案件要素句子关联图卷积的案件舆情摘要方法*
2021-02-25韩鹏宇余正涛高盛祥黄于欣郭军军
韩鹏宇,余正涛,高盛祥,黄于欣,郭军军
1(昆明理工大学 信息工程与自动化学院,云南 昆明 650504)
2(云南省人工智能重点实验室(昆明理工大学),云南 昆明 650504)
案件舆情是指与案件相关的互联网舆情,与一般的新闻舆情相比,案件舆情具有敏感性、特殊性,有着更大的社会影响.案件舆情摘要能够从案件相关新闻文本中摘取重要信息,从而简化新闻文本长度,帮助用户在大量的舆情数据中获取舆情事件的关键信息,对于案件舆情的监控与及时处理有着重要的作用.
案件舆情摘要本质上是一种特定领域的多文档摘要任务,在多文档摘要的研究中,关键问题是对句子的重要性进行评价,并以此抽取摘要句子.传统方法有基于统计的摘要方法[1-4]、基于主题模型的摘要方法[5-7]和基于图的摘要方法[8-11]等.基于统计的方法一般通过词频、句子位置、句子相似度等这类特征来评价句子的重要程度,然后通过一定的策略选取重要句子得到摘要,其中具有代表性的方法有基于词频-逆文档频率(TF-IDF)的统计方法[1].Hong 等人[4]提出了一种简单的多文档摘要方法,用词的概率作为输入,然后选择平均词概率较高的句子作为摘要.基于主题模型的方法一般采用狄利克雷分布(LDA)的方法得到文本簇中预设数量的主题,然后采用不同的算法计算句子和主题的相似度来得到摘要句.例如:刘娜等人[6]引入主题重要性的概念,将LDA 建立的主题分成重要和非重要两类,并使用词频、位置等统计特征和LDA 特征一起计算句子权重;吴仁守等人[7]提出一种方法将新闻事件划分为多个不同的子主题,在考虑时间演化的基础上同时考虑子主题之间的主题演化,最后将新闻标题作为摘要输出.还有很多研究者提出了一些基于图的方法[8-11],将文本表征成一张图,图中使用句子或其他单元作为顶点,用边连接两个有相似性或者关联关系的顶点,使用各种方法计算句子相似度或关联关系来构建边.典型的有Mani 等人在1997 年最早使用图模型进行多文档摘要任务的研究[8].Mihalcea 等人在基于PageRank 算法的基础上,提出了一种基于图排序的TextRank 模型[9].Li 等人[10]利用主题和句子之间的关系,将主题模型集成到图排序中.Yasunaga 等人[11]提出一种图卷积的多文档摘要方法,统计句子中出现的动名词组合数、位置信息等特征来进行构图,然后用图卷积的方法对句子进行分类.
基于统计的摘要方法虽然实现简单且有一定效果,但对于句子的打分一般都是比较孤立的,忽略了文本结构信息、尤其是句子与句子之间的关联关系.基于主题模型的方法一般针对没有特定主题的多文档摘要任务,不适合主题明确的案件舆情摘要.基于图的方法虽然可以较好地表征句子间的关联关系,但构图方法一般是通用方法,不涉及特定要素或关键词之间的关联关系.
以上方法无论是基于统计、主题模型和图模型的,多是通用领域的无监督多文档摘要方法.针对案件舆情这一特定领域问题,需要更好地考虑案件主题的相关信息以及跨文档句子之间的关联关系.同一案件相关的多篇新闻文本构成一个文本簇,具有与特定案件相关的主题,这一主题可以通过一些案件要素来进行表征.如表1所示,在“奔驰女车主维权案”中,案发地、涉案主体、案件描述:“西安、奔驰4s 店、女车主、利之星、发动机漏油、消费者维权”等关键词就是该案件的案件要素,代表其主题信息.可以看出:这些案件要素贯穿于多篇新闻文本,共现于和案件主题相关的句子当中,并且集中出现在参考摘要中,对于句子关系的表征和摘要生成的准确性都有着重要的作用.又因为句子都是词的集合,因此在抽取句子形成摘要的过程中,需考虑异构的句子关联图特征:借鉴基于统计的方法,引入词节点来得到句子的特征表示,借助案件要素节点来加强与案件主题相关的句子间的关联关系,然后再学习这些关系来对句子的重要性进行评价.在如何对图进行学习方面,借鉴Yao 等人提出的一种基于图卷积的文本分类方法[12]使用两层图卷积神经网络来对图中节点的特征进行学习,可以很好地学习到图中的结构信息.针对以上分析,本文探索在句子关联图中用词节点和案件要素节点强化句子间关联关系的表征,研究使用图卷积的方法预测句子的得分,然后经过去重和重排序进而得到摘要.
本文的主要贡献总结如下:
1) 提出在案件舆情领域进行多文档摘要的研究探索,创新性地引入案件要素信息来指导摘要句的抽取;
2) 提出一种基于案件要素句子关联图卷积的摘要模型,融入案件要素节点、词节点,并构造异构图来对文本簇进行建模,有效利用了文本语义特征、句子与案件要素之间的关联关系等特征;
3) 与多种多文档摘要方法进行比较评估,在收集的案件舆情摘要数据集上进行了实验,验证了本文方法的有效性.

Table 1 Case analysis of case-related public opinion表1 案件舆情实例分析
1 模型结构
本文提出一种基于图卷积的案件舆情摘要方法,融合句子、词和案件要素共同构建跨文档的句子关联图,再用图卷积的方法得到每个句子的重要性得分,经过去重和重排序得到文本摘要.模型部分参考了Yao 等人2019 年在文本分类领域有关图卷积的相关工作[12],将其应用于多文档摘要领域,并进行了改进,具体结构如图1所示(图中展示了一个案件对应的文本簇的核心处理过程,圆角矩形节点表示句子,矩形节点表示词,菱形节点表示案件要素,圆形节点表示句子的分类),其中,S1.2表示第1 个文本中的第2 个句子,W表示词,C表示案件要素.
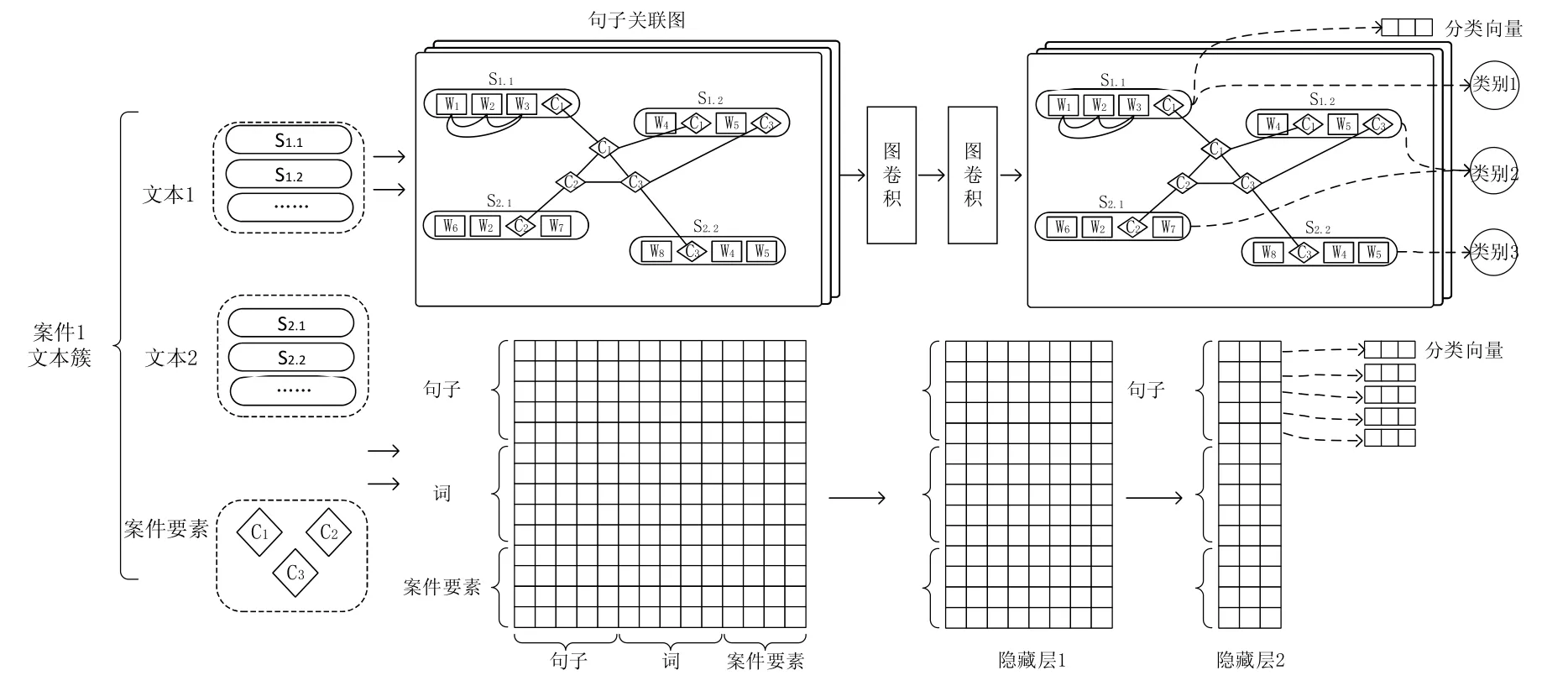
Fig.1 Case-related public opinion summarization method based on graph convolution of sentence association graph with case elements图1 基于案件要素句子关联图卷积的案件舆情摘要模型
模型包括3 个主要部分,分别是融合案件要素的句子关联图模块、基于图卷积的句子分类模块、摘要生成模块.下面分别对以上部分进行介绍.
2 融合案件要素的句子关联图构建方法
2.1 案件要素
案件舆情文本摘要可以看作特定领域的摘要问题,同一案件相关的多篇新闻构成一个文本簇,这些文本具有相同的案件相关信息.通过对案件本身和新闻舆情的特点进行分析,定义了一些案件要素来表征案件的主题信息,包括“案件名、案发地、涉案人员、案件描述”这4 个要素作为案件要素,具体实例见表2.

Table 2 Case elements表2 案件要素表
表2 中以南京摩托车飙车案为例,“案发地”包括案发的城市地区和案发的具体场所,例如“江苏、南京、高速公路”等.“涉案主体”不仅仅局限于受害人、嫌疑人和其代称,还包括关键证人,相关家属等所有与案件相关人员.“案件描述”是指发生的是什么事情以及一些其他案件关键词,例如“飙车、危险驾驶”等.通过对每一个案件构建一组案件要素,来表征案件相关信息.共构建了50 组案件要素.
2.2 关联图构建方法
本节引入词节点来得到句子的特征表示、句子间的关联关系,借助案件要素节点来加强与案件主题相关的句子间的关联关系.使用词频-逆文档频率(TF-IDF)、互信息(PMI)、同属关系、包含关系等方法来计算边的权重,构建了一个包含句子、词和案件要素这3 种节点的句子关联图:

其中,集合V表示图中节点的集合,由3 部分构成:句子集合S、词集合W和案件要素集合C.
• 句子集合s={s1,s2,…,sl}里共有l个句子,是不同文本簇的所有文档经过去除特殊字符、分句、去除短句子等预处理之后的句子总和.其中,s2表示第2 个句子,l表示句子集合的大小;
• 词集合w={w1,w2,…,wm}是对所有文本簇使用jieba 分词工具进行分词以及去停用词等操作后得到的词表,其中,m表示词表大小;
• 案件要素集合c={c1,c2,…,cn}共有n个案件要素,包括所有不同案件的案件要素,其中,c2表示第2 个案件要素.E表示图中边的集合:E={(vi,vj)|v∈V},其中,vi表征图中第i个节点.
因为图中有3 种节点,所以图的邻接矩阵A 由9 个分块矩阵构成,见公式(3).其中,ASS表示句子和句子 节点的关系矩阵,ASW表示句子和词节点的关系矩阵,表示句子和案件要素关系矩阵的转置:

共有6 种边,每种边的定义和计算见公式(4):

其中,Aij表示第i和第j两个节点之间边的权值.这6 种关系的具体计算方法是:
(1) 对于句子与句子关系矩阵ASS,使用同属关系来计算:当一个句子和另一个句子同属于一个文本时,在它们之间连接一条边;
(2) 对于句子与词关系矩阵ASW:使用词频-逆文档频率(TF-IDF)的方法来计算词节点wj和句子节点si之间边的权重,见公式(5):

其中,si表示第i个句子节点,wj表示第j个词节点,TF表示词在句子中的词频,IDF表示词在所有文本中出现的频率.当一个像“的”这样的高频词在所有文本中出现的频率越多,其IDF值就越低.通过在句子和大量词之间构建关联关系,可以用词来表征句子的特征,同时也在所有句子之间构建了一层关联关系;
(3) 对于句子与案件要素关系矩阵ASC,使用包含关系来计算:当一个案件要素出现在某个句子中时,在它们之间连接一条边;
(4) 对于词与词关系矩阵AWW:使用互信息(PMI)来计算两个词节点之间边的权重,见公式(6):

其中,wi和wj表示第i和第j个词节点,两个词的相关性越大,其PMI值也就越大.当PMI的值小于0时,表示两个词相关性为负,也就是互斥的,此时,两个词之间边权重为0;
(5) 对于词与案件要素关系矩阵AWC:案件要素会出现和某一个词相同的情况,当案件要素和某一个词恰好相同时,在它们之间连接一条权重为1 的边;
(6) 对于案件要素与案件要素关系矩阵ACC,使用同属关系来计算:当一个案件要素和另一个案件要素同属一个案件时,在它们之间连接一条边.
通过以上方法,可以构建一个融合案件要素的句子关联图.下一步,在此基础上使用图卷积的方法得到每个句子的重要性评价.
3 图卷积层
图卷积网络(GCN)是一种在图上学习的神经网络,可以直接处理图,并利用图的结构信息.图卷积网络具有强大的学习能力,研究表明:两层的GCN 即可以得到很好的学习效果,过多的层数可能导致节点之间更加趋同.因此,在本文实验中也采用两层的GCN.
在第2.2 节构造的句子关联图G中,节点总数size=l+m+n.因为每一个节点在进行图卷积的时候,既要包含周围节点的特征,又要包含自身的特征,所以每个节点还应该有一个连接到其自身的闭环,还需要将邻接矩阵A 对角线上元素初始化为1,即Aij=1,最后构成一个大小为size×size的图的邻接矩阵A:

令图的度矩阵为D,表示每一个节点和多少个其他节点相连,其中,度矩阵对角线上元素为

根据公式(7)和公式(8),可以得到可以进行图卷积操作的规范化的矩阵:

将节点的特征矩阵X 初始化为一个和邻接矩阵A 一样大小的单位矩阵,相当于使用one-hot向量表示节点的特征.
在第1 层图卷积网络中:

其中,L(1)表示第1 层的输出,是规范化的邻接矩阵,X 是特征矩阵,W1是参数矩阵,激活函数使用ReLU.在第2 层图卷积网络中,使用softmax进行分类,如公式(11)所示:

采用交叉熵作为模型的损失函数:

其中,s是训练集中参与计算损失的所有句子,yi表示第i个句子的标签,表示第i个句子的预测结果.通过两 次图卷积操作后,可以得到每一个句子节点的分类结果,表示每一个句子的得分.
4 摘要生成
摘要句既要反映文档的中心思想,又要具有低冗余性和一定的时序关系.通过前面的方法得到每一个句子评分之后,需要从中选取得分最高的几个句子,对其进行去重和排序,具体流程如下所示.
(1) 对于测试集中不同的文本簇,分别进行摘要生成;
(2) 对于一个文本簇,首先选取一个得分最高的句子加入候选摘要句集合中;
(3) 然后选取下一个句子和候选摘要句集合中的每一个句子计算相似性,其值若小于相似性阈值,则将该句子加入候选摘要句集合中;
(4) 重复第(2)步的操作,直到候选摘要句集合长度超过摘要预期长度;
(5) 最后再对候选摘要句集合中的句子按照文档的爬取顺序(代表文章发表的时序)以及句子在文档中出现的顺序排序,得到最终的多文档摘要.
5 实 验
5.1 数据集
本文针对50 个案件,构造50 组案件要素,使用爬虫程序从互联网上搜集相关新闻,对数据清洗去噪,得到50个文本簇.每个文本簇包含10 篇文档.对每个文本簇人工撰写摘要,最终构建出案件舆情摘要数据集.见表3.

Table 3 Dataset表3 数据集
5.2 评价标准
本文采用自动摘要任务中常用的一种评价指标ROUGE 来作为介绍评价指标.ROUGE 是基于摘要中n元语法(n-gram)的共现信息来评价摘要的一种方法,包括ROUGE-1,ROUGE-2 等.ROUGE-L 和ROUGE-N 相似,是一种基于最长公共子序列的评价方法.ROUGE 值越高,说明摘要效果越好.例如,ROUGE-N 的一般计算方法见公式(13):
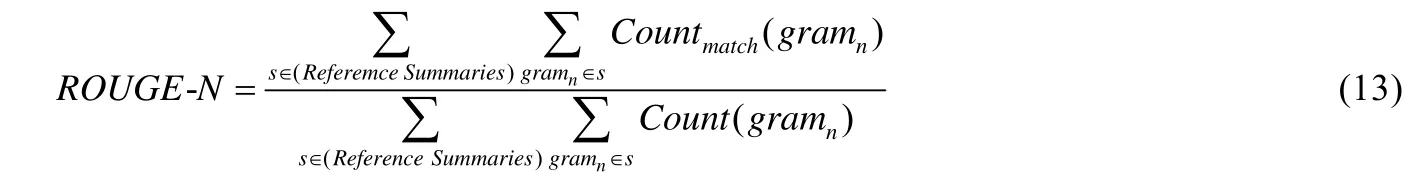
其中,分子表示模型输出的摘要和参考摘要中同共现的n-gram 的个数,分母则表示参考摘要中的n-gram 个数.
5.3 实验设置
实验采用2 层图卷积网络,特征矩阵每一行使用one-hot向量来初始化,第1 层输出的节点特征向量为200维,第2 层输出的节点分类向量为10 维.Dropout设置为0.5,学习率设置为0.02,训练轮次设置为400,提前截至的容忍度设置为12,摘要预期长度设置为200.
本文共设置了3 组对比实验和1 个实例分析.
• 第1 组对比实验对比了本文模型和10 个基准模型的性能,其中包括未融入案件要素的消融实验:“句子+词+GCN”;
• 第2 组对比实验研究了不同句子分类数目对生成摘要质量的影响,设置2,5,10 和20 等4 种不同的分类数目,使用本文模型分别进行实验;
• 第3 组实验研究了去冗余步骤中,不同相似度计算方法对摘要的影响,其中,rouge 方法阈值设置为0.8、jaccard 方法阈值设置为0.8、tf-idf 方法阈值设置为0.8 和word2vec 方法阈值设置为0.9;
• 实例分析选取了针对“快递员遭投诉自杀”案件的摘要实例进行对比分析.
5.4 基准模型
本文共选择了10 个基准模型,分别在案件舆情摘要数据集上进行实验,得到ROUGE-1,ROUGE-2 和ROUGE-L 这3 种评分.基准模型包括LEAD,Centroid,LexPageRank,TextRank,Submodular,ClusterCMRW,Query+ MR,LDA,Manifold-Ranking 和“句子+词+GCN”,其中,部分代码由开源工具包PKUSUMSUM 提供.
• LEAD 是一种依靠句子在文章中的位置来抽取摘要的方法,研究表明,文章中的重要信息很大概率会出现在文章开头部分;
• Manifold-Ranking[13]是一种类似PageRank 的方法,利用流行排序进行多文档摘要;
• Query+MR 在Manifold-ranking 模型的基础上增加了一个案件要素集合作为查询句,来对句子节点之间的权重进行调整,然后得到摘要;
• LDA 方法通过使用LDA 对文本簇进行主题聚类,然后寻找含有主题信息最多的句子作为摘要;
• Centroid[14]是一种基于质心的多文档摘要方法,通过寻找中心词最多的句子来得到摘要;
• ClusterCMRW[15]是一种基于马尔科夫链和随机游走的多文档摘要方法,利用文档集中句子之间的链接关系来生成摘要;
• Submodular[16]利用次模函数的单调递减特性来抽取句子作为摘要;
• LexPageRank[17]和TextRank[9]都是一种基于图的关键词提取算法,将句子视为节点,通过计算图中每个节点的得分,来选择得分最高的几个句子作为摘要;
• “句子+词+GCN”表示未融入案件要素的图卷积神经网络方法.
5.5 实验结果分析
第1 组实验为了验证本文模型的有效性,与10 个基准模型进行了对比实验,其中,和“句子+词+GCN”对比以验证融入案件要素的有效性.选取ROUGE-1,ROUGE-2 和ROUGE-L 这3 种评分,实验结果见表4.
根据表4 的实验结果可以看出:
1) 在采用ROUGE-1 的评价方法中,本文模型和其他基准模型相比,有0.43~6.07 的提升,说明了本文模型的优越性;
2) 对比TextRank,LexPageRank 和本文模型,虽然同为基于图的方法,但是图卷积比这两种方法具有显著的效果提升,充分说明了图卷积方法在多文档摘要任务上的优越性;
3) 对比“Manifold-Ranking”和“Query+MR”的结果可以看出,引入案件要素作为查询条件来指导摘要生成是有作用的;
4) 对比“句子+词+GCN”和本文模型的ROUGE-1 和ROUGE-2,本文模型分别提升了3.37 和2.92,说明在案件舆情领域,融合案件要素构建句子关联图的方法是有效的,能够很好地表征跨文档句子之间的关联关系,对于指导抽取出更贴近多文档主题的摘要句有着重要作用.
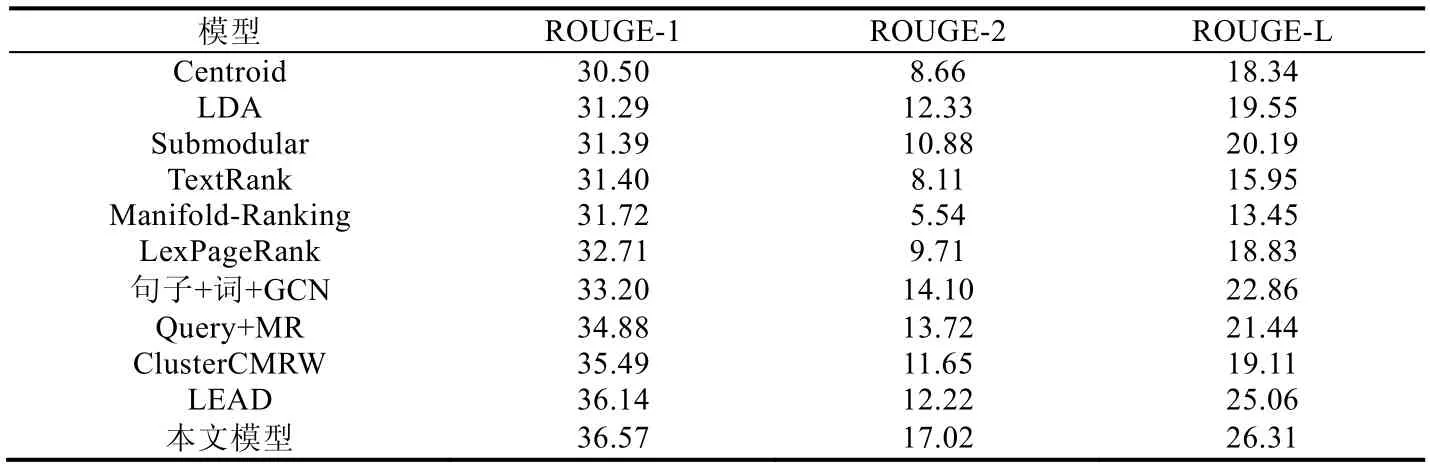
Table 4 Comparison of experimental results between our model and the baselines表4 本文模型与基准模型实验对比结果
第2 组实验研究了使用图卷积进行句子分类时,句子的不同分类数目对于摘要质量的影响.设置2,5,10和20 等4 种不同的句子分类数目,选取ROUGE-1,ROUGE-2 和ROUGE-L 作为评价指标,实验结果见表5.

Table 5 Comparison experiments of different classification numbers表5 不同分类数目对比实验
根据表5 的实验结果可以看出:在句子分类数目为10 的时候取得的摘要效果最好,分类数目较低会略微降低摘要质量,分类数目过高会严重降低摘要的质量.分析可能是因为分类数目的不同导致了句子分类准确率的不同.
第3 组实验研究了不同相似度计算方法对摘要性能的影响,分别使用rouge(0.8),jaccard(0.8),tf-idf(0.8)和word2vec(0.9)等4 种.其中,基于word2vec 使用词向量+average pooling 来表示句子信息.选取ROUGE-1,ROUGE-2 和ROUGE-L 作为评价指标,实验结果见表6.

Table 6 Comparison experiments of different similar computing methods表6 不同相似度计算方法对比实验
根据表6 的实验结果可以看出:前3 种相似度计算方法得到的结果一致.可能的原因是:在本实验中,得分较高的几个句子之间的差异性是比较大的,这3 种方法对句子差异性的敏感程度是相似的.Word2vec 的方法效果略好一点.
如表7 的实例分析中,从测试集中选取了“快递员遭投诉自杀”案件,针对该案件的部分基准模型生成的摘要进行实例分析.
根据表7 可以看出:
1) 对比TextRank 和本文模型,本文结果在事件表述的完整性上有着较好的效果;
2) 对比Centroid 模型结果,本文模型摘要更加贴近文本簇的中心思想;
3) 对比“句子+词+GCN”的结果可以看出本文模型在连贯性和可读性上有一定的优势.

Table 7 Example of summary comparison of “courier suicide”表7 “快递员遭投诉自杀”案摘要对比实例
6 结束语
针对案件舆情摘要任务,本文提出一种融合案件要素关联和句子关联的构图方法,有效地通过案件要素融入了案件主题信息,很好地表征了跨文档的句子关联关系.使用图卷积的方法充分学习到了图中的结构信息,抽取的摘要句和基准模型相比取得了一定的效果提升.
在下一步的工作中,拟更多地去探索上下文关系、语义关系、篇章结构关系和逻辑关系等其他关系对摘要生成的作用.
