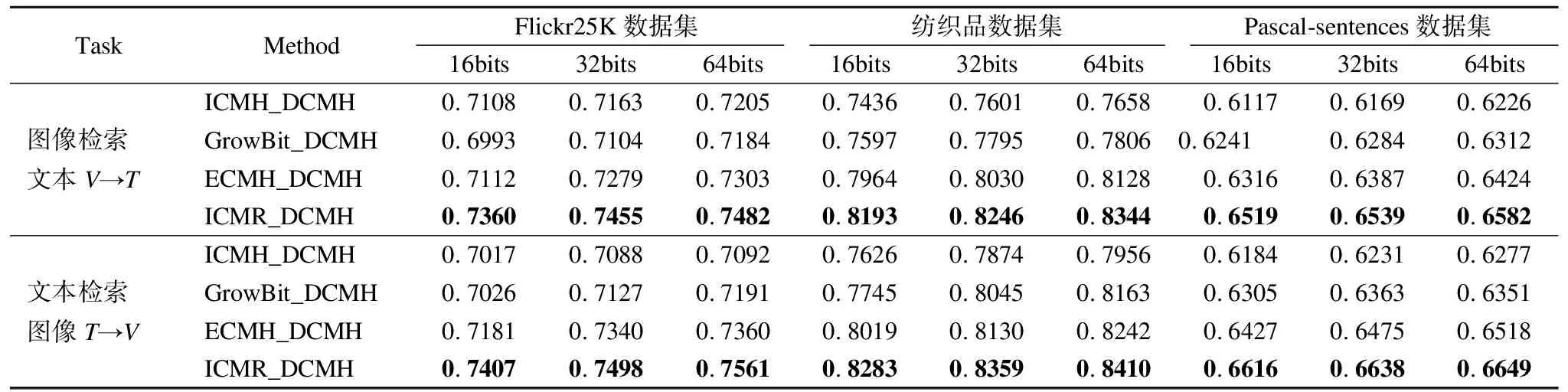
表1 增量学习方法平均精度均值(MAP)对比结果

表2 平均精度均值(MAP)在新旧任务上的对比结果
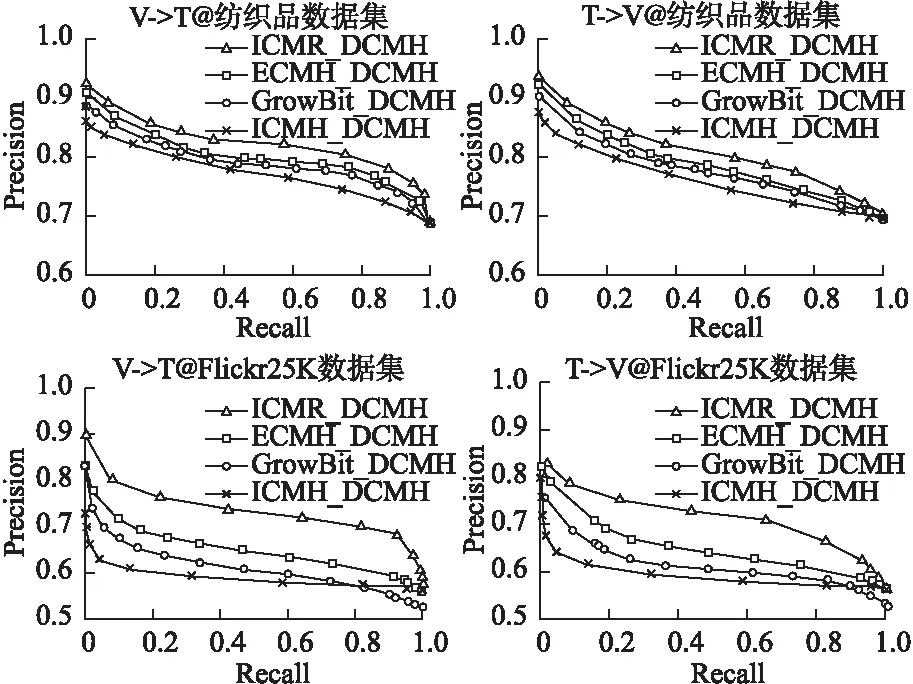
图4 增量学习方法在Flickr25K和纺织品数据集的PR曲线
从表1可以发现,本文提出的方法在大多数编码长度检索上的MAP值都高于其它方法,证明了本文提出的增量跨模态检索方法在面对数据样本增量迭代的场景下检索性能更优.其中和其他跨模态增量方法相比上本方法较其它的方法精准率高出2%-5%左右.
在表2中发现,ICMR方法在旧样本数据集上的检索精度较DCMH方法低,其差值保持在1%-2%左右,检索精度差别不大.这说明增量模型ICMR仍然保留了在旧样本数据集上的检索性能.同样在新样本数据集中,明显表现出DCMH跨模态检索模型的检索精度极大的降低,而ICMR在新样本数据集中保持了较高的检索精度.其中差距最显著的是DCMH与增量跨模态检索方法ICMR在Flickr25K新数据集上的检索精准率,其差值为9.32%.
从两表联合观察,因为DCMH是基于旧数据集训练得到的跨模态检索模型,在新增类数据集上因为新增的标签语义的缺失,DCMH模型在增量迭代数据集中检索精度性能上表现出不足.但是对比表1可以得出结论,基于DCMH的增量学习网络的组合,都使得扩展后的DCMH模型在新样本检索任务中精度得到提升,其精度提升区间为5%-10%.因此可以看出增量网络模型在训练学习过程中,通过跨模态知识蒸馏不仅有效的保留了旧样本数据集检索性能,还通过增量学习获得标签语义信息以及新增样本数据集样本之间的真实语义关系.
图4给出了在Flickr25K数据集和纺织品数据集上哈希编码为32位的两个跨模态检索任务的PR-Curve曲线,其值是根据检索结果的所属类检索命中率以及汉明排序产生.从各图的PR-Curve曲线可以看出,本文所提跨模态增量方法在不同的召回率下均获得了较其它方法更高的精度.
5 小 结
本文提出了增量跨模态检索方法.该方法仅使用新增类样本进行模型扩展.构建跨模态的知识蒸馏网络,目的是防止增量学习模型对旧数据集的灾难性遗忘.在生成不同模态哈希编码特征表示时,将新旧标签“共现概率矩阵”作为监督信息作用于增量模型学习,用以标识样本之间关于新增类标签的相似的可信度.实验结果表明,本文的算法在增量扩展上具有更好的检索性能表现.
下一步的工作我们将考虑成对模态数据的细粒度特征表现,通过有效的细粒度成对语义特征匹配从而提高检索系统中的检索性能.
