基于互信息F统计量特征选择技术的地基气象云图分类
2021-02-27杨秋良杨杏丽李济洪
杨秋良,王 钰,杨杏丽,李济洪
(1.山西大学数学科学学院,山西 太原 030006; 2.山西大学现代教育技术学院,山西 太原 030006)
0 引 言
云对天气与气候变化有着非常重要的指示作用,准确获取云的信息对社会、经济、军事等各方面都有很大的意义。当前,对云的观测主要有卫星云观测和地基云观测2种方式。其中,地基云图观测由于它在局部云观测中的及时性和准确性而备受关注。特别地,地基云图观测中的一个重要参数是云状(云类),云状的正确识别在理解数值天气预报、分析气候条件及大气环流模式中都起着十分关键的作用[1-3]。
实际上,地基云图是一类特殊的自然纹理图像,地基云图云状识别就是机器学习中的图像分类。针对地基云状识别地基可见光云图的特殊自然纹理特性,已有文献提出了多种纹理特征提取方法来对地基云图云状识别进行研究,例如旋转不变的纹理特征、Gabor小波变换、灰度共生矩阵等。然而,这些方法有的仅对图像的绝对纹理位置信息进行了编码,有的仅拥有旋转不变的特性[4]。为此,文献[5]提出了具有旋转不变性和直方图均衡化不变性的局部二值模式(Local Binary Pattern, LBP)描述子,由于该方法的简单有效,使其得到了广泛的扩展和应用,尤其是在地基云图的研究中。比如,文献[6]把LBP方法应用到人脸识别的任务中,提出了更加稳健的局部三值LTP(Local Ternary Pattern)描述子;文献[7]指出传统的LBP方法只使用了符号向量信息,忽略了绝对值和中心像素本身的信息,为此提出了一种融合这3种信息的完整LBP方法,即CLBP(Completed Local Binary Pattern)方法;文献[8]提出了基于主要LBP模式的DLBP(Dominant Local Binary Pattern)特征抽取算法;在DLBP方法的基础上,文献[9]提出了一种面向地基可见光云图分类的显著性特征提取方法SaLBP(Stable Local Binary Pattern);文献[4]通过融合地基云图复杂的自然纹理特性提出了一种稳定的LBP特征提取方法。其他相关方法见文献[10-15]。
虽然传统LBP方法在自然纹理图像的分析中广泛使用,但是原始LBP特征向量的维数(远远)大于样本量[16-20],此时,如果直接基于所有的LBP特征进行分类,计算开销会非常大,而且分类的精度也会大大下降。另外,上述提到的所有LBP类特征选择方法皆是直接基于LBP原始特征进行特征的选择,没有利用云类的信息,显然这是不合适的。因此,本文考虑使用互信息度量融合云图的类别信息来进行LBP特征的选择。
具体地,本文通过计算每个LBP特征和类别变量之间的互信息构造了一个F检验统计量,并利用前向搜索的思想进行特征选择。本文提出的特征选择算法不仅考虑了特征之间的冗余,使用简单方便,而且所选出的特征个数要远远少于直接基于互信息的最大相关性准则选出的特征个数,在降低计算开销的同时也使得分类性能得到显著的改进。
1 基于互信息F统计量的特征选择算法
1.1 LBP描述子
对于纹理图像分类,常常假定测试样本和训练样本具有相同的空间尺度、方位和灰度。然而,在现实中,纹理可能发生在任意的旋转和空间分辨率中,同时它们很容易受到光照变化的影响。因此,文献[5]提出了一种基于LBP模式的灰度和旋转不变的描述子。这个方法是基于灰度来描述图像纹理特征的不相关算子,主要刻画了中心像素点的灰度相对于其领域内像素点的灰度的变化情况。
具体地,中心像素的灰度值记为hc,其周围半径为R(R>0)的圆上的q个近邻像素值为hq,q=0,1,…,Q-1,那么LBP操作算子的具体形式如下:
(1)
其中,

式(1)中s(x)表示中心像素hc与其近邻像素hq之间的差值符号,LBP描述子就是用差值符号,即0、1的二进制编码来代替它们精确的灰度值,然后对每个符号s(hq-hc)分配权值因子2q,从而转化成十进制LBP值,就得到了一个对灰度的任意单调变换都不变的LBP描述子。
当图像旋转时,hq的像素值也随之移动,这将导致式(1)所计算的LBP的值也不一样,为了消除这种旋转的影响,定义一个如下形式的旋转不变的LBP描述子:
(2)
1.2 互信息度量
在概率和信息论中,互信息是对2个事件集合之间的相关性(mutual dependence)的度量,它决定着联合分布与边缘分布的乘积的相似程度。
对于2个离散随机变量X和Y之间的互信息有如下定义:
(3)
当随机变量X、Y存在连续随机变量时,上述互信息公式的求和符号被替换成二重定积分:
(4)
其中,公式(3)中p(x,y)是离散随机变量X和Y的联合分布列,而p(x)和p(y)分别是它们的边际分布列,公式(4)中的p(x,y)是连续随机变量X和Y的联合密度函数,而p(x)和p(y)分别是它们的边际密度函数[21]。
1.3 基于互信息的最大相关性(Max-Relevance)准则
基于互信息的特征选择的目标是在包含有M个特征的特征集合中找到一个含有m(m≤M)个特征{xi}(i=1,2,…,m)的特征集合S,使得其与目标类y有最大的相关性,即最大相关性准则(Max-Relevance),文献[21]给出了如下的表示形式:
其中,i=1,2,…,m,I(xi,y)为xi与y之间的互信息度量。
然而,注意到上述基于互信息的最大相关性准则在进行特征选择中只是简单地要求特征与类别变量间的互信息最大,没有考虑特征之间的冗余,同时在高维数据中,该方法所选出来的特征数量很多且计算开销非常大,为此本文提出一种基于互信息的F检验统计量特征选择方法。
1.4 基于互信息构造的F检验统计量的特征选择算法
(5)
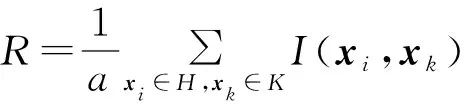
前向搜索法是一个进行特征筛选行之有效的数学方法。本文应用前向搜索法的思想给出互信息构造的F检验统计量的特征选择算法过程,具体如下:
算法1基于互信息构造的F检验统计量的特征选择算法
输入:全部特征向量{xi}(i=1,2,…,p);
类别向量y;
经F检验被选入的有效特征集合的指标集A;
经F检验未被入选的无效特征集合的指标集N;
集合N的特征个数b;
集合A的特征个数a;
显著水平δ。
过程:
1A=空集;t=空集;N=全部特征的指标集;a=0;b=p;δ=0.15
2 foriinNdo
3 ifa<1 then
4R=0
5 else
6R=第i个特征与特征指标集A中所对应的所有特征之间的互信息的均值
7 end if
8t(i)=相应的式(5)的F值
9 end for
10F=t中最大的值
11 ifF>对应的1-δ分位数的值then
12A=F对应的特征指标集并入A中
13N=F对应的特征指标集从N中剔除
14b=b-1
15 接着重复执行步骤2~步骤11
16 elseA=A;N=N;
17 end if
输出:选入的特征集合的指标集A;未选入的特征集合指标集N。
2 实验分析
本文选用有5个类别的云图数据集来比较旋转不变LBP(其中q=16,r=2)、基于互信息最大相关性准则和本文所提出的基于互信息构造的F统计量这3种特征选择方法的性能。为了对这3种特征选择方法进行评价,分别选用支持向量机(SVM)、决策树(rpart)和朴素贝叶斯(NB)这3种分类器作为学习算法,计算云图的分类精度,且每个分类器都给出了二折、五折、十折交叉验证的结果。
2.1 实验设置
2.1.1 实验数据
地基气象云图分类数据集SWIMCAT(Singapore Whole-sky Imaging CATegories Database)是这个领域的很多文献中广泛用于性能评价的一个基准数据集,本文基于这个数据集进行整个实验的分析。所有的图片都是2013年1月到2014年5月这17个月之间在新加坡拍摄的。图像的分辨率都是125×125像素,格式为PNG格式。这个云图数据集共有784个图片方块,包含了晴空、厚黑云、厚白云、模式云和薄云这5种不同的天气条件。使用了550幅图片(包含157幅晴空云图,176幅厚黑云云图,95幅厚白云云图,61幅模式云云图,60幅薄云云图)[26]进行实验分析。为了方便,晴空云、厚黑云、厚白云、模式云和薄云这5类云图分别用数字1、2、3、4、5来表示。
对于上述5类云图来说,在用LBP方法提取特征时,若从图像中提取到的LBP的模式是“00000000”(共q个0),那么它是用来检测图像中的亮点,则这个特征对于区分第三类和第五类云类有重要的作用;若LBP模式是“11111111”(共q个1),那么它是用来检测图像中的黑点;若LBP的模式是“11110000”(即一半是1另一半是0),那么它是用来检测图像中的边,则这个特征对于区分第二类和第四类云类有重要的作用。
2.1.2 2个连续变量间的互信息的估计
在本文提出的特征选择算法中,F统计量是基于互信息构造的,因此互信息的计算对于算法来说是非常重要的。如式(4)所示,当x和y至少有一个变量是连续变量时,它们之间的互信息I(xi,y)很难直接求解,因为它需要通过计算连续空间的积分来进行。一般地,常用的方法包含2种:1)先对数据进行离散化处理,然后基于式(3)进行互信息的计算;2)采用密度估计的方法来计算连续变量间的互信息。显然离散化数据处理的方式会引起信息太多损失,因此本文采用文献[21]提出的密度估计的方法,下面给出这2种方法的实验对照。
具体地,已知变量x的N个样本,估计密度函数p(x)有如下形式:
(6)
其中ω(·)的形式如下表示:
(7)
其中,x(i)是第i个样本,h是带宽,X=x-x(i),d是样本x的维数,∑是x的协方差矩阵。当d=1时,利用式(6)估计出来的值是边缘密度;当d=2时,可以利用式(6)估计二元变量(x,y)的密度,即x和y的联合概率密度p(x,y)。
下面,本文给出离散和连续这2种互信息计算方法在五折交叉验证下使用2.1.1节提供的云图数据集上的云状分类精度对照。在同样的数据样本上,分别利用离散、连续变量的互信息计算方法求每个特征与类别变量的互信息,然后进行降序排列,选取前100个特征利用支持向量机(SVM)在五折交叉验证下分别计算2组特征在每一折以及五折平均上的分类精度,结果如表1所示。

表1 L_MI与C_MI的分类精度比较 单位:%
表1中L_MI与C_MI分别表示离散互信息估计方法与连续互信息估计方法。
由表1可以看出,相同的数据经过离散互信息操作之后得到的分类准确率要比连续互信息估计方法计算的分类准确率平均低了21.1个百分点。因此,采用离散互信息的方法可能在实际中是不合适的,它将导致很大的信息损失,而采用连续互信息的估计方法可以有效地改进互信息的计算。
2.2 实验结果分析
2.2.1 特征数量
首先,给出本文提出的基于互信息构造的F统计量的特征选择算法与基于互信息的最大相关性准则在3种不同的分类器下所选择的特征数量的结果,见表2。
由表2可以看到本文提出算法所选择的特征是30个。而基于互信息的最大相关性准则特征个数的确定是和分类器相关联的,它在分类器支持向量机(SVM)、决策树(rpart)和朴素贝叶斯(NB)下所选择的特征数量分别是1758、768、1299个。即本文提出的算法所选择的特征个数要远远小于基于互信息的最大相关性准则选择的特征个数,具有更小的计算开销。下一节将看到本文方法有更高的分类准确率。另外,旋转不变LBP从云图中所提取的特征个数是4116个。

表2 F_add与M_MI所选的特征数 单位:个
表2中F_add、M_MI_SVM、M_MI_rpart、M_MI_NB分别表示基于互信息构造的F统计量、基于互信息的最大相关性在分类器SVM、rpart、NB下的方法。
2.2.2 分类精度
本节给出了本文方法、最大相关性准则方法以及原始LBP特征提取方法在支持向量机、决策树、朴素贝叶斯3个分类器上的二折、五折、十折交叉验证下每一类以及5类平均的分类准确率的结果,见表3~表8。
首先,在表3的SVM分类器下,本文方法的准确率在二折交叉验证下第二类的准确率达到了100%,而旋转不变LBP的准确率却是0。在第五类上,本文方法的准确率高出基于互信息最大相关性的准确率18.3个百分点。同时在五折、十折交叉验证上也有类似的结论。实验结果显示,本文方法的准确率在二折、五折、十折交叉验证的5类样本上平均的总精度分别是80.9%±0.1%、82.5%±0.2%、83.0%±0.4%,都显著优于旋转不变LBP方法的20.0%±0.0%、20.0%±0.0%、20.0%±0.0%和基于互信息的最大相关性方法的77.7%±0.3%、80.5%±0.3%、81.1%±0.3%。

表3 在SVM分类器上3种方法在不同类别上的准确率 单位:%
表3中,LBP_ri、F_add、M_MI分别表示旋转不变LBP、基于互信息构造的F统计量、基于互信息的最大相关性的方法。
如表4所示,在二折、五折、十折交叉的每一折上本文方法的分类性能都是最好的,旋转不变LBP方法的分类性能最差,在每个折上本文方法的平均准确率较旋转不变LBP方法大约都提升了50个百分点,虽然较基于互信息的最大相关性方法提升了大约1个百分点,但是本文方法是显著优于基于互信息的最大相关性方法的。例如在二折交叉验证上本文方法、旋转不变LBP的方法、基于互信息最大相关性的方法的平均分类准确率分别是77.7%±0.1%、28.5%±0.2%和76.7%±0.1%。

表4 在SVM分类器上3种方法在不同折数上的准确率 单位:%
在表5、表6的决策树分类器下,总的分类情况与在支持向量机分类器下是类似的。本文方法在这3类折数的交叉验证上的第一、三、五类的准确率都是最高的,分别高出大约2~5个百分点。
除了十折交叉验证中的第五折其他每个交叉验证的每一折上本文方法的分类性能也都是最好的,而在每个折上本文方法的平均准确率较旋转不变LBP、基于互信息的最大相关性方法都提升了大约2个百分点。例如在二折交叉验证上本文方法、旋转不变LBP的方法、基于互信息最大相关性的方法的平均分类准确率分别是74.8%±0.0%、72.4%±0.1%和72.7%±0.1%。

表5 在rpart分类器上3种方法在不同类别上的准确率 单位:%

表6 在rpart分类器上3种方法在不同折数上的准确率 单位:%
最后,在表7、表8的朴素贝叶斯分类器下,本文方法的准确率在三类交叉验证的五类平均总精度上依然都是最优的,这一点与前2个分类器是一样的。其中本文方法在二折、五折、十折交叉验证的第二类上的分类准确率分别达到了99.6%、100.0%和100.0%。

表7 在NB分类器上3种方法在不同类别上的准确率 单位:%

表8 在NB分类器上3种方法在不同折数上的准确率 单位:%
在二折、五折、十折交叉验证下,本文方法的分类准确率比旋转不变LBP的每一折以及平均精度上都高出约38个百分点,虽然在二折交叉验证下比基于互信息的最大相关性方法上只高了0.4个百分点,但是本文方法的准确率是73.5%±0.0%,显著优于基于互信息的最大相关性方法的73.1%±0.1%。虽然在五折交叉验证下基于互信息的最大相关性方法的准确率73.7%±0.3%要优于本文方法的准确率73.6%±0.2%,但这个差异却不是显著的。在十折交叉验证下本文方法和基于互信息最大相关性的方法是没有显著差异的。
3 结束语
针对地基气象云图的传统特征选择方法皆是直接基于图像特征本身进行特征选择,完全没有利用云的类别信息,本文基于互信息将特征变量与类别变量融合进行特征的选择,提出了一种基于互信息构造的F检验统计量的特征选择算法。在多个分类器上的实验表明,本文方法大大降低了计算开销且云图云状识别的性能显著提高。
虽然本文方法相对于其他方法在地基云图的云状识别性能上有显著改进,但是总体的分类性能还是有很大的提升空间的,为此,笔者下一步将考虑融合LBP的多尺度特征来进行分类性能的进一步提升,以及进一步考察本文方法在噪声图像和其他云图数据集上的鲁棒性。
