近邻中心迭代策略的单标注视频行人重识别*
2021-02-25张云鹏王洪元吴琳钰顾嘉晖
张云鹏,王洪元,张 继,陈 莉,吴琳钰,顾嘉晖,陈 强
1(常州大学 信息科学与工程学院,江苏 常州 213614)
2(社会安全信息感知与系统工业和信息化部重点实验室(南京理工大学),江苏 南京 210094)
行人重识别(person re-identification)旨在解决跨摄像机检索匹配行人图像或视频的问题,主要有两种方法:基于图像的行人重识别和基于视频的行人重识别.前者利用行人图像匹配同一行人在不同摄像机视图下的行人图像[1-5],后者直接利用信息更加丰富的行人视频片段匹配同一行人在不同摄像机视图下的行人视频[6-8].而基于视频的行人重识别与现实世界的应用更为贴切,从而在近期引起了极大的关注.现有的基于视频的行人重识别的方法主要依赖于完全标注的视频片段.由于标注数据的成本过于巨大,因此研究依赖少量标注的半监督视频行人重识别具有极大的应用价值.
单标注样本学习是半监督学习的一种.单标注样本视频行人重识别的关键在于如何准确地对大量无标签视频片段进行标签估计[9-11].其常见的方法是:在迭代过程中先将数据嵌入特征空间,以每个行人唯一的有标签视频片段特征作为固定度量中心,无标签视频片段根据与固定度量中心的距离为其分配伪标签.初始有标签数据和每次选定的伪标签数据合并作为新的数据集,进行下一次训练.如图1 所示(图中共有3 类数据:实心圆表示无标签数据,颜色表示各自真实的分类;空心圆表示该类的初始有标签数据特征;虚线圆内与空心圆颜色不同的点则表示伪标签标注错误的数据,以空心圆为中心选取一定比例的伪标签数据用于下一次训练):随着选取用作下次训练伪标签数据的增加,标注错误的伪标签数量也极大地增加.因此,以上这种固定度量中心的方法是有缺陷的.在这种情况下,当有标签数据在特征空间中处于类的边缘或者远离类的中心,随着选取伪标签数据的增加,将会得到大量不准确的伪标签数据,而过多的不可靠的伪标签数据在迭代过程中将会严重影响模型的性能.
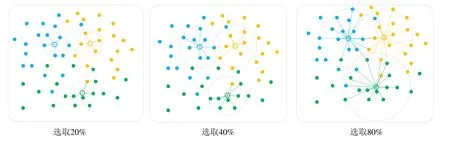
Fig.1 Common label evaluation methods图1 常见标签评估方式
为了在每轮训练过程中得到更多的正确伪标签视频片段用于下一次训练,本文提出了一种新策略:近邻中心迭代策略(neighborhood center iteration,简称NCI).每一次迭代训练后,在特征空间中找出所选取的伪标签视频片段和有标签视频片段特征每一类的中心点,作为其下一轮预测无标签视频片段的伪标签的度量中心点.随着选取伪标签视频片段的数量逐步增加,本文的策略能更加准确地加入复杂的无标签视频片段用于下一次训练.此外,传统的行人重识别特征学习主要依赖于三重损失[12]等函数,其计算量大,因此,本文提出一个损失控制策略,联合训练交叉熵损失(crossentropy loss)和在线实例匹配损失(online instance matching loss,简称OIM Loss)[13],既能有效地缩小类内距离,又能使得训练过程更加地稳定高效.
本文的主要工作如下:
(1) 提出训练策略NCI,该策略中提出的新标签评估准则能有效地提升无标签视频片段的伪标签预测准确率和最终算法的精度;
(2) 提出损失控制策略,联合训练CrossEntropy Loss 和OIM Loss,使得训练过程更加的稳定.
相对于最新的半监督和单标注学习方法,本文的方法在MARS 和DukeMTMC-VideoReID 两个大型数据集上都有很好的性能提升.
1 相关的研究工作
对于监督视频行人重识别,新出现了许多基于深度学习的方法[14-18],如:文献[14]将细化循环单元模块和时空线索聚合模块用于恢复缺失帧和利用上下文信息,从而获得行人视频片段的特征表示;文献[17]提出时空注意力感知学习方法,旨在视频序列的时空上关注视频中行人的重要部分,以解决行人图像质量因不同的时间空间区域变化而变化的问题;文献[18]提出了判别聚合网络方法,直接聚合原始视频帧,且结合度量学习和对抗学习的思想生成更多的判别图像,减少每个视频处理的图像帧数,误导性信息的低质量帧也可以得到很好的过滤和去噪.对于无监督的视频行人重识别,文献[13]提出了半监督行人检测的OIM Loss,它也可用于无监督的视频行人重识别;文献[19]提出了一种自底向上聚类方法(bottom-up clustering,简称BUC)来联合优化CNN 和无标签样本间的关系,并且在聚类过程中利用了一个多样性正则项来平和每个聚类的数据量.
以往的半监督行人重识别方法大多数是基于图像[20-23]行人重识别.近期出现了不少半监督视频行人重识别方法,如Zhu 等人[24]提出了一种基于半监督交叉视图投影的字典学习方法;也出现了一些单标注视频行人重识别任务的方法,如Liu 等人[10]用有标签的样本初始化模型,计算出与查询集样本最接近的k个样本并且删除其中的可疑样本,再将其余样本添加到训练集中,重复该过程直到算法收敛为止;Ye 等人[11]提出了一种动态图匹配(dynamic graph matching,简称DGM)方法,该方法迭代更新图和标签估计,以学习更好的特征空间;Wu 等人[9]使用一个逐步利用无标签视频片段的策略(exploit the unknown gradually,简称EUG),先用有标签视频片段初始化网络模型,再根据与有标签数据的距离将伪标签数据线性合并到训练集中进行后续的训练;文献[25]用了一个单标注样本渐进学习的方式(progressive learning,简称PL),将标签数据、伪标签数据和索引标签数据这3 个部分在迭代过程中联合训练模型.但是文献[10,11]中采用静态策略来确定每次训练所选择的伪标签数据的数量的方法是不合理的,因为初始模型可能不健壮,只有少数伪标签预测在初始阶段是可靠和准确的,如果选择与后期训练相同数量的数据,则不可避免地会出现更多错误的伪标签数据.而文献[9,25]中将有标签视频片段特征作为固定度量中心也会得到大量不准确的伪标签数据.因此本文提出了近邻中心迭代策略,从一定程度上解决伪标签错误率低的问题.
2 近邻中心迭代策略
2.1 基本框架
在迭代训练过程中,采用的是一种常见的渐进学习方式[9],每次训练选取一定比例可靠的伪标签视频片段 用于下一次训练.S表示选取下一次训练的伪标签数据的候选集:

本文方法的具体框架如图2 所示,采用ResNet-50 结构的端到端模型作为特征提取网络,且在分类层前面加上了一个全连接层和一个时间平均池化层.对于每一个视频片段,当所有图片被提取为帧级特征后,时间平均池化层将所有的帧级特征合并,作为视频片段的特征表示.
初始训练时,使用唯一有标签视频片段集合L来初始化模型,再用训练好的模型提取U中无标签视频片段特 征,每个无标签视频片段的伪标签由特征空间中距离最近的度量中心点的标签进行分配,然后产生每个无标签 视频片段的选择指示器si,并根据公式(1)来得到候选集S.在之后的迭代中,每次候选集S和初始的标签数据L合并为新的数据集D,D=S∪L.D则作为下一次训练用的训练集.且在训练过程中,S随着训练次数的增加而不断地 扩大.
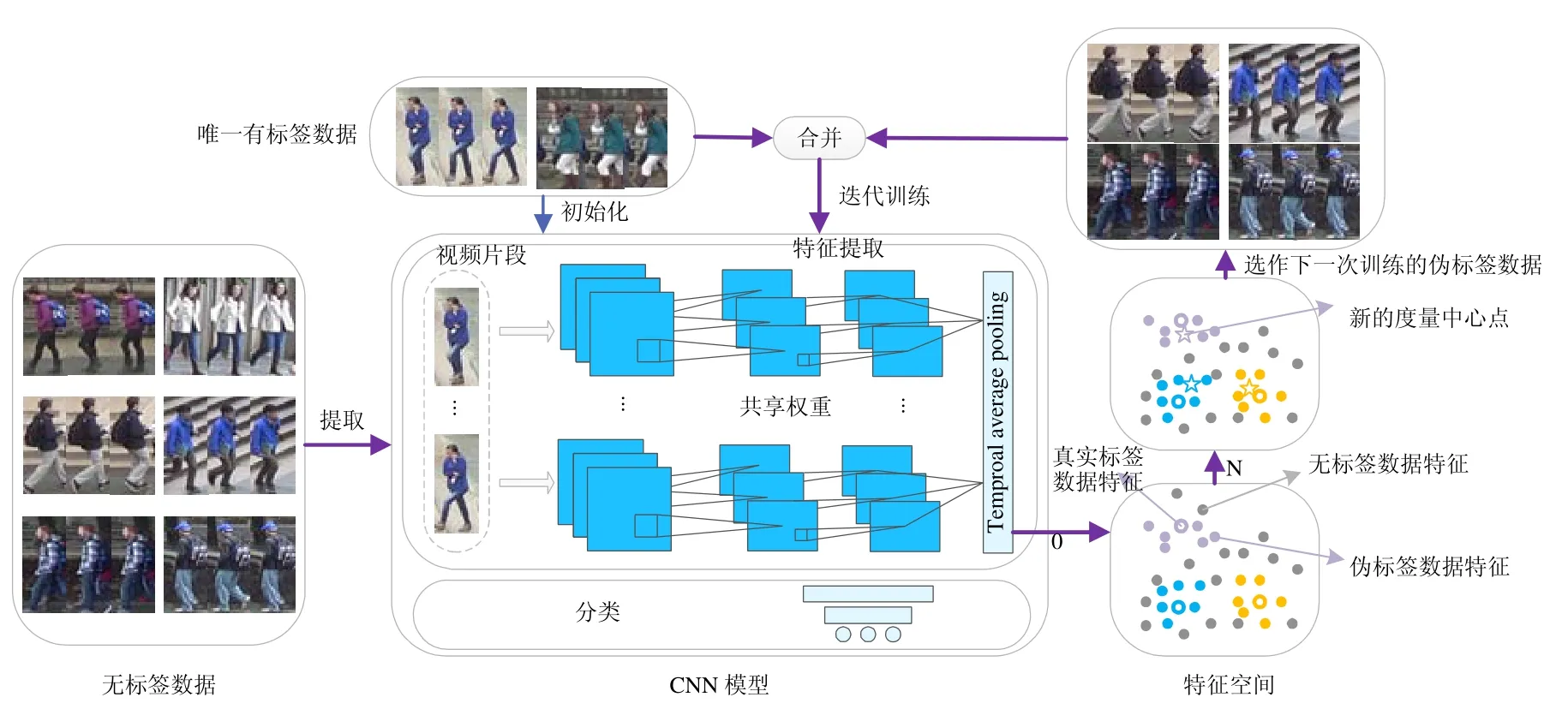
Fig.2 Overall framework of NCI strategy图2 NCI 策略整体框架
2.2 标签评估标准
以往的标签评估方法[9,25]中,有标签数据作为固定度量中心,在每轮训练中为最近的无标签数据进行伪标签分配.如图1 所示,这一方法是有很大弊端的:原始有标签视频片段在特征空间内同类中的相对位置是固定的;且当原始有标签视频片段在特征空间中处于同类的边缘或者远离类中心的点时,每次训练会预测出更多错误 的伪标签,随着选取伪标签数据S的增大(例如图中选取80%),选取到不可靠数据的概率变得更大.
针对这种情况,提出了一种新的标签评估标准.在迭代过程中,利用得到的可靠集合D中每个类的中心,作为 下一次训练预测伪标签的度量中心点.具体来说,每次训练结束,训练完的模型提取无标签视频片段的特征并嵌 入特征空间,此时,无标签数据特征与上一次训练所得的集合D中每个类的中心(初次训练D中每个行人只有一 个初始数据,则以此为类中心)依次计算距离,距离最近的类的标签则为该无标签视频片段的伪标签.然后,无标签视频片段与为其分配伪标签的度量中心的距离排序,按比例选取距离较小并带有伪标签的无标签视频片段 作为可靠伪标签数据候选集S,并与L合并为D,作为下一次训练的数据集.依次迭代,直至用完所有无标签视频 片段.这样能够使得每次选取的度量中心更准确地反映出特征空间内每个类中的特征的集中趋势,能够更加接近类的真实中心,使得每次预测的伪标签更加准确.
如图3 所示(图3 共有3 类:实心圆表示无标签数据特征,空心圆表示该类的初始有标签数据特征,五角星代 表上一次训练所得集合D的类中心,虚线圆内与空心圆颜色不同的点则表示伪标签标注错误的数据,此时则以 五角星为中心选取一定比例的伪标签数据用于下一次训练):当初始训练后,以唯一有标签样本为中心点选取20%的数据,在之后训练中依次以新的中心(五角星)为度量中心点选取40%,80%的数据.可以明显地看到:前一次迭代选取的伪标签数据与初始有标签数据合并之后产生的新的度量中心点更加接近类的真实中心,而相比于图1 预测出更多正确的伪标签.因此,近邻中心迭代策略中的标签评估标准,能够极大地提高每次伪标签预测的准确率,进而提高最终结果.
数据样本的集中趋势描述有平均数、中位数等,本文分别用平均中心和中位数中心计算特征空间的样本中心.由于MARS 数据集采样的摄像头较多且场景较为复杂,可能在特征空间中离群点较多,因此使用中位数中心 更为合适.DukeMTMC-VideoReID 数据集场景相对简单,则使用平均中心更合适.用R表示D中所有类的中心的 集合,其中,平均中心公式可表示为

其中,Rk表示第k类样本新的度量中心点,Dk表示D中第k类样本的集合,N为Dk中元素的个数.
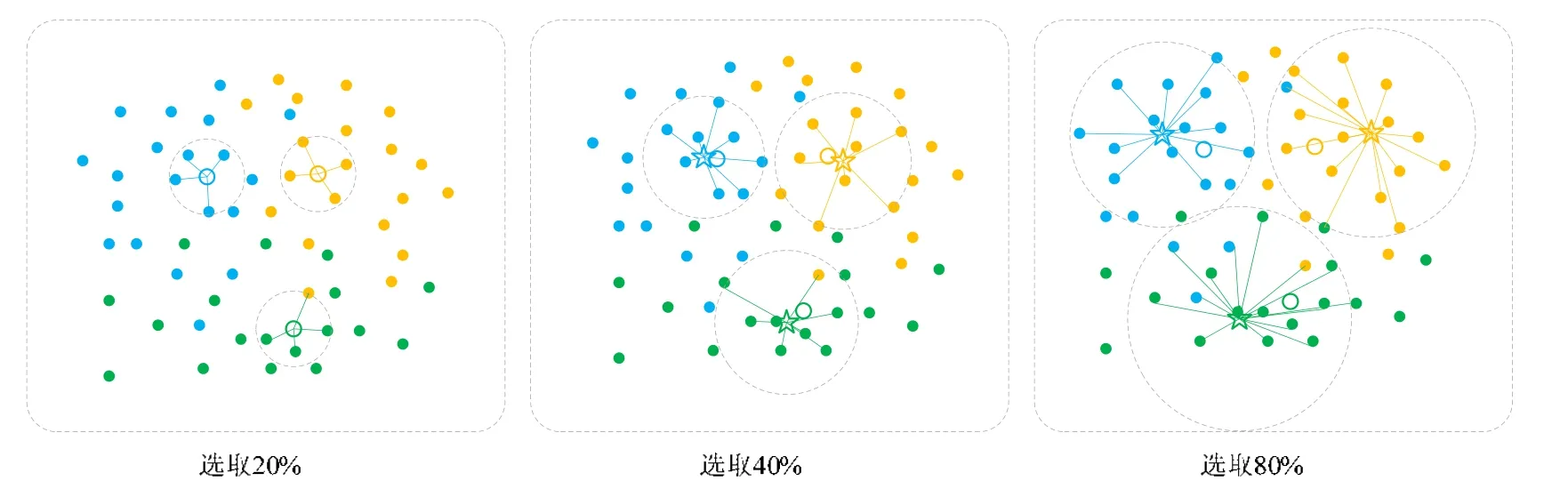
Fig.3 NCI label evaluation method图3 NCI 标签评估方式
2.3 动态抽样策略
由于前几次用于训练的数据较少,模型的性能较差,预测的无标签视频片段的伪标签可靠的数量较少,因此,若前几次训练每次选取过多的伪标签数据,会极大地影响最终的模型性能.因此,本文采用了渐进的动态抽样策略.其中,每个无标签视频片段与所有度量中心的距离的最小值可表示为

其中,xi∈U,Rk∈R表示新的度量中心点,φ(·)表示该无标签视频片段在特征空间中的特征.对于伪标签数据的选 择,通过选择指示器st将一定比例较小的d(xi)对应的无标签视频片段xi作为可靠的伪标签数据采样到训练中:

其中,mt表示当前轮次选取伪标签数据的数量.随着迭代次数t的增加,选取可靠伪标签数据的数量会逐步增加:mt=mt-1+p·nu,p∈(0,1).其中,p表示迭代过程中选取伪标签数据数量的增长率.比较好的选择是将p设置为一个很小的值,这意味着mt逐步增大,并且每一步的变化很小.这种设置随着迭代过程逐步优化,模型性能会非常稳定地提高,并最终获得令人满意的性能.
3 损失函数训练策略
常用的OIM Loss 利用来自有标签行人视频数据的特征形成查询表,与批次样本之间的进行距离比较.另外,那些无标签视频片段可以被视为负样本,将它们的特征存储在循环队列中并进行比较.不仅适用于单标注视频行人重识别训练场景,并且相比于其他损失函数收敛得更快更稳定.OIM Loss 可以表示为

其中,XOIM表示视频片段的特征矩阵,V表示每个类代表性的特征,C表示提取的特征X与每个类的余弦距离.而 CrossEntropy Loss 也是常用的损失函数,在深度训练中有着比较稳定和准确的效果.用XCe表示最终视频片段的特征矩阵,则CrossEntropy Loss 可表示为

基于以上两个损失函数,为了单标注视频行人重识别的训练过程更加稳定、模型性能更佳,本文提出了一个有效的损失函数训练策略,联合训练OIM Loss 和CrossEntropy Loss 两个损失函数:
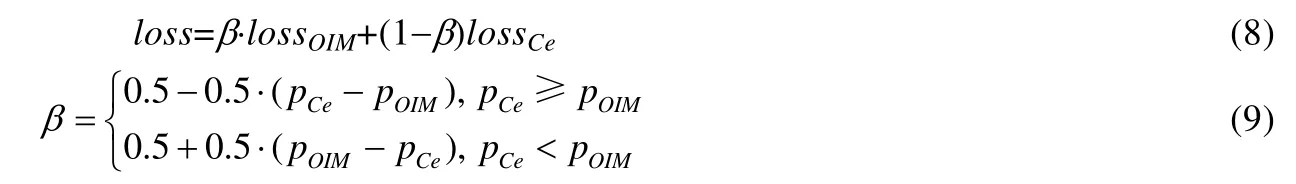
其中,pCe和pOIM表示训练过程中两个损失评估的精度;β是一个可变参数,用于动态分配权重.损失函数的评估精度高,则分配大一点的权重;评估精度低,则分配小一些的权重.通过动态地调整训练权重,使得在训练过程中模型能够更加稳定,表现得更加鲁棒,无标签数据的伪标签精度更高.通过两个大型数据集上的实验,也验证了本文的损失控制策略的有效性.
4 实验与分析
4.1 数据集
MARS[7]数据集是视频行人重识别任务中最大的数据集,数据集包含1 261 个行人,共有17 503 个视频片段和3 248 个干扰视频片段.其中,625 个行人用于训练,636 个行人用于测试.训练集中每个行人平均有13 个视频片段,每个视频片段平均有816 帧.
DukeMTMC-VideoReID[26]数据集包含1 812 个行人,共有4 832 个视频片段.并将行人分别划分为702,702和408 份,分别用于训练、测试和干扰.总共2 196 个视频片段用于训练以及2 636 个视频片段用于测试和干扰.每个视频片段平均有168 帧.
本文使用累积匹配特征(cumulative matching characteristic,简称CMC)曲线和平均准确率(mean average precision,简称mAP)来评估每次迭代模型的性能,并使用符号M表示最终预测无标签视频片段伪标签准确率.
4.2 实验设置
在两个数据集中,为每个行人随机选择摄像机1 中的一个视频片段作为初始化有标签数据集L.如果摄像机 1 没有该行人,将在下一台摄像机中随机选择一个视频片段,以确保每个行人都有一个用于初始化的视频片段.
实验中,本文使用ImageNet[27]预训练去掉最后的分类层的ResNet50 作为NCI 的初始模型.采用动量为0.5且权重衰减为0.000 5 的随机梯度下降(SGD)优化方法.整体学习率初始化为0.1,并在最后15 个周期衰减为0.01.在用损失函数控制策略训练的时候,由于初始数据过少,本文使用CrossEntropy Loss 来进行前几次迭代的训练,以获得稳定的伪标签数据;之后使用本文提出的损失函数控制策略,使得实验过程更加稳定、效果更好.
4.3 实验对比
4.3.1 参数分析
当训练循环到第t步,本文会选择t×p比例的带有伪标签的无标签视频片段用作下一次的模型训练.其中,增长率p的影响见表1、表2.p取0.05~0.3 时,p值越小,rank-1,mAP的精度越高.且当p=0.05 时,rank-1,mAP和伪标签的精度最高,模型性能最好.如图4 所示,当p取0.05,0.10 和0.20 时,前面几次迭代3 张图曲线间的间隙不大,然而后面曲线间的间隙则越来越大,并且p取0.05 时的曲线明显高于0.10 和0.20.原因是错误标签评估在迭代过程中会不断累积,选取伪标签越多错误的累积影响越大.因此,增长率p扩大的越缓慢,选取的正确伪标签越多,从而模型精度rank-1,mAP越高.综合分析,p值取小一些效果会更好.本文以下阐述以p=0.05 和p=0.1 的结果进行比较.
在选取特征空间的数据中心点时,本文使用了平均中心和中位数中心.结果见表1:p取0.05~0.3 时,在MARS 数据集上,中位数中心比平均中心伪标签精度明显更高.其中:当p=0.05 时,中位数中心比平均中心预测伪标签精度高 1.63%;当p=0.10 时,中位数中心比平均中心伪标签精度高2.43%.而p取 0.05~0.3 时,在DukeMTMC-VideoReID 数据集上,平均中心比中位数中心伪标签精度明显更高.其中,p=0.05 时,平均中心比中位数中心伪标签精度高0.8%;当p=0.10 时,平均中心比中位数中心伪标签精度高0.87%.因此,本文实验选用中位数中心作为MARS 数据集的标签评估方式,平均中心作为DukeMTMC-VideoReID 数据集的标签评估方式.

Table 1 Comparison of center selection method correct rate表1 中心选取方式正确率的对比区性 (%)

Table 2 Comparison of NCI and EUG results表2 NCI 与EUG 结果对比 (%)
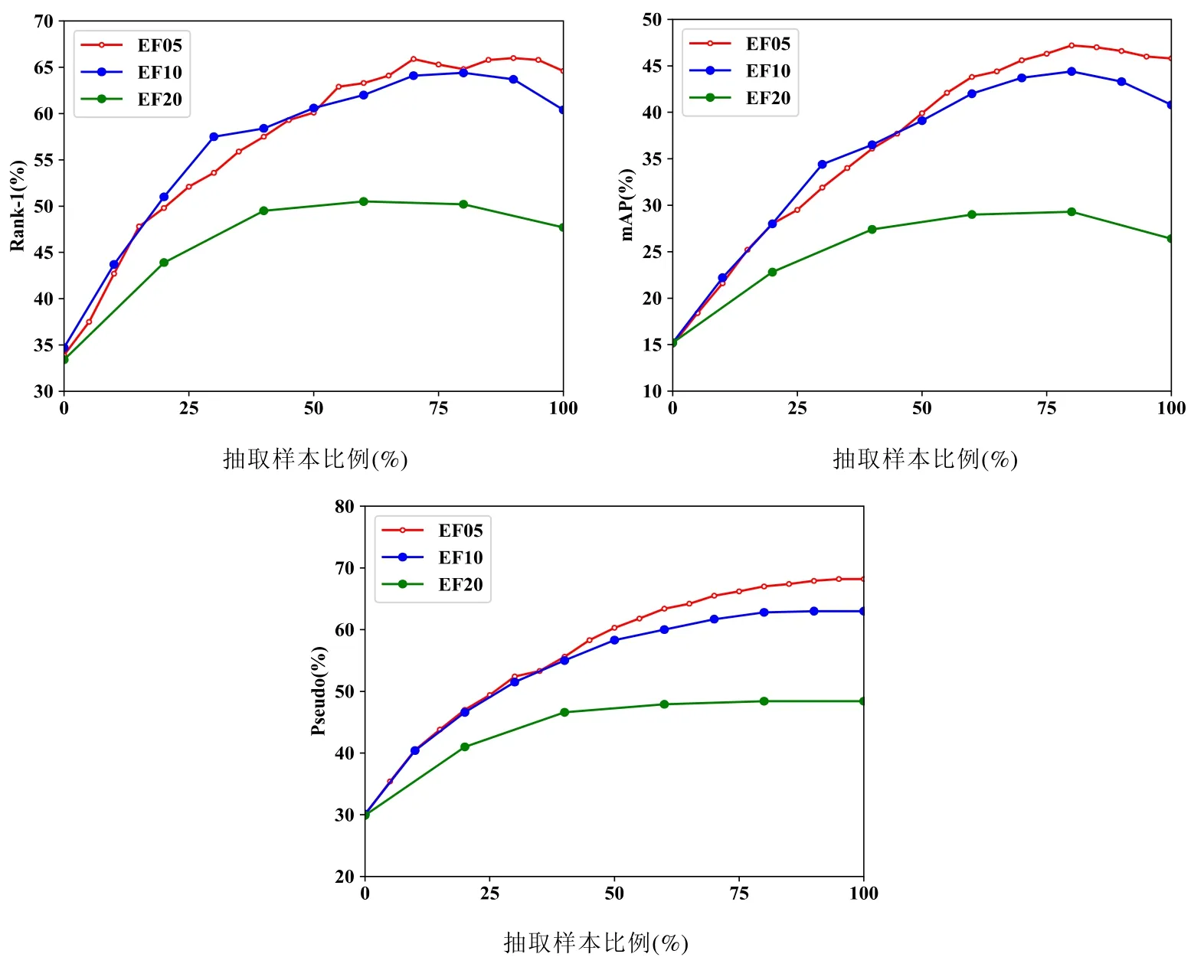
Fig.4 Results of different values of parameter p on the MARS dataset图4 参数p 不同值在MARS 数据集上的结果图
4.3.2 近邻中心迭代策略的有效性
如表2、表3 所示,表示p取0.05~0.3 时,NCI 策略相比于EUG 在rank-1accuracy(%)、mAP(%)、伪标 签准确率M(%)有着全面性的提升.
• 当两种方式均取p=0.10 时,在DukeMTMC-VideoReID 数据集上,NCI 的rank-1 精度提升2.61%,mAP精度提升3.84%,伪标签的预测精度提升1.61%;在MARS 数据集上,NCI 的rank-1 精度提升2.78%,mAP精度提升6.12%,伪标签的预测精度提升4.04%;
• 均取p=0.05 时,在DukeMTMC-VideoReID 数据集上,NCI 的rank-1 精度提升1.61%,mAP精度提升3.17%,伪标签的预测精度提升1.13%;在MARS 数据集上,NCI 的rank-1 精度提升1.93%,mAP精度提升3.35%,而伪标签的预测精度提升1.97%.
综合以上分析能得出,增长率p取0.05~0.3 时,无论是rank-1,mAP精度还是伪标签的准确率,均有了极大的提升.由此得出,本文提出的NCI 相比于最新的策略EUG 有着全面的性能提升.
4.3.3 损失控制策略的有效性
表3 是联合NCI 和损失控制策略分别在DukeMTMC-VideoReID 和MARS 数据集上的实验结果与NCI 在rank-1accuracy(%)、mAP(%)、伪标签准确率M(%)的比较,以验证损失控制策略的有效性.如表3 所示,NCI 和损失控制策略联合训练的结果与NCI 进行比较可得:
• 当均取p=0.10 时,DukeMTMC-VideoReID 数据集上,rank-1 精度提升6.1%,mAP精度提升7.5%,伪标签准确率提升5.36%;在MARS 数据集上,rank-1 精度提升0.7%,mAP精度提升0.6%,伪标签的准确率提升0.51%;
• 当p=0.05 时,DukeMTMC-VideoReID 数据集上,rank-1 精度提升5.9%,mAP精度提升7.6%,伪标签的准确率提升4.82%;在MARS 数据集上,rank-1 精度提升2%,mAP精度提升2.9%,伪标签的准确率提升3.48%.

Table 3 Comparison of loss control strategy results表3 损失控制策略结果的对比 (%)
综合以上分析,本文提出的损失控制策略能有效地提升NCI 的性能,最终提升模型的性能.同时,表3 在同等p值下的实验结果对比,能依次证明本文的NCI 和损失控制策略提升效果明显.
4.3.4 与其他方法比较
表4 是本文的方法NCI 和损失控制策略分别在DukeMTMC-VideoReID 和MARS 数据集上,与其他方法在rank-1accuracy(%)和mAP(%)的比较.表4 中,与本文的对比方法有OIM,BUC,DGM,Stepwise,EUG 和PL 等方法.本文提出的方法相比其他方法对单标注视频行人重识别性能都有明显的提升.本文提出的方法 NCI 在DukeMTMC-VideoReID 数据集上,最高使rank-1 达到74.40%,mAP达到66.40%;在MARS 数据集上,最高使rank-1 达到64.60%,mAP达到45.80%.而在NCI 加上提出的损失控制策略之后,在DukeMTMC-VideoReID 数据集上,最高使rank-1 达到80.30%,mAP达到74.00%;在MARS 数据集上,最高使rank-1 达到66.60%,mAP达到48.70%.性能远超过DGM,Stepwise,EUG 和PL 等方法.
NCI 和损失控制策略联合训练的最终结果与无监督的方法OIM 和BUC 相比,在DukeMTMC-VideoReID和MARS 数据集上有着明显的优势.相比于单标注视频行人重识别最新的方法EUG 和PL 有很大提升.
• 当p=0.05 时,在DukeMTMC-VideoReID 数据集上,rank-1 分别提升了7.51%,7.4%,mAP上分别提升了10.77%,10.7%;在MARS 数据集上,rank-1 分别提升了3.93%,3.8%,mAP上分别提升了6.25%,6.1%;
• 而当p=0.10 时,在DukeMTMC-VideoReID 数据集上,rank-1 分别提升了8.71%,8.5%,mAP上分别提升了11.34%,11.2%;在MARS 数据集上,rank-1 分别提升了3.48%,3.2%,mAP上分别提升了6.72%,6.5%.

Table 4 Comparison of accuracy between NCI and other methods表4 NCI 与其他方法的结果的对比 (%)
综合以上分析,说明本文NCI 和损失控制策略联合训练,相比于同类的方法有很大的提升,从而验证了本文提出的近邻中心迭代策略和损失控制策略的有效性和优越性.
5 结束语
单标注学习的错误标签估计会严重降低模型的鲁棒性,无标签视频片段的标签估计对于单标注视频行人重识别至关重要.针对这个问题,本文提出了一种近邻中心迭代策略.该策略从简单可靠的无标签视频片段样本开始,逐步更新用于预测伪标签的度量中心点,获取更加可靠的伪标签数据来更新模型.每次选取的可靠伪标签数据以较慢的速度增加.此外,本文提出了一种新的损失训练策略,能使得训练过程更加稳定又能缩小类内距离,从而获得可靠的伪标签数据和更鲁棒的模型.本文方法的有效性在MARS 和DukeMTMC-VideoReID 两个大规模数据集上得到了很好的验证.
