考虑变量相关性的正交异性板细节疲劳可靠性评估
2021-02-26张海萍冯东明
张海萍, 刘 扬, 邓 扬, 冯东明
(1. 湖南工业大学 土木工程学院,湖南 株洲 412007; 2. 长沙理工大学 土木工程学院,长沙 410114;3. 北京建筑大学 土木与交通工程学院,北京 100044; 4. 纽约威丁格运输管理局,纽约 10027)
近年来,随着大跨度桥梁健康监测系统的迅速发展[1-2],使得桥梁结构实测应变数据得到了大量的积累[3]。研究人员基于桥梁健康监测数据开展正交异性板主梁细节疲劳耐久性研究[4]。
Liu等[5]提出了基于应变数据的疲劳可靠度功能函数的建模方法。Deng等[6]探讨了基于应变监测数据的钢箱梁焊接细节点疲劳可靠度功能函数变量的概率模型及其取值。疲劳可靠度功能函数主要由疲劳强度变量和疲劳效应变量两种不同性质的变量组成。对于疲劳强度变量,可参考美国和英国的钢结构疲劳规范(AASHTO规范[7]和BS5400规范[8])。对于疲劳效应变量,则是依据实测应变数据构建概率模型。实测应变数据包含了所有外界荷载对桥梁的扰动,涵盖了随机干扰、温度和车辆荷载信息等。为剔除无用干扰数据,需要对获取的数据信号进行分离。现有的研究工作中,一般假设疲劳效应变量相互独立,缺少对监测数据深入挖掘和探讨。Liu等[9]分别从不同角度论述了温度对疲劳应力大小和循环次数的影响。疲劳应力与循环次数存在一定的相关性,在疲劳可靠度计算过程中不可忽视。
在工程学中,直接建立相关性变量的多维联合概率模型有一定难度。难点在于变量之间的相关性结构难以明确以及多重积分求解复杂。线性相关系数(皮尔逊系数、斯皮尔曼系数等)和非线性相关函数(指数函数、幂函数等)用于表征变量之间的确定性相关性结构,难以描述实际工程变量的时变和模糊特性。提出一种能够适用于工程疲劳可靠性研究领域多元联合概率分布建模的简易方法显得十分重要。Copula理论将复杂多维变量的联合分布建模分解成各变量边缘分布建模和Copula函数的选择及其参数的评估。近几年,Copula函数在土木工程领域也有了初步的发展,如Tang等[10]采用Gaussian Copula函数建立桩基荷载-位移曲线参数的联合分布函数,还讨论了5类典型Copula函数构建地震位移极值和残余位移值的相关性模型。考虑变量相关性疲劳可靠性评估的本质问题归结于如何在有限的信息条件下构建相关性变量的联合分布模型。Copula函数相比较传统联合分布建模方法具有较强的优势,变量之间相关结构的准确解析是选择最优Copula函数的关键所在。
综上所述,本文引入Copula函数建立钢箱梁正交异性板焊接细节的疲劳可靠性联合概率密度功能函数。讨论5类Copula函数的性质以及其适用范围。从根本上解决了多维联合概率分布函数建模和可靠度指标的计算的问题。
1 基于实测应变数据可靠度功能函数
1.1 可靠性功能函数
工程结构为满足使用要求,材料的抗力R在服役期需大于结构所受的荷载效应S。当两者相等时,表明结构处于安全与危险的临界状态。表达式为
g(X)=R-S=0
(1)
式中:g(X)为结构的临界状态方程;X={X1,X2,…,Xn}为变量矩阵,包含所有的抗力和荷载变量。基于现有疲劳规范和Miner线性准则,可将材料的疲劳可靠性功能函数表达式(1)改写为
(2)
式中:A为正交异性板焊接细节疲劳强度系数;B为疲劳强度曲线的指数参数; 在欧洲规范中取值为3; Δ为疲劳线性累计损伤的临界破坏值;e为应变传感器的测量误差变量,陈永高等的研究给出了应变传感器的误差变量的取值,e的均值和变异系数分别取1.0和0.3; 参数Seq为疲劳等效应力幅值; 参数Nm为桥梁服役m年内结构受等效应力幅Seq的作用大小。等效应力幅和循环次数的表达式分别为
(3)
(4)
式中:Si为第i个监测应力幅值大小;ni为应力循环大小为Si的循环次数;α为年交通增长率;Tm为桥梁的服役年限。依据式(2)~式(4)可得疲劳可靠度功能函数表达式
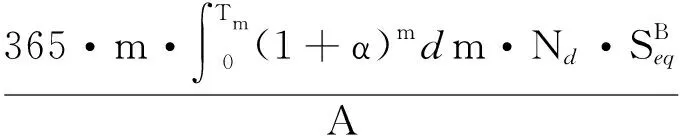
(5)
基于应变监测数据的细节疲劳可靠度功能函数相对简单,疲劳应变数据可以直接监测,疲劳寿命评估结果更为可靠。式(5)中除疲劳应力和荷载循环次数两类变量,其他变量的分布类型和参数取值如表1所示。表1中疲劳损伤指标、疲劳强度系数和传感器误差均为对应文献的研究学者通过试验得到实测样本数据,并通过实测样本数据概率分布特征拟合得到最优理论模型。
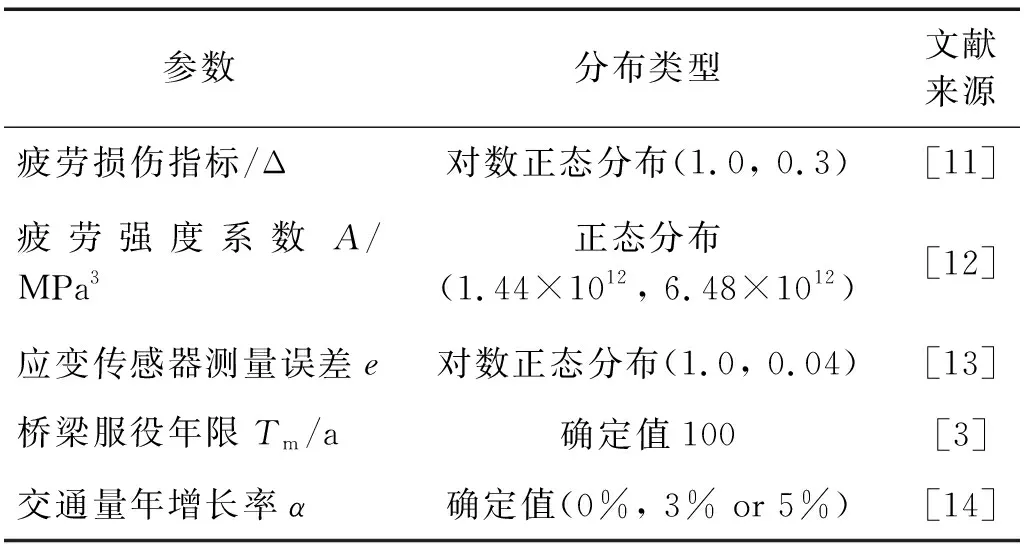
表1 疲劳可靠性功能函数参数表Tab.1 Parameters in fatigue reliability limit equation
1.2 疲劳可靠度指标
可靠度指标是可靠性评估结果的量化,其计算表达式为
β=Φ-1(1-Pf)
(6)
式中:Φ-1为标准正态分布函数的反函数;Pf为材料的疲劳失效概率。
材料的失效概率可定义为Pf=P(g(X)<0)。基于经典概率理论的基本原理,联合概率密度功能函数的失效概率表达式为
(7)
式中:gxn(x1,x2,…,xn)为函数gx1(x1),gx2(x2), …,gxn(xn)的联合概率密度函数。
2 Copula函数
2.1 Copula函数的基本原理
以往对于桥梁结构疲劳研究文献通常假设认为式(7)中各变量之间相互独立,则可以将表达式(7)简化为
(8)
基于各参数的统计数据,分别建立各参数的独立概率密度函数模型。
Sklar[15]提出了Copula函数模型,Sklar认为任意两个具有相关性的概率函数可以用一种连接函数进行表述,其表达式为
G(x1,x2)=C(G1(x1),G2(x2),θ)
(9)
式中:C(·)为Copula函数;θ为函数G1(x1)和G2(x2)的相关性参数。
Nelsen[16]将Sklar理论进一步推广至n维变量,则式(9)可以扩展为
G(x1,x2,…,xn)=
C(Gx1(x1),Gx2(x2),…,Gxn(xn),θ)
(10)
对式(10)求导函数,则联合概率密度功能函数表达式为
g(x1,x2,…,xn)=
(11)
式中,gx(xi)为Gi(xi)的概率密度函数。为简化功能函数表达式,将函数Gxi(xi)用Ui来表示。连接函数C(·)具有以下几点性质: ①连接函数C(·)的值域范围在[0,1]; ②连接函数C(·)对所有变量均为严格单调递增函数; ③当连接函数的各随机变量u1,u2,…,un相互独立,则连接函数C(u1,u2,…,un)=u1u2,…,un。
2.2 几类Copula函数族的对比讨论
当两变量之间同时受不同的环境因素干扰时,两变量之间往往呈现出非线性相关性,需要用非线性连接功能函数来建立联合概率密度功能函数。本文引入最常用的5组Coupla函数,分别为:Gaussian Copula,t-Copula, Gumbel Copula, Frank Copula, 和Clayton Copula。Gaussian Copula的概率密度函数呈现出几何对称性。在概率分布函数的中部表现出较强的相关性,在函数的上尾和下尾部表现出较强的独立性。Gaussian Copula函数广泛应用于经济和水文研究领域[17]。对于t-Copula函数,函数模型的上尾和下尾具有比Gaussian Copula函数更强地独立性。t-Copula适用于建立极值函数模型之间的联合概率密度函数。Gumbel Copula, Frank Copula 和 Clayton Copula三者均属于Archimedean Copulas族函数,三者具有相似的性质。Gumbel Copula函数的几何概率密度分布不具备几何对称的性质,该函数在上尾部分变量之间具有较强的相关性,在下尾部分变量之间具有较强的独立性。Clayton Copula概率密度函数的性质正好与Gumbel Copula函数相反,即在上尾部分变量具有较强的独立性,而在下尾部分变量具有较强的相关性。Frank Copula函数密度分布具有几何对称的特征,上尾和下尾具有较强的独立性,但相比Gaussian Copula函数较弱。表2列出了5类Copula函数的概率密度和概率函数表达式。

表2 5类Copulas的概率和概率密度函数Tab.2 CDF and PDF expressions offive types of Copulas
2.3 最优Copula判别准则
两变量之间的相关性关系往往比较复杂,不能简单的用一种线性关系或非线性关系定义。各类型的Copula函数都具有本身的优势。需要在常用Copula函数中找到最优的模型来确定最终的联合概率密度函数。Akaike信息判别准则作为最常用的最优模型的选择准则,其判别表达式[18]为
VAIC=-2ln(c)+2a
(12)
式中: ln(c)为估计值的对数;a为相关性参数总数。当VAIC值达到最小时,该参数所对应的Copula模型最优。
2.4 相依性度量
为量化两变量之间的相关性程度,需要对两变量进行相关性度量。最常用的线性相关性度量方法有Pearson系数相关性度量法。其表达式[19]为
r(u1,u2)=
(13)
式中:Fu1(u1) 和Fu2(u2)分别为变量U1和U2的秩;E(Fu1(u1))和E(Fu2(u2))分别为Fu1(u1) 和Fu2(u2)的均值;σFu1(u1)和σFu2(u2)分别为Fu1(u1) 和Fu2(u2)的标准差。
3 基于Copula函数的疲劳可靠指标评估法
应用Copula函数建立疲劳可靠度联合概率密度功能函数,对服役桥梁进行疲劳可靠度评估可分为以下6个步骤:
步骤1推导疲劳可靠度功能函数,确定极限状态方程中变量的类型和数量。总体而言,疲劳可靠度功能函数中变量分为疲劳抗力变量R和疲劳效应变量S。
步骤2讨论各变量之间具有相关性的可能性。对存在相关性可能的变量组,统计变量组的时间序列数据。采用相关性度量法确定变量组的相关性系数。
步骤3选择几类Copula函数分别构建具有相关性变量组的联合概率密度函数表达式。并采用极大似然法估计联合概率密度函数的参数。
步骤4采用AIC判别准则确定最优Copula函数表达式。
步骤5基于统计数据,构建变量的边缘概率模型和联合概率模型。
步骤6计算联合密度函数的失效概率,并求解疲劳可靠度指标。
图1为基于应变监测数据考虑变量之间的相关性的桥梁疲劳可靠度计算流程图。
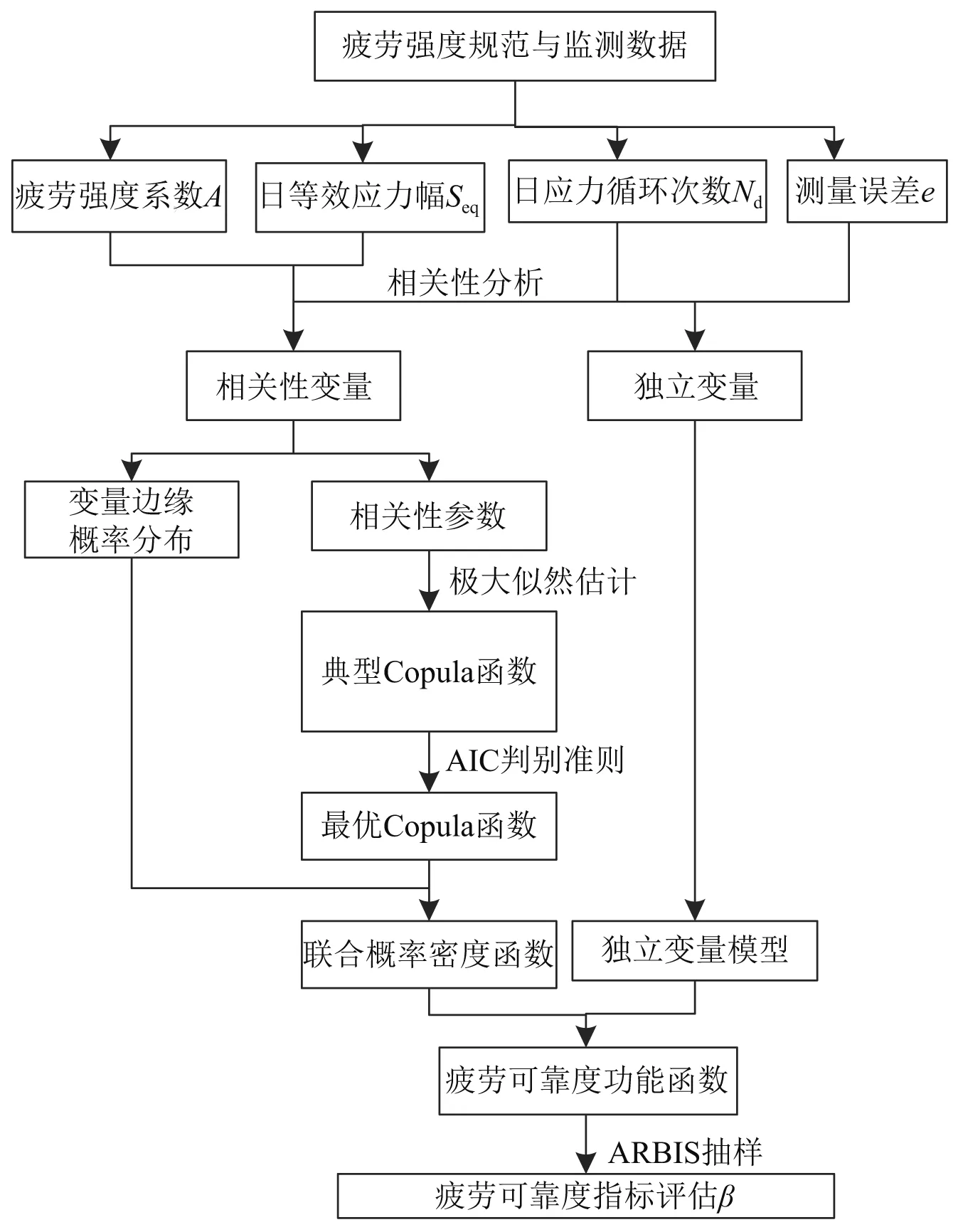
图1 细节疲劳可靠度指标评估流程图Fig.1 Flowchart of details fatigue reliability assessment
4 工程实例
4.1 南溪长江大桥应变与温度监测系统
南溪长江大桥悬索桥作为中国西南地区最大主跨的悬索桥,是宜宾到泸州高速路上跨越长江的控制性工程大桥,其主跨跨径为820 m(见图2)。为讨论环境温度对应变数据的影响,在悬索桥的跨中设置温度传感器,监测该地区环境温度的变化。传感器采样频率为5 Hz。在行车道两车轮加载位置所对应的U肋-顶板焊接点和U肋-U肋对接点分别埋设振弦式应变传感器,传感器编号分别为B0-SG-01、B0-SG-02、B0-SG-03和B0-SG-04,采样的频率为50 Hz(见图3)。

图2 南溪长江大桥立面图Fig.2 Nanxi Yangtze River suspension bridge
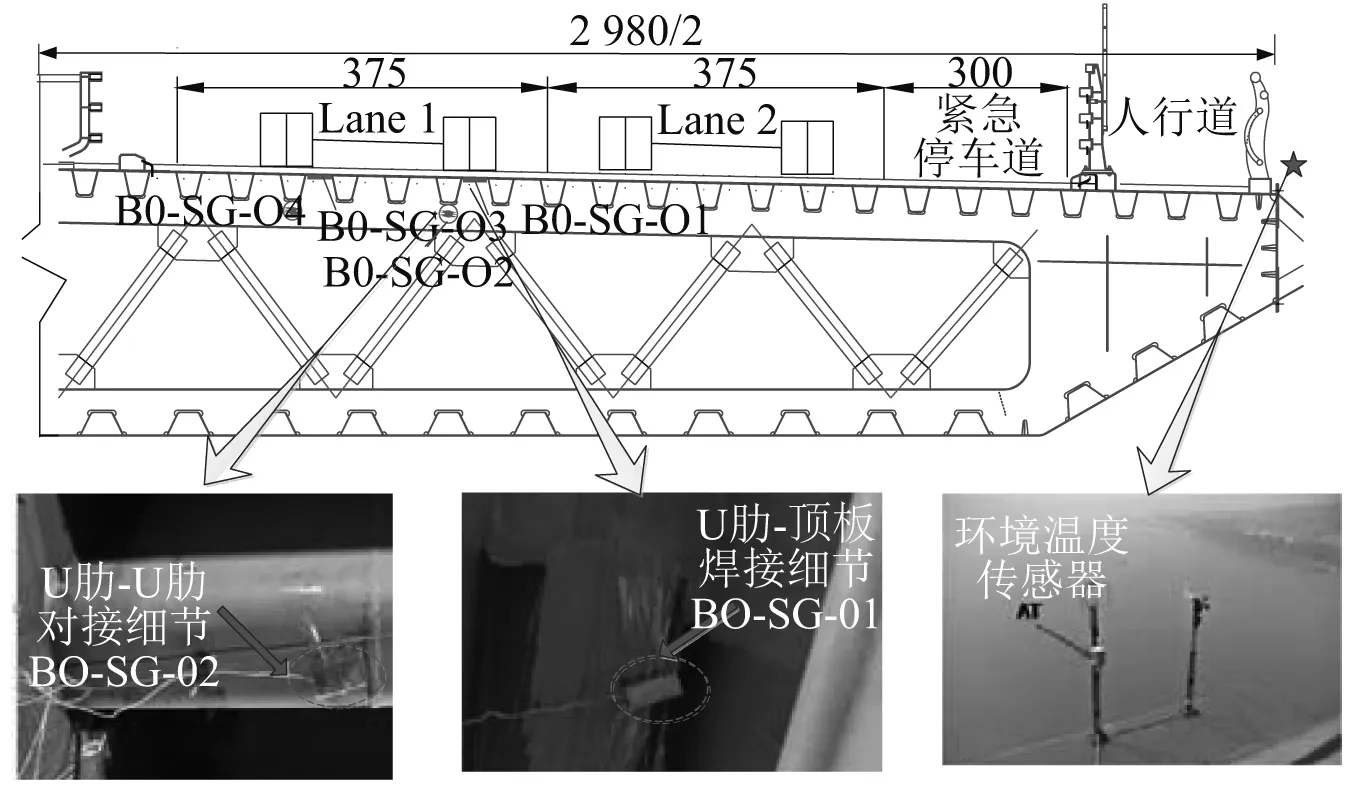
图3 温度与应变传感器布置截面图(cm)Fig.3 Layout of strain and temperature sensors in cross section of steel box girder (cm)
4.2 实测应变数据处理
应变传感器所接受到的信号包含了桥梁结构遭受所有外界荷载作用的信息。主要包括车辆荷载、环境温度荷载和信号干扰(对于地震荷载等小概率性偶然荷载,本文忽略不计)。应变传感器采集的原始信号包含了对疲劳寿命评估计算有干扰的信号。需要采取一定的手段将干扰信息分离出来。由于车辆荷载、温度荷载和干扰荷载信号三者的频率具有明显的区别,可以采用小波技术分离三种不同频率的信号。小波分离技术的基本原理认为任何一种采集信号波是由最基本的母波叠加而成。小波技术则是采用最简单的母波信号对原始信号进行拆解和重构[20]。本文选用的小波函数为Daubechies小波。将温度信号与其他信号进行分离。
对2018年5月1日传感器B0-SG-01的采集数据进行统计(见图4(a)),并采用Daubechies小波对原始数据从3~10级进行逐步分离,可知当分离等级到达5级时,可以将车辆荷载信号、环境温度荷载信息以及外界其他干扰信号分离开来。将环境温度荷载信号与外界干扰信号组合后去除。得到有效的车辆荷载信号。由图4(b)可知,环境温度作用下,结构的应力变化呈现出正弦函数的变化图形。车辆荷载效应信号的形式为脉冲式(见图4(c))。需要说明的是,图4(c)中分别在时间节点8 h,12 h和22 h附近出现应变“突变”均由超限轴重引起。

图4 传感器BO-SG-01器应变监测数据Fig.4 Time-history curve of strain of sensor BO-SG-01
4.3 变量相关性讨论
疲劳可靠度极限状态方程中的变量组包括:疲劳临界失效值Δ,疲劳强度系数A,传感器测量误差e,等效应力幅Seq和等效应力幅循环次数Nd。讨论和分析变量之间的相关性是计算可靠度指标的前提。
(1) 独立变量
对于变量Δ,一般认为对于理想的材料当损伤累计达到1时发生疲劳失效。而在实际工程中,材料本身具有一定的差异,如在运输过程的造成的碰撞缺口、焊接缺陷以及材料的初始裂纹均会影响材料的最终的疲劳寿命。变量Δ的概率取值与材料的制作工艺以及施工工艺有着密切联系,而与疲劳极限状态方程中的其他变量没有实质的关联,可以认为变量Δ与方程中其他变量相互独立。
对于变量A,材料的疲劳强度系数为材料的固有特征参数。构成材料的元素的种类、各元素在材料中所占的比例、材料的试验几何尺寸决定了该类型材料的疲劳强度系数的取值。由此可知,变量A与极限状态方程中其他的变量没有相关性。
对于变量e,主要受传感器本身的构造、工程人员对传感器的参数设置、以及外界的侵蚀介质对传感器的影响。一般认为传感器的测量误差与疲劳失效功能函数中的其他变量无直接的关联性。可以将其视作为独立变量。
(2) 相关变量
假设在一个方程中,有两个及两个以上的变量受同一外界参数影响,则可以认为受影响的变量之间存在相关性。Liu等的研究认为环境温度对钢箱梁正交异性板焊接细节的应力大小和循环次数较大的影响。由此可以推测应变(应力)监测数据通过雨流计数后细节点的等效应力幅Seq和应力幅循环次数Nd存在一定相关性。
为进一步验证该推论,将环境温度、等效应力幅与应力循环次数三组数据进行对比分析。本文取既有桥梁结构在2018年1月1日—2018年7月30日期间的环境温度、U肋细节应力和应力循环次数监测数据进行讨论分析。图5对比了环境温度、日等效应力幅和应力循环次数三个变量从2018年1月份到7月份(春-夏)的时间序列。环境温度在局部范围内出现一定震荡。日等效应力幅值在1月份的平均等效应力为7.2 MPa,而在7月份的日等效应力幅均值达到了14.2 MPa。整体而言,日等效应力幅随温度的升高而变大。日应力循环次数随时间的变化呈现出一定的增长。1月份的日应力幅次数均值为1 052次,明显小于7月份的均值数(1 931次)。试验数据验证了推论的正确性。对于U肋-U肋对接细节,1月份和7月份的等效应力幅均日等效应力幅分别为7.0 MPa和8.8 MPa,相对第一类细节变化要小。
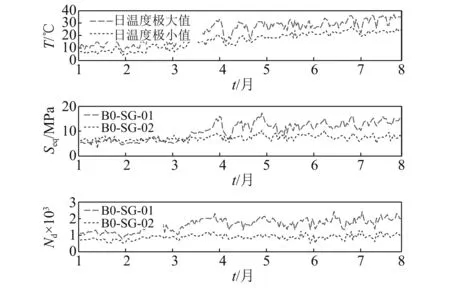
图5 两类细节点环境温度、日等效应力幅和应力循环次数时间序列对比图Fig.5 Comparisons of T, Seq, and Nd time-history curves for two details
整体而言,日温度极大值和极小值呈现上升的趋势。对于焊接细节点的日等效应力幅值与环境温度局部的震荡呈现出协同性。
4.4 Copula联合概率密度函数建模
(1) 边缘概率密度函数
在构建联合概率密度之前,首先要得到边缘概率密度函数模型。对于独立变量Δ,A和e的边缘概率分类型与参数在表3中已列出,不再赘述。分别选用三类最常用的概率模型(正态分布、对数正态分布和威布尔分布)对统计变量进行描述。图6(a)和图6(b)分别对比两类细节点等效应力幅值实测概率密度分布和三类概率模型的对比图。三类拟合模型的精度均满足要求,其中正态分布拟合精度达到了96%,在三类模型中最高。图7(a)和图7(b)则为日应力循环次数的实测概率分布和拟合模型对比图。在三类拟合模型中,正态分布模型拟合精度最高。表4给出两类细节点日等效应力幅和应力循环次数的三类拟合模型的参数取值。
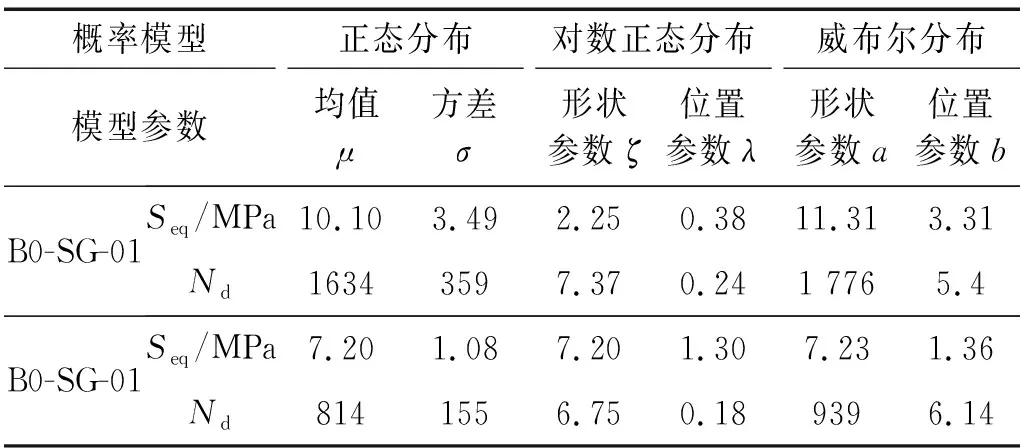
表3 Seq和Nd概率模型的参数模型Tab.3 Parameters of probability distribution models for Seq and Nd
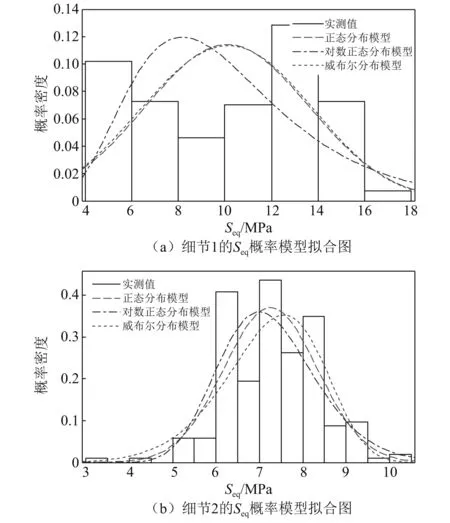
图6 两类细节点的Seq概率模型拟合图Fig.6 Comparisons with Seq PDFs of two details
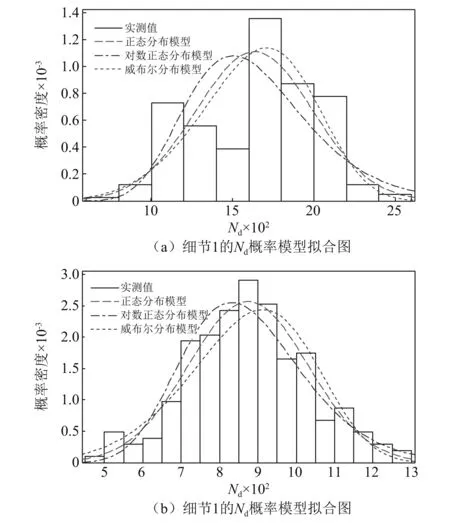
图7 两类细节点的Nd概率模型拟合图Fig.7 Comparisons with Nd PDFs of two details
(2) 最优Copula函数选取
最优Copula函数的选择分为以下两个步骤:
步骤1基于实测应力幅值大小与应力循环次数的时间序列,采用极大似然估计法估算5类常用的Copula函数参数θ。极大似然估计通过对Copula边缘概率密度函数求对数,并计算极值,表达式为
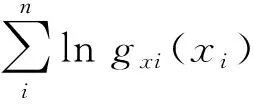
(14)
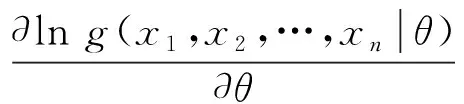
(15)
步骤2分别计算Gaussian Copula,t-Copula, Gumbel Copula, Frank Copula和Clayton Copula的AIC判别值。表4列出了5类Copula函数的参数表及AIC判别值。通过对比可知,正交异性板两类细节点的Gaussian Copula函数的VAIC的计算值相对其他4类最小。本文取Gaussian Copula函数作为最优的一种连接模型。为了验证Gaussian Copula函数模型的精准性,在Gaussian Copula函数模型中抽取1 000个样本点与实测样本点数据进行对比论证。由图8可知,实测数据和样本数据点在概率分布中部呈现出较强的相关性,且两组样本数据概率分布形态分布特征相似。
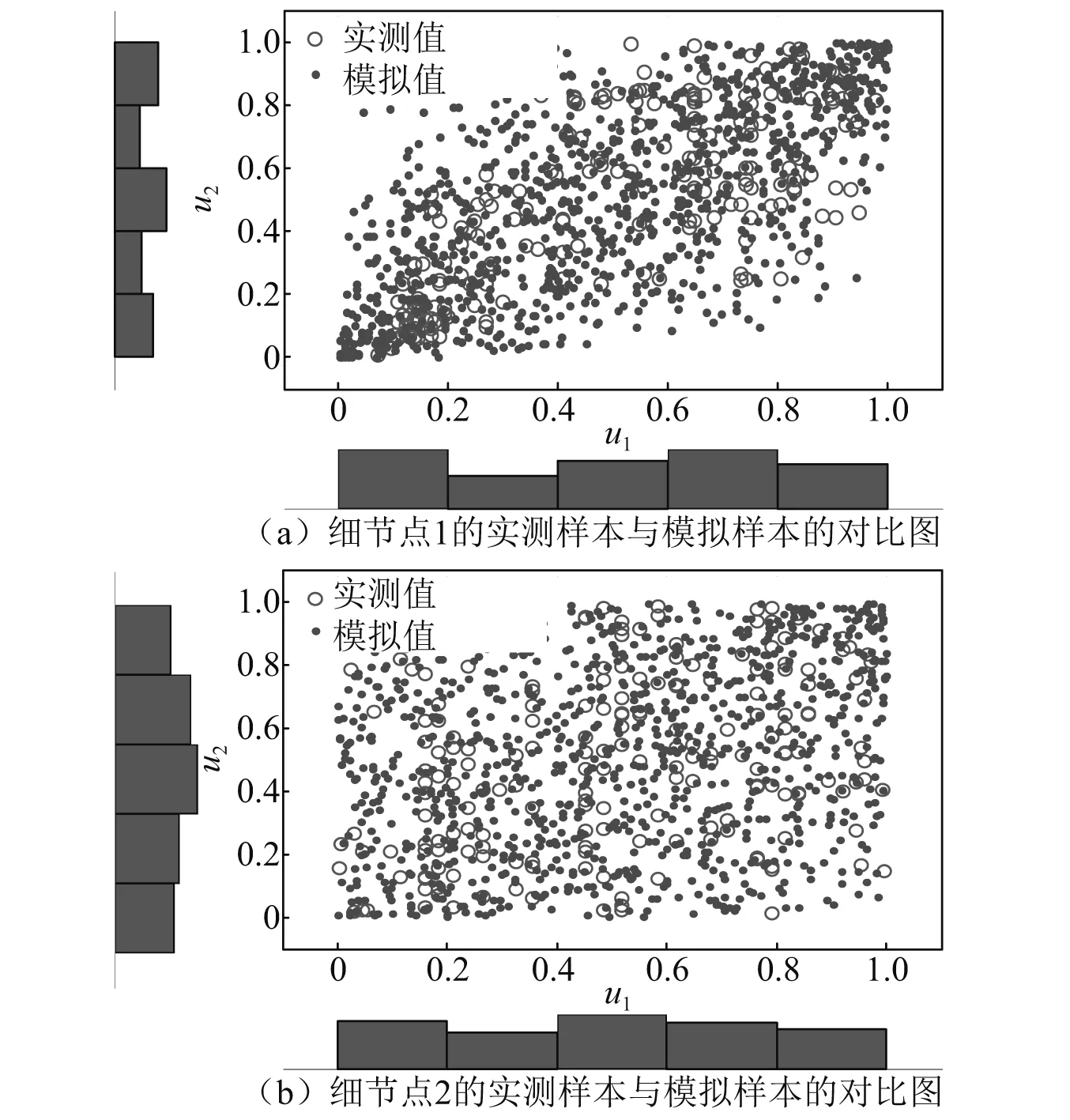
图8 两类细节点的实测样本与模拟样本点对比图Fig.8 Scatter plots of measured data and simulated data
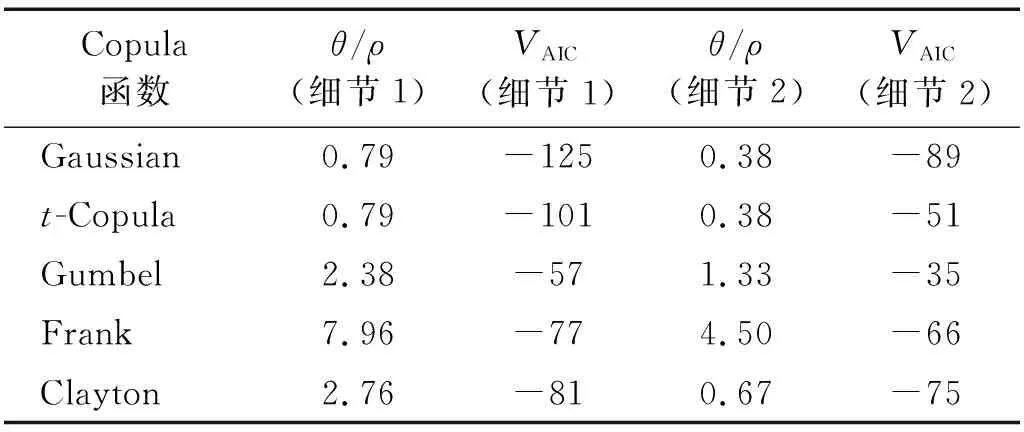
表4 Copula函数参数估计值和AIC判别值Tab.4 The copula function parameters estimated value and AIC discriminant value
由表2可得到最优Copula函数的表达式为
C(u1,u2;θ)=
(16)
式中:u1和u2分别为变量Seq和Nd的边缘概率分布模型;θ为Copula函数的参数值。采用极大似然估计法计算得到两类细节点Seq和Nd的参数值分别为0.79 和 0.38。图9列出了两类联合概率密度分布函数分布图。
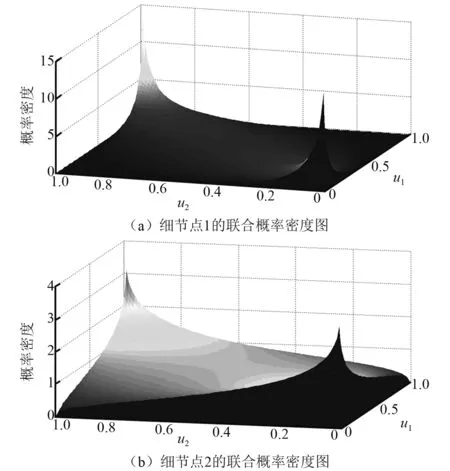
图9 两类细节点的联合概率密度分布图Fig.9 Joint PDFs for details 1 and 2
5 讨 论
5.1 变量相关性对可靠度指标的影响
采用重要抽样法计算考虑与不考虑变量相关性两种情形下正交异性板焊接细节点的疲劳可靠度指标。图10(a)对比了两种情形下细节点1的疲劳可靠性指标随服役年限的变化情况。考虑变量Nd和Seq相关性的可靠度指标明显小于不考虑变量相关性的可靠性指标。桥梁结构服役100年时,考虑与不考虑变量相关性的可靠度指标值分别5.3和6.9,两者之间相差约1.3倍。
图10(b)对比了考虑与不考虑变量相关性下,细节点2的时变可靠度指标的变化曲线。由图10(b)可知,两类情况下可靠性指标曲线间距较小。桥梁结构服役100年时,考虑与不考虑变量相关性的可靠度指标值仅相差1.03倍。表明考虑和不考虑变量的相关性,对细节2的可靠性指标影响较小。
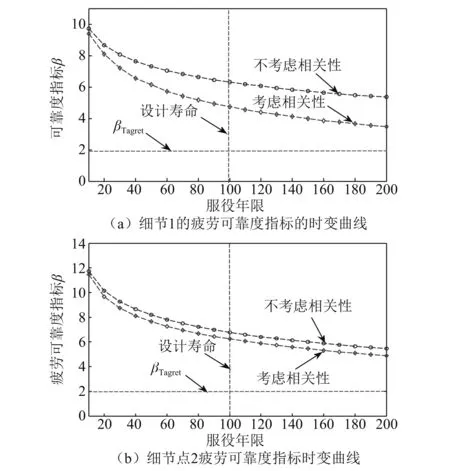
图10 两类细节点疲劳可靠度指标时变曲线Fig.10 The fatigue reliability index time-varying curves for two types of details points
在设计基准期100年内,两类细节的疲劳可靠度指标均大于目标可靠度指标2。说明在不考虑交通增长率的情形下,结构在设计期内具有足够的安全储备。
5.2 Copula函数对可靠度指标的影响
图11对比了Gaussian Copula,t-Copula, Gumbel Copula, Frank Copula和Clayton Copula函数构建的联合概率密度函数下细节1的可靠度指标的时变曲线。由图11可知,在5类可靠度指标时变曲线中,Clayton Copula函数构建的联合概率密度函数模型,可靠度指标要大于其他4类Copula函数构建的联合概率密度函数。Gumbel Copula函数模型的可靠性指标时变曲线最小。桥梁服役100年时,Clayton Copula函数模型和Gumbel Copula函数模型的可靠度指标分别为5.9和3.8。
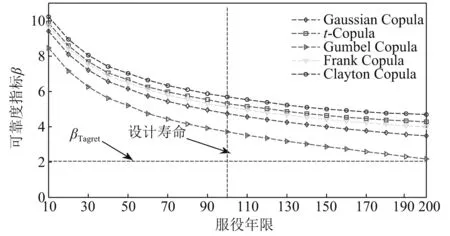
图11 5类Copula函数模型的可靠度指标时变曲线Fig.11 Fatigue reliability time-varying curves by five types copulas
Clayton Copula函数模型在概率分布的上尾部分的相关性相对较强,导致样本较小的数据具有较强的相关性,可靠度指标计算值较大。Gumbel Copula函数模型在下尾部分相关性较强。样本较大值数据相关性较强,致使疲劳荷载效应较大,可靠度指标小。对于Gaussian Copula,t-Copula和Frank Copula模型在概率分布函数的中部相关性较强,可靠度指标值在前两类Copula函数的可靠度指标之间。
5.3 交通增长率对可靠度指标的影响
交通增长率α作为影响结构的可靠度指标的另一变量,需要进行讨论分析。分别选取为0%,3%和5%作为交通增长率α的取值,计算两类细节的时变可靠性指标。由图12(a)可知,当α分别等于3%和5%时,细节点1的可靠度指标在服役年限为94.6年和67.1年时间节点等于目标可靠度指标。考虑交通增长率因素的前提下,结构在细节点1服役期内存在较大的安全隐患。由图12(b)可知,对于细节点2,疲劳可靠度指标明显要高于细节点1。当交通增长率为α=5% 时,当桥梁结构服役年限为81.9时,细节点2的疲劳可靠性指标等于目标可靠度指标,需要对该类细节进行维修加固来增加结构的安全储备。
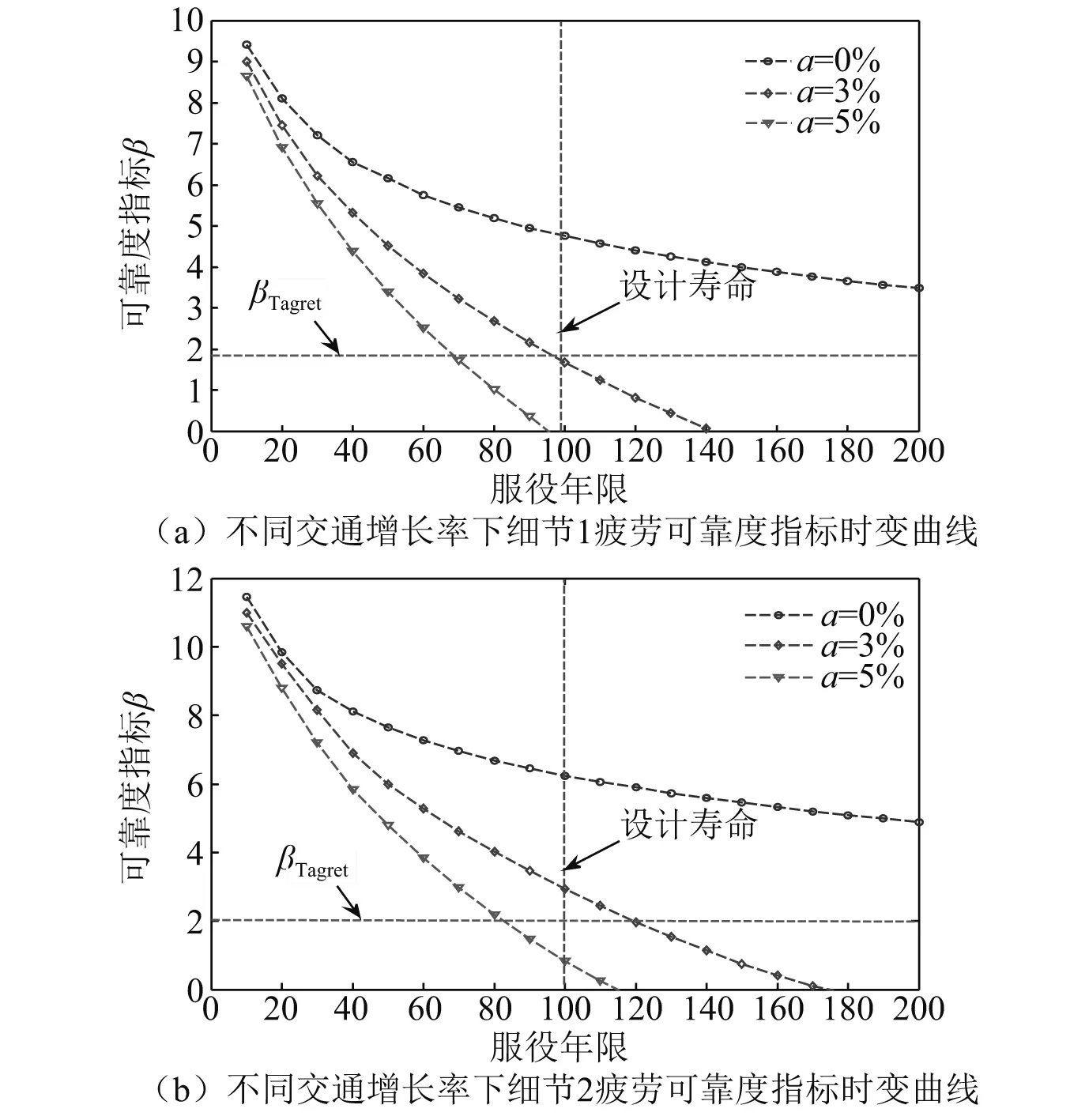
图12 不同交通增长率细节疲劳可靠度指标时变曲线Fig.12 Comparisons of fatigue reliability index time-variant curves with difference traffic growth rates
6 结 论
基于实测应变数据和Copula函数,提出了一种考虑变量Nd和Seq相关性的可靠性评估方法。并将该方法应用于我国西南地区最大主跨的南溪长江大桥悬索桥主梁正交异性钢箱梁的疲劳可靠性评估中。并得到以下结论:
(1) 桥梁结构服役100年时,对于U肋-顶板细节,考虑与不考虑变量相关性的可靠度指标值分别5.3和6.9,两者之间相差约1.3倍,假定疲劳极限状态方程中各变量相互独立值得商榷。
(2) 讨论了5类Copula函数分别建立联合概率密度函数时,细节点疲劳可靠度指标的时变曲线,可知Clayton Copula函数和Gumbel Copula函数所对应的疲劳可靠度指标分别最大和最小。
(3) 考虑交通增长率为3%和5%时,细节点1的疲劳可靠度指标分别在服役年限为94.6年和67.1年到达目标可靠度指标。需严格控制交通增长率。
