模型驱动的高性能计算集群配置管理
2021-02-27韦建文王一超文敏华林新华周子豪
韦建文, 王一超, 文敏华, 林新华, 周子豪
(上海交通大学网络信息中心,上海200240)
0 引 言
高性能计算集群是为求解大型计算问题、由多个节点通过高速网络连接而组成的集群,其能否有效工作很大程度上取决于集群中各节点是否处于协调一致的配置状态。集群节点从上架通电到下线退役发生的软件配置调整,都可归入配置管理的范畴,包括为节点初始化做的离线配置和不中断节点服务的在线配置。传统配置方法关注配置的具体操作,譬如“使用useradd命令添加用户”“用户已存在该如何处理”等。受限于命令式配置的建模能力,传统配置方法很难快速正确地将复杂系统配置到预期状态,而由此导致作业运行效率低甚至集群下线,将严重影响高性能计算集群的正常使用。
“基础设施即代码”(Infrastructure as Code,IaC)[1]是为解决复杂系统配置问题而提出的方法,其核心理念是专注表达配置的需求——即构建配置建模,具体烦琐的配置操作则由程序在模型驱动下完成。
以表1 所示的添加用户为例,配置建模使用“声明式”描述,相比配置过程使用的“命令式”描述,能更加简洁准确地表达配置意图。尽管由模型驱动的配置管理在云计算领域已获得广泛应用,但这项技术是否适合于物理机占比高、异构硬件数量多的高性能计算集群,仍需要进一步探索。

表1 “声明式”与“命令式”配置对比
上海交通大学高性能计算平台是国内规模最大的校级计算平台之一[2],已建成π1.0(2013 年上线)、π2.0(2019 年上线)两代集群,理论计算能力超过3PFlops,存储容量超过10 PB,配备CPU计算节点、多路胖节点、GPU计算节点等总计超过1 000 个物理节点,以及数十个虚拟管理节点。将这些节点配置成一个协同工作的集群,是一项很有挑战性的工作。本文介绍一种以配置模型为核心的高性能计算集群配置管理方法,包括:配置管理工具选型、Puppet特性、模型驱动的集群配置管理流程、配置时间对比和配置集群的流程展示。
1 配置管理工具选型
在“基础设施即代码”实践中,配置管理与编程解题有很多共同点。如图1 所示。
程序员使用高级语言编写程序代码,经编译器编译后得到可执行程序,执行后输出计算结果。类似地,管理员使用建模语言描述配置模型,经配置管理工具翻译后得到可执行脚本,执行后将目标节点配置到预期状态。程序员在选择编程工具链时会考察编程语言的表达能力、执行效率、第3 方库丰富程度以及对版本回溯等软件工程特性的支持。同样地,管理员选择配置管理工具时,也会重点考察建模能力、配置速度、模块数量、对版本回溯的支持和部署难度。
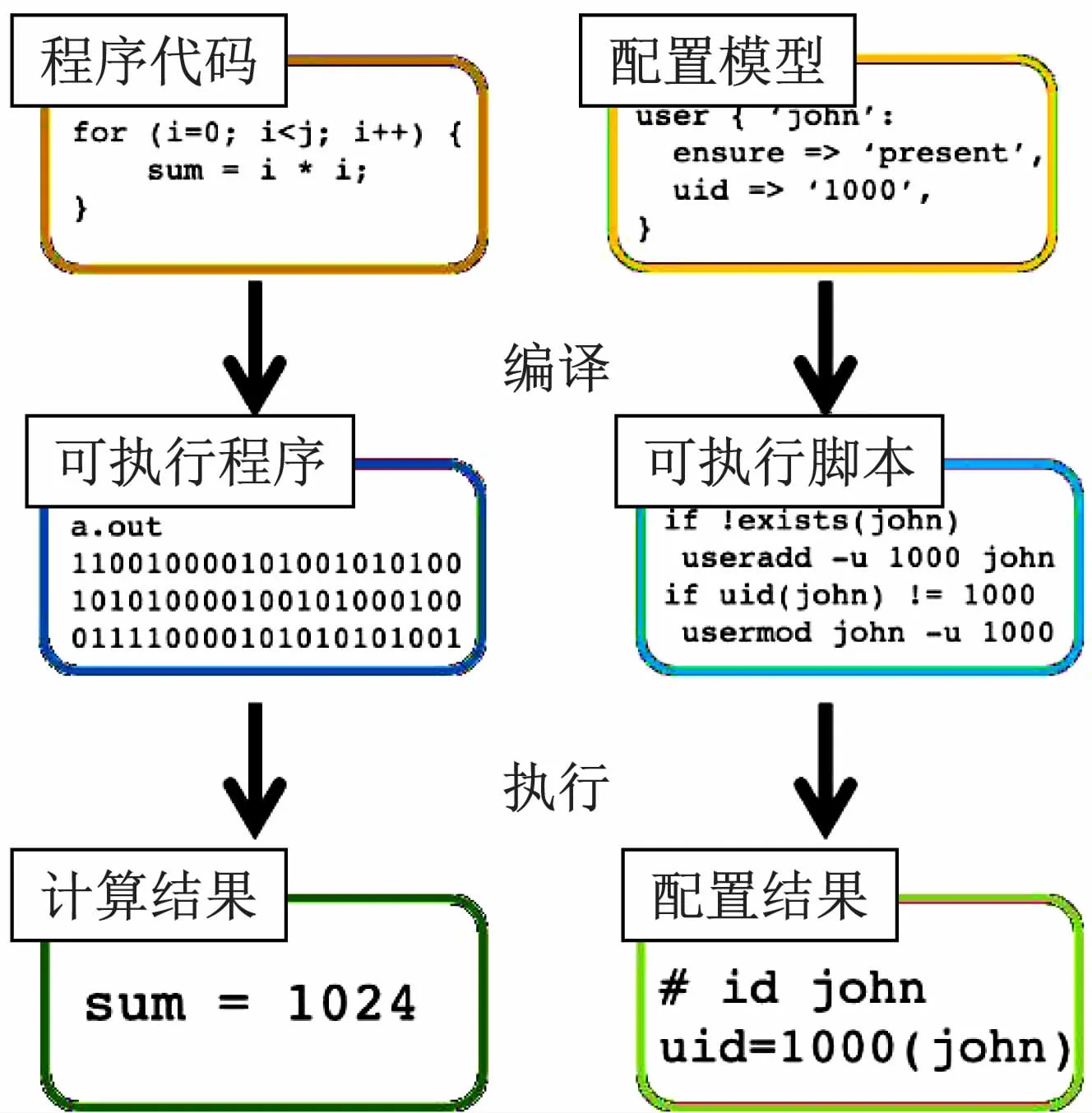
图1 配置管理执行流程
现有主流开源配置管理工具特性对比见表2。表中,Puppet使用了语法类似Ruby 的定制语言,具有很强的建模能力,又因为使用了独立的客户端所以配置速度快,庞大的社区提供了超过6 000 个模块,且可与git版本控制系统[7]整合提供变更回溯功能。尽管Puppet部署难度要比其他配置管理工具高,但其提供的层次化建模、逻辑与数据分离特性对管理复杂集群配置提供了极大的便利。

表2 主流开源配置管理系统对比
2 Puppet配置管理工具
Puppet配置管理工具的3 个主要组件如图2 所示,包括建模组件、主控节点和客户端。管理员使用建模组件构建的配置模型由主控节点编译后变成可执行脚本,客户端执行脚本把目标节点配置到预期状态。
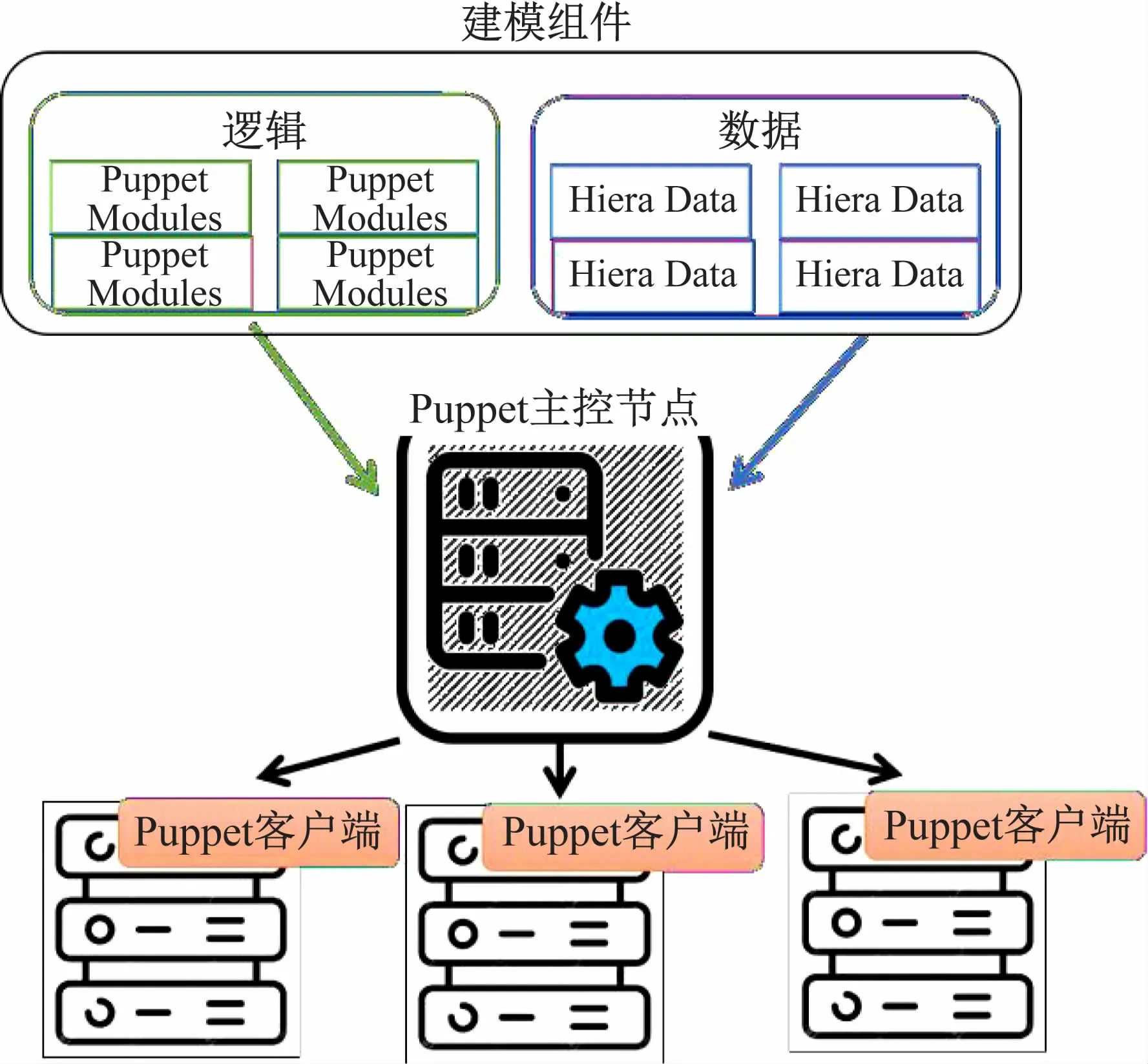
图2 Puppet配置管理系统组件
2.1 Puppet建模组件
Puppet的配置模型包含“逻辑”与“数据”两个要素,分别描述“配置什么”和“配置参数”。
模型的逻辑使用名为Puppet DSL 的特定领域描述语言(Domain Specific Language,DSL)描述。这个语言专为配置管理设计,不仅提供了完成基础配置所需的函数,如安装特定RPM包、启动特定服务等,还包含了用于构建复杂功能的语言特性,如变量、数据结构、条件分支等。Puppet 推荐使用名为“角色-剖绘”(Roles-Profiles)编码规范[8]把模型代码分散到多个文件中。这个编码规范使用角色和剖绘两层抽象,分别描述节点的功能(如compute、nameserver等)以及实现这些功能所需的软件栈(如slurm、bind 等)。部分具有共性功能的模型代码(如配置MySQL、SLURM)可发布在Puppet Forge 社区[9]或GitHub[10]供其他用户使用。Puppet社区提供的模块数量和质量一直在不断提高,已经积累了超过6 000 个模块,涵盖了高性能计算集群所需绝大部分软件栈。
Puppet使用名为Hiera 的程序组织模型中的数据。Hiera提供了从最细粒度的“节点”到最粗粒度“全局默认”之间多粒度层次化的参数匹配方法。Hiera可从节点角色、操作系统或其他特征搜索参数,并按照用户指定的优先级替换或合并参数,若搜索失败将使用默认的全局参数。Hiera 很好地处理了配置数据中“一般”与“特殊”的关系,通过多粒度参数汇聚避免重复配置在多处出现。Hiera 使用“逻辑”与“数据”分离的编程理念,使得敏感配置信息得以从配置逻辑中分离出来得到保护。
2.2 Puppet配置变更跟踪
Puppet提供了“文件”和“模型”两个级别的配置变更跟踪机制。在文件一级,Puppet 主控节点会备份file函数每一次对配置文件所做的修改,管理员可以查看、对比和恢复配置文件的历史记录。在模型一级,Puppet与git 集成,跟踪整个配置模型,即“逻辑+数据”的代码变更历史。管理员可使用“git 签出”抽取任意时刻的模型应用到目标节点,或使用“git分支”创造多个独立于生产环境的配置模型。Puppet配置变更跟踪机制是实现配置回溯和独立测试环境的基础。
3 使用Puppet配置高性能集群
使用Puppet建模组件构建了上海交大高性能计算集群的配置模型,并借助Puppet配置变更跟踪特性搭建了可回溯可测试的在线配置流程,结合Cobbler操作系统部署工具,搭建了无须人工干预的节点离线配置流程。
3.1 使用Puppet构建高性能计算集群的配置模型
按照Roles-Profiles 编码规范,集群节点的角色和所需软件栈见表3。

表3 节点角色分配表
具体地,lib/facter/role.rb配置文件通过正则表达式为其指定角色变量puppet_role 和计算节点子类型变量puppet_subtype,接着在角色文件中引入所需软件栈剖绘。从Puppet Forge和GitHub站点选取软件栈对应的模块加剖绘文件,并针对高性能计算领域特有的软硬件系统,如Omni-Path 网络[11]、SLURM 调度系统[12]编写了Puppet 扩展模块。Hiera 使用“角色(role)-子类(subtype)-节点(node)”的优先级顺序合并参数。git代码仓库的多个分支分别对应不同的测试环境,每个环境都可独立地分配“角色-剖绘”配置、使用其他外部模块、指派配置数据。
3.2 使用Puppet进行可回溯的在线配置
在线配置用于完成那些无须重启节点的维护操作,包括SLURM 队列设置、增加软件包、调整告警检查阈值等。
如图3 所示,基于生产环境的模型新建git测试环境分支,在这个分支上修改模型选择个别节点应用新模型,确认新配置模型工作正常后再将git分支的修改合并到生产环境分支。在所有节点上应用更新后的配置模型。在新的git 分支调试新模型时,可以使用git revert撤回某一个错误修改,或者用git checkout 回滚到某个历史状态,还可以使用puppet agent -t --environment production把测试分支的集群配置复位到生产环境状态,然后开启新的git 分支继续“开发-测试-合并”的流程。
3.3 使用Puppet进行无人值守离线配置
Cobbler[13]节点部署工具和Puppet 配置工具用于无人值守离线配置,可以一键完成节点上线的流程。离线配置适合重大更新,如操作系统大版本升级、更换节点角色等。
如图4 所示,首先,管理员通过IPMI设置目标节点通过PXE网络启动并重启节点,节点从Cobbler 服务器获得启动镜像和Kickstart文件[14],重新部署操作系统。然后,安装程序调用puppet 客户端在这个新部署的操作系统上配置其他服务组件。最后,安装程序退出,节点自动上线提供服务。经测试,这个流程可并发部署超过1 000 个物理机或虚拟机。通过调整Cobbler和Kickstart的设置,还可以定制每个节点使用的操作系统和分区方案。
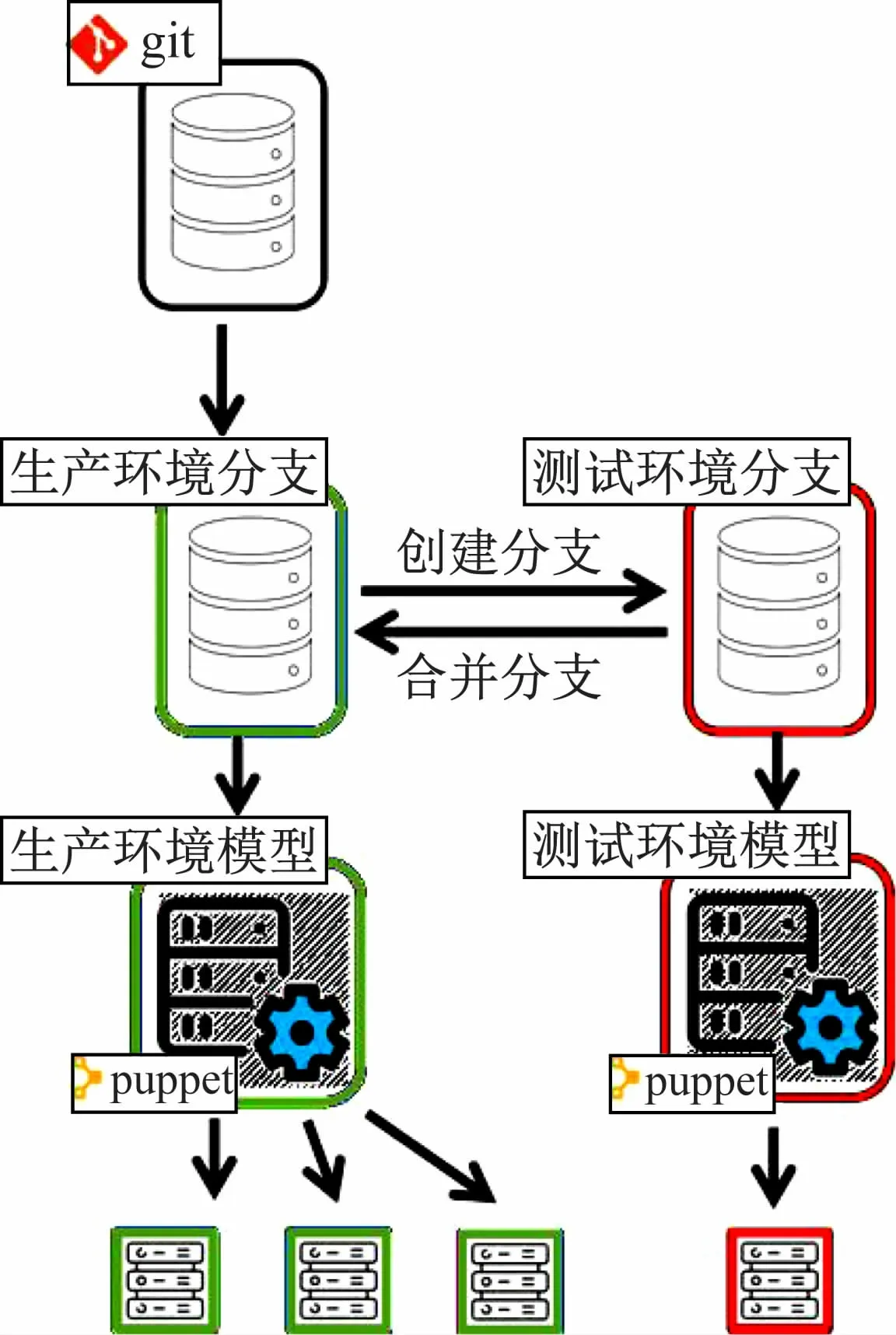
图3 在分支环境测试配置变更

图4 无人值守部署流程图
4 性能测试
4.1 配置时间对比
以“配置SLURM作业调度系统”和“配置一个新的节点”这两个任务为例,传统配置方法和模型驱动的Puppet方法的工作效率对比见表4。
模型驱动方法在准备阶段时间、执行阶段时间和需要撰写代码行数均优于传统配置方法。传统配置方法在“配置SLURM 调度系统”时,需要单独为slurmctld、slurmdbd、slurmd 这几个服务维护内容相似的配置文件,并配置相应的MUNGE、SSSD等服务;Puppet配置方法则可以共享SLURM 主要配置信息,并直接使用现成的SLURM、MUGNE、SSSD 配置模块。传统配置方法在“配置一个新的节点”时,需要额外编写配置流程,或在操作系统部署后人工运行配置程序;Puppet配置方法则可完全复用已有的配置流程,只需在Kickstart 文件末尾加入一行调用puppet 客户端的代码。除此以外,模型驱动的配置方法引入了模块化设计、变更追溯等软件工程方法,使管理员能够像发布软件一样,保障质量地进行配置变更,这是传统配置方法做不到的。

表4 模型驱动配置和传统配置方法对比
4.2 使用Puppet部署一个高性能计算集群
图5 展示了使用模型驱动的配置方法部署一个高性能计算集群的主要过程和耗时。
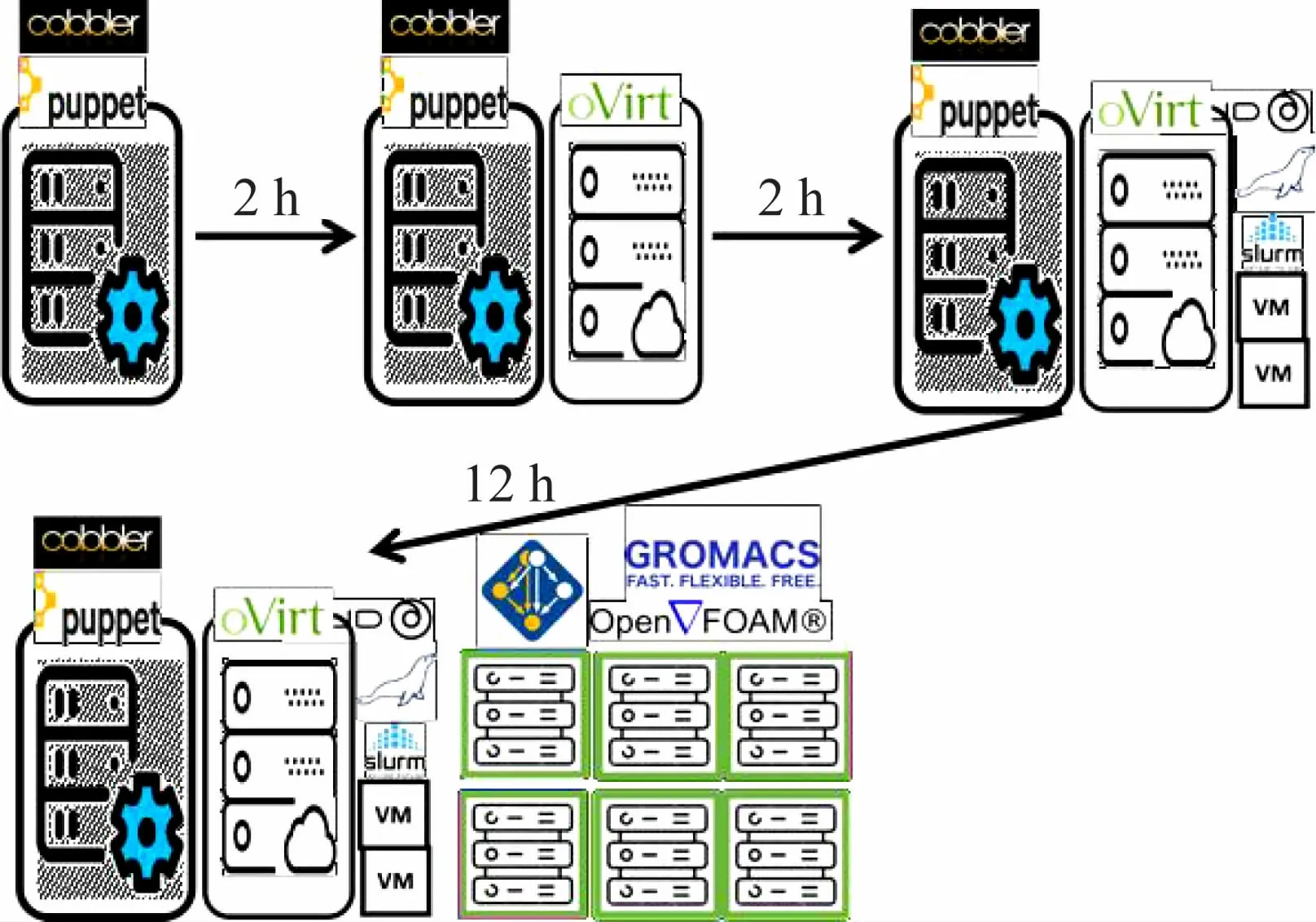
图5 集群配置主要流程图
在管理节点物理机上安装Cobbler 部署服务和Puppet主控节点服务;在管理节点安装Ovirt虚拟机管理器服务[15],另选一台服务器安装Ovirt宿主机服务;新建Ovirt虚拟机承载集群内的Bind 域名解析、Squid代理、MariaDB数据库、SLURM 主控节点服务;批量为计算节点部署和配置系统,与此同时使用Spack 软件包管理器为集群安装编译器、MPI 库、数学库等工具。传统部署方法最耗时的操作系统安装和系统配置部分,被Puppet +Cobbler 无人值守部署流程替代,使得部署一个包含几十甚至上千计算节点集群的时间,从1 周缩短到了一天。
5 结 语
传统“命令式”配置方法建模能力受限,不能胜任日益复杂的高性能计算集群配置任务。借鉴“基础设施即代码”的思想,将配置问题转换为建模问题。在以模型为核心的配置管理中,管理员专注编写配置模型,具体的配置操作交由模型驱动的程序执行。这套方法在开源Puppet配置管理工具基础上实现,并加入了模块划分、逻辑-数据分离、变更追溯等特性提高配置的执行效率、通用性和正确性。这套方法支撑了上海交大校级高性能计算平台超过1 000 个节点的配置,极大缩短在线配置、离线部署的时间,为开发新的服务内容提供了便利的测试流程。后续将整合“连续集成”技术用于自动验证和应用配置,进一步将管理员从烦琐重复的运维工作中解放出来。
