一种提升细粒度日志解析准确度的方法
2021-02-28葛志辉李陶深
葛志辉,邱 晨,李陶深,叶 进
(广西大学 计算机与电子信息学院,南宁 530004)
1 引 言
在当今不断变化的数字世界中,几乎所有的计算系统都被设计成将其运行状态、环境变化、配置修改和错误等信息记录到某种事件日志中(例如系统日志或应用程序日志).日志被开发人员和操作人员广泛用于确保系统可靠性,因为它们通常是在生产环境中记录详细的系统运行时信息的唯一可用数据,每一个字段包括事件的发生时间、级别和任务执行的状态等运行时的信息.原始日志消息通常是非结构化的,要实现日志分析,第一步也是最重要的一步是日志解析[1],这是一个将自由文本原始日志消息解析为结构化事件和事件分类的过程.随着现代系统的规模和复杂性的不断增加,日志的数量也在快速增长,每小时以GB级别的速度增长[2].目前许多最近的研究以及工业解决方案,已经发展到提供强大的文本搜索和基于机器学习的分析功能,具有较高的解析准确度.然而,对于大多数系统日志存在不同比例的细粒度日志,现有的日志解析器无法正确解析这些日志,导致整体解析准确度不高的问题.例如:分布式系统日志HDFS的事件等长率占比为93%,以此对应的可变长度日志占比为7%,因为这些解析器选取日志长度作为粗分类的特征,导致不同长度但具有相同事件的日志相互分离,造成额外的事件分类;此外,在计算日志相似度时也容易忽略日志的状态变量带来的影响,该系统日志有19%的错误合并事件,造成必要事件的减少.因此,如何正确分类细粒度日志以提升自动化日志解析的整体准确度成为一个备受关注的重要研究问题.我们提出一个结合常量令牌长度特征的决策树解析模型,在完成日志分类的基础上提升细粒度日志解析的有效性,从而提高解析器整体的准确度,这有利于后续使用相关机器学习算法进行日志分析.
2 相关研究
为了实现日志自动化解析,提升日志解析准确度,学术界和工业界提出了许多数据驱动方法,能够从日志数据中学习模式并自动生成公共事件模板[3].主要分为聚类和迭代分区方法.Cheng等人[4]结合Canopy聚类和K-means聚类算法用于提升错误日志的分类方法,Zhong和Guo[5]改进logSig聚类算法以提升解析准确度.然而聚类算法需要计算每个日志文本之间的距离,时间开销巨大,而迭代分区技术在运行时间上更为高效.迭代分区技术将所有日志消息聚集到粗分区中,然后迭代地划分粗分区,以创建所有日志消息都对应于单个模板的集群.LKE算法[6]使用层次聚类技术,通过计算每对日志消息的编辑距离来创建初始集群,这使得这个过程在内存和计算利用率方面都非常昂贵,并且无法在有限的时间内处理数据量较大的任务;IPLoM算法[7]根据行中的令牌数量创建初始集群,它们进一步识别在给定位置出现最频繁的令牌,并在这些令牌位置上分割集群,此方法在运行效率上具有优势,但是整体解析准确度偏低;Spell算法[8]使用前缀树划分日志集群,在计算文本相似度和事件生成时使用最长公共子序列算法(LCS),但没有限制前缀树的深度,LCS容易导致过度分区,在事件较多的日志集中也存在准确度不高的情况;Drain算法[9]使用结合日志长度的固定深度树来表示日志消息,并有效地提取通用模板,然而没有考虑细粒度日志的存在,在事件等长占比率低、事件数较多的日志集中存在解析准确度不高的情况.在日志解析中,细粒度日志分类是解析器的一大难点,目前考虑细粒度日志划分的日志解析研究相对较少.对于提升整体解析准确度而言,研究细粒度日志划分有着重要意义.
另一类工作为提升细粒度日志分类的研究.POP算法[10]的结构与Drain类似,它还使用层次聚类进一步将相似的事件合并,虽然获得了目前解析器最高的整体水平,仍没有解决状态变量导致的细粒度日志错误合并.Guo[11]采用离线层次化解析来实现不同粒度下的日志解析,以及改进的基本签名生成算法来确保状态变量保持低熵,剥离需要考虑状态变量的日志,但是额外的模型势必造成额外的时间开销,不能确保在一个模型中解决多个粒度日志的问题.因此,提出一种用于日志解析的结合常量令牌长度特征的决策树方法,用于解决长度可变的或含有状态变量的细粒度日志划分问题.
3 CLDT日志解析模型
本文设计一个结合常量令牌长度特征的树状结构(CLDT,decision tree with constant lenth)来帮助日志组的搜索.模型主要包括数据预处理、决策树搜索、相似度计算与事件生成、更新决策树.其中,常量令牌指的是日志文本中的不变部分,而状态变量属于不含参数的可变部分.
3.1 按照常量令牌长度搜索
大部分解析方法基于这样的假设:具有相同日志事件的日志消息可能具有相同的日志消息长度.然而,即便具有不等长度的日志消息也可能属于同一事件.这使得具有可变长度的同一类型日志相互分离.在此步骤中,决策树选择常量令牌长度(conLen,Constant token length)作为日志消息的特征,使用conLen可以有效合并具有可变长度的日志类型,因为它们日志长度不同,但conLen却是相同的.对于包含n个令牌T的日志序列seq={T1,T2,T3,…,Tn},conLen表示为式(1):
(1)
其中,c表示常量令牌,ρ表示变量令牌.
3.2 按照常量令牌搜索
状态变量在系统日志中尤为重要,具有不同状态变量的日志往往不属于同一类型.传统的解析方法将状态变量归为含参变量来处理,这会导致具有不同状态的日志归为同一类.通常状态变量的形式与常量令牌相同,借助常量令牌的搜索可以有效地保留状态变量.具体地说,决策树制定参数特征,通过日志消息开始位置的标记选择下一个搜索节点,当遇到匹配参数特征的令牌时会略过此令牌的搜索,只对常量令牌以及常量形式的状态变量进行搜索.这一步有效地保留了状态变量,以防错误的事件合并.如图1所示:‘PacketResponder 1 for block <*> terminating’和‘PacketResponder 0 for block <*> Interrupted’,这两类日志很容易合并,它们都有4个常量令牌,如果树的深度为6层(包括根节点和叶节点2层),决策树根据常量令牌‘PacketResponder’、‘fo’、‘block’及对应的状态变量来指导搜索过程,‘terminating’和‘Interrupted’因此得到保留.
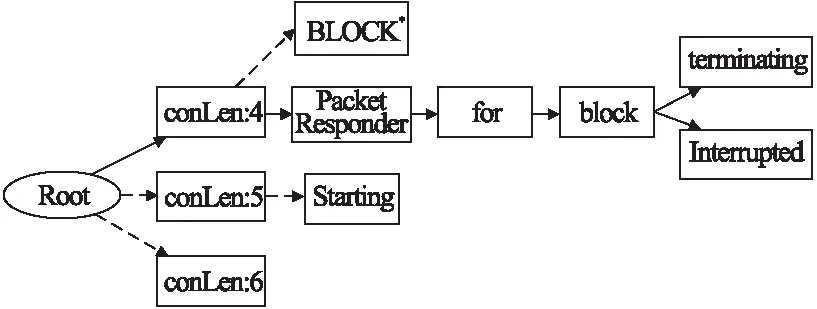
图1 一棵深度为6的决策树
3.3 改进的相似度计算
其他解析方法通常考虑完整的日志消息与事件模板的相似度,然而相似度会受到参数变量的影响,通常不会对日志分类有太大的帮助.在此步骤中,决策树考虑常量令牌并计算日志消息与事件模板的相似度logSim,确定日志的最终归类.logSim的定义如式(2)所示:
(2)
其中event和log分别表示日志事件和日志消息;event(i)表示事件模板的第i个常量令牌;log(i)表示日志消息的第i个常量令牌;n表示常量令牌比较的次数;函数comToken定义如式(3)所示:
(3)
其中tc1和tc2分别表示event和log的常量令牌.如图2所示,在找到logSim最大的日志组之后,将其与预定义的相似阈值st进行比较.如果logSim≥st,决策树将这一日志消息添加到该日志组.否则,决策树将新建一个日志组.
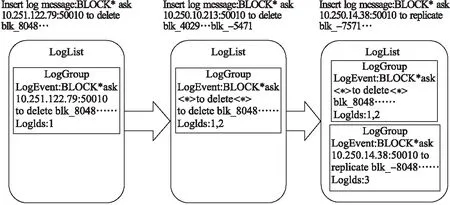
图2 事件生成
3.4 更新决策树
如图3所示,每当决策树学习新的日志,决策树从根节点遍历到应该包含新日志组的叶子节点,并相应地沿着路径添加缺少的conLen节点、常量令牌节点和叶子节点.

图3 更新决策树
本文提出一种面向细粒度日志的CLDT解析模型.操作步骤如下:Begin
Step 1.设置全局变量、树的深度和相似度阈值;
Step 2.日志切割、使用正则表达式将日志消息进行预处理;
Step 3.计算日志消息的常量令牌长度,若决策树存在该长度节点,执行Step 3.1,否则执行Step 3.2;
Step 3.1选择对应的第一层长度节点;
Step 3.2创建对应的长度节点;
Step 4.常量令牌与节点匹配搜索,若存在节点,则执行Step 4.1,否则执行Step 4.2;
Step 4.1匹配完毕后选择到下一层节点,重复执行Step 4;
Step 4.2创建对应的搜索节点;
Step 5.日志消息抵达叶节点,计算日志与列表中每个日志组事件模板的相似度,若最大相似度大于阈值,执行Step 5.1,否则执行Step 5.2;
Step 5.1日志消息与最大相似度的日志组以频繁项生成事件模板;
Step 5.2在此列表中生成新的日志组,事件模板就是此日志消息.
End
4 实验结果
4.1 评价指标
4.1.1 F-measure
使用F-measure这一典型的算法评价指标来评价日志解析方法.F-measure的定义如下:
(4)
其中精度(Precision)和召回率(Recall)定义如下:
(5)
其中,真阳性(TP,True Positive)表示将两个具有相同事件的日志消息分配给相同的日志组;假阳性(FP,False Positive)表示将两个具有不同事件的日志消息分配给同一个日志组;假阴性(FN,False Negative)表示将两个具有相同事件的日志消息分配给不同的日志组.
4.1.2 Accuracy
准确度(Accuracy)指标定义为正确解析的日志消息与日志消息总数的比值[3].当且仅当日志消息的事件模板与真实数据(ground truth)对应的同一组日志消息相同时,日志消息才被认为是正确解析的.Accuracy的定义如下:
(6)
其中,假阴性(TN,True Negative)表示将两个具有不相同事件的日志消息分配给不同的日志组.
4.2 实验设置
采用HPC、Zookeeper、HDFS数据集[3](如表1所示)进行实验,首先通过小样本数据来综合评价解析器的Precision、Recall、F-measure、Accuracy;然后在不同规模的数据集中(如表2所示)比较CLDT、Drain、Spell、IPLoM的准确度和运行效率来评估解析器的性能.参数涉及树的深度(depth)和相似度阈值(st),经过大量测试,对于不同日志集,决策树参数设置如表3所示.

表1 日志集描述

表2 数据集的大小划分(单位:条)

表3 CLDT解析方法的参数设置
4.3 模型评价
我们的评估中从每个数据集随机抽取2k日志消息.在很多情况下,现有日志解析器的准确度都大于0.8.此外,HDFS数据集的整体准确率高于HPC.我们发现,这主要是因为HPC日志涉及的事件类型要多得多,并且与HDFS、Zookeeper相比,它们具有更多不同的日志长度范围.
实验结果如图4所示,观察到CLDT为所有这些数据集提供了最佳的解析准确度.对于日志事件相对较少的数据集HDFS,其解析精度为1.00,这意味着所有日志都可以被正确解析.对于具有相对较多日志事件的数据集,CL-DT仍然提供非常高的解析精度,HPC为0.9775.CLDT具有最佳的解析准确度,原因有两点:首先,可以根据领域知识手动提取日志中某些特有属性,减少解析过程的噪音;其次,CLDT根据常量令牌长度特征将日志划分到合适的组,解决了不同长度的日志消息可能属于同一事件导致无法正确分类的问题,并且借助常量令牌搜索来划分状态变量,以防具有不同状态变量的日志错误合并.与其他具有相似结构的决策树解析器相比,CLDT提供了更细粒度的划分.

图4 解析方法在3种数据集的测试评价
4.4 日志解析方法的准确度
先在小样本数据集上进行参数调优,并直接将它们应用于大型数据.将完整的原始数据集划分为15个不同规模的数据集.
实验结果如图5所示,从实验中观察到CLDT对于所有数据集的准确性是非常一致的,即便在小样本数据上调优参数也能在所有数据集上一致获得高准确度.对于HDFS、Zookeeper,5个规模的数据集上的准确度都达到了0.99.对于HPC,CLDT最小准确度达到了0.9197.观察到CLDT在这类日志数据集上准确度表现出一定的波动.在75k数据量上,细粒度日志占比约0.53,CLDT和Drain能够保证较好的准确度.Spell基于LCS匹配日志与模板,LCS算法容易出现过度区分长度不同的日志与模板,仅能够正确解析部分含参数变量的日志;IPLoM根据日志长度、令牌位置和映射关系将消息划分为多个组,Drain结合日志长度和有限令牌将消息划分为多个组,然而日志长度特征对于可变长度和含状态变量的日志都不能保证良好的解析准确度;由于CLDT限制了决策树的深度,在限定层内可以很好的区分状态变量,常量令牌数量一旦超过树的深度时,CLDT不能区分后续的状态变量.但随着数据量增大(375k的HPC细粒度日志仅为0.14),各解析算法的准确度逐渐提升.现有的解析算法即便在小规模数据集中具有较高的解析准确度,但是在不同规模数据下仍存在缺陷.与最先进的解析算法Drain相比,CLDT在不同规模的数据集中具有良好的稳定性和较高的准确度.

图5 解析方法在3种数据集的准确度
在15个采样数据集上测量这些日志解析器的效率.本文中的效率是指用于运行日志解析器的时间.日志大小对本文解析方法运行时间的影响结果如图6所示.日志解析运行时间随着日志大小的增加而增加,并且增长幅度逐渐增加,因为它们的运行时间主要依赖于日志事件的数量和日志长度等因素,解析过程中的正则表达式匹配、日志划分匹配、相似度计算和模板生成等每个阶段的效率也各不相同.

图6 解析方法在3种数据集的运行效率
4.5 日志解析方法的效率
这些解析方法在日志划分匹配过程中均采用决策树结构.Drain的时间复杂度为O((d+cL)n),其中d为解析树的深度,c为叶节点中候选日志组的数量,L为日志的令牌数,n为日志消息的数量,d、L、c都可看做常数.而CLDT在搜索时需要判断令牌类别,与Drain的时间复杂度类似,为O((d+c·conLen)n+conLen);IPLoM的结构同样类似,但是需要将所有日志消息加载到计算机内存中,在处理大规模的日志数据时效果欠佳.因此,上述3个解析算法的时间复杂度均为O(n).对于Spell,采用LCS算法并依赖于比较日志的每个令牌,时间复杂度为O(L1·L2),其中L1和L2分别为日志的令牌数.通过计算日志消息和日志候选事件之间的令牌相似性,相比于LCS可以大幅度降低运行时间,时间复杂度为O(L1+L2),由于CLDT更具细粒度的划分,每个日志组的事件数和令牌比较次数更少,因而此阶段的运行效率更高.对于不同的日志解析器,每个阶段的运行时间各具优势和不足,但总体而言,它们均采用决策树结构来划分日志,所以效率是相似的.
5 结 语
本文提出了结合常量令牌长度特征的决策树的日志解析模型,在保证一定的执行效率下,解决细粒度日志影响整体解析准确度的问题,进一步提升日志解析的准确度.实验结果表明,该模型在HDFS、HPC、Zookeeper这3类日志集中获得准确度提升,与同类解析器相比,具有较高的准确度,运行时间相当.然而,本文提出的模型未考虑参数字段的语义,识别参数语义能够帮助用户理解日志.未来的研究可以结合自然语言处理技术来识别参数语义.
