BC算法性能与图数据格式的关系特性分析
2021-02-21邓军勇李远成
蒋 林,冯 茹,邓军勇,李远成
(1.西安科技大学 计算机科学与技术学院,陕西 西安 710600;2.西安邮电大学 电子工程学院,陕西 西安 710121)
图因其宜于表征不同实体间复杂的依赖关系而受到广泛应用[1-3]。社交网络分析[4]、推荐系统、交通网络等都紧密依赖于高性能、高能效的图计算系统[5-6]。然而,由于真实图规模的不断增加和图结构数据的复杂多变性,图算法变得越来越重要[7],使得其在遍历、查找等图计算过程中面临巨大的挑战。因此,学术界和工业界非常重视图数据的分析和预处理[8-9],其中设计数据的压缩格式是常用的重要手段之一。但是,不同的压缩格式对图算法会产生不同的影响,针对特定的图算法,如何根据其性能需求选择合适的压缩格式是一个待研究的问题。
目前,图数据基本表示格式主要有边阵列(Edge Array)和邻接表(Adjacent List)两种。以边阵列的方式存储,可以顺序地读取图数据中边的属性,能有效提高其访存效率。很多系统[10-13]都采用此表示格式来存储数据。邻接表存储方式将源顶点和目标顶点之间的有向边编码为非零项,可线性顺序地访问每一个顶点的所有边信息,有效减少了随机访问,从而提高内存访问速度,目前邻接表是大多数图计算系统[14-16]存储数据的选择方式。然而,对于大规模图进行计算时,传统的图数据存储格式限制了内存访问的速率。同时,因为真实图数据的稀疏性和幂律性等特征,大多数的图计算系统和加速器都会根据系统的特性以及存储的特性,重新设计数据的存储格式,以满足图计算系统的访存、特性,提高内存访问效率。
设计的存储格式表现多样化,不同的压缩格式需要能够支持对边的查询、循环遍历所有顶点的邻接点以及遍历所有的边。常见的压缩格式有压缩稀疏列(Compressed Sparse Column,CSC)[17-18]、压缩稀疏行(Compressed Sparse Row,CSR)[19]以及双压缩稀疏列(Doubly Compressed Sparse Column,DCSC)[18,20]等。它们共同的特点是以最小的开销紧凑地存储图数据,空间效率高,且允许快速遍历、查找[20]。但是,每种压缩格式都有其独特的优点和缺点,在算法的执行过程中,程序的性能不仅与输入图的大小以及算法的时间复杂度息息相关,更重要的是图数据的拓扑结构对算法产生的影响[21-22]。此外,由于各种图计算框架的引入导致许多应用程序具有不同的实现,框架的数据预处理方式的不同,使单个图算法的不同实现在可扩展性、计算操作、数据移动、能耗等方面可能会产生很大的差异。因此,研究人员了解图应用程序的各种实现特征非常重要。所以,针对不同的图应用程序选择合适的预处理方式,使得图应用性能最优是一个迫切需要解决的问题。笔者尝试分析了图应用中心性(Betweenness Centrality,BC)算法的性能与图数据格式之间的关系,选择5种图数据压缩格式,分别为按坐标表示(COOrdinate,COO)[23]、CSC、CSR、DCSC以及独立稀疏列压缩(Compressed Sparse Column Independently,CSCI)[24]。针对中心性算法,对不同输入格式数据的性能指标进行特性分析。性能指标参数包括数据移动量(Datamv)、计算量(Compute)、每周期指令数(IPC)、功耗(Energy)、各级cache缺失率(cache MPKI)等。通过性能事件统计结果,为遍历类应用中心性算法选择不同压缩格式的图数据提供了依据。
1 算法及压缩格式分析
1.1 中心性算法
中心性算法[25]是一种检测节点对图中信息或资源流的影响程度的算法。通过计算经过该节点并连接这两点的最短路径和这两点之间的最短路径数目,其比值越大,中心性越高[26]。在现实图网络中可以解决各种问题,比如优化通信网络和计算机网络的行为[27]、资源定位和分配[28-29]、发现电网等网络中的关键转移点[30]等。
中心性算法的基本思想为:图G=(V,E)是由节点集合V和连接各个节点之间的边E⊆V×V构成的数据结构。为了方便计算,假设图G是无向连接图,权重值默认为1。图中节点v的中心性值CG[v]是图G中任意两个节点经过节点v的最短路径条数与图G中任意两个节点之间的最短路径条数的比值:
(1)
其中,σst表示图中节点s到节点t之间最短路径的条数,σst(v)表示图中从节点s到节点v之间经过节点v的最短路径条数。现已知求图中节点的中心性值的最快的算法是由文献[25]提出的算法,计算未加权图的时间复杂度是O(mn),其中m表示边数,n表示顶点数。对于在集合V中的任意3个节点s、t和v,定义pair dependencyδst(v)和source dependencyδs•(v),分别表示如下:
(2)
(3)
根据上面的定义,式(1)可以写为
(4)
BRANDS提出的source dependencyδs•(v)计算公式如下:
(5)
其中,σij是节点i到节点j的最短路径条数,Ps(w)是从节点s广度优先搜索的无向图中节点w的父节点组成的列表。BRANDES提出的算法主要分为两个步骤:第1步执行从节点s开始,使用广度优选择遍历(Breadth Fist Search,BFS)算法计算到节点t的最短路径条数σst和Ps(w),节点t∈V且s≠t;第2步执行从叶子节点到根节点的反向BFS算法和利用式(5)计算δs•(v)。
算法1Betweenness Centrality(BC)。
输入:GraphG(V,E),顶点V和边E,且E⊆V×V。
输出:中介中心性值CB(v)。
① for everyv∈VdoBC(v)←0
② for everys∈Vdo
③ run Dijkstra SSSP(G是有向图)fromsor run BFS(G是无向图)
④ ∀t∈V{s}.计算σst和Ps(t)
⑤ store vertices in StackSin non-increasing distance froms
⑥ for everyv∈Vdoδs•(v)←0
⑦ whileS≠0 do
⑧w←pop(S)

⑩ ifw≠sthenCB(w)←CB(w)+δs•(w)。
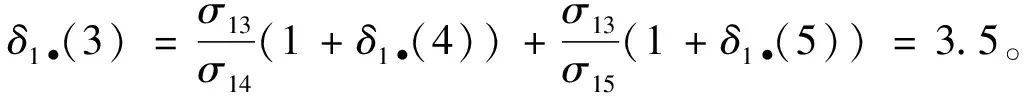

图1 BC算法示例以及计算δ1•(v)的过程
1.2 图数据压缩格式分析
(1)COO压缩格式按坐标表示,是图数据压缩格式中最基本的压缩方式。每一个元素需要用一个三元组来表示,包含行索引、列索引以及数值。COO压缩格式中的三元组都可以直接定位,实现起来较为简单,但是记录的信息多,因此占用空间较大。COO格式的时间复杂度是O(V+E),如图2所示为图的基本表示方法。
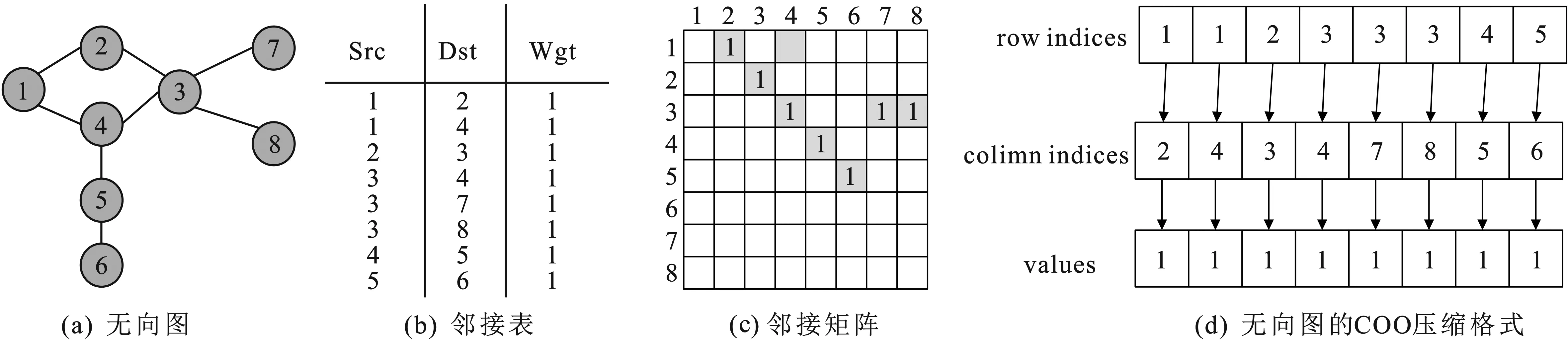
图2 图的基本表示方法
(2)CSR压缩格式按行进行压缩,需要使用row offset(行偏移量)、column indices(列索引)和values(权值)3个数组存储。row offset表示某一非零行的第1个元素在values里面的起始偏移位置(即该元素所在当前行之前的非零元素个数),column indices表示非零元素的列索引,values表示列索引对应的权值。CSR将数据进行打包存储,因此添加和删除数据的时间与图数据的大小呈线性关系,CSR格式的空间复杂度为O(V+E)。邻接矩阵图2(c)的CSR压缩格式如图3所示。

图3 邻接矩阵的CSR压缩
(3)CSC压缩格式按列进行压缩,与CSR类似,节省了内存大小,简化了图构建、复制以及传输的复杂性。需要3个数组表达:column offsets(列偏移量)、行索引(row indices)和权值(values)。column offsets表示某一非零列的第1个元素在values里面的起始偏移位置(即该元素所在当前列之前的非零元素个数),row indices表示非零元素的行索引,values表示行索引对应的权值。邻接矩阵图2(c)的CSC压缩格式如图4所示。

图4 邻接矩阵的CSC压缩
(4)DCSC是一种双重压缩稀疏列的压缩格式,是CSC的一种扩展格式。该压缩格式可以有效存储大规模稀疏矩阵。主要是使用column offsets、row indices、column indices以及values来存储图数据,其中,column indices是对column offsets二次压缩,表示至少有一个非零元素的列索引,其他数据与CSC压缩格式类似。邻接矩阵图2(c)的DCSC压缩格式如图5所示。

图5 邻接矩阵的DCSC压缩
(5)CSCI是一种独立稀疏列压缩格式,每列图数据包括列标识数据对和非零元素数据对,需要使用ioc(标识符)、column(row)indices以及values(权值)3个数组存储。将图数据独立地压缩成多个数据对(ioc,indices,values),ioc为“1”,则indices指向column,values表示该列非零元素的个数;若ioc为“0”,则indices指向row,values表示该非零元素的值。邻接矩阵图2(c)的CSCI压缩格式如图6所示。

图6 邻接矩阵的CSCI压缩
2 硬件环境建立与性能模型
2.1 硬件平台搭建
本次实验是在HPE580高性能服务器上进行的,该服务器配备了Inter(R)Xeon(R)Platinum 8164 CPU。该服务器具有208个物理核416线程,每个核心都有一个32 kB的L1级数据cache,一个32 kB的L1级指令cache,1 024 kB 的L2级cache以及36 608 KB的L3级cache,内存大小为1 TB,运行Linux内核4.15.0系统。表1总结了测试平台的具体信息。采用评测工具Perf[31]对影响计算性能能耗的性能事件基于真实图进行不同图计算应用下的参数统计。Perf是内置于Linux内核源码树中的性能剖析(profiling)工具。它基于事件采样原理,以性能事件为基础,对处理器相关性能指标与操作系统相关性能指标进行性能剖析。性能指标参数主要包括:数据移动量(datamv)、计算量(compute)、能耗(energy)和执行时间(exec.time)等。

表1 实验平台信息性能参数
2.2 数据集选取
中心性算法在社交网络结构上有广泛的应用,可以捕获网络中单个节点的相对重要性。实验数据选自斯坦福大学的SNAP(Stanford Network Analysis Project)数据集中Social networks的feather-deezer-social、Wiki-Vote和ca-AstroPh[32]以及网络数据仓库(The Network Data Repository with Interactive Graph Analytics and Visualization)数据集中Social networks的Soc-brightkite、Soc_gemsec_HU和Soc_gemsec_HR[33],具体顶点个数、边数以及内存占用情况如表2所示。

表2 实验所选数据集
2.3 性能指标定义
根据统计的硬件性能事件,笔者分析的性能指标如下:IPC、数据移动量、功耗、计算量、L1、L2以及L3数据缓存MPKI。由于输入图数据规模差别较大,笔者将性能指标统一到每一条边的处理上。
(1)执行时间。执行时间(Exec.Time)直接决定了图处理性能。任务的执行时间即目标任务真正占用处理器的时间。根据下式可计算不同压缩格式中每条边的执行时间(单位为ms):
E=Tt/Ne。
(6)
(2)IPC。IPC(Instruction Per Clock)是衡量处理器性能的一个基本指标,表示平均每一时钟周期所执行的指令数。一般IPC越大越好,说明程序充分利用了处理器的特征。首先,通过运行算法代码,计算运行所需要的机器级指令的数量;其次,使用高性能计时器计算在实际硬件上完成运行代码所需要的时钟周期数,即根据下式计算算法设计的IPC:
I=i/c,
(7)
其中,i表示执行的指令数,c表示时令中数。
(3)数据移动量。数据移动量(datamv)受延迟和带宽的限制,在高性能计算程序中往往属于不可并行或者很难并行的部分。据观察,移动数据的成本高于计算操作的成本。在大数据时代,很多应用越来越受到数据移动成本的影响。在图计算中,这个问题是一个突出的问题。为了显示数据移动问题的强度,应测量每个图中的数据移动的数量。注意,这是移动操作的次数,而不是移动的数据量。数据移动量D表示记录加载(load)和存储指令(store)之和的计数与边(edges)数量的商,即
D=(Nload+Nstore)/Nedges。
(8)
(4)功耗。在大图分析中,功耗E(Energy)是一个必不可少的考虑因素,尤其是对于移动设备。由于能耗应该随着图的大小而伸缩,用每条边的功耗来代替功耗效率,如下所示:
E=Rpower_all/Nedges,
(9)
其中,Rpower_all表示执行期间的功耗(单位为J)。
(5)MPKI。MPKI(Misses Per Kilo Instructions)是一个用来分析cache性能的通用指标,表示每千条指令的平均未命中数。MPKI通常优于cache Miss,因为MPKI还传达了关于内存访问指令在整个指令流中的比例的信息。可根据下式计算各级cache的M(MPKI):
M=1 000m/i,
(10)
其中,m表示cache未命中数,i为指数。
(6)计算量。计算量性能指标对于算法分析也极为重要。使用每条边上的计算量表示不同压缩格式处理数据集的计算量效率C:
C=(i-l-s-b)/Ne,
(11)
其中,i表示当前执行的指令总数,l表示加载指令数,s表示存储指令数,b表示分支指令总数。
3 不同压缩格式的内存占用情况及特性分析
针对中心性算法,通过对6种不同的输入图数据集进行5种压缩格式的比较分析。本节从多个角度提供了比较结果与相应分析。
3.1 不同压缩格式内存占用情况
6种输入图数据集经过5种压缩格式后的内存占用情况如图7所示。图中显示,将其他压缩格式的数据归一化到COO格式,且其余格式都对数据进行不同程度的压缩,其中DCSC对数据压缩最明显,CSCI的压缩结果最不理想,CSC以及CSR的结果比较好且相差不大。稀疏矩阵通过压缩数据的方式更新成本来节省这些空间存储。CSC和CSR压缩格式输出结果主要包含行(列)偏移量、行(列)索引以及权值,所以,压缩效果比较好且占用的内存的大小较小。若稀疏矩阵的行数和列数接近或是对称矩阵,压缩格式的结果则会趋于相近,甚至相同。DCSC为双压缩稀疏列格式,在CSC的基础上对列偏移量进行压缩,主要包含非零列的列偏移量、非零列的行(列)索引以及权值。因此,DCSC的压缩效果最好,占用内存最小,存储效率最高。CSCI是独立压缩稀疏列,需要将非零元素在该列的个数以及索引全部输出,占用内存空间非常大,存储效率最慢。
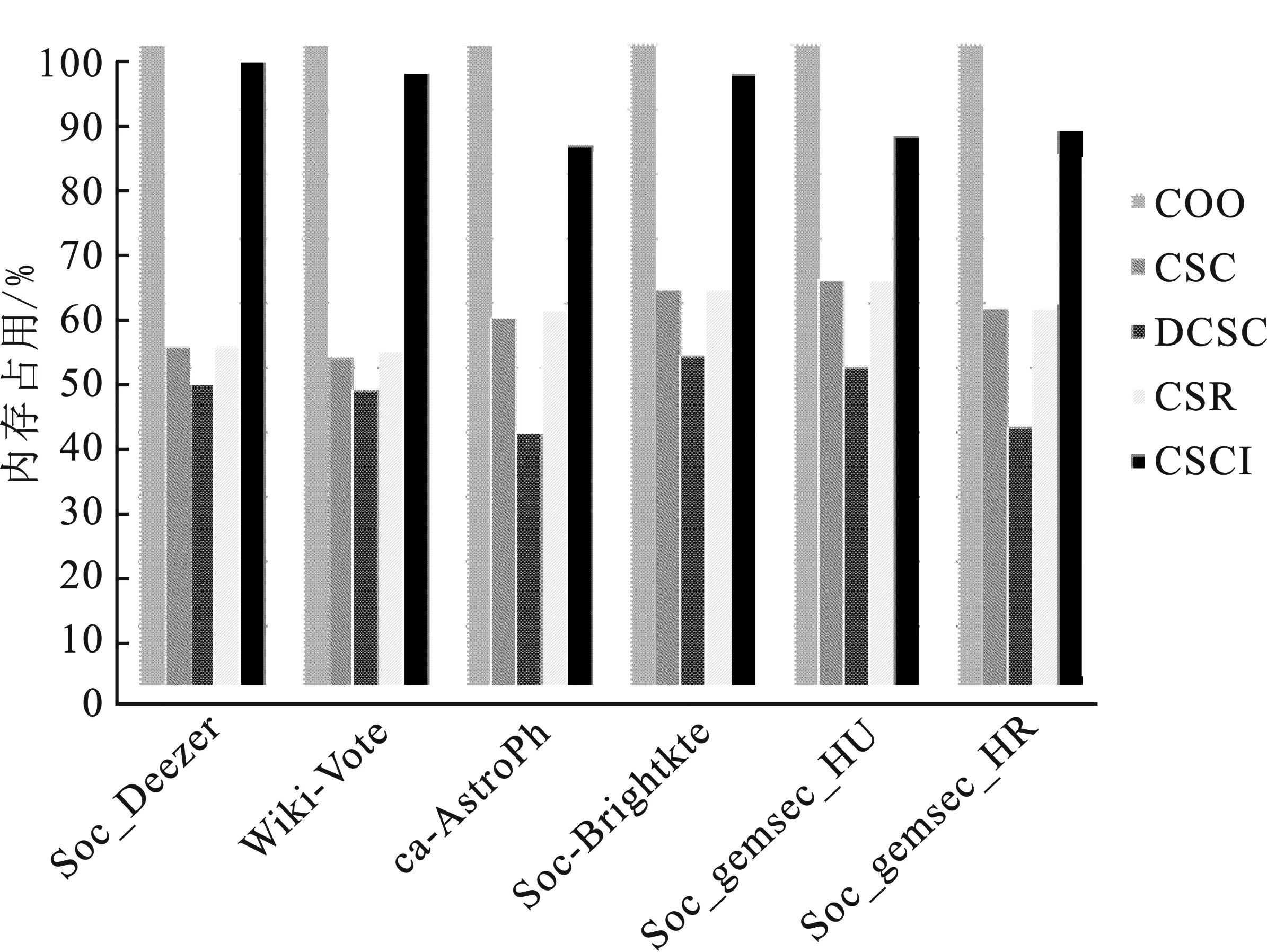
图7 6种数据集5种压缩格式下的内存占用情况(归一化到COO格式)
3.2 不同压缩格式的特性分析
对不同压缩格式处理中心性算法的性能特征进行系统分析,通过雷达图形式形象地展示了6种数据集的COO、CSR、CSC、DCSC以及CSCI 5种压缩格式处理BC算法的性能,如图8所示。

(a)feather-deezer-social
图8(a)~(f)分别表示6种数据集feather-deezer-social、Soc-brightkite、Wiki-Vote、ca-AstroPh、Soc_gemsec_HU 以及 Soc_gemsec_HR下的性能雷达图。雷达图中性能指标包括执行时间(exec.Time)、IPC、数据移动量(data.move)、三级cache MPKI以及功耗(energy)。其中,每个度量指标的最大值视为100%,其他数据以此作为标准。另外,采用Pearson相关系数分析方法,将参数实测结果与性能指标进行相关性分析,具体分析结果如下。
(1)执行时间。图9给出了6种数据集在不同的压缩格式下每条边的执行时间。图9显示,COO和CSCI执行边的时间最长,且随着数据集边数的增大,CSCI的执行时间也在呈正相关增长。DCSC压缩格式次之,同时发现随着数据的稀疏性越来越明显,DCSC压缩格式的执行时间越来越短,这是因为DCSC在CSC的基础上对列偏移量进行压缩,使得数据更加具有相关性。CSC和CSR压缩格式的结果最接近,且执行时间最短,原因在于,这两种压缩格式只记录当前活动顶点的偏移量、索引值和权值,占用内存小且存储速率高,可快速定位顶点信息。因此对于以遍历为中心的算法,在考虑边的执行时间的情况下,优先选择CSR和CSC压缩格式作为参考。

图9 5种压缩格式下每条边的执行时间
(2)数据移动量。6种数据集在不同的压缩格式下每条边的数据移动量如图10所示。数据移动量主要是由于CPU与内存交互这个过程影响的,若CPU减少Load和Store次数,则可有效提高运算效率。图10显示,数据移动量会随着数据集的增大而增加。CSR压缩格式相对于其他压缩格式具有较好的边的数据移动量,COO和CSCI压缩格式的数据移动量最差,原因在于这两种压缩格式压缩的效果不理想,导致存取数据操作复杂。DCSC相较于CSC和CSR次之。因此对于以遍历为中心的算法,在考虑边的数据移动量的情况下,应选择CSR或者压缩格式。

图10 5种压缩格式下每条边的数据移动量
(3)功耗。图11给出了6种数据集在不同的压缩格式下每条边的功耗。可以看出,CSR和CSC压缩格式的每条边的功耗最小,原因在于这两种压缩格式记录了每一个顶点的行(列)偏移量,可以快速地遍历查询当下顶点的邻接点,可以很大程度上降低能耗。COO和CSCI压缩格式完整地记录了从源顶点到邻接点的信息,对于较大的稀疏矩阵,消耗能量较大。DCSC在图数据的稀疏性比较明显时,才能发挥特长。因此,对于以遍历为中心的算法,在考虑边的能耗的情况下,应选择CSR(CSC)压缩格式,当数据量足够大时,应考虑DCSC格式。

图11 5种压缩格式下每条边的功耗
(4)cache MPKI。6种数据集在不同的压缩格式下的L1、L2、L3级的cahe MPKI如图12所示。图12显示,L1级的cache MPKI平均大于L2级的cache MPKI,L3级的cache MPKI更是微乎其微,主要考虑对L1级的cache MPKI的影响程度。影响各级cache缺失的因素主要与数据集的规模、程序访问的局部性规律以及映射方式等相关。可以发现,CSC压缩格式的cache缺失率最低,因此对于以遍历为中心的算法,在考虑cache性能的情况下,应选择CSC压缩格式。

图12 5种压缩格式下L1、L2、L3级的cache MPKI
(5)计算量。6种数据集在不同的压缩格式下每条边的计算量如图13所示。CSR压缩格式的计算量最小,COO和CSCI压缩格式的计算量最高,原因在于程序需要全部遍历当前顶点的邻接点,数据信息复杂,因此平均到每条边的计算量便会增大。并且,随着数据规模的增大,COO和CSCI处理数据的计算量将会是CSR的数倍。因此,在考虑数据计算量受限的情况下,优先选择CSR压缩格式。

图13 5种压缩格式下每条边的计算量
4 结束语
笔者针对以遍历为中心的中心性算法,通过分析6种数据集下的5种压缩格式(COO、CSR、CSC、DCSC、CSCI)的性能数据,根据其特征得出以下结论:对于BC算法,考虑到数据规模复杂影响内存存储效率,应优先选择DCSC压缩格式,可有效提高图数据的访存速度;在硬件环境有限的情况下,应优先选择CSR压缩格式,可有效减少程序执行时间、数据移动量以及降低能耗;在有效提升cache的性能,降低cache缺失率的情况下,优先选择CSC压缩格式;当程序的计算量受限时,优先选择CSR压缩格式;CSCI压缩格式是结合线性代数中矩阵向量乘积可以看作矩阵列向量的线性组合提出的,在硬件加速器的数据并行性方面有一定的优势,但在通用处理器上的图应用方面并不理想;COO压缩格式在提升图计算应用性能方面相对较差。综上所述,针对以遍历为中心的BC算法,研究者可以针对不同的应用环境、不同的性能需求和软硬件条件,基于上述结论进行实际需求的调整,可有效提升图计算系统的性能。同时,笔者预估在其他的遍历类应用,结果具有相似性,在后续的工作将逐步验证。
