结合一维扩展卷积与Attention机制的NLP模型
2021-02-22廖文雄徐雅芸
廖文雄,曾 碧,徐雅芸
广东工业大学 计算机学院,广州 510006
自然语言处理(Natural Language Processing,NLP)是信息技术最重要的研究方向之一[1]。自然语言处理是利用计算机技术研究和处理语言的一门学科,把计算机作为语言研究的工具,对语言或文字信息进行定量化的研究,并提供人与计算机之间能够共同使用的语言描写[2]。随着现代信息规模的急剧增大,大部分的自然语言处理任务(如文本分类、情感分析、中文分词、机器翻译)都很难通过浅层学习[3]的算法完成。
目前在自然语言领域最常用的深度学习模型主要有循环神经网络(Recurrent Neural Network,RNN)和卷积神经网络(Convolutional Neural Network,CNN)。但是循环神经网络及其变体LSTM(Long Short-Term Memory)[4]、GRU(Gated Recurrent Unit)[5]结构较复杂,并且存在时序依赖问题,难以实现并行化计算[6]。虽然CNN 能够容易地实现并行化计算,但是CNN 只能关联卷积窗口内的特征信息,而不能像循环神经网络那样联系全文[7]。
为了提升CNN 联系上下文的能力,本文提出一种结合一维扩展卷积和Attention 机制的自然语言处理模型,与LSTM 相比,本模型能够更好更快地完成自然语言处理的任务。
1 相关工作
自然语言处理算法大致分为以下两类:(1)浅层学习方法;(2)深度学习方法。
1.1 浅层学习方法
经典的自然语言处理算法主要有朴素贝叶斯算法、K近邻算法、支持向量机以及最大熵模型等算法,这些都称为浅层学习方法。Pang等人[8]使用朴素贝叶斯、支持向量机、最大熵等模型在电影评价的情感分析任务中取得较好的效果。这些浅层模型最多拥有1~2 个非线性特征转换层,计算量小且容易实现,在解决简单问题上能取得较好的效果,但是由于对复杂问题的表达能力有限,难以完成现代复杂的自然语言处理任务。
1.2 深度学习方法
随着深度学习在图像领域取得的巨大进展,研究者们纷纷尝试用深度学习的方法解决自然语言处理问题。其中最常见的是循环神经网络,循环神经能够联系上下文信息,在解决序列化的问题上有突出的效果,因此在自然语言处理领域广泛应用。随着循环神经网络及其变体LSTM、GRU 的不断发展,自然语言处理技术有了较大的进步,因此现在大部分的自然语言处理任务都把LSTM和GRU作为首选算法。Liu等人[9]基于循环神经网络对文本进行分类,取得了不错的效果。王伟等人[10]基于双向GRU和Attention机制对文本进行情感分析。张子睿等人[11]通过双向LSTM 和CRF 结合的网络模型对中文进行分词。但是循环神经结构较复杂,并且在反向传播时多个门(Gate)和记忆单元都依赖上一个时间步,导致训练速度较慢。
Attention机制方面,Bahdanau等人[12]提出自然语言的Attention机制并首次应用于翻译领域,取得了相当不错的效果。Luong等人[13]提出了Global Attention和Local Attention 两种 Attention 方式。Attention 机制在翻译领域取得的成功,使得其广泛应用到基于深度学习的自然语言处理各个任务中。
与此同时,CNN 对自然语言处理的能力一直被低估。近年来随着循环神经网络的缺点逐渐暴露出来,研究者们纷纷尝试采用比循环神经网络更加简单的CNN。Kim[14]2014 年将 CNN 应用到句子分类中;Zhang 等人[15]2015 年提出字符级的CNN 文本分类方法;Gehring 等人[16]将CNN的结构应用到机器翻译;王盛玉等人[17]提出通过在词嵌入层后增加Attention机制,给予每个情感词不同的权重以提升CNN的情感分析性能。
但是CNN 只能获取卷积窗口内的局部特征信息,会导致模型无法像RNN那样联系文本上下文信息。为了增强CNN 在处理自然语言任务时的上下文关联性,本文提出一种结合一维扩展卷积和Attention 机制(One-Dimensional Dilated Convolution and Attention Mechanism,1DDilaConv_Att)的自然语言处理模型。1DDilaConv_Att 模型能够在较短的时间内实现与循环神经网络相近的性能。
2 1DDilaConv_Att模型
图1 为1DDilaConv_Att 模型结构图解。首先将所有的文字都经过Embedding 层把每个词转化成向量的形式,并输进1DDilaConv 层;通过1DDilaConv 层提取文字信息的深层特征;随后通过Attention 机制整合由1DDilaConv 层提取得到的特征;最后通过全连接层实现分类或者回归任务。
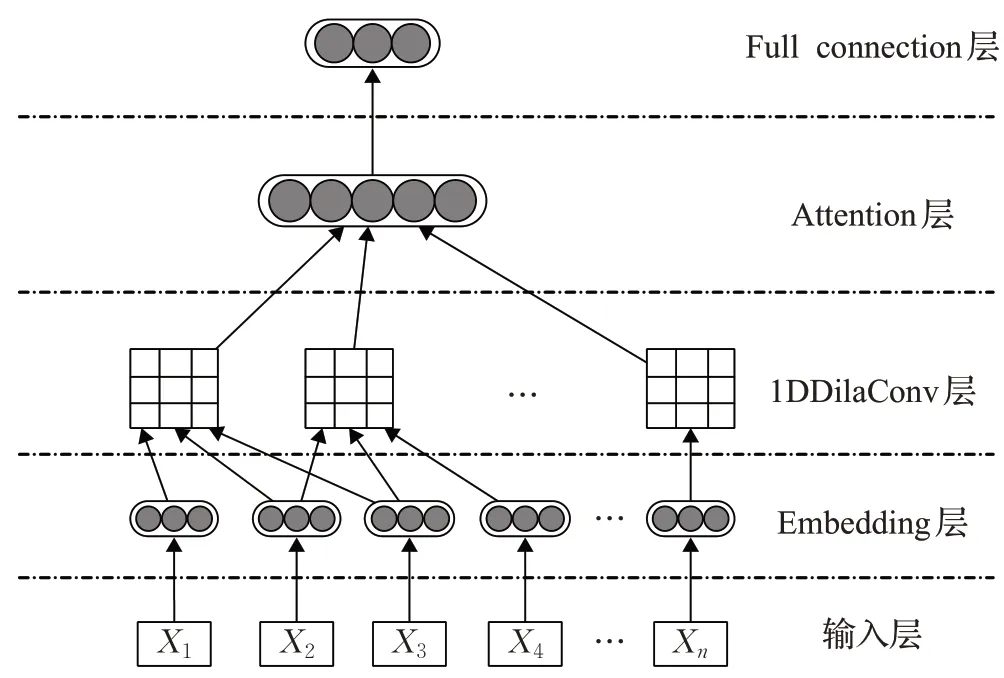
图1 1DDilaConv_Att模型结构
2.1 Embedding层
Embedding 层即词嵌入层。由于CNN 最早是应用于图像处理和识别领域,而图像由像素点矩阵组成,因此需要将文本信息转成二维矩阵的形式。词向量是基于语料库利用算法学习得到的词语低维表示形式,能充分体现上下文的相关特征和词语之间的相似性。目前常 用的词嵌入方法有 word2vec[18]、GloVe[19]、ELMo[20]。假设文本中含有n个词,且嵌入层的输出为k维特征,则1DDilaConv的输入为n×k的二维矩阵。
2.2 1DDilaConv
本文提出的1DDilaConv以一维卷积(One-Dimensional Convolution,1DConv)为基础。1DConv 主要通过模仿N-gram获得上下文信息,设卷积的窗口大小为l,那么l即为N-gram 中的n,每个卷积窗口产生的信息可以认为是一个时序信号。
2.2.1 1DConv
本文所提及的1DConv与文献[14]所提到的卷积层类似。设Xi∈Rk,其中k代表嵌入层输出维度,而i代表该词在文档或者句子中的位置。经过Embedding 层后一个包含n个词的文档或句子可以用以下形式表示:

这里符号⊕表示连接操作。通常用向量Xi:i+j表示一系列词向量Xi,Xi+1,…,Xi+j。每个卷积操作都包含一个卷积核w∈Rl×k,它可以通过一个包含l个词的窗口来产生一个新的特征。例如:一个特征ci可由窗口Xi:i+l-1产生:

这里b∈R 是一个偏置项,f是一个类似双曲正切的非线性函数。最后文档或句子可以表示为:

如图2所示为卷积窗口大小为2且包含3个卷积核的卷积层,经过特征提取后形成一个大小8×3 的特征图,其中8=n-l+1=9-2+1,3 为卷积核数量。
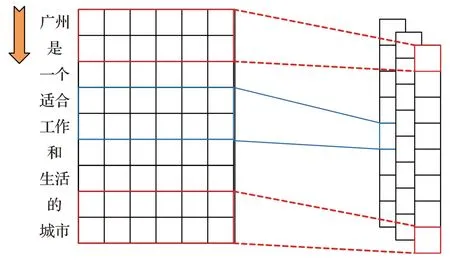
图2 1DConv操作示意图
2.2.2 1DDilaConv原理
为了增大卷积的感受野,增强网络模型对上下文的联系能力,本文在文献[21]的基础上,提出一维的扩展卷积(One-Dimensional Dilated Convolution,1DDilaConv),对文本进行特征提取。
与1DConv相比,1DDilaConv引入一个名为扩展率(Dilation Rate)的超参数,以控制卷积核中空值0 的数量。扩展率定义了卷积核处理文本数据时各词之间的间距,图2中原始1DConv的扩展率为1。经过扩展后的卷积窗口大小可以由式(4)计算得到:

其中,l为原始卷积窗口大小,d为扩展率。通过扩展卷积操作后,可以捕获到距离较远词语的相关性,并且有利于特征降维。
原始卷积窗口大小为3,扩展率为3且包含2个卷积核的1DDilaConv 操作如图3 所示。在图3 中不同颜色代表不同的卷积核,在卷积核中,圆点标记的位置同正常卷积核,无圆点标记的位置为0。
从图3并且结合式(4)可知:经过扩展率为3的扩展后,原来大小为3的卷积窗口,扩大至7。经过特征提取后形成一个大小6×2 的特征图,其中6=n-l′+1=12-7+1,2 为卷积核数量。

图3 1DDilaConv示意图
2.3 Attention机制
Attention 机制的优势是其随着时间推移而整合信息的能力,可以用来表示文本或句子中的词与输出结果之间的相关性。本文所用到的Attention 机制参考文献[22]。假设ht是由第t个时序窗口产生的特征,那么Attention机制的过程可以用以下式子表示:
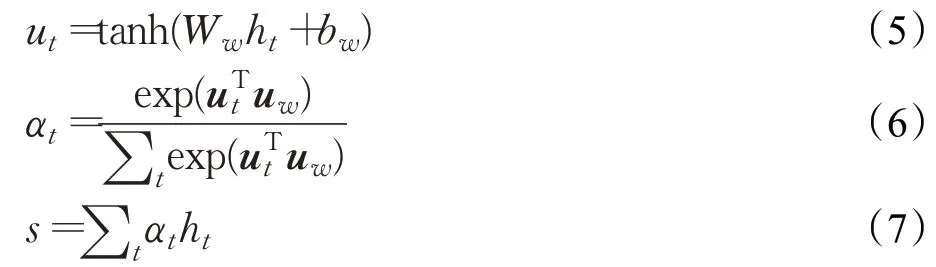
其中,Ww与bw为Attention的权重和偏置项。式(6)为对所有的结果计算softmax 值。式(7)将计算出的αt作为各个卷积窗口的输出权值,对其加权求和表示为一个向量。对于图3 所产生的6×2 特征图,则有ht∈R3,1 ≤t≤6 ,而经过Attention 机制后,输出结果为
Attention机制的网络结构如图4所示。
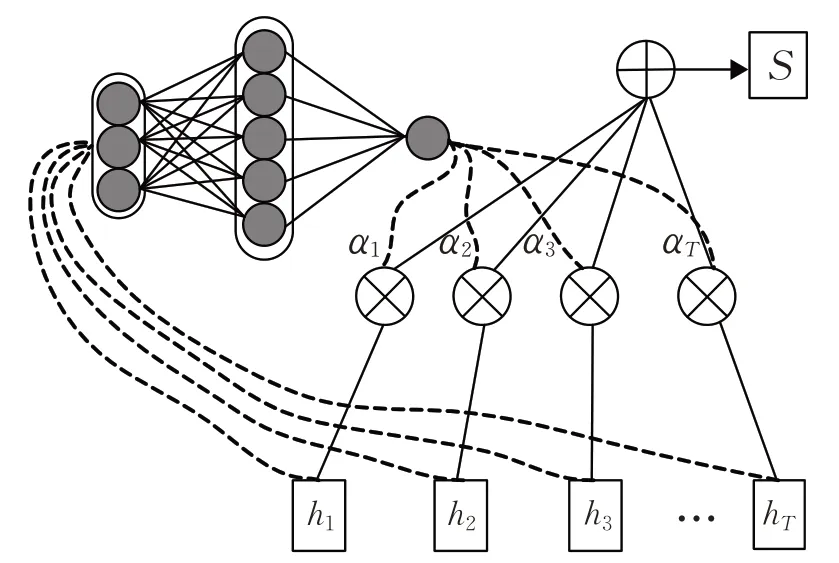
图4 Attention机制的网络结构
3 实验与分析
3.1 实验环境
本文验证实验的运行环境是一台具有16 GB 内存 且 配 有 型 号 为 Intel®CoreTMi7-7770HQ 的 CPU 和GTX1060 显卡的个人计算机,该计算机操作系统为Windows 10家庭中文版。
3.2 对比实验
本实验实现了以下四种模型的对比:
(1)Native Bayes 模型,该模型参考文献[23]的方法,先对文本计算TF-IDF值,再通过朴素贝叶斯对文本进行处理;
(2)LSTM模型,该模型参考文献[9]的方法,将经过嵌入层的文本输进两层堆叠LSTM后,根据LSTM的输出值做相应的处理;
(3)LSTM_Att 模型,该模型参考文献[24]的方法,将经过嵌入层的文本输进两层堆叠LSTM,并且LSTM后接Attention层,根据Attention层的输出值做相应的处理;
(4)1DConv_Att模型,该模型参考文献[14],将经过嵌入层的文本输入两层堆叠的卷积层,并在卷积层后添加Attention层;
(5)本文提出的1DDilaConv_Att模型,为了与LSTM模型、LSTM_Att模型做对比,该模型也含有两层堆叠的扩展卷积层。
除了实验设置中有特别说明外,其他的数据预处理过程,模型超参数等设置,所有模型保持一致。
3.3 评价指标
本文采用accuracy、F1、训练时间作为评价指标。对于多分类问题,本文采用宏平均值。accuracy、F1的计算公式如下:

式中的TP、FN、FP、TN如表1所示。

表1 二分类结果混淆矩阵
3.4 imdb数据集情感分析
3.4.1 数据集介绍
本文采用来源于keras的imdb数据集,其包含50 000条电影评论(英文),以情绪(正面/负面)标记。该数据集被划分为用于训练的25 000 条评论和用于测试的25 000条评论,训练集和测试集都包含50%的正面评价和50%的负面评价。样本分布情况如表2所示。
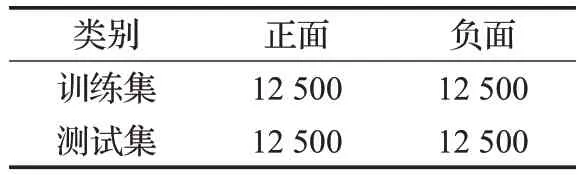
表2 imdb数据集样本分布
3.4.2 实验设置
Native Bayes 模型通过sklearn 实现,其他模型通过keras 实现。本实验的Embedding 层使用imdb 数据集作为语料库通过word2vec 方法训练词向量。在1DDilaConv_Att 模型中第一层扩展卷积的原始卷积核大小设为3,扩展率设为1;第二层扩展卷积的原始卷积核大小设为3,扩展率设为3。
3.4.3 结果
各模型的imdb数据集情感分析结果如表3和图5所示。从accuracy来看,Native Bayes最低,只有0.834 7,最高的是LSTM_Att,为0.879 8;从F1来看,1DDilaConv_Att最高,为0.884 1;从每轮训练时间来看,Native Bayes耗时最短,仅需要0.023 5 s,其次1DConv_Att为17.046 7 s,1DDilaConv_Att为18.807 8 s,而LSTM_Att每轮耗时最长,达到49.447 8 s。
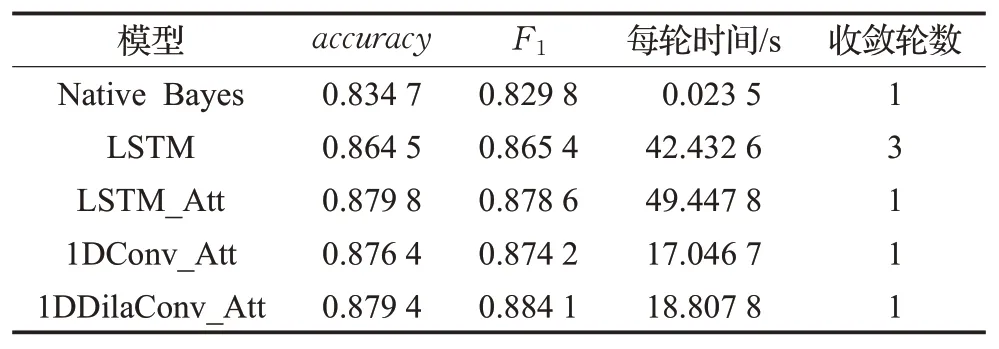
表3 各模型情感分析性能对比
3.5 THUCNew新闻主题分类
3.5.1 数据集介绍
THUCNew 是根据新浪新闻RSS 订阅频道2005—2011 年的历史数据筛选过滤获得的,一共包含74 万篇新闻,约为2.19 GB。本文从该数据集中提取出10个主题,每个主题随机抽取5 000篇新闻作为训练集,500篇新闻作为验证集,1 000 篇新闻作为测试集。样本分布如表4所示。
3.5.2 实验设置
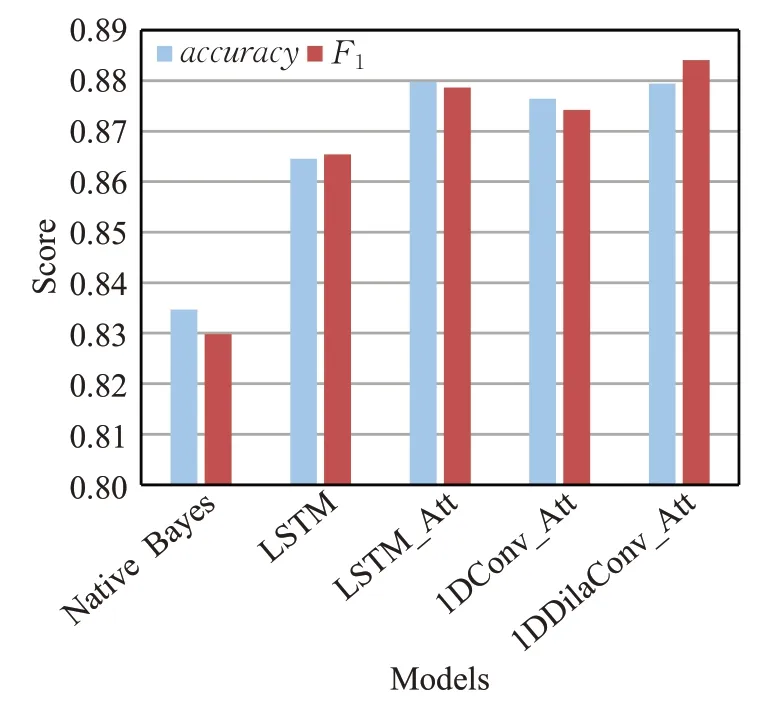
图5 各模型情感分析性能对比
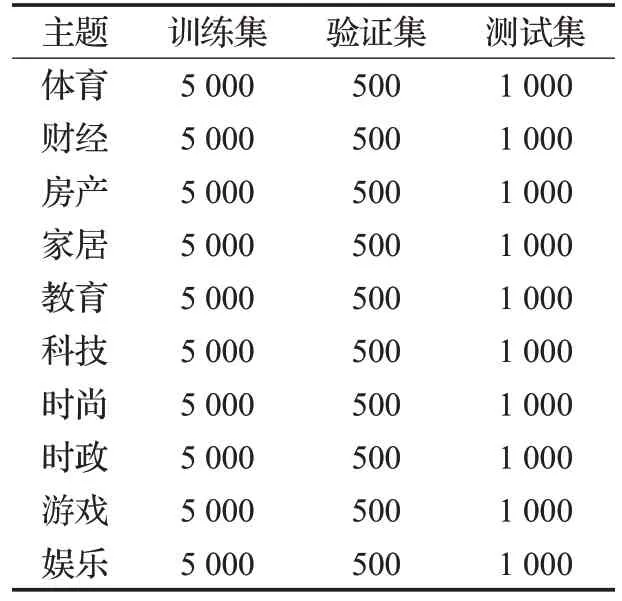
表4 新闻主题分类数据集样本分布
Native Bayes模型通过sklearn实现,其他模型通过keras实现。与情感分析实验不同的是本实验的Embedding 层使用约4.1 GB 的百度百科外部语料库通过GloVe 训练字符级嵌入。在1DDilaConv_Att 模型中第一层扩展卷积的原始卷积核大小设为6,扩展率设为1;第二层扩展卷积的原始卷积核大小设为5,扩展率设为2。
3.5.3 结果
各模型新闻主题分类结果如表5 和图6 所示。从accuracy和F1来看,1DDilaConv_Att 均为最优模型,其中accuracy达到0.962 1,F1达到0.961 84;从每轮耗时来看Native Bayes 耗时最短,仅需要0.169 3 s,其次为1DConv_Att,每轮耗时 84.901 2 s,1DDilaConv_At 为86.715 9 s,而耗时最长的为LSTM_Att,达到221.163 6 s。
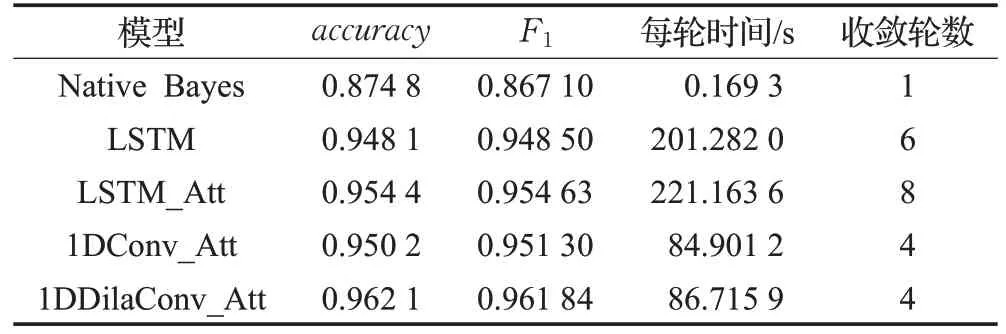
表5 各模型主题分类性能对比
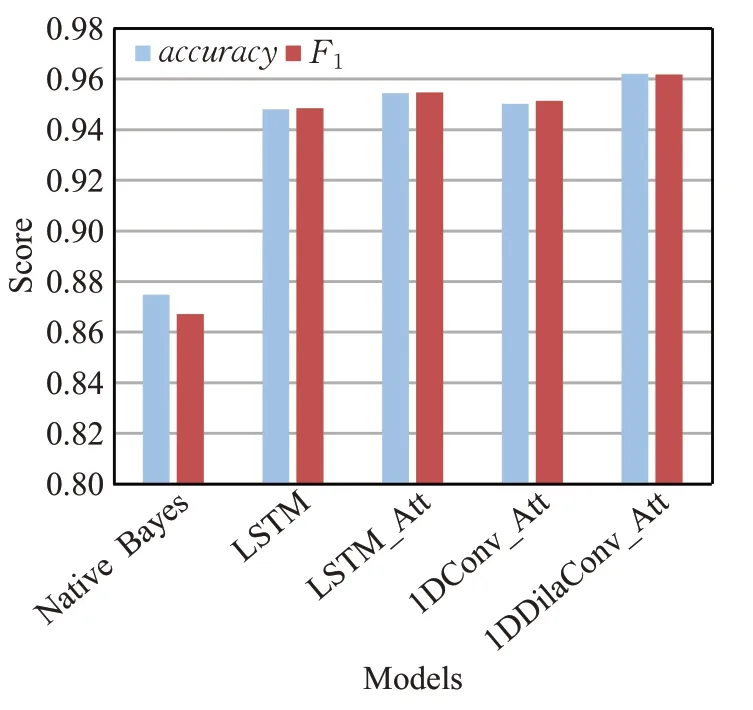
图6 各模型主题分类性能对比
3.6 实验分析与总结
以上实验中,Native Bayes只是通过简单的统计方法进行训练,因此训练速度较快,但是由于其表达能力不足,导致性能逊色于其他模型。LSTM模型通过循环神经网络联系上下文信息,而LSTM_Att 通过Attention机制整合各个时序的信号,因此LSTM_Att 比LSTM 性能更好,可是LSTM和LSTM_Att由于网络结构复杂,导致训练时间急剧增加。本文提出的1DDilaConv_Att 模型比1DConv_Att 能够更好地联系上下文并且结构比LSTM模型更加简单,同时借助一维扩展卷积强大的特征提取能力和通过Attention机制整合深层特征,因此性能较好并且耗时比LSTM和LSTM_Att都要少。
通过在公开的数据集中进行实验验证可知,本文提出的1DDilaConv_Att与现在主流的循环神经网络相比,速度提升明显,能够更好更快地处理自然语言处理任务。
4 结束语
本文提出一种基于一维扩展卷积和Attention 机制的自然语言处理模型1DDilaConv_Att,详细描述了1DDilaConv_Att的工作原理,并且通过实验验证了本文模型能够在较短的时间内获得和循环神经网络相近甚至超过循环神经网络的性能。
尽管本文提出的1DDilaConv_Att 比LSTM 性能有所提升,但是本文使用的Attention机制较为简单。未来的工作需要结合多头Attention 机制(Multi-head Attention)更好地融合由一维扩展卷积产生的特征信息,从而实现性能的进一步提升。另外,本文只在情感分析和主题分类任务上进行模型验证,未来工作需要在更多任务上(命名实体识别、词性标注、关系抽取等)进一步验证本文模型的有效性。
