基于大数据技术的铁路电子支付平台双活中心交易日志处理研究与实现
2021-02-23王宁,王胜
王 宁,王 胜
(1. 北京经纬信息技术有限公司,北京 100081;2. 中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
铁路电子支付平台自2010年开始建设,解决了铁路客户现金支付的各种安全隐患,显著提升了铁路旅客服务水平。提升了铁路运输收入资金周转周期,实现了中国国家铁路集团有限公司(简称:国铁集团)铁路运输收入集中收缴。
铁路电子支付平台支撑12306互联网售票系统、车站窗口、自助售票机和铁路货运站支付等场景。随着交易量的增加,系统中的交易日志和交易快照数据量,从设计之初的每秒百万级上升到TB级。原有基于关系型数据库的记录储存方式,已无法满足性能要求。特别是春运、国庆等高峰期,高并发的数据写入对数据库主机CPU、内存、磁盘I/O等带来较大冲击,出现长时间写入延迟和堆积,对系统可用性、稳定性带来较大风险。
为解决系统处理瓶颈,提升系统处理能力。本文通过相关研究,基于高并发消息队列中间件Kafka和Hadoop相关大数据处理技术[1],实现对现有交易日志和快照数据的处理和存储方式进行改造,将该部分数据从关系型数据库移至大数据平台。同时,基于铁路电子支付平台双活数据中心整体架构基础,设计了满足双中心双活处理方式。实现了海量数据的高效采集、存储、查询,有效地支撑了铁路电子支付平台高效业务处理。
1 主要技术介绍
1.1 高并发消息中间件技术
基于高峰期数据处理量的要求,考虑系统的弹性伸缩能力,满足高吞吐量需求,主要采用高并发消息队列中间件Kafka完成数据接入[2],Kafka可支持每秒数百万级别和TB级别的消息处理,且支持Hadoop并行加载。
1.2 实时流数据处理技术
参考铁路大数据应用顶层设计研究,各种系统产生的数据是一组顺序、大量、快速、连续到达的数据序列并且要求实时进行处理,此类数据可采用流式计算方法[3]。SparkStreaming[4]可以实现高吞吐量且具备容错机制的实时流数据处理。Spark可以接收Kafka的实时输入数据,进行实时统计和计算,数据处理完成后,Spark可以和Hadoop进行集成,将结果保存在HDFS,利用YARN服务进行资源调度。
1.3 分布式文件系统
分布式文件系统具有可移植、高容错和可水平扩展的特点,一般采用HDFS作为存储海量数据的底层平台[5-6],基于HDFS之上采用HBase满足快速查询检索[7]。
常见的大数据处理平台以整合、集成成熟的Hadoop 生态圈开源技术为主,采用分布式存储HDFS、HBase、分布式计算框架 Spark,以及 ZooKeeper、Redis等组合实现。
1.4 双活处理技术
基于铁路电子支付平台现有交易处理已实现双中心双活处理,基于Hadoop技术的交易日志改造也需设计实现双活处理。考虑到Kafka的高性能处理能力,采用数据双写方式,每个中心产生的数据均调用Kafka的接口写入两个中心进行处理。保证每个中心均存储两中心全量数据,实现数据同步和一致性,满足双中心的故障转移及数据查询、统计等需求。
2 设计方案
结合系统现状和技术研究,主要改造目标包括:
(1)整体架构支持大并发的数据量高效处理和存储需求,满足铁路电子支付平台现有双中心双活运行架构及峰值交易处理要求。
(2)提供基于业务处理量的实时数据收集、统计,提供基于交易流水号等的条件关联快速查询能力(秒级)。数据在线存储6个月,历史数据转入历史库,可快速进行数据上、下线切换和查询。
(3)对Hadoop整体运行环境配置、运行状态、数据处理量、存储、系统资源消耗等进行管理、监控和预警。
根据改造目标,铁路电子支付平台大数据处理逻辑架构,如图1所示,主要包括数据采集模块、数据存储模块、数据统计查询模块、组件运行监控4个部分。
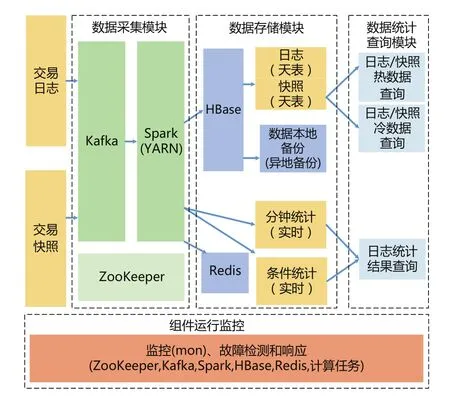
图1 铁路电子支付平台大数据处理逻辑架构
2.1 数据采集模块
现有交易日志、交易快照模块,通过Kafka客户端接口将消息发送至Kafka集群,两个中心将数据发送至本地Kafka集群和另一个中心Kafka集群,确保两中心数据均保持全量数据。
2.2 数据存储模块
Spark模块将接收的日志和快照数据保存至HBase中,按天进行存储,日志和快照分别保存在一张HBase表中,由于存储数据量大,90天前的数据,自动进行下线处理,节省HBase region server资源,下线的数据作为历史数据依然保留在HDFS上。需查询时,执行上线处理,可继续进行处理。
采用Hadoop YARN管理Spark集群。YARN在Hadoop中的功能作用有2个,负责Hadoop集群中的资源管理;对任务进行调度和监控[8]。
采用ZooKeeper 的容错性和高可用性分布式组件协调功能构建每个中心内部Hadoop的高可用模式。该模式具备双 NN 节点,能够实现容灾的功能[9]。
2.3 数据查询统计模块
根据不同需求,数据统计包括实时统计和查询。包括以下3类:
(1)按固定周期每分钟一次基于默认条件的实时统计和计算,使用Spark steaming每分钟进行一次统计任务,基于时间确定Kafka数据偏移量并处理对应数据,结果写入Redis保存;
(2)基于指定条件的统计计算,在接收到用户请求后,采用Spark任务,从Kafka拉取数据进行计算,进行统计并直接返回;
(3)基于交易流水号的查询,通过一、二中心统一的查询接口请求至HBase执行查询,返回结果合并去重后返回给用户。
2.4 组件运行监控
独立部署监控系统对整体大数据环境进行监控,主要包括:
(1)实时统计监控Kafka的数据写入量和数据消费延迟;
(2)各Spark程序的运行时间戳(由程序记录在Redis中),平台各服务(HBase、HDFS、ZooKeeper等)的状态;
(3)按周期巡检Hadoop(HDFS)、 HBase、ZooKeeper等集群所在主机状态(CPU、内存、网络、磁盘等)。
以上各类监控数据分别进行采集、判别和告警,通过页面展示和触发报警提示。
通过数据采集、数据存储、查询统计、组件运行监控模块4个部分组成数据处理完整流程,模块调用关系,如图2所示。
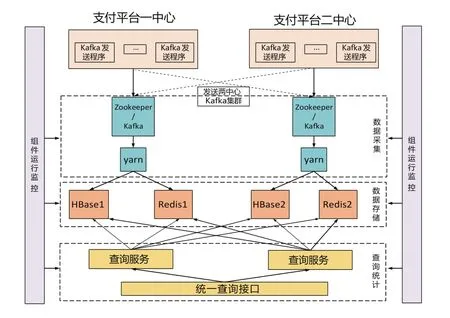
图2 模块调用关系
3 系统部署及性能测试
基于大数据环境包括较多的组件部署和配置,搭建完成的环境还需根据业务处理需求进行高并发、高可用稳定性测试。通过测试可以对环境参数进行调优,对处理性能指标评估,对系统稳定性进行验证等。
3.1 系统部署结构
铁路电子支付平台大数据处理功能基于支付平台一、二中心独立部署,各功能组件均采用集群模式搭建,确保系统环境高可用性。
根据机房物理设备情况,支付平台一、二中心均用物理机环境搭建,ZooKeeper、Kafka、YARN node manager,Hadoop Datanode,Hadoop Namenode,监控均单独部署在不同的机器上,以尽量避免相互之间资源竞争的影响。
数据存储配置及规划,按交易量每天2 000万笔,每日志数据量1.2 KB,每快照数据量6 KB计算。一天的原始数据量为720 GB。Hbase数据存储量90天约 51 TB。
3.2 系统性能测试
系统测试方案按照生产真实数据编写用例,利用20台虚拟机模拟客户端,每台机器启用多个服务,每个服务启动多个线程,模拟多客户端向支付平台一、二中心发送数据,客户端数量基本等同生产环境,达到1500个客户端。使用验证脚本统计Spark入库时间,统计发送数据量,利用HBase程序校验Kafka数据和HBase是否一致。
性能测试通过两个系统维护天窗期进行,每次持续时间4 h模拟1500个客户端,测试期间,交易量平均达 3000 笔/s,峰值达 5000 笔/ s,日志和快照处理平均量 15000 条/s,数据带宽流量约 110 MB/s,Spark数据统计平均延时6 s。测试完成后,支付一中心和支付二中心均完成超过4500万笔交易,存储超过4.5亿条数据。
3.3 系统高可用测试
为保障系统高可用,进行了各类故障场景的模拟测试。主要包括:
(1)模拟其中一个中心故障,数据写入可以自动检测并切换至另一中心完整写入;
(2)模拟某一中心内部部分组件失效,包括Kafka队列服务中断、Spark单节点故障、HBase单节点故障、HDFS数据存储单节点故障等,均可失效自动检测故障,进行故障节点隔离、Server自动转移。
根据性能和功能测试结果,整体处理能力达到峰值交易处理能力,运行平稳,能够完成故障自动切换和恢复。满足高并发、高可用设计目标。
4 结束语
本文提出了一种基于Kafka、Hadoop等的数据采集与存储方案,设计了满足双中心运行的大数据处理集群架构环境,具有吞吐量大、高可用等特点,提升了支付系统处理能力。系统经实际环境运行特别是春运售票高峰,系统运行平稳、性能优良,具有一定的应用和参考价值。
