分类梯度提升算法(CatBoost)与蝙蝠算法(Bat)耦合建模预测中国西北部地区水面蒸发量
2021-02-25董力铭曾文治雷国庆
董力铭,曾文治,雷国庆
(武汉大学水资源与水电工程科学国家重点实验室,武汉430072)
0 引 言
蒸发是气象科学、水资源评价和水循环的重要内容[1,2]。精准的预测水面蒸发对于干旱、半干旱地区的水资源合理规划、农业节水灌溉及水资源评价具有重要意义和价值[3,4]。预测水面蒸发量的方法大致分为2 类:实地测量法及模型估计法。其中,实地测量法如蒸发皿测量法,虽然可以得到较为精确的结果,但十分容易受到田间状况、人工成本、极端天气情况等因素的限制,制约了其应用的范围[5,6]。同时,由于蒸发过程具有高度非线性、复杂性和不稳定性等特点,较难建立包含所有相关因素的,具有较强普适性的经验数学模型[7−9]。
近年来,随着机器学习及启发式搜索算法的快速发展及其在解决非线性复杂问题上的巨大优势,已有许多学者将机器学习如人工神经网络(ANN)[10,11]、多元自适应回归曲线(MARS)[6,12]、 随 机 森 林(RF)[13]、 分 类 梯 度 提 升(CatBoost)[14]等算法应用于蒸散发、水面蒸发等方面的模拟并得到较为准确的水面蒸发预测精度。其中,CatBoost模型以其强大的特征分类能力及高准确度,受到学者们的广泛关注。Huang[14]将CatBoost模型与SVM模型和RF模型在估算中国湿润地区ET0时进行了对比,发现CatBoost模型不仅在精度和稳定性方面具有显著优势,在计算时间和内存使用方面也同样更为优越。然而CatBoost模型需要设置的参数较多,增加了陷入局部最优解的可能性。为此,利用具有强大搜索功能的蝙蝠算法进行耦合,提升CatBoost模型处理参数的能力,进而增强模型预测准确度及鲁棒性是一种可行且有效的办法[15]。
本文针对我国西北部干旱地区的水面蒸发量预测,建立耦合蝙蝠算法的改进CatBoost模型(Bat−CB),测试其预测能力,并与原CatBoost模型及较为常用的随机森林模型(RF)进行对比,进而提出适用于干旱、半干旱地区的水面蒸发模型。
1 材料与方法
1.1 随机森林法(RF)
随机森林法是基于分类和回归树,利用自动聚集(bootstrapping)及“bagging”方法等集成策略来处理高维回归问题的算法[16]。随机森林通过bootstrap 重抽样方法从原始数据集中随机抽取子训练集,并在采集后将其放回,直到达到指定的节点数。没有被采集的数据称为“箱外数据”,用来计算泛化无偏误差并提高精度。最后,通过对决策树投票或取平均值的方式做综合评价,生成最终结果[17]。目前,随机森林算法已广泛应用于模型预测的领域,本文也因此选择随机森林作为对比的对象,探究水面蒸发模型的预测能力。
1.2 分类梯度提升算法(CatBoost)
CatBoost 是一种基于梯度增强决策树(gradient boosting decision tree,GBDT)算法的新型机器学习算法。相对于其他的早期GBDT 算法如XGBoost 和LightGBM,CatBoost 在很多方面都有较大提升,特别是在处理大量数据和特征的时候。CatBoost 功能的增强主要体现在3个方面。首先,CatBoost 采用“有序原则”的方式避免了GBDT算法的迭代过程中固有存在的条件位移问题,并使其可以利用整个数据集进行训练和学习。其次,CatBoost 将传统的梯度增强算法转化为有序增强(Ordered Boosting)算法,解决了迭代过程中梯度偏移这一不可避免的问题,提高了泛化能力,降低了模型过拟合的可能,增强了模型的鲁棒性[18]。最后,CatBoost 通过贪婪策略(Greedy Strategy)构造分类特征的组合,并将这些组合作为附加特征,这有助于模型更容易地捕获高阶依赖关系,进一步提高预测精度。此外,CatBoost 选择健忘决策树(Oblivious Decision Trees)作为基础预测期,降低了过拟合的可能并加快了模型的执行速度。
1.3 耦合蝙蝠算法的CatBoost模型(Bat-CB)
蝙蝠算法是由Yang[19]提出,仿生蝙蝠觅食行为,利用每只微型蝙蝠发出高频脉冲来搜索目标,并分析其独特的回声信息特征来定位目标的元启发式算法。在数学上,它的实现方法如下面步骤所示。
第1步:创建蝙蝠数量,赋予每只蝙蝠初始速度vi、频率fi和位置xi。
第2步:在每一次迭代过程中,在t时刻将3个特征按下面公式更新:
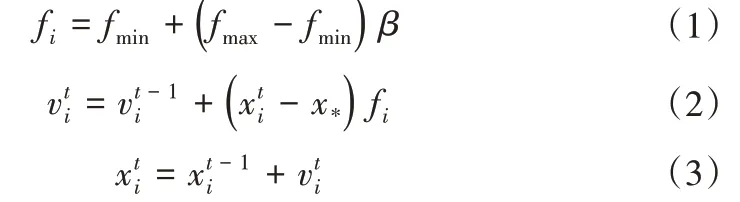
式中:β∈(0,1)为正态分布的一个随机向量;和为蝙蝠在时刻t更新的位置和速度;x*是当前最佳位置(解决方案)。
第3步:生成一个随机数rand用以判断当前位置是否需要改进,若rand>At,则蝙蝠通过rand步长来更新自己的最佳位置:
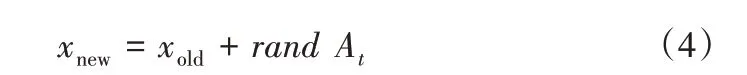
式中:rand∈[−1,1];At为t时刻所有蝙蝠的平均响度。
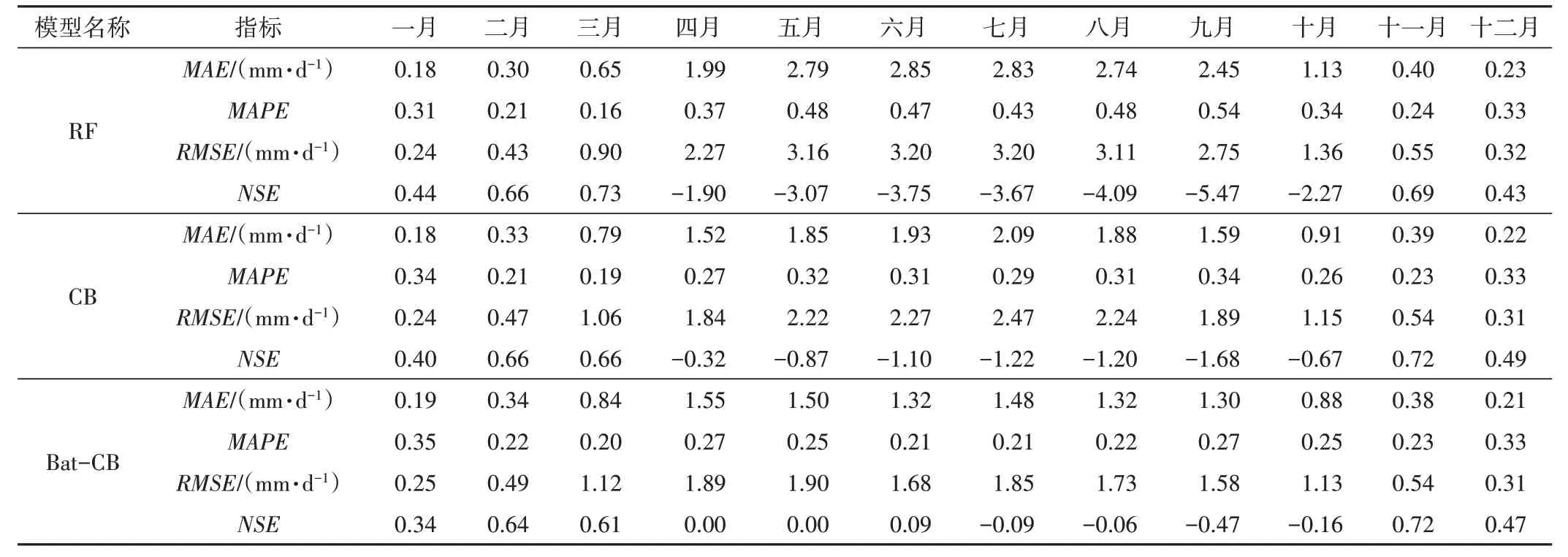
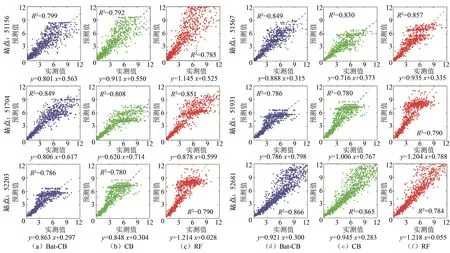
第4步:生成另一个随机数,如果rand 式中:α和c均为常量,0<α<1且c>0。 第2步至第4步的迭代过程将一直持续到达到最大迭代次数或要求的精度为止。最后,对所有蝙蝠的适应度进行排序,得到最佳位置(最优解) 在本文中,使用蝙蝠算法优化了CatBoost模型的3个最为关键的参数,分别为决策树的数量(nrounds)、学习速率(eta)和树的最大深度(depth)。理论上可以强化梯度增强功能,显著提高预测能力。 试验区为中国的西北部干旱及半干旱地区的45个气象站所形成的区域,约占中国总面积的1/6(见图1)。该地区属于典型的温带大陆性气候,酷热、干燥、日照充足、降水稀少,并且蒸发量随季节变化较大,夏季的蒸发量是春季和冬季的10~30倍。水面蒸发实测值作为校核模型预测能力的基准,由西北45个气象站以蒸发皿测量得到。而数据集则由西北45个气象站2006−2017年间包括最低气温、最高气温、相对湿度、风速及太阳辐射5个因素的逐日长系列数据构成。另外,由于研究区内可直接测量辐射参数的气象站有限,太阳辐射的数据不足,因此,根据Fan[20]采用经验Angstrom−Prescott模型(A−P模型),利用日照天数(R0)和日照时间(N,h)来计算全球太阳辐射这一参数。此外,数据分为2 组,一组(2006−2013)用于开发和训练3个模型,另一组(2014−2017)用于模型测试。气象数据见表1。 图1 45个研究站点分布图 本文采用均方根误差(RMSE)、平均绝对误差(MAE)、纳什系数(NSE)和平均绝对误差百分比(MAPE)评价模型的训练与测试精度。4种统计学评价指标的具体计算方法如下: 式中:YEST,i和YOBS,i分别表示水面蒸发的预测值和观测值;YOBS,i,MEAN表示水面蒸发观测值的平均值。 为检验上述3种模型对于试验区域水面蒸发的预测能力,本文采用4个常用的统计指标,分别为均方根误差(RMSE)、平均绝对误差(MAE)、纳什系数(NSE)及平均绝对百分比误差(MAPE)。模型在训练阶段及测试阶段的统计指标见表2。 在模型的训练阶段,3种模型在不同的各项统计指标中表现出结果的高度一致性。RF模型(RMSE: 0.127~0.528 mm/d;MAE: 0.077~0.353 mm/d;NSE: 0.981~0.995;MAPE:0.042~0.081)的各项指标均优于CB模型及Bat−CB模型。而Bat−CB(RMSE:0.288~1.125 mm/d;MAE:0.166~0.846 mm/d;NSE: 0.908~0.952;MAPE: 0.115~0.167)模型略优于CB 模 型(RMSE: 0.300~1.322 mm/d;MAE: 0.180~0.851 mm/d;NSE: 0.894−0.950;MAPE: 0.131~0.181)。但在模型的测试阶段,RF模型的预测能力显著弱于Bat−CB模型及CB模型,这说明RF模型在3个模型中存在着最严重的过拟合问题,这与Zhang[21]在探究CatBoost、RF 和GRNN 3种模型在ET0预测上的研究结果一致。而Bat−CB模型在测试阶段依旧强于CB模型,并且在最大值(Max)及标准差(SD)这2个指标上提升最为明显。这说明改进的Bat−CB模型在总体上降低了CB模型存在的过拟合问题的影响,并提升了模型的整体性能和预测能力。胡梦月等[22]利用改进的蝙蝠算法优化KELM模型的2个参数,证明了利用蝙蝠算法的搜索功能可有效提升KELM模型预测能力。综上所述,改进的Bat−CB模型的预测能力优于CB模型及RF模型。 此外,由于难以将45个站点中每一个站点的模拟情况全部展示出来,故本文随机从45个站点中随机选取6个分散的站点进行散点图的绘制,进一步检验模型的预测能力,结果见图2。 图2表明,当蒸发量较小时3个模型均有较好的预测结果。但当蒸发量大于4 mm/d时,RF模型的预测值与实测值的偏离明显变大,逐渐偏离1∶1 线。考虑到试验区域每年大部分时间蒸发量较大,RF模型在干旱、半干旱地区的实用性和准确度总体上明显弱于Bat−CB模型及CB模型。而相对于CB模型,改进的Bat−CB模型在全部6个点的精度更高,尤其是在51567 站点及51704 站点上。因此,在蒸发量较大的情况下,Bat−CB模型相对于RF模型和CB模型具有更高的准确度和稳定性。 在评估模型整体预测能力时,使用预测值与实测值之间绝对误差的频率分布图是一种常用且有说服力的方法之一。本文绘制了以上6个站点的绝对误差分布直方图,见图3。 在以上6个站点中,3种不同的模型在预测水面蒸发量时,都有大约50%的站点的绝对误差低于0.4 mm/d,并且绝对误差从0 到2 mm/d 增加过程中对应站点的所占比例逐渐降低。在3个模型中,Bat−CB模型在全部站点的绝对误差值中,都有着最高比例小于0.4 mm/d 的分布及最低比例大于2 mm/d的分布。但RF模型在大多数站点中的表现劣于Bat−CB模型及CB模型。同时,从总体上看,改进的Bat−CB模型相对于CB模型,各个站点的预测能力均有所提升,在蒸发量较大的情况下,提升更为明显。因此,Bat−CB模型的整体性能和预测能力强于CB模型和RF模型。 最后,针对我国西北部干旱、半干旱地区较大蒸发量的气候状况,本文分析了水面蒸发的季节性变化对于模型预测能力及稳定性的影响。3种模型预测指标的月平均值见表3。 目前,大多数机器学习模型在预测非平衡或有极大数值的数据集时经常表现出脆弱性和不稳定性[23]。由表3可知,在11月至3月,试验区域的蒸发量较小,3种模型的性能相差不大,但在每年的4月至10月,Bat−CB模型相对于CB模型及RF模型的优势逐渐显露出来。RF模型在处理不平衡数据集时适应性较差的特点,在蒸发量季节性变化的预测之中体现得较为明显。而从平均绝对百分比误差(MAPE)指标上来看,Bat−CB模型在不同月份间没有明显差异,体现出较强的均衡性及稳定性。 表1 本文所选45个气象站点的地理及气象信息Tab.1 Geographical and meteorological information of the 45 stations selected for this study 表2 3种模型在中国西北部水面蒸发预测中的统计指标表现Tab.2 Statistical indicators of three machine learning models for predicting the pan evaporation in northwest China 图2 随机6个站点中水面蒸发量的实测值(OBS)及3个模型的预测值(FOR)绘制的散点图 因此,综合上述全部方面,Bat−CB模型整体上表现显著优于CB模型及RF模型,并且在有较大变化的数据集中学习和训练的过程中更为精确和稳定,适用于类似于干旱、半干旱地区水面蒸发量等有较大变化或季节性改变的预测领域。 本研究建立了一种新型的耦合了蝙蝠算法的CatBoost机器学习模型(Bat−CB),并评价了该模型在西北干旱、半干旱地区水面蒸发量预测中的应用。结果表明,Bat−CB模型在干旱和半干旱地区具有较好的准确性和稳定性,总体上明显优于CatBoost模型和RF模型。CatBoost模型与RF模型相比具有非常小的优势,并且RF模型对干旱地区的水面蒸发等不稳定变化的数据集的处理能力较差。与原CatBoost模型相比,耦合蝙蝠算法显著提升了模拟精度。在季节性分析中,Bat−CB模型在不同月份中具有较好的均衡性,在4月至10月期间较RF模型和CatBoost模型表现出更强的准确度和稳定性。然而,本研究没有考虑气象输入和更多气候类型的参数组合,此外在极端气候条件以及气象资料缺失条件下的模型应用扔有待于进一步研究。 图3 3种模型绝对误差频率分布直方图 表3 测试阶段3个模型统计指标的月平均值汇总Tab.3 Monthly average values of statistical indicators generated from the three machine learning models during the testing period
1.3 试验区概况

1.4 统计指标

2 结果与分析


3 结 论