时间图查询在实验设备管理中应用
2021-02-27黄金晶
黄金晶, 赵 雷
(1.苏州工业职业技术学院软件与服务外包学院,江苏苏州215104;2.苏州大学计算机科学与技术学院,江苏苏州215006)
0 引 言
实验室中存放大量的实验设备和实验仪器,合理有效的管理这些设备和仪器将大大提高它们的利用率。近年来,随着实验设备的不断更新,这给实验室管理人员的工作带来了一定的困难,如何对实验设备、实验仪器进行更高效的管理是一个值得深入研究的问题。
本文从图的角度出发,将实验设备、管理员、使用者等对象抽象成图的节点,使用者、管理员与设备之间的关系抽象成图中节点的边,使用者在特定时间段里使用了设备,将时间段设置成边上的时间区间,进而将设备管理抽象成对时间图数据管理,图1 所示的为实验设备时间图。为了方便描述,将图1 中的年份设定为2020 年。在图1 中,从节点“李桐”有箭头指向“设备A”,箭头上标注了“使用”,时间为“3 月7 日9:00~9:45”,说明“李桐”在3 月7 日的9:00 ~9:45 使用了“设备A”。当管理员需要了解“李桐”3 月7 日使用了哪些设备的时候,其实就是要执行一个查询。本文利用了图匹配技术,从时间图中匹配出相关的查询结果,并将其运用于实验设备的管理中,能够快速地在众多对象与设备的关系中,找出所需要的信息。

图1 设备时间图
1 相关研究现状
图匹配一般分为子图同构和子图模拟2 种。子图同构[1]是一个NP 问题,它要求从数据图中找到和查询图完全一致的子图,对图的拓扑结构有严格的要求。Ullmann[2]是典型的基于图结构的匹配方法,GraphGrep[3]是经典的基于路径查询的图匹配算法,GIndex[4]算法是对频繁子图建立索引帮助快速的查找子图。事实上子图同构往往很难匹配到完全一致的结果,近年来,学者们从不同的角度进行了图的近似查询,即子图模拟[5],它允许匹配的结果与查询图之间存在一定差别,比如SUBDUE[6]和SAPPER[7]等。随着图规模的增大,传统的图匹配技术不能有效的匹配出结果,文献[8-10]中是使用了分布式技术进行图匹配,文献[11-12]则是利用了top-k技术查询出符合要求的前k个结果,满足实际应用。在动态图匹配研究上,文献[13-14]中主要采用增量处理技术,对新增数据进行匹配。在时间图匹配上,文献[15-16]中研究了有时间限制关系的图匹配,本文主要研究时间图上包含时间关系的查询,将查询转换为查询图,利用时间图的匹配找到相关结果,并将其应用于实验设备的管理中。
2 问题定义
下面给出本文所述问题的相关定义。
定义1时间图G。给定一个时间图G ={V,LV,E,LE,TE},其中V 是图中点的集合;LV是点的标签集合;E 是图中全部边的集合;LE是边上的关系标签集合;TE为边上关系存在的时间集合,TE中的每个元素都是一个时间段[ts,te],ts为起始时间,te为终止时间,若te为“*”表示至今。
定义2查询图Q。给定一个查询图,其中Q ={V,LV,E,LE,TE},V =Vl∪Vp是查询图中点的集合,Vl是查询图中已知的点,Vp是查询图中待查的点;LV是点的标签集合,若LV=“?”表示对应的V 点为待查询的点;E是图中全部边的集合,LE是边上的标签集合,若LE=“?”表示对应边上的关系为待查询的关系;TE为查询图中给定的时间集合。
定义3时间匹配。给定一个查询图Q中的时间段为[tqs,tqe],时间图G 中的时间段为[ts,te],[ts,te]能形成[tqs,tqe]的匹配需满足[ts,te]和[tqs,tqe]重合或者部分重合,即符合如下3 种情况之一:
①ts≤tqs≤te≤tqe;②ts≤tqs≤tqe≤te;③tqs≤ts≤tqe≤te。
定义4单元查询图QU。QU≤Q,QU只包含2 个点V1和V2、连接这两个点的边、边上的关系和时间段。若Vi=“?”(i =1,2),则Vi为待查询的点;LE= “?”表示连接V1和V2边上的关系为待查的。
图2 所示的为单元查询图示例。图2(a)表示在时间图中查询3 月7 日9:00 ~11:00 间李桐是否使用过设备A。单元查询图中的“?”表示待查的元素,可以是点,也可以是边上的关系,图2(b)和2(c)表示单个的节点是未知元素,分别查询谁在3 月7 日9:00 ~11:00 使用了“设备A”以及“李桐”在3 月7 日9:00 ~11:00 使用了什么设备。图2(d)表示单个的节点和边上的关系都是未知元素,即查询3 月7 日9:00 ~11:00 设备A经历了哪些操作。图2(e)表示查询节点之间的关系,即查询“李桐”在3 月7 日9:00 ~11:00对“设备A”做了哪些操作。图2(f)所示的只有关系是已知的,2 个节点的值都是未知的,即查询3 月7 日9:00 ~11:00 哪些人使用了哪些设备。
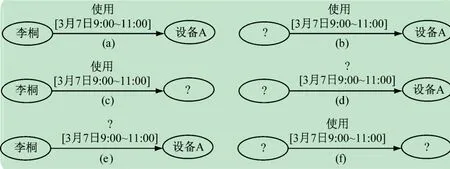
图2 单元查询图
定义5单元匹配。单元查询图QU在G中的匹配结果称为单元匹配。对于一个给定的时间图G,一个单元匹配图QU,R 是G 的一个子集,令QU的点集为{V1,V2},R的点集为{U1,U2},若R 是Q 的一个单元匹配要满足:
①LU1=LV1,LU2=LV2;
② 如果V1和V2之间存在边e1,那么U1和U2之间也存在边e2,且Le1=Le2;
③如果边e1上的时间段为Te1,e2上的时间段为Te2,那么Te1和Te2是匹配的。
定义6完全匹配M。给定一个时间图G,一个查询图Q,M⊆G,令Q的点集为{V1,V2,…,Vn},M的点集为{U1,U2,…,Un},那么M是Q的一个完全匹配需要满足的条件:
① ∀Vi∈Q,∃Ui∈M,且LUi=LVi;
② 如果Vi和Vj之间存在边ev,那么Ui和Uj之间也存在边eu,且Lev=Leu;
③如果边ev上的时间段为Tev,eu上的时间段为Teu,那么Tev和Teu是匹配的。
根据上述的定义,本文的问题定义为:给定一个查询图Q,在时间图G中找到全部的完全匹配结果,形成结果集R = {M1,M2,…,Mn}。
3 查询过程
3.1 朴素匹配算法(NM)
朴素匹配算法(Naive Matching)将查询图分解成若干个单元查询图,并进行单元匹配,而后将单元查询的结果进行合并。
对图3(a)所示的是时间图1 的一个查询图,NM算法将其分解成了3 个单元查询图,如图3(b)所示。对单元查询图的图(1)来说,查询“范新”在3 月7 日的7:00 ~16:30 期间检修了什么设备,匹配的结果分别为{{范新,检修,设备A,[3 月7 日7:30,3 月7 日8:30]},{范新,检修,设备B,[3 月7 日16:00,3 月7日16:30]}}。单元查询图(2)需要查询2 月5 日之后的相关采购信息,节点均是未知的,根据边上的关系进行匹配,匹配的结果为{{设备B,采购于,公司A,[2月5 日9:00,*]},{设备C,采购于,公司B,[2 月20日10:00,*}}。同样,单元查询(3)要查询“王楠”3月7 日9:30 到12:15 之间使用设备的情况,查询结果为{{王楠,使用,设备B,[3 月7 日9:30,3 月7 日10:00]},{王楠,使用,设备C,[3 月7 日10:15,3 月7 日11:00]}}。最后,将单元匹配的结果进行合并,最终结果为{{范新,检修,设备B,[3 月7 日16:00,3月7 日16:30]},{设备B,采购于,公司A,[2 月5日9:00,*],{王楠,使用,设备B,[3 月7 日9:30,3月7 日10:00]}}。很显然,这种方法需要进行大量的重复匹配,匹配完毕后的合并也需要耗费较多的时间,计算量大,是一种朴素匹配方法。
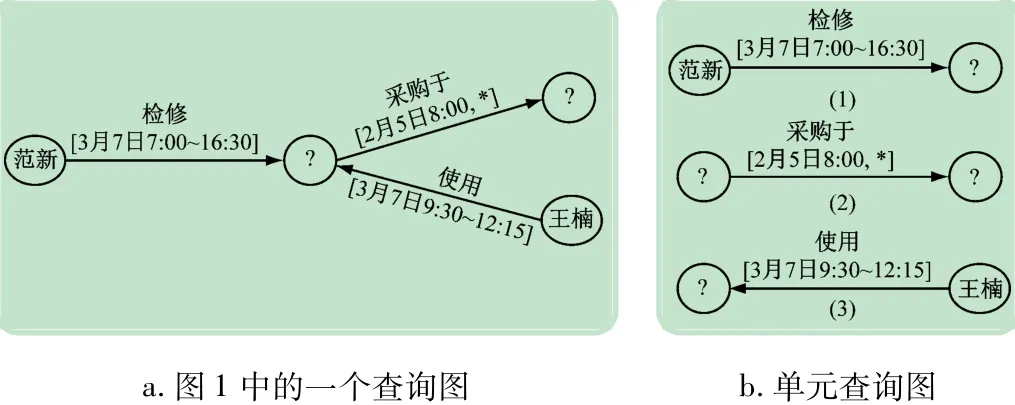
图3 查询图与单元查询图示例
3.2 基于BFS的点匹配算法(BVM)
由于朴素匹配算法需要对单元匹配进行合并,耗时较多,BVM(BFS-Vertex Matching)算法利用了BFS遍历图中点的方法依次遍历查询图中的点,在此过程中进行单元匹配。
(1)算法思想。
①选择一个入度为0 的点,作为初始节点V0。
②在V0和其相邻点Vi之间进行单元匹配。
③根据BFS算法选择下一个节点进行单元匹配,直到全部的节点匹配结束。

A l g o r i t h m 1 B V M(G,Q)/ /G为时间图,Q为查询图1.v i s i t[V 0]=1;q.p u s h(V 0);R = Ø;2.w h i l e(!q.e m p t y()){3.V 1 =q.p o p();4.f o r每个和V 1相邻的节点V i{5.若V 1和V i之间没有进行过单元匹配,则R =U n i t m a p(V 1,V i,e,t)∪R;6.i f(v i s i t[V i]≠1){7.q.p u s h(V i);v i s i t[V i]=1;8.}9.}1 0.}1 1.r e t u r n R;
(2)实例说明。以图3(a)的查询图为例,对BVM算法进行说明。
①节点“范新”入度为0,作为初始节点,单元查询图为图3(b)中的(1)图,匹配出“设备A”和“设备B”。
②对单元查询图3(b)中的(2)图进行匹配,根据第一步的匹配结果,查询图变更为图4 所示。

图4 更新后的查询图1
设备A在时间图中没有匹配到采购信息,将其删去。设备B采购于公司A。
③查询到设备B后,继续匹配,单元查询图如图5所示。查询得到“王楠”在3 月7 日9:30 ~10:00 使用了设备B。

图5 更新后的查询图2
BVM算法相较于NM算法而言,BVM算法在匹配过程中就进行了合并,减少了大量不必要的匹配,因而算法执行的效率要高于NM算法。
3.3 拓扑剪枝匹配算法(TPM)
尽管BVM算法运行的效率要高于NM算法,但是在包含大量数据的时间图中一一进行单元匹配的效率也不高,本节提出一种TPM(Topological Pruning Matching)算法,该算法从拓扑结构和语义角度出发,在匹配过程中进行剪枝,大大加快了查询的效率。
定义7拓扑单元匹配。对于一个给定的时间图G,一个单元匹配图QU,R⊆G,令QU的点集为{V1,V2},R的点集为{U1,U2},Ui.o 代表节点Ui在时间图G 中的出度,Ui.i 代表节点Ui在时间图G 中的入度,Vi.o代表节点Vi在查询图Q 中的出度,Vi.i 代表节点Vi在查询图Q中的入度,如果R是Q的一个匹配要满足:
①LU1=LV1,LU2=LV2;
② 如果从V1到V2有边e1,那么从U1到U2也有边e2,且Le1=Le2;
③ 对于待查节点Vi,Ui.i≥Vi.i,Ui.o≥Vi.o;
④ 对于待查节点Vi,令EVO和EVi分别为Vi在Q 中所有指出去的边和指向Vi的边上关系的集合,EUO和EUi分别为Ui在G 中所有指出去的边和指向Ui的边上关系的集合,EVO⊆EUO,EVi⊆EUi。
⑤如果边e1上的时间段为Te1,e2上的时间段为Te2,那么Te1和Te2是匹配的。
(1)算法思想。①选择一个入度为0 的点,作为初始节点V0;② 在V0和其相邻点Vi之间进行拓扑单元匹配;③根据BFS算法选择下一个节点进行拓扑单元匹配,直到全部的节点匹配结束。
(2)索引构建。为了加快算法执行的效率,本文构建了TV-索引和TE-索引,分别用于快速的定位点和边上的关系,从而提高拓扑单元匹配的速度。图6、7所示分别为TV-索引和TE-索引结构图。
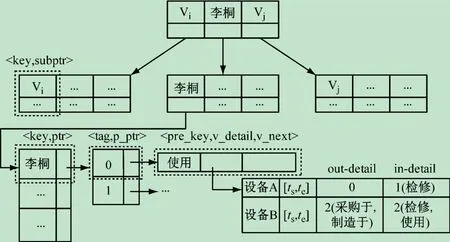
图6 TV-索引结构图
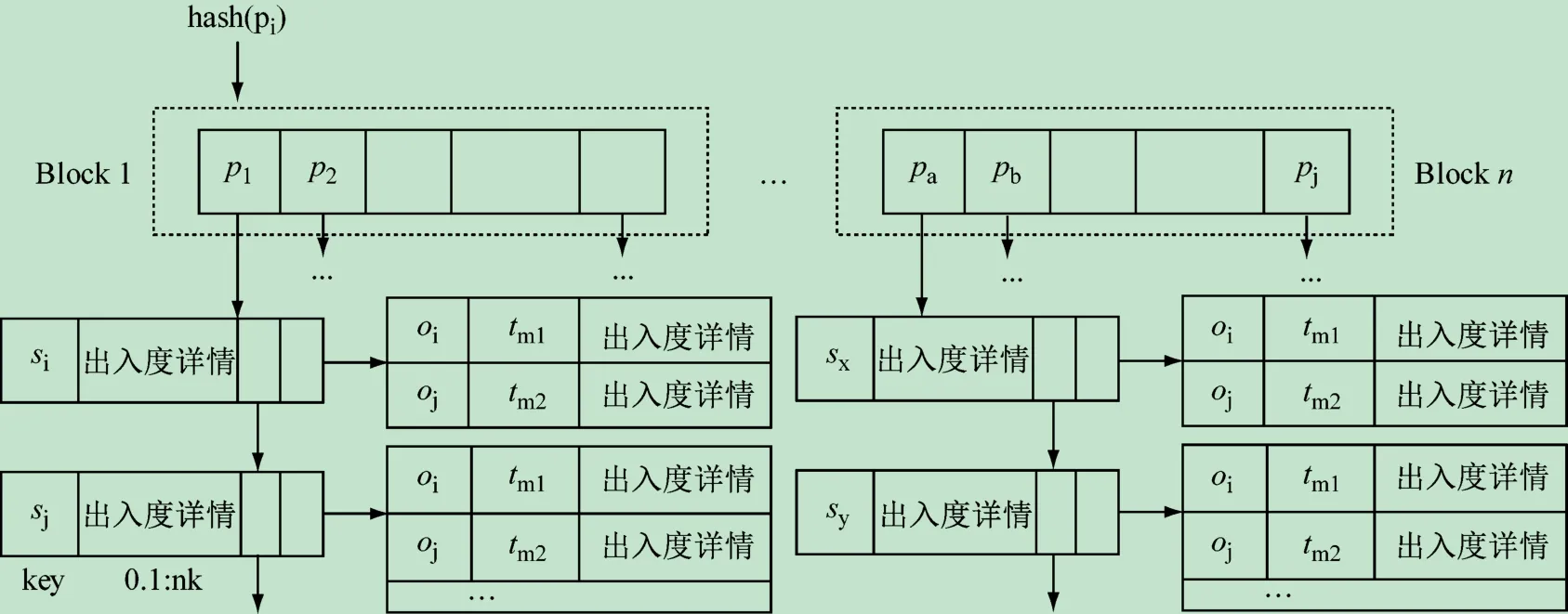
图7 TE-索引结构图
TV-索引是一个类B +树结构的索引。每一个叶子节点由key和ptr两项组成,其中key表示时间图中的节点标签值Vi,ptr指向两个链表,tag 为0 的链表中记录了Vi点所指向的节点Vj情况,包括Vj的标签值,关系上的时间,以及出入度详情out-detail 和in-detail。out-detail中记录了Vj点的出度,以及由Vj指出的边上的关系,in-detail 中记录了Vj的入度(除去Vi指向Vj的边),以及指向Vj的边上的关系(除去Vi指向Vj的边上的关系)。tag为1 的链表中记录了指向Vi点的节点情况。每个非叶子节点由key和subptr两项组成,key是节点的标签值,用于索引,subptr指向子树的根节点。
TE-索引能根据边上的关系查找到连接该边的两个节点。具体来说,给定一个关键字Pi,计算Pi的hash值,在对应的hash表中找到Pi,Pi中有指针指向链表,该链表的每一个项集中Si代表节点的标签,且该节点有指出去的边,边上的关系值是Pi,出入度详情同TV-索引中记录的内容一致。每一个Si节点都有一个指针指向一个数据块,记录了Si节点指向的节点Oi,且Si和Oi之间关系为Pi。在Oi中记录了Si指向Oi关系的时间段,以及Oi的出入度详情。
(3)实例说明。以图3(a)的查询图为例,对TPM算法进行说明。
节点“范新”入度为0,作为初始节点。图3(b)中的(1)图作为单元查询图,做单元拓扑匹配。根据查询图3(a),待查节点除去3(b)(1)图的边以外,入度和出度都为1,边上的关系分别为“采购于”和“使用”。根据TV-索引,定位到“范新”,很显然“设备A”出入度详情中记录的数据不符合拓扑单元匹配的要求,最终查找到“设备B”。根据同样的方法进行下面的匹配。

images/BZ_241_194_1510_1198_1577.png images/BZ_241_194_1577_1198_3267.png
很显然,加入了拓扑结构和关系上的语义后,使得不符合要求的数据在匹配过程中尽早剔除,大大减少了匹配次数。在TPM 算法中,构建了相关的索引,提高了算法运行的效率。
(4)拓扑单元匹配算法描述。算法2 对拓扑单元匹配算法进行了描述,其中区分了不同的单元查询图。
4 实 验
为了验证算法的正确性和有效性,本文在8GB 内存、I5-3470 处理器、3.2GB 主频的计算机上进行了相关实验。实验使用了3 个不同数量级大小的模拟数据集,如表1 所示。数据集中的点模拟了人、单位、设备、仪器等对象,边模拟了对象间的相互关系以及关系的时效。

表1 数据集描述
图8 所示为NM算法、BVM算法和TPM算法分别在D1、D2 和D3 数据集中运行的结果。从图8 可见,NM算法消耗的时间最多,BVM 算法次之,TPM 算法消耗的时间最少,这是由于在NM 算法中每次进行单元匹配后均需要合并,消费了大量的时间,TPM 算法在BVM算法的基础上加上了拓扑结构和边上语义的匹配,能将不符合条件的中间结果进行剪枝。
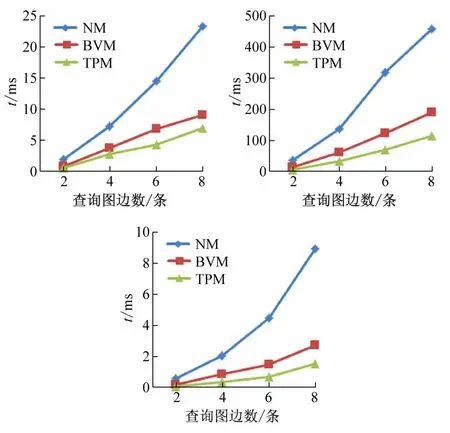
图8 三种算法在不同数据集中对比结果图
图9 所示为TPM 算法中确定的模式查询与Ullmann算法[2]和TCGPM-E 算法[15]进行的对比,从图中可以看出TPM算法优于Ullmann算法和TCGPME算法的性能,因为Ullmann 算法采用的是深度优先搜索策略,基于点结构的无索引匹配方式,TCGPM-E采用了基于边结构的图匹配方式,TPM算法构建了基于拓扑结构和边上语义的索引,加快了算法的运行效率。
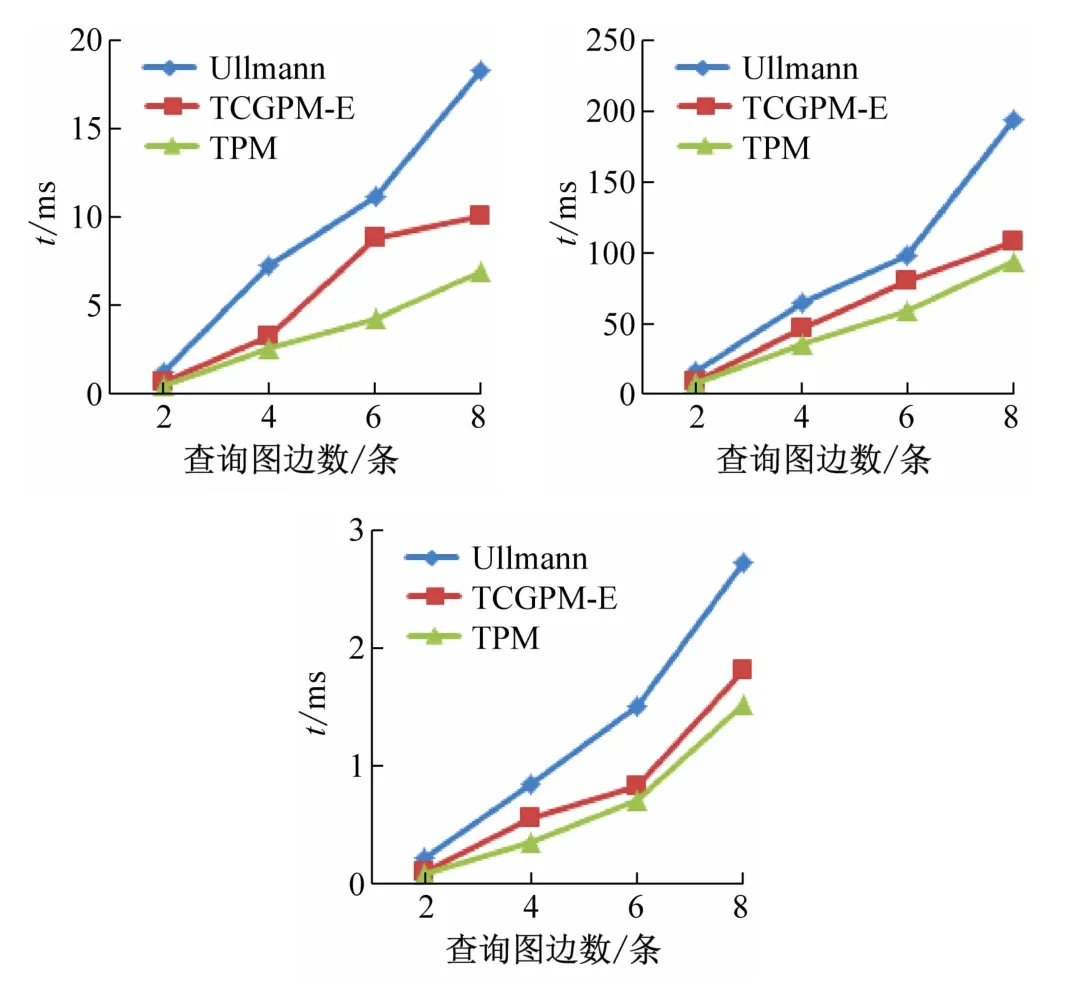
图9 TPM算法与其他算法对比结果图
5 结 语
本文利用时间图匹配技术实现对实验设备使用、维护、检修等情况的管理,将设备、单位、人等对象抽象成为时间图的节点,将使用等信息抽象成为时间图上的边和时间区间。本文提出了NM、BVM以及TPM算法用于查询图的匹配,并通过实验对比了3 种方法的性能。实验结果表明,TPM 的运行效果最好,这是由于TPM算法中运用了拓扑结构和语义匹配,因而能快速地进行剪枝。将TPM算法运用于设备管理,丰富了查询的语义,提高了查询效果。
