最小二乘损失在多视角学习中的应用
2021-02-21刘云瑞周水生
刘云瑞,周水生
(西安电子科技大学 数学与统计学院,陕西 西安 710126)
近年来,人们收集和存储数据的能力得到了极大的提高。在科学研究和社会生活的各个领域,海量表现形式复杂的数据涌现。针对同一对象从不同途径或不同层面获得的特征数据被称为多视角数据,其呈现出多态性、多源性、多描述性和高维异构性等特点。多视角数据广泛存在于生物医学研究[1-2]、工业生产实践[3-4]和无监督学习等领域[5-6]。
多视角数据不仅可以从不同领域、不同特征提取获得,而且也可以通过随机划分、主成分分析、降维等方法人工生成[7-8]。不同视角间既具有内在联系,又存在差异,因此需要一种新的学习方法对这些数据和特征进行加工处理,从而充分合理地利用多视角数据中的信息。这就诞生了一个新的领域——多视角学习(Multi-View Learning,MVL)。经典的支持向量机(Support Vector Machines,SVM)属于单视角学习范畴,可以很好地解决小样本分类、回归等学习问题,是一种基于结构风险最小化原则和最大间隔原理的机器学习方法。但是,支持向量机所用到的数据往往是单个视角的数据,并不能很好地发掘多视角数据之间的结构特性。目前围绕支持向量机衍生出来的多视角学习算法越来越多,较为流行的有以下几种算法:基于学习使用特权信息框架(Learning Using Privileged Information,LUPI),是通过将特权信息确定的非负校正函数替换标准支持向量机中的松弛变量得到的SVM+模型[9-12];将多视角学习理论应用于最大熵判别算法(Maximum Entropy Discrimination,MED),得到多视角最大交叉熵模型(Multi-View Maximum Entropy Discrimination,MVMED)[13-14];将正则化最小二乘孪生支持向量机(Regularized Least Squares Twin SVM,RLSTSVM)与多视角学习理论结合,可以得到正则化多视角最小二乘孪生支持向量机(Regularized Multi-view Least Squares Twin SVM,RMvLSTSVM)[15]。典型相关性分析(Canonical Correlation Analysis,CCA)和核典型相关性分析(Kernel Canonical Correlation Analysis,KCCA)[16-17]是两种常用的子空间学习算法,利用映射后的基向量之间的相关关系来反映原始变量之间的相关性,得到多视角数据的共享子空间。FARQUHAR等[18]利用样本的多个特征集和标签信息,提出将KCCA和SVM相结合的SVM-2K多视角学习模型,由此也产生了许多新型的多视角子空间学习算法[19-20]。
在机器学习研究中,许多学者基于不同的损失函数提出了不同的支持向量机模型。最经典的就是基于合页(hinge)损失函数提出的支持向量机模型,往往通过MATLAB求解二次规划问题,算法复杂度较高。基于最小二乘损失,文献[21-22]提出的最小二乘支持向量机(Least Squares SVM,LSSVM)模型,只需要求解线性方程组即可解决问题,降低了模型的计算复杂度,取得了广泛的应用。多视角学习模型SVM-2K若通过对偶问题的二次规划形式求得最优解,则不仅效率低下,而且精度较低。受传统最小二乘支持向量机模型改进思路的启发,笔者首先提出了对SVM-2K模型改进的LSSVM-2K模型,只需要求解一个线性方程组即可快速获得良好的分类结果。同时,针对SVM-2K模型中不同的损失函数,可以构建另外两种部分应用最小二乘思想的LSSVM-2KI和LSSVM-2KII学习算法,并辅助验证LSSVM-2K模型的优劣性。实验结果表明,LSSVM-2K模型在处理多视角数据分类问题上具有良好的分类性能,尤其是大大缩减了训练时间,在较大规模的数据集上相比于SVM-2K模型训练时间缩减了约90%。LSSVM-2KI具有比LSSVM-2K模型更好的分类效果,训练时间比SVM-2K模型的短,但比LSSVM-2K模型的长一些。LSSVM-2KII在分类精度和训练时间上均介于两种模型之间。
1 相关算法
先简述LSSVM和SVM-2K模型及算法,并在下一节提出引用了最小二乘思想的LSSVM-2K、LSSVM-2KI和LSSVM-2KII模型。
1.1 最小二乘支持向量机
由于引入了hinge损失,使得支持向量机成为一个非光滑的凸优化问题,往往要通过求解带约束的对偶问题得到其最优解。显然,对于非光滑的凸优化问题的求解比较复杂。在支持向量机中引入光滑的最小二乘损失,可以构造如下所示光滑的凸优化问题:
(1)
其中,lleastsquares(w,b)=(1-yi(wTφ(xi)+b))2,是最小二乘损失;φ是将样本数据xi从低维映射到高维空间的特征映射;xi和yi分别是经典单视角学习模型的训练样本和标签,i=1,2,…,l。
通过求解优化问题的KKT条件,可以立即写出下式来求解问题:
(2)
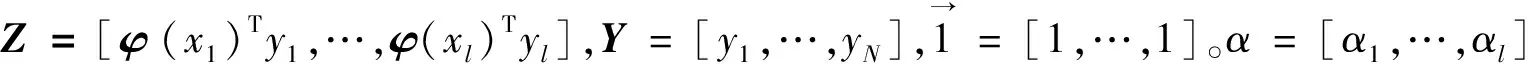
1.2 SVM-2K模型
多视角数据的涌现使得多视角学习逐渐成为热门话题,许多学者致力于多视角学习领域的研究。典型相关性分析和核典型相关性分析利用映射后的基向量之间的相关关系来反映原始变量之间的相关性,从而得到多视角数据的共享子空间,它们是两种常用的子空间学习方法。FARQUHAR等[18]提出了将子空间学习方法和支持向量机相结合,进而构造出了SVM-2K模型。
(3)
通过拉格朗日函数,得到原问题(3)的沃尔夫对偶为
(4)

(5)
2 LSSVM-2K、LSSVM-2KI和LSSVM-2KII模型的建立及算法
上述有约束的SVM-2K算法可以改写为如下所示的无约束优化问题:
(6)
A、B两个视角松弛变量对应的hinge损失函数为
(7)
A、B两个视角间一致性约束的松弛变量对应的ε不敏感损失函数为
(8)
SVM-2K模型虽然可以有效地利用多视角数据间的结构特性提高分类性能,但由于凸优化问题是非光滑的,这将花费更长的训练时间和更大的内存空间来满足计算需要,增大了问题的求解难度。最小二乘损失是一个光滑的凸函数,在计算上要比非光滑的凸hinge损失函数更容易求得最优解,可以大大地降低计算复杂度。SVM-2K模型中的ε是一个容许样本违反约束的不敏感松弛变量,一般取较小值。此外,笔者研究的是具有核函数的非线性问题,为简单起见,只考虑没有偏置b的多视角学习器[23]。实际上,偏置b可以视为添加进每一个样本中额外的值为1的属性。借鉴最小二乘思想,一致性不等式约束可以改为等式约束,故可得到如下修正的一致性等式约束条件[24]:
(9)
将构造如下所示的最小二乘损失函数对SVM-2K模型进行改进,并在下文对如何有效利用最小损失函数展开讨论。
A、B两个视角各自的松弛变量对应的最小二乘损失函数为
(10)
衡量A、B两个视角一致性约束的松弛变量对应的最小二乘损失函数为
(11)
2.1 LSSVM-2K模型建立
这里的模型假设和符号意义均和SVM-2K模型相同,不再重述。用最小二乘损失完全替换LSSVM模型中的两个hinge损失和一个ε不敏感损失,最终得到LSSVM-2K模型:
(12)
(13)
对偶问题可以化简为如下所示的简洁形式:
(14)


(15)
(16)
(17)
2.2 LSSVM-2KI模型和LSSVM-2KII模型的建立
在单视角学习任务中,LSSVM模型相比于支持向量机最突出的优点便是大大缩短了训练时间。那么,如何对拥有3个松弛变量的SVM-2K模型应用最小二乘思想,是笔者也要考虑的问题。在此通过对SVM-2K模型应用最小二乘损失,不同程度地替换原模型中的hinge损失。笔者分别构建了LSSVM-2KI和LSSVM-2KII模型,以便更好地研究最小二乘损失对SVM-2K模型的影响。这里的模型假设和符号意义均和SVM-2K模型的相同,不再赘述。
2.2.1 LSSVM-2KI模型
SVM-2K模型中的ξA,ξB表示A、B两个视角分离超平面各自对应的松弛变量。SVM-2K模型中的松弛变量ξA,ξB与一致性约束的松弛变量ξ意义相近。因此,首先通过对SVM-2K模型中ξA,ξB应用最小二乘思想,同时保持原模型中一致性约束为不等式约束,构建了LSSVM-2KI模型:
(18)
通过拉格朗日函数得到原问题式(18)的沃尔夫对偶为
修复重复三元组不一致性,用R代表(s,p,o)[start,end])是一条时态RDF数据记录,Ri表示第i条记录,Ri+1就是下一条记录。首先在时态RDF数据库中的记录中匹配(s,p,o)三元组,找到三元组完全一样的时态RDF数据记录,通过比较两个时间区间的起始时间点和结束时间点,计算出修改时间区间,对一条记录的两个时间点进行修改,再删除另外一条记录。
(19)
这里同样可以将对偶问题转化为一个简单的有约束的二次规划形式,证明方法与LSSVM-2K模型类似。然后,通过求解二次规划问题即可求得最优解。
2.2.2 LSSVM-2KII模型
再通过对SVM-2K模型中一致性松弛变量ξ应用最小二乘思想,同时保持A,B两个视角各自的松弛变量ξA,ξB不变,构建了LSSVM-2KⅡ模型和拉格朗日函数:
(20)
通过拉格朗日函数得到原问题式(20)的沃尔夫对偶为
(21)
这里同样可以将对偶问题转化为一个简单的有约束的二次规划形式,证明方法也与LSSVM-2K模型类似。然后,通过求解二次规划问题即可求得最优解。
2.3 LSSVM-2K、LSSVM-2KI和LSSVM-2KII模型算法步骤
LSSVM-2K模型通过求解一个简单线性方程组得到问题的最优解。对于LSSVM-2KI、LSSVM-2KII,通过二次规划求解器解决问题。通过上述分析,设计了LSSVM-2K、LSSVM-2KI和LSSVM-2KII算法的步骤,3个模型的算法的不同之处将在括号中注明。
输出:αA,αB,α(LSSVM-2KI模型输出αA,αB,α+,α-),决策函数如式(15)~(17)所示。
步骤2 通过交叉验证选择最优参数,构建并且求解线性方程组(LSSVM-2KI和LSSVM-2KII构建并且求解二次规划问题,通过交叉验证选择最优参数);
步骤4 通过决策函数式(15)~(16)分别预测单个视角A的测试样本xA和单个视角B的测试样本xB的标签,最后通过决策函数式(17)共同预测两个视角样本(xA,xB)的标签。
3 实验验证
本节将展示LSSVM-2K模型和另外两个模型LSSVM-2KI、LSSVM-2KII的实验结果,并与其他多视角分类方法进行比较。为了验证笔者提出算法的普适性和有效性,将在动物特征数据集(Animals With Attributes,AWA)、UCI手写数字集(UCI Digits Dataset)和森林覆盖类型数据集(Forest CoverType Data)上进行实验。这3组数据集在多视角学习领域应用较为广泛。AWA数据集探究模型在固定视角下不同分类对象的分类精度和训练时间,Digits数据集探究模型在固定分类对象下不同视角的分类精度和训练时间,Forest CoverType Data数据集探究模型在不同数据规模情况下各个模型的分类精度和训练时间。通过在这些不同的数据集上进行实验,可以多视角、多维度地验证模型的优劣性,同时也说明了多视角学习算法具有较强的普适性。实验环境如下:Windows 7系统,8 GB内存,Intel(R)Core(TM)i7-4790 CPU的电脑,编程环境为Matlab R2017b。
当前,多视角学习理论在各个领域都有广泛的应用。在支持向量机领域中具代表性的有SVM+、MVMED、RMvLSTSVM和SVM-2K。将笔者构建的LSSVM-2K,LSSVM-2KI和LSSVM-2KII模型与上述模型进行比较,以验证新模型的优越性。
(1)SVM+:由特权信息确定的非负校正函数替换标准支持向量机中的松弛变量,就可得到SVM+模型。选择其中一个视角作为训练的标准信息,另一个视角作为特权信息,分别记为SVM+A(视角B为特权信息)和SVM+B(视角A为特权信息),将这两种情况均作为比较模型。
(2)MVMED:MVMED是在结合了最大熵和最大间隔原理的最大熵判别算法(MED)的基础上应用了多视角学习理论的模型。
(3)RMvLSTSVM:正则化最小二乘孪生支持向量机(RLSTSVM)是一种新的不平行超平面分类器,它与多视角学习理论结合产生了RMvLSTSVM模型。
(4)SVM-2K:SVM-2K模型是一种结合了KCCA和SVM的经典多视角学习模型。
参数选取:模型中的参数均采用网格搜索法进行参数寻优。SVM+模型和MVMED模型中网格寻优参数范围取C={10-3,10-2,…,100,…,102,103}。对于RMvLSTSVM模型,不失一般性,为了加快模型的求解,假设正类和负类中松弛变量的参数均相等,取c1=c2=c3=c4={10-3,10-2,…,100,…,102,103},D=H={10-3,10-2,…,100,…,102,103}。在SVM-2K,LSSVM-2K,LSSVM-2KI和LSSVM-2KII模型中,网格寻优参数范围取CA=CB={10-3,10-2,…,100,…,102,103},D={10-3,10-2,…,100,…,102,103},这里均采用高斯核函数κ(xi,xj)=exp(-‖xi-xj‖2/2σ2),其中σ是核函数参数,取值范围是σ={2-6,2-5,…,2-1,20,21,…,26}。为公平起见,以上所有模型的学习率γ取1,所有实验数据均进行归一化处理,并在同一条件下运行10次,取平均值来统计结果。
3.1 AWA数据集
通过将构建的模型应用在动物特征数据集上,探究在固定两个视角下不同分类对象的模型分类情况。AWA由50个动物类别的30 475幅图像组成,每幅图像有6个预先提取的特征表示。这里选取颜色直方图特征(Color Histogram Features)和加速稳健特征(SURF Features)两种不同的特征提取方案,分别作为视角A和视角B。在A、B两个视角中各自选取了4个测试类,即黑猩猩(chimpanzee)、美洲豹(leopard)、浣熊(raccoon)和斑马(zebra),共计2 712张照片的数据特征。通过一对一策略,为每个类共组合训练了6组二分类器,如表1所示。在每种动物类中随机选取100个样本作为训练集,其余的作为测试集。实验结果如表1所示。
根据表1可知,对于固定两个视角下不同分类对象的情况,LSSVM-2K、LSSVM-2KI和LSSVM-2KII模型的分类情况要明显优于同类其他多视角模型。对这3种模型进一步进行比较,可以发现LSSVM-2K分类情况良好且所需要的平均训练时间是同类中最少的,但它比LSSVM-2KI模型的分类效果在整体上略差一些。事实上,LSSVM-2KI是这3种模型中分类效果最好的,但训练耗时较长。LSSVM-2KII的分类情况在整体上表现则较为一般。

表1 AWA数据集的实验结果对比
3.2 Digits数据集
通过将构建的模型应用在UCI手写数字集上,探究新模型在固定两个分类对象下不同视角的分类情况。Digits数据集取自UCI数据库,由从荷兰公用事业地图集合中提取的共2 000个手写数字(0~9)构成。这些数字数据集由mfeat-fou、mfeat-fac、mfeat-kar、mfeat-pix、mfeat-zer和mfeat-mor提取方案的视角特征来表示,每个数字由200个被数字化成二进制图像的样本组成。取“0~4”之间的数字为“+1”类,“5~9”之间的数字为“-1”类。为了减少计算量,从每个类(正类或负类)随机抽取100个样本,每组实验总共200个样本作为训练集,其余的作为测试集。在选取的200个样本的基础上,通过一对一的策略,每次选择两个视角组成实验数据集,共训练了15组二进制分类器,实验结果如表2所示。

表2 Digits数据集上的实验结果对比
根据表2可知,对于固定分类对象下不同视角的情况,LSSVM-2K、LSSVM-2KI和LSSVM-2KII模型的分类效果同样要优于同类其他多视角学习模型。对这3种模型之间进一步进行比较,可以发现LSSVM-2K模型在此数据集上不仅分类效果在整体上表现更为良好一些,而且运算速度更快。LSSVM-2KI的分类效果在这3种模型中分类精度表现相对更稳定一些,但是平均训练耗时最长。而LSSVM-2KII在数据集Digits的分类效果介于两者之间,分类效果较为一般。
3.3 Forest Covertype Data数据集
通过将构建的模型在森林覆盖类型数据集上应用,探究各个模型随着训练集规模逐渐增大的情况下,训练时间的变化情况。实验中采用的数据集来自UCI Forest Cover Type(Frank & Asuncion,2010)数据集。UCI森林覆盖类型数据集包含581 012个实例,12个指标和54列数据(10个定量变量,4个荒野地区的二进制变量和40个土壤类型的二进制变量)以及7个目标类,代表从US Forest获得的30 m×30 m cells的森林覆盖类型。在UCI森林覆盖类型数据集中,40个属性为代表土壤类型的二进制列,4个属性为代表荒野区域的二进制列,其余10个为连续地形属性。在实验中,根据一对一的策略,从原来的7种分类问题中的Aspen(9 493组数据)和Douglas-fir(17 367组数据)两类数据集中随机抽取每类8 000个数据作为二分类对象,取前者为“+1”类,后者为“-1”类。这里将10个连续属性中的前5个属性和4个荒野区域的二进制列结合构成一个9维的数据集作为视角A,将10个连续属性中剩余的5个属性和40个土壤类型二进制列结合构成另外一个45维的数据集作为视角B。通过此数据集探究随着数据规模的逐渐增大,训练时间的变化情况。
图1说明了LSSVM-2K和LSSVM-2KI模型在Forest Covertype Data数据集上相比其他模型具有更好的分类性能,且模型随着训练集规模的增大,分类的精度也在逐渐提高。而且,LSSVM-2KI的分类效果相比LSSVM-2K模型要略胜一筹。

图1 Forest Covertype Data的精度折线图
为了更清晰地观察到训练时间的变化情况,对训练时间取以10为底的对数做出如图2所示的训练时间折线图。由于MVMED算法所需的训练时间过长,暂不予以考虑,仅对SVM+,SVM-2K、LSSVM-2K、LSSVM-2KI和LSSVM-2KII模型进行比较。

图2 Forest Covertype Data的训练时间折线图
图2表明了随着数据规模的增加,同类型的算法训练时间增加较为明显,而且SVM-2K模型的训练时间的增加尤其突出。LSSVM-2KI模型相比其他同类模型可以得到更高的分类精度,但所消耗的训练时间比LSSVM-2K和LSSVM-2KII更长。LSSVM-2KII模型是对SVM-2K模型的一致性约束的松弛变量添加了最小二乘思想,虽然分类效果上比SVM-2K模型略差一些,但是大大缩短了模型的训练时间。LSSVM-2K模型相比其他同类模型既可以得到相对较好的分类精度,而且又比同样应用了最小二乘思想的RMvLSTSVM耗时更少,所需的训练时间是最短的。实际上,与SVM-2K模型相比,LSSVM-2K在训练集规模达到2 000时,训练时间缩短了约90%,证明了LSSVM-2K模型具有计算方便、速度快、精度高的优点。
4 结束语
通过对SVM-2K模型不同程度地应用最小二乘思想,笔者分别构建了LSSVM-2K、LSSVM-2KI和LSSVM-2KII 3种模型。在固定视角下不同分类对象和在固定分类对象下不同分类视角的情况,探究了3种模型的分类情况。同时,探究了3种模型在不同规模的数据集下模型训练的耗时情况。实验表明,笔者提出的LSSVM-2KI算法可以有效地提高数据的分类精度,但耗时相对较长;LSSVM-2KII模型在分类精度和训练时间上整体表现较为一般;LSSVM-2K算法的分类效果虽然比LSSVM-2KI略差,但是与其他同类型的多视角分类模型相比要好,而且大大地缩短了模型的训练时间,研究思想具有一定的推广价值。
