一种基于深度学习的交通标志识别新算法*
2021-02-26陈昌川王海宁王延平李连杰张天骐
陈昌川,王海宁,赵 悦,王延平,李连杰,李 奎,张天骐
(1.重庆邮电大学 通信与信息工程学院,重庆 400065;2.山东大学 信息科学与工程学院,山东 青岛 266237)
0 引 言
交通标志识别是交通道路运输的重要组成部分[1-2],但受多种因素干扰,如下雨天、标志牌老化等,为保证道路安全,既要考虑识别的精度也要确保识别速度,因此实际应用中要求实现实时高精度识别。
目前关于交通标志识别已有多种方法。由于标识牌特有的形状与颜色,有学者提出基于色彩空间识别方法[3],或根据形状特征识别交通标志[4],或采用色彩与形状特征融合[5]识别,或者通过颜色空间提取感兴趣区域[6],随后使用支持向量机(Support Vector Machine,SVM)进行分类[7-9]。然而这些方法存在一定弊端:采用色彩或形状识别算法存在大量误检,当交通标志所处背景与其颜色或形状相近,往往会将背景错误识别成交通标志;再者,通过颜色和形状对特殊情况下交通标志很难提取,例如下雨天、大雾天、遮挡等情况,进而导致精度偏低;使用颜色或形状提取图像候选区域随后使用SVM分类的方法对于类别过多交通标志,很难做到正确分类,存在通用性偏低问题。近年来由于卷积神经网络(Convolutional Neural Network,CNN)的兴起,为解决精度低的问题,又有学者提出将CNN应用在交通标志检测与识别。Lee[10]等人基于SSD(Single Shot Multibox Detector)算法[11]构建的CNN算法同时估计交通标志位置与边界,在基于VGG16模型下最高平均准确率(Mean Average Precision,mAP)达到88.4%。Filatov[12]基于交通标志边缘,通过形态学运算与Canny算法处理待检测图像得到交通标志轮廓,随后送入CNN模型进行判断,实现交通标志识别。但对于使用CNN检测方法,通过提取大量目标候选区域送入分类网络进行判断和识别[13-18],虽然保证一定的精度与通用性,但不针对交通标志特定场景,网络设计复杂,提取候选区域图像均要送入网络判断与识别,需要大量计算导致识别速度慢,且精度受限无法进一步提升。
本文从交通标志牌边缘信息出发,基于深度学习YOLOv2算法检测思想,提出一种T-YOLO检测算法。该算法自行搭建网络结构,融合残差网络、下采样操作舍弃通用池化层而改用卷积层,设计7层特征提取网络,解决检测速度慢问题,缩短检测速度;针对交通标志特定场景,提出卷积层四周填充0提取边缘信息与上采样方法,卷积层填充0提高识别精度,上采样方法解决算法无法定位小目标问题提升定位准确度,进一步提高识别精度;随后采用Softmax函数归一化0~1,产生目标概率可能值,实现多分类识别,解决SVM分类器通用性偏低问题;通过批量归一化、多尺度训练等训练方法,增强了算法的鲁棒性。实验表明,相比于同期交通标志识别算法,所提算法在检测速度与平均准确度上均达到最优;相比于YOLOv2,所提算法平均准确率提高7.1%,检测速度缩短每帧9.51 ms,整体性能都得到了提高。
1 T-YOLO算法
1.1 T-YOLO算法结构
如图1所示,T-YOLO算法首先将图像归一化同一尺度,整幅待检测图像被划分成S×S个网格,每个网格负责检测目标图像中心点是否落在该网格,对于目标图像中心点落在的网格,Pr(object)=1,否则Pr(object)=0。通过人为设定的anchor锚点,产生定量个数预测框,每个预测框会产生坐标信息(x,y,w,h)和置信度(confidence)。x、y为相对该网格左上角坐标偏移值,w、h为该预测框宽与高,置信度为边界框包含目标的可能性Pr(object)与边界框准确度IOU(Intersection over Union)的乘积,如公式(1);同时,每个预测框还会产生一个固定的类别C。
(1)
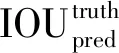

图1 T-YOLO算法检测示意图
交通标志边缘含有丰富的色彩对比信息与线条鲜明形状信息,可以提高识别准确度。为此,T-YOLO算法采用卷积层均四周填充0,提取边缘信息,以提升检测精度。再者,交通标志图像不同于一般图像,单纯采用池化层作为下采样操作,边缘信息将被丢失,因此,T-YOLO算法对于下采样操作不采用池化层,而改用卷积层,通过3×3的卷积核,设置步长为2,进行图像下采样(见图2),确保边缘信息不会被丢失,进而提升检测精度。深度越深的网络层,参数初始化一般接近0,在训练过程中,随着迭代次数增加,网络更新浅层参数,而进一步导致梯度消失,产生梯度爆炸等现象,从而导致无法收敛,损失率增加,而残差网络能解决梯度消失与梯度爆炸等现象,进而使得模型收敛。为此,T-YOLO算法在特征提取结构后加入残差网络,用以防止模型过拟合。图3为引入残差网络结构示意图。
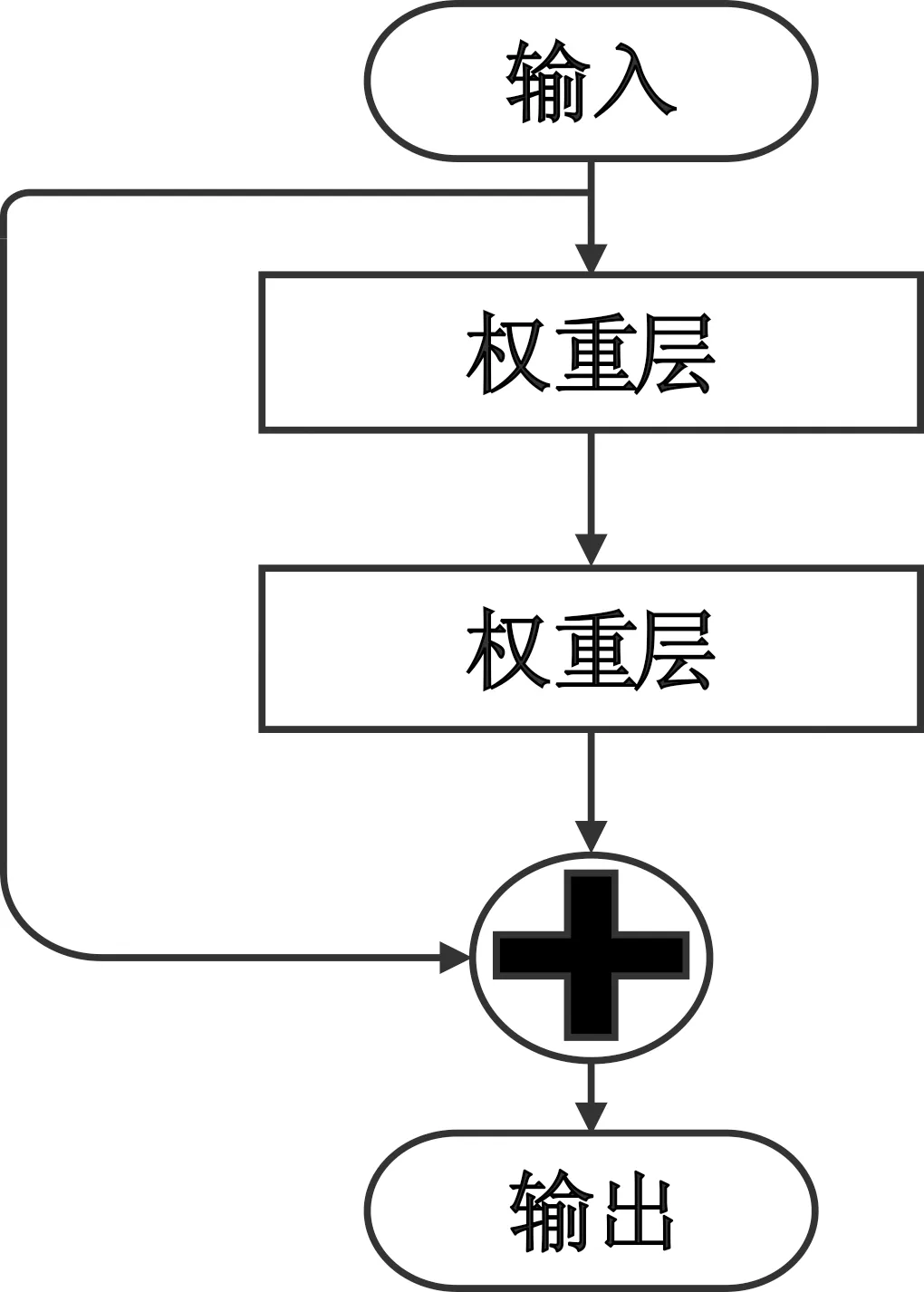
图3 残差网络示意图
神经网络训练是个复杂过程,只要前面几层发生微小变化,这种微小变化就会在后面几层不断放大,形成大变化,一旦网络输入数据分布发生改变,那么网络层势必要去适应学习这个新数据分布,这将极大影响训练速度。为此,T-YOLO算法在每个卷积层中均加入批量归一化操作(Batch Normalization,BN),加速训练模型的收敛速度。
首先找到最小batch,假设最小batch中输入数据为x,β是由输入x构成的集β={x1,x2,…,xm},求得最小batch中的均值与平方差,并将其归一化操作,进而产生了一种从原始数据到训练数据的映射表达式,如公式(2)所示:
(2)
如图4所示,T-YOLO对图像粗略特征提取采用7层卷积层,缩短模型特征提取速度,随后送入后续残差网络与上采样继续进行细节特征提取。T-YOLO算法为解决无法准确定位小型目标图像问题引入上采样操作,如图5所示,通过融合残差网络的输出与输入并上采样,解决识别小型目标问题,以提升精度。最终生成全连接采用Softmax函数归一化。相比于SVM分类器采用超平面将图像进行0与1分类,Softmax函数产生目标概率值,可以实现多目标的分类,解决了SVM分类器通用性偏低问题。

图4 7层特征提取网络
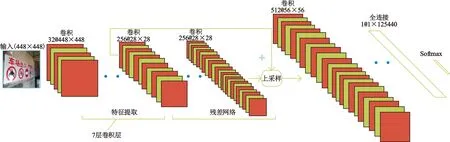
图5 T-YOLO网络示意图
1.2 T-YOLO检测算法
针对目标检测,T-YOLO算法将待检测图像划分成56×56个网格,每个网格会检测是否包含目标图像区域,对于区域性包含目标图像的网格通过算术求得网格中心值,进而确定目标中心点落在的网格。对于检测到目标中心点网格将会截取并产生系列事先设定大小的预选框图像,截取图像送入神经网络进行判断与识别。本文将网格中输出预选框图像个数设置为5个,并采用k均值聚类算法(k-means)求解事先设定预选框大小,随机选取k个对象作为初始聚类中心,然后计算目标中的点与聚类中心距离,并将每次产生的对象分配给距离它最近中心点,每分配一个样本,聚类中心点将会重新计算,然后继续聚类,直到所有样本都被计算完成,最终产生所有的聚类点,选取其中聚类最多的5个矩形框的点作为预选框。
因此,含有交通标志目标中心点的网格将会产生(5+3)×5个预选框图像,该网格产生的40个预选框图像均要送入T-YOLO神经网络进行判断识别。图6为T-YOLO网络检测流程图。
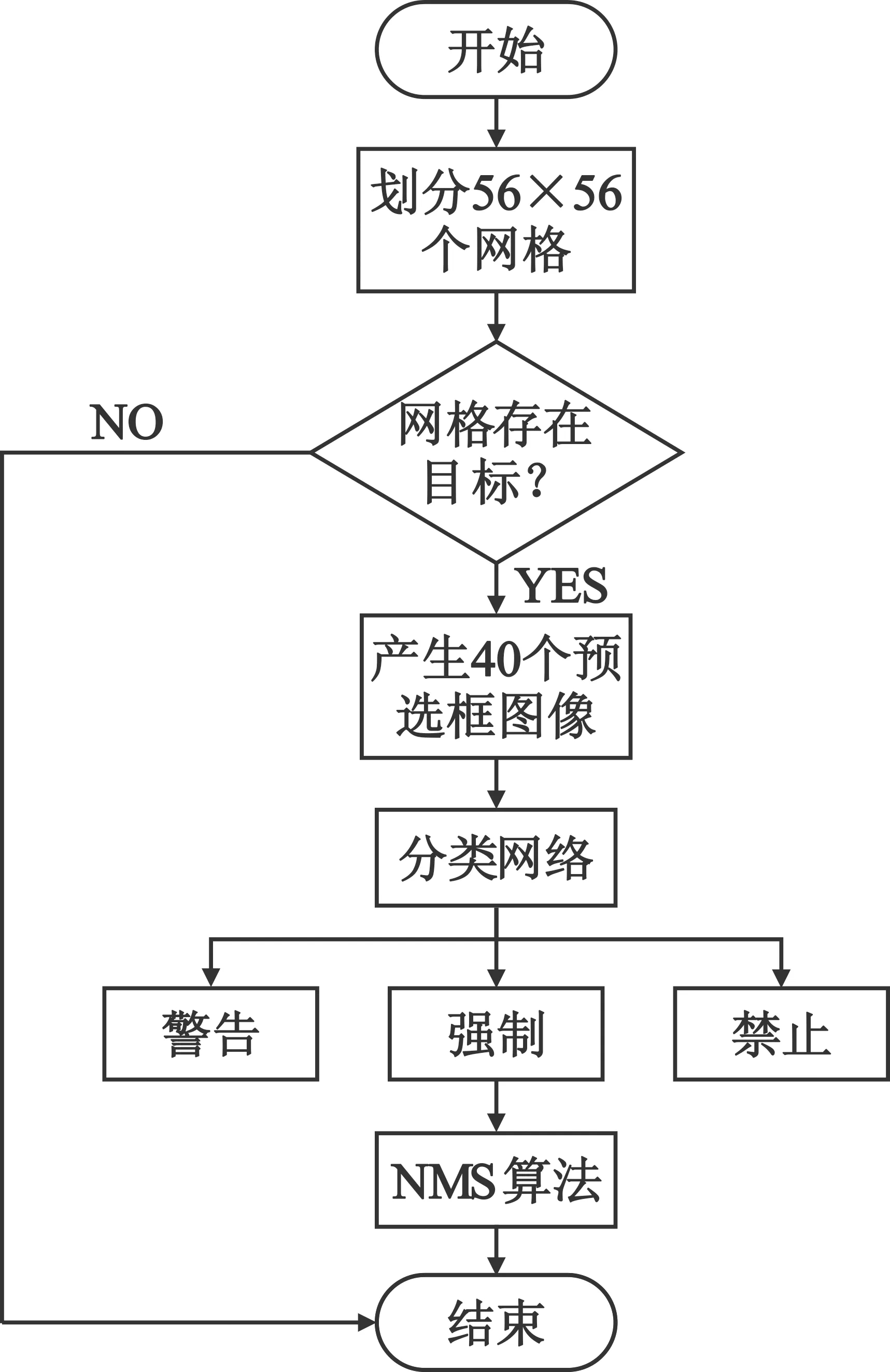
图6 算法检测流程图
同时,为了使模型更具通用性提高模型鲁棒性,T-YOLO网络采用多尺度训练方式,每隔10轮调整一次输入图像分辨率,进而使得模型对于不同分辨率图像均能做到有效的识别与定位。
2 实验效果与算法对比
2.1 数据集预处理及训练
本文选取数据集是Zhang[19-20]等人公开的中国交通标志检测数据集(CSUST Chinese Traffic Sign Detection Benchmark,CCTSDB),丰富的数据集有助于提高模型平均准确率,同时可以加速模型训练时收敛,降低损失率。为了使得训练集更加丰富,包含不同场景情况下图像,采用旋转、调整饱和度、调整亮度三种混合方式增强数据集。按照5∶1的比例划分训练集与测试集,分别为15 000张与3 000张图片,并将数据集划分为警告、强制、禁止三类。
本文实验硬件配置如表1所示,并在上面搭配所需的软件环境Ubuntu16.04、CUDA10.1、Cudnn7.5、Opencv3.4.3,同时根据数据集的特点,一并参考YOLOv2的参数配置。T-YOLO算法的参数配置见表2,在1~30 000次迭代设置学习率大小0.001,然后随着迭代次数的累计,依次调整学习率,直到损失率保持稳定。

表1 硬件配置
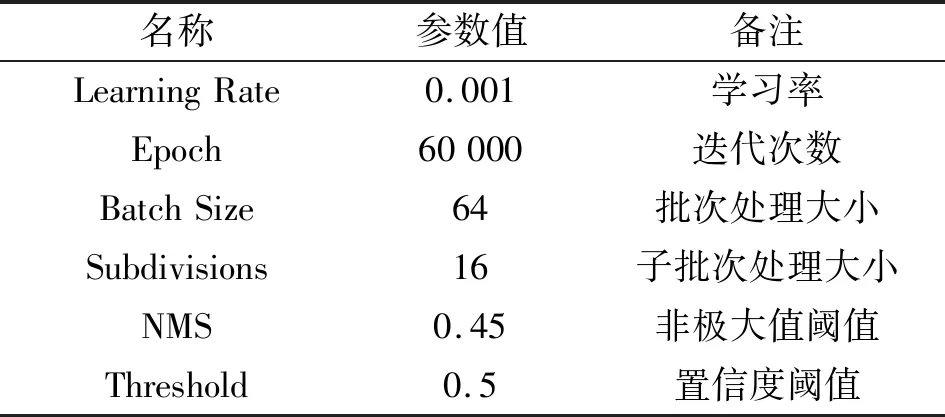
表2 T-YOLO参数配置
2.2 算法对比
为了验证T-YOLO算法准确性与可靠性,在基于硬件平台GPU RXT2080 Ti与CPU Intel(R) Xeon(R) W-2133和软件平台Ubuntu16.04、opencv3.4.3的基础上,将测试集3 000张图片送入不同网络,图片大小为1 024 pixel×768 pixel,并选取平均准确率(mAP)、平均召回率(Average Recall,AR)、GPU检测速度(ms/frame)作为验证指标。AR计算公式如公式(3)所示:
(3)
式中:TP代表真正正样本,FP代表假正样本,FN代表假负样本,i代表类别。算法对比见表3。从表3可以看出,T-YOLO算法无论是在平均准确率还是在检测速度上都达到最优效果,相比于YOLOv2算法,T-YOLO算法在平均准确度上提高7.1%,检测速度每帧缩短了4.9 ms;相比于Faster R-CNN算法,T-YOLO算法在速度上提高124倍,精度提高3.8%;相比于传统算法HOG+SVM,检测精度提高13%。
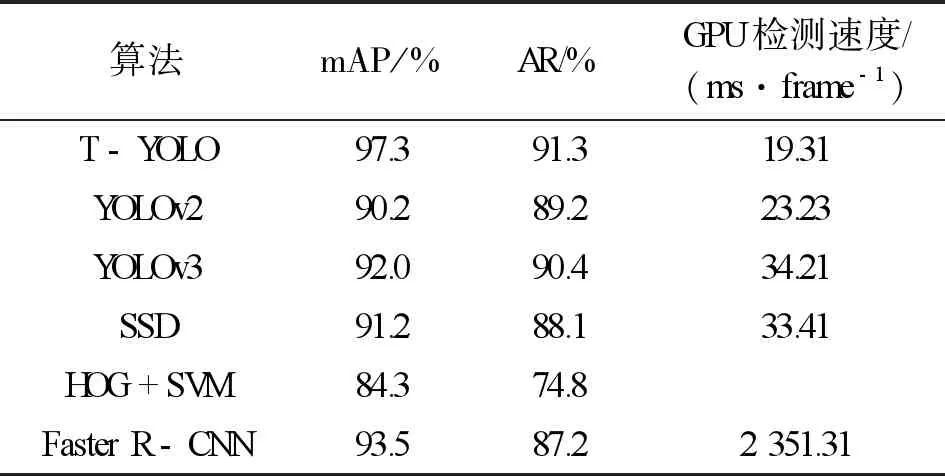
表3 算法对比
同样,为了验证T-YOLO算法鲁棒性,采用不同分辨率输入图像进行测试。采用224 pixel×224 pixel、320 pixel×320 pixel、416 pixel×416 pixel、512 pixel×512 pixel、608 pixel×608 pixel五种分辨率图像,将原始图像按照等比例方式缩放到上述分辨率固定尺度,对于空出像素区域填充黑色像素0,分别验证各个分类的准确率以及平均准确率、检测速度三个指标,结果如图7和图8所示。从图7可以看出,对于图片大小为224 pixel×224 pixel的图像识别准确率较低,这是由于交通标志图像大都为低分辨图像,如果采用更低分辨率图像,交通标志图像会变小,所以导致平均准确率偏低;从图像大小为320 pixel×320 pixel往上,平均准确率越来越高,结果如图7和图8所示。从图7与图8可以看出对于低分辨率的图像,检测速度比较快,但对应的平均准确率低,对于224 pixel×224 pixel图像,GPU上检测速度达到13.69 ms/frame,随着分辨率不断提高,检测耗时也增加。
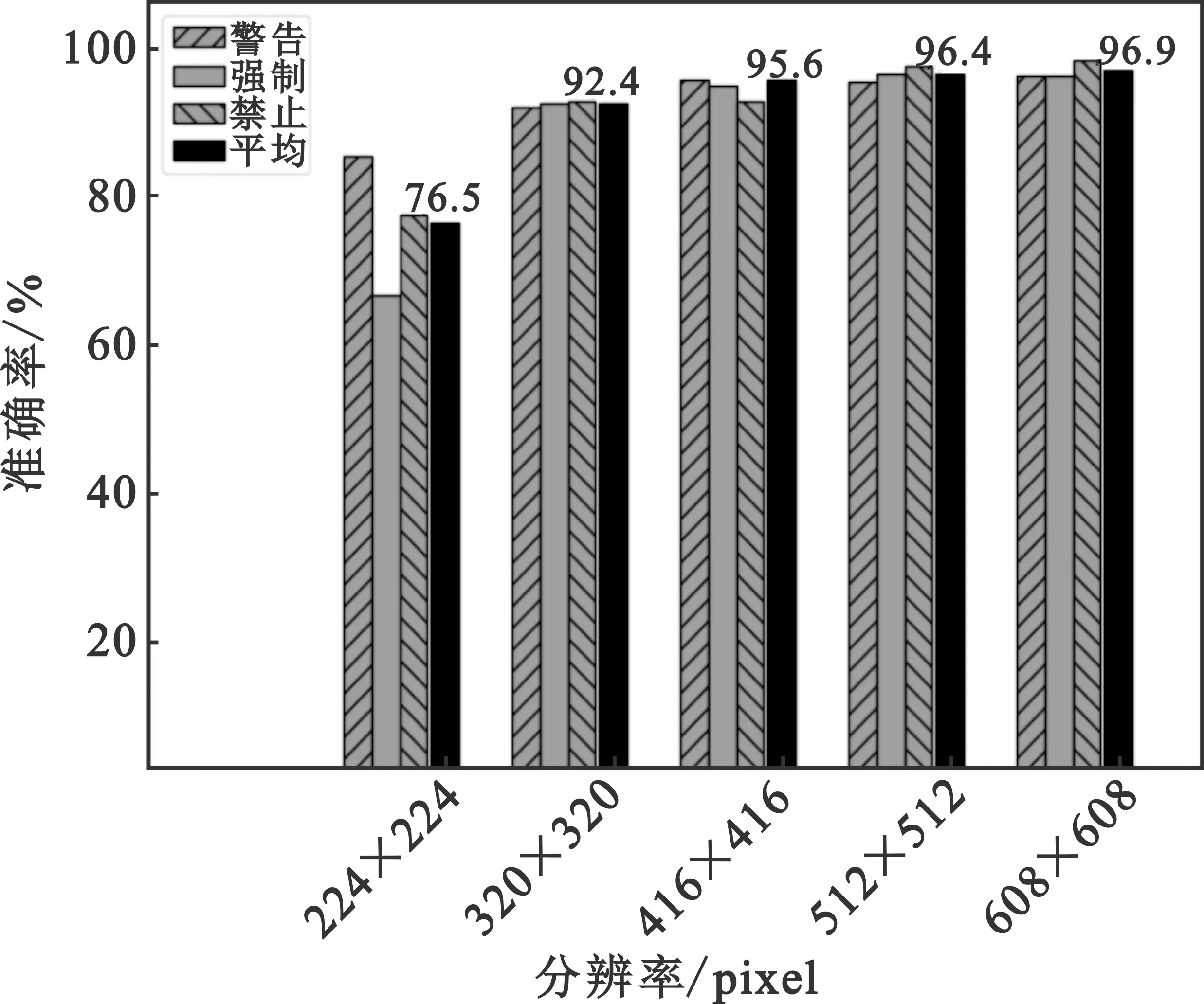
图7 不同分辨率图像准确率
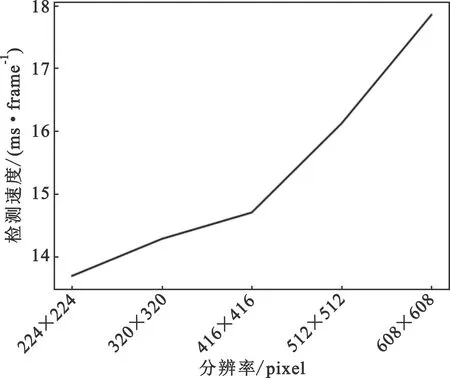
图8 不同分辨率图像检测速度
2.3 T-YOLO算法检测效果对比
交通标志往往悬挂在高空或道路两旁,从人视觉或汽车视觉内观察到的基本为小型目标图像与中型目标图像;再者,对于交通安全,能尽早准确无误地将远方交通标志检出,可以减少不必要的损失,避免进一步的人员伤亡。从图9(a)可看出,YOLOv2算法针对于小型目标图像检测,对小型目标定位很不准确,进而很难检测出;同样可以看出,由于采用池化层作为下采样操作丢失边缘信息,对于遮挡目标很难检测出。从图9(b)可看出,T-YOLO算法可以准确无误将小型目标图像定位,进而进一步检测出目标。由于采用卷积层填充0、卷积层下采样、上采样等方法,T-YOLO算法对于交通标志边缘信息非常敏感,对部分遮挡标志仍能将它检测出来。对于一些特殊天气下的小型目标图像,T-YOLO算法仍可以检测出。

图9 部分算法对比检测效果图
3 结束语
本文提出了一种基于深度学习识别交通标志新方法,与一般算法不同,该算法从交通标志边缘信息出发,针对交通标志特定场景,精简模型缩短速度,通过提取边缘信息与上采样提升识别精度。实验表明该方法真实有效,相比同期交通标志识别算法精度与速度方面均有大幅提高,GPU平台上采用原始图像数据(1 024 pixel×768 pixel),检测速度19.31 ms/frame,mAP为97.3%;由于采用多尺度训练方式,模型的鲁棒性增强。但现实场景细分每类交通标志,算法针对交通标志分类范围过大、类别过少,且未结合标志牌特有颜色与形状特征以提升识别精度,未经实车测试。细分多类交通识别与实车测试将是下一步研究的方向。
“亲近自然,亲近泥土”无疑是陶艺作品在当今的可贵之处,亦在当今也愈发成为了人们的奢求。当它出现于人们的活动空间时,便是将这么一份可贵的物质给予人们,让空间充满意义与欢喜。作为物质与精神融合的产物,其多样化的材料表达方式也符合大家追求特立独行和丰富的艺术风格。以极为自然的艺术表现形式,承载着一定的文化元素,慢慢融入空间环境中,点缀、装饰着空间,促成空间的自然化、艺术化和多元化。
