基于极限学习机与负荷密度指标法的空间负荷预测
2021-02-23邵宇鹰彭鹏张秋桥王冰
邵宇鹰, 彭鹏, 张秋桥, 王冰
(1. 国网上海市电力公司,上海 200122;2. 南京宽塔信息技术有限公司, 江苏 南京 211100;3. 河海大学能源与电气学院,江苏 南京 211100)
0 引言
空间负荷预测这一概念由H. Lee Willis于20世纪80年代初首次提出[1],不仅要对某一区域的负荷总量进行预测,同时还要预测这一区域负荷增长的位置。空间负荷预测是城市配电网规划中不可或缺的重要环节,其预测结果的精度对城市配电网规划的经济性[2—6]以及可操作性有着重大影响。因此,随着城市负荷的增长以及智能电网建设需求的增加,空间负荷预测越来越受到重视。
目前,空间负荷预测的方法主要有趋势法[7]、多元变量法[8]、用地仿真法[9]以及负荷密度指标法[10—12]。用地仿真法是一种自上而下的预测方法,首先将规划区以网格的形式划分为面积相同的元胞,然后以土地利用性质为原则对负荷总量预测的结果进行空间位置上的分配[13—14]。负荷密度指标法是一种自下而上的空间负荷预测方法,首先按照负荷类型划分功能小区,通过预测功能小区的负荷密度,然和结合小区的面积计算出各小区的负荷值,进而得出总量负荷值[15]。这种预测方法适用于未来土地使用较为明确的情况,我国的土地使用方案已经被规划部门基本制定,因此负荷密度指标法在我国应用较多。
文献[16]为了解决数据匮乏且难以处理的问题,提出一种基于最小二乘支持向量机的新型配电网空间负荷密度预测算法,引用了灰色关联度算法来筛选样本数据,采用混沌粒子群算法优化最小二乘支持向量机参数。文献[17—18]提出一种考虑了分布式能源以及电动汽车接入的配电网空间负荷预测算法,但是分布式能源与电动汽车是一种复杂的非线性变化,文中只依靠支持向量机算法难以保证预测的精度与准确性问题。
针对上述情况,文中提出基于极限学习机(extreme learning machine,ELM)和负荷密度指标法的空间负荷预测算法,通过划分小区元胞,对负荷进行详细划分,构造精细化的负荷密度指标。基于模糊C均值(fuzzy C-means,FCM)算法进行样本数据的筛选,利用粒子群优化(particle swarm op-ti-mi-za-tion,PSO)算法优化ELM模型参数,通过实例验证了所提算法和模型的有效性。
1 ELM算法
人工神经网络在电力负荷预测中应用较多,且模型的泛化能力以及训练速度较快,但存在易陷入过拟合以及预测精度不高的问题。针对这些问题,采用ELM算法建立空间负荷预测模型,与传统神经网络相比,ELM的泛化性能好,训练速度更快。在进行空间负荷预测时,主要分为2个步骤:(1) 选取训练样本数据代入模型,确定模型的参数;(2) 将要预测的小区特征代入模型,进行预测。
ELM算法是一种单隐含层前馈神经网络学习算法[19—22],该算法随机产生输入层与隐含层间的连接权重及隐含层神经元的阈值。算法的原理为:假设共有N个训练样本(xi,yi),隐含层有L个神经元,输入层与隐含层之间的连接权重为W,隐含层与输出层之间的连接权重为β,激励函数为g(x)。故网络的输出T为:
T=(t1,t2,…,tN)
(1)
(2)
式中:wi=(wi1,wi2,…,win)为隐含层第i个神经元与各个输入层神经元间的连接权重;βi=(βi1,βi2,…,βim)为隐含层第i个神经元与各个输出层神经元间的连接权重;bi为隐含层第i个神经元的阈值。
根据式(1)和式(2)可得:
Hβ=TT
(3)
式中:TT为矩阵T的转置;H为神经网络的隐含层输出矩阵。H具体形式为:

(4)

(5)
一般情况下,隐含层神经元要远远小于输入层神经元,故此时H是奇异的,可通过广义逆矩阵求解奇异矩阵的逆矩阵,即式(4)的解为:
(6)
式中:H+为隐含层输出矩阵H的Moore-Penrose广义逆矩阵。
2 FCM算法
为了进一步提高空间负荷预测的精度,在进行仿真之前,需要对训练样本进行聚类分析。文中采用了使用较为广泛的FCM算法对训练样本进行聚类分析。FCM算法是利用求解隶属度来确定每个样本所属程度的一种聚类算法,该算法具体求解步骤如下:
(1) 对于N个训练样本X={x1,x2,…,xN},将其划分为C类,V={v1,v2,…,vc}是C个聚类中心。实际问题中C一般是人为给定的,设定迭代停止条件ε,同时初始化聚类中心V=V0,设置迭代计数器t= 0,模糊权重指数m= 2。
(2) 根据式(7)计算模糊隶属度矩阵U。
(7)
(8)
式中:uij为样本xi隶属于第j类的模糊隶属度,0≤uij≤1;dkj为样本xi到第k类聚类中心vk的欧式距离;dij为样本xi到第j类聚类中心vj的欧式距离,即:
(9)
按下式迭代聚类中心矩阵vj,t+1:
(10)
若‖Vt-Vt+1‖<ε,则停止,输出U和聚类中心矩阵V;否则令h=h+1,转至步骤(2)。
个体则是根据隶属度矩阵每列最大元素位置判断个体所属类别,给定输入样本,计算其与每一类聚类中心的欧式距离,取最小欧式距离的那一类数据作为回归模型的训练样本,从而极大地提高空间负荷预测精度。
3 基于PSO-ELM的建模
文中采用ELM建立空间负荷预测模型,利用PSO模型的参数提高负荷预测的精度。PSO的原理如下:
PSO算法中每个粒子就是d搜索空间中的一个潜在解,记为Xi=(xi1,xi2,…,xid)。将Xi代入目标函数计算其适应度值,则粒子的“好坏”可用适应度值来评判。第i个粒子的速度则是用一个d维向量表示,记为Vi=(vi1,vi2,…,vid)。在迭代的过程中,第i个粒子搜索到的最佳位置记为Pid=(pi1,pi2,…,pid),所有粒子搜索到的最佳位置记为Pgd=(pg1,pg2,…,pgd)。粒子根据下式更新速度和位置:
(11)
式中:i=1,2,…,m;k为迭代次数;ω为惯性权重因子;非负常数c1,c2为学习因子;r1,r2为(0,1)间的随机数。
考虑到粒子在搜索的过程中是非线性变化的,因此采用非线性凹函数递减惯性权重方式会获得更好的效果。
(12)
式中:Tmax为最大迭代次数;ωmax,ωmin分别为惯性权重的最大、最小值,通常ωmax取0.9,ωmin取0.4。
由上文对ELM的介绍可知,输入层神经元个数、隐含层神经元个数以及输出层神经元个数预先设定,模型未知的参数变量是输入层与隐含层之间的连接权重W和隐含层神经元阈值b,激励函数采用Sigmoid函数,目标函数是使式(5)最小。
因此,PSO优化的过程,就是找到使得目标函数最小的ELM最优的输入层与隐含层之间的连接权重W和隐含层神经元阈值b的过程。通过粒子群的不断迭代,将模型的目标函数作为粒子群的评价指标,最终满足精度要求后输出模型的最优参数。
4 空间负荷预测步骤
采用负荷密度指标法进行空间负荷预测最重要的步骤是建立精细化的负荷密度指标体系,利用FCM算法对样本数据聚类分析;然后采用文中所提的PSO-ELM模型预测,将负荷密度作为模型的输出,结合小区的面积求出小区的负荷大小。空间负荷预测的具体步骤如下。
(1) 构建精细化的负荷密度指标体系。文中将电力负荷根据用电性质分为以下10类:工业负荷,居民住宅负荷,行政办公负荷,商业负荷,文化娱乐负荷,研发负荷,教育、医疗、体育等公共设施负荷,市政设施负荷,仓储物流负荷,绿化、广场及道路负荷。分析搜集到的数据可知,每一类负荷从最大值到最小值的跨度较大,有必要对每一类负荷再进行细分,见图1。等级1到等级T表示将每一类负荷再细分为T类,通过上文提到的FCM算法实现。
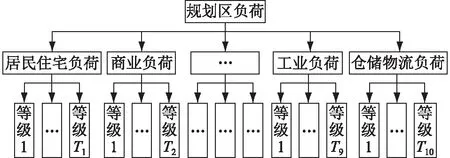
图1 负荷密度指标体系Fig.1 Load density index system
(2) 确定训练样本。利用FCM聚类算法,将每类负荷再细分为几个类型。以居民住宅为例,将这一类负荷分为再5种类型,求出每一类的聚类中心矩阵。对于给定的待预测地的特性指标,求出与5个聚类中心的欧式距离,取距离最小的那一类样本作为训练样本。
(3) 建立回归模型。文中采用的回归模型是基于PSO的ELM算法,将选好的训练样本代入模型,影响因素作为模型的输入,负荷密度作为模型的输出。训练好模型后,代入待预测地的特性指标,即可得出待预测地未来年的负荷密度。
(4) 进行空间负荷预测。将求出的各类负荷密度ρi乘以小区的面积Si即可得每个小区的负荷值Wi,将小区负荷相加并进行修正即可得到规划区的总量负荷。
(13)
式中:pi为小区的同时系数;N为小区个数;W为预测的空间负荷值。
根据以上4个步骤,基于ELM和负荷密度指标法的空间负荷预测流程如图2所示。
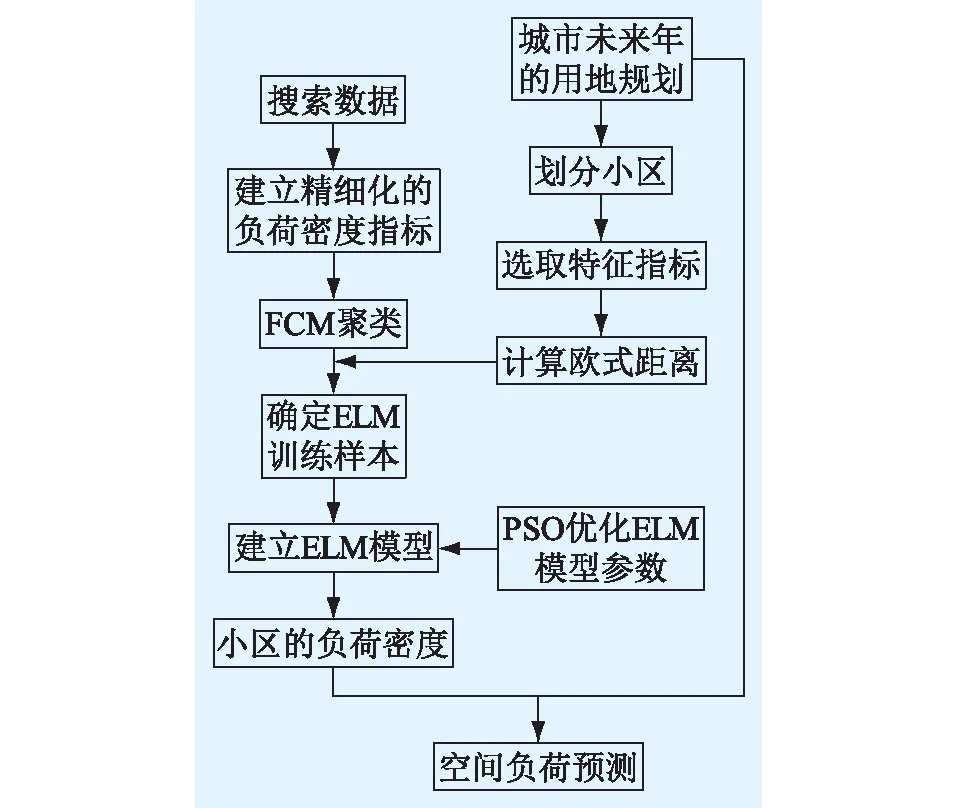
图2 空间负荷预测总流程Fig.2 General flow chart of space load prediction
5 算例分析
以居民住宅负荷为例,搜集上海市某规划地小区居民负荷数据样本,参考负荷密度指标体系可知,影响居民住宅负荷的主要因素为:人口密度A1,人均收入A2,人均用电量A3,煤电价格比增长率A4及回归模型的输出负荷密度C。搜集到的128个居民住宅样本数据如表1所示。
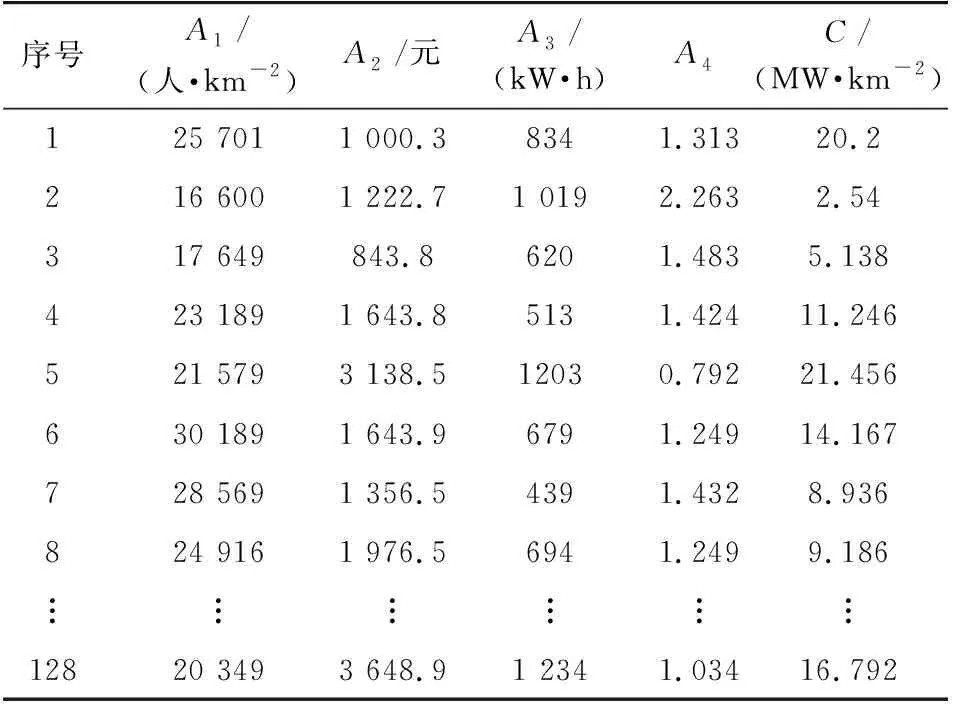
表1 样本数据Table 1 Sample data
考虑到居民住宅负荷密度大小跨度较大,因此将其再细分为5类,使用FCM算法将其聚类,每一类的聚类中心以及样本数如表2所示。

表2 各类负荷的聚类中心矩阵和样本数目Table 2 Cluster center matrix and sample number of each load
已知预测小区影响因素的数值为:A1=26 431,A2=1 576.3,A3=751,A4=1.379,对数据进行归一化处理,计算该样本与上述5类样本距离中心矩阵的欧式距离,采用标量值表示,记为d={0.048 7,0.657 3,0.313 2,0.685 4,0.238 6}。计算结果表明,预测小区与第一类负荷的欧式距离最小,故选取第一类负荷的28个样本数据作为训练样本训练极限学习机回归模型。文中使用Matlab建立ELM模型,利用PSO算法来对ELM的参数进行优化。
采用绝对误差EAE和相对误差ERE作为评价指标:
EAE=|C-C′|
(14)
(15)
为了验证文中所提算法的有效性,分别对未采用FCM算法、未采用PSO算法与文中所提算法进行比较,预测结果如表3所示。
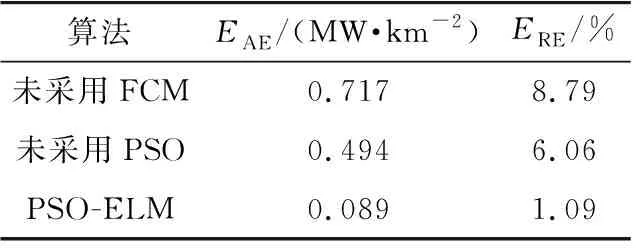
表3 3种算法的预测结果比较Table 3 Comparison of prediction results of three algorithms
由表3可知,PSO-ELM算法精度最高,且误差满足实际的工程要求。FCM聚类算法只是对数据进行处理,没有改变模型本身的复杂性。PSO算法优化耗时较短,因此引入PSO算法并不会影响模型的计算速度。
对于上述小区的负荷大小,可通过负荷密度乘以小区面积获得,对于规划地的空间负荷总量的预测则需要预测出每个小区的负荷密度大小,然后求取每个小区的负荷大小。表4给出了另外3个小区的特性指标,采用上述的PSO-ELM算法预测负荷密度大小。

表4 预测结果分析Table 4 Analysis of prediction results
按照此方法,求出规划区内所有的小区负荷密度,即可得到居民区空间负荷分布规律。文中在求取总负荷时,参考统计数据,设置同时系数为0.9,将每个小区负荷叠加修正即可得到总的空间负荷大小。
6 结语
文中所采用的空间负荷预测的算法是基于我国土地开发的实际情况提出的,我国土地的规划主要由政府决定,土地的使用性质明确,故可采用负荷密度指标法。文中采用的回归模型是ELM,该算法属于神经网络范畴,具有运行速度快、自学习能力强等优点。但是该算法也容易陷入过拟合状态,因此采用了改进的PSO算法来对其参数进行寻优处理。文中提出的负荷密度指标法意在建立精细化的负荷密度指标体系,采用FCM算法对每一类负荷进行再细化的聚类,为ELM提供训练样本,提高预测的精度。仿真试验证明,该算法具有很强的实用性。
本文得到国网上海市电力公司“基于智能算法的配电网空间负荷聚类及预测研究”(52-0-9-7-0-1-8-0-0-0G)资助,谨此致谢!
