基于联合特征和迁移学习的跨域图像分类方法
2021-02-16孟欠欠伏明兰沈龙凤李梦雯
孟欠欠,伏明兰,沈龙凤,李梦雯
(淮北师范大学 计算机科学与技术学院,安徽 淮北 235000)
图像领域中,基于稀疏编码的特征表示方法仍被广泛应用,Sha L等[1]人将稀疏编码与拉普拉斯正则化相结合,用于图像复原;钱冲等[2]人提出图拉普拉斯正则化稀疏变换的图像去噪学习方法;刘明等[3]人提出核稀疏编码方法,用于阵发性房颤检测;Zhang H等[4]提出低秩分解与卷积稀疏编码相结合的图像分解算法。以上编码学习方法常需要足量的源域(带标记)样本,源域(带标记)与目标域(无标记)样本服从同一特征分布,训练的分类模型可取得较好效果。但是在实际应用中,各种因素的存在往往导致源域与目标域样本处于不同分布中,诸如分辨率、表情、动作等差异均会造成特征的分布发生改变。此外,从互联网下载的用于训练的图像与来自真实场景中不同光照或角度的图像之间的分布也不同。这种情况通常要求对源域数据重新标注,会耗费大量资源,如何有效充分利用这些不同分布的源域数据,是当前阶段亟需考虑的重要问题,许多专业学者也提出了解决方案:迁移学习[5-7]。
迁移学习的核心是找到源域与目标域的相似性,而通过MMD计算源域与目标域之间的距离常作为评价相似性的重要指标。Zhang J等[8]人在低维空间中进一步减少源域与目标域的几何移位与分布移位。姚明海等[9]人提出一种多层校正的无监督领域自适应方法,采用多层权值最大均值差异适应目标域。Wang J等[10]人在边缘分布差异的基础上进一步结合两域的条件分布。Li S等[11]人综合考虑类内距离与类间距离,降低两域的分布差异。赵鹏等[12]人提出基于联合特征分布和实例的迁移学习方法,引入权值调节系数权衡两者的重要度。Han N等[13]人提出利用低秩重构的方法减少源域与目标域的分布差异。Chen D等[14]人提出双图正则化判别转移稀疏编码算法,将域内与域间相似性构造对偶图来度量不同数据集的距离。李萍等[15]人提出联合类间及域间分布适配的迁移学习方法,进一步最大化源域的类内分布距离。
根据上述情况,发现基于编码的迁移学习方法存在以下两个问题:(1)随机初始化字典,学习的初始基向量随机性强,不利于后序字典学习;(2)在子空间中单一考虑了域间的边缘分布,忽略了域间的条件分布和源域的类间分布。基于此种情况,本文首先提出基于联合特征和迁移学习的跨域图像分类方法,利用Kmeans初始化字典,学习更具代表性的字典基;其次使用MMD度量分布距离,进一步考虑边缘分布、条件分布和类间分布,并在通用的迁移数据集上进行相关跨域实验验证所提方法的有效性和可行性。其算法流程图如图1所示。
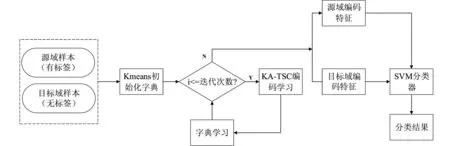
图1 KA-TSC算法流程
1 问题定义与符号说明
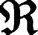
P(Xs)≠P(Xt),Q(Ys|Xs)≠Q(Yt|Xt)
(1)
使用MMD经验估计度量任意两个样本集Xs,Xt对应的不同分布Ps,Pt之间的距离,如式(2)所示。
(2)
其中ns,nt分别为Xs,Xt的样本数,Xsi,Xtj分别为Xs,Xt中的样本,φ(·)为映射函数。
2 KA-TSC方法
2.1 Kmeans字典优化
图题与表题的写作要求为学习更具代表性的字典基,采用Kmeans聚类方法初始化字典,主要学习目标是将给定的数据集X划分为k个簇,并给出每个样本数据对应的中心点,且收敛速度快。其算法步骤如下:
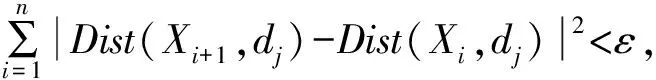
(4)重复执行(2)—(3),直到簇中心不在发生变化;
算法伪代码如表1所示。

表1 Kmeans字典初始化算法
2.2 类间及域间差异项
迁移学习的关键是尽可能缩小源域与目标域的分布差异,其中数据域的边缘分布体现了目标域的聚类情况,而领域的条件分布体现了带标记数据的判别结构,源域中不同类别样本间分布体现了带标记样本的差异性。文中用MMD度量源域与目标域的分布距离,旨在减少域间的边缘和条件分布差异,并优化源域不同类别样本分布差异。接下来将依次计算三种分布距离。
首先,计算源域与目标域的边缘分布,计算公式如式(3)所示。
(3)
(4)
其次,对于两域的同类样本条件分布,MMD距离计算公式如式(5)所示。
(5)
其中c=1,2,…,C,Mc是MMD矩阵,如式(6)所示。
(6)
最后,源域中不同类样本间的MMD距离计算如式(7)所示。
(7)

(8)
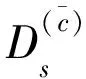
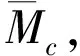
mintr(AMfAT)=mintr(AM0AT)+
(9)
2.3 图拉普拉斯正则项
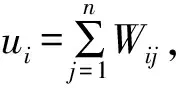
(10)
2.4 目标模型
综合稀疏编码项、域间和类间分布差异项、图拉普拉斯正则项以及稀疏保持项,建立数学模型如式(11)所示。
(11)
3 模型求解
由于模型(11)存在两个自变量D和A,在求解的过程可以分为编码学习与字典学习两部分。因此,目标函数可分解为两个子函数,并分别交替迭代寻优,最终使目标函数收敛。
3.1 编码优化
为更新编码系数,需要固定字典D,如式(12)所示。
(12)

(13)

3.2 字典优化
首先,利用Kmeans方法初始字典基向量;其次,为更新字典,需固定A,字典优化模型如式(14)所示。
(14)
对于带二次约束的最小平方凸优化问题,可先将式(14)转化为拉格朗日对偶(Lagrange dual)问题,如式(15)所示。
L(D,Λ)=Tr((X-DA)T(X-DA))+
(15)
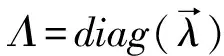
L(D,Λ)=tr(XTX-2AXTD+
DAATDT+AΛAT-cΛ)
(16)
接下来对式(16)求导,结果如式(17)所示。
(17)
求解结果如式(18)所示。
D=(XAT)(AAT+Λ)-1
(18)
将式(18)带入式(16),在利用拉格朗日对偶,可求取Λ,在反带入公式(18)求字典D。
3.3 本文算法
KA-TSC伪代码如表2所示。

表2 KA-TSC算法
4 实验及结果分析
4.1 数据集和评价标准
文中实验分别在字符数据集MNIST和USPS,人脸识别数据集PIE和对象识别数据集Office通用的迁移数据集上进行。其中MNIST和USPS数据集各提取2000幅和1800幅字符图像,两者分别作为源域和目标域,形成两对迁移学习任务MNIST_vs_USPS和USPS_vs_MNIST,图像大小为28×28,类别数为10。Office包含三个子数据集Amazon、Webcam和Dslr,将三个子集分别与Caltech数据集结合,从中随机选取两个分为作为源域和目标域,形成六个不同的学习任务,图像大小32×32,类别数为10。共设计16组迁移学习任务,每组任务属于同一类别,但服从不同分布,所用数据集的统计信息如表3所示。
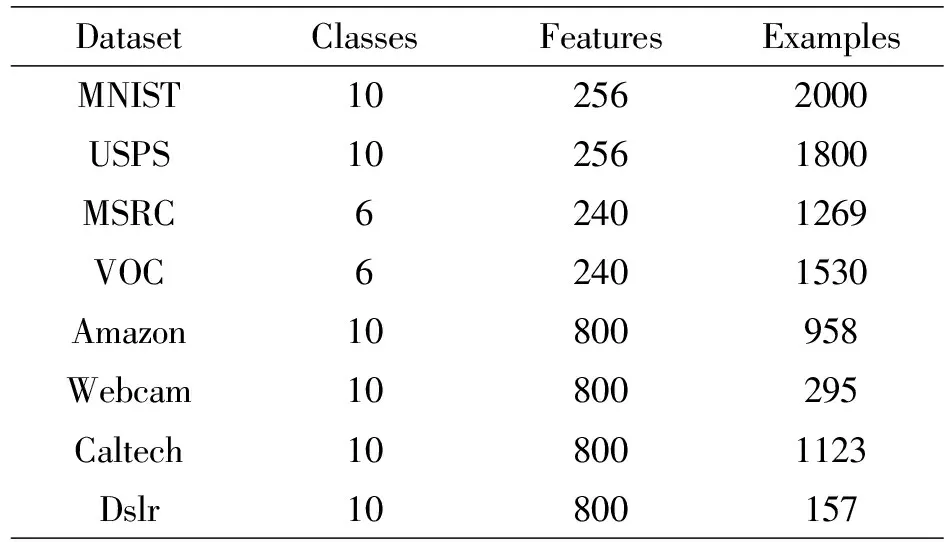
表3 实验数据集
本文通过对目标域上的样本计算平均分类准确率(Accuracy)作为算法效果的评价标准,公式如式(19)所示。
(19)
其中,Dt表示目标域,f(x)为测试集x的真实标签,y(x)为测试集x的预测标签。
4.2 对比方法和参数设置
文中对比方法为稀疏编码(SC)、图正则化稀疏编码(GSC)和迁移稀疏编码(TSC)。各参数设置如下:稀疏编码中k-128,λ=0.2;图正则化稀疏编码中k=128,γ=1,λ=0.1;迁移稀疏编码中k=128,γ=1,λ=0.1,μ=1e5。所提方法参数设置如下:图正则化参数设为1,权重调节因子β取0.1,聚类维度取128,迭代次数设置为10,对于MMD正则化参数和稀疏惩罚因子,在MNIST+USPS、Office+Caltech数据集上分别取1e5和0.01,在MSRC与VOC数据集上分别取1e6和0.1。实验结果如表4所示,为方便比较,对比直方图如图2所示。
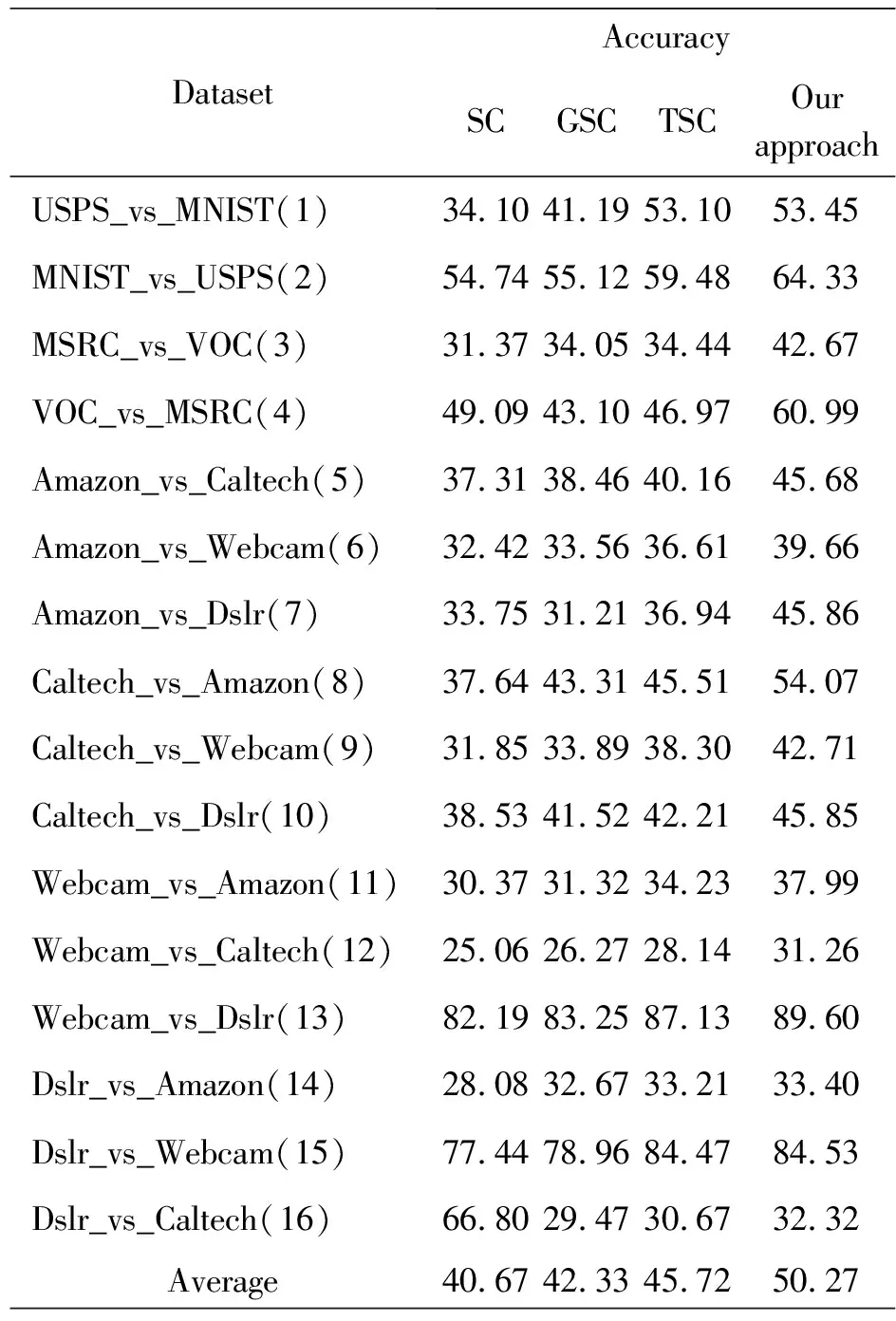
表4 4种方法在16个跨领域分类任务上的性能对比

图2 分类精度柱状图
从表4可以看出,相比SC、GSC和TSC算法,本文方法的分类准确率有一定程度的提升,分别提高了9.6%、7.94%和4.55%,实验结果体现了与传统方法相比,KC-TSC方法可更有效解决迁移学习问题,验证了本文方法的有效性,即初始化基向量和考虑域间及类间分布差异的重要性。
为表明本文方法的有效性,从跨域数据集A_D中源域Caltech选取100幅图像,从Dslr数据集中选取100幅图像,构建基于其稀疏编码的权值矩阵,并根据权值矩阵画出了四种稀疏编码方法的编码散点图,如图3所示。
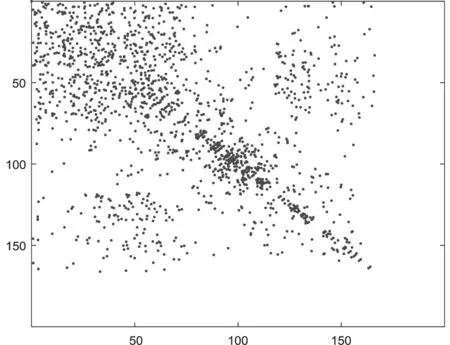
(a)SC权值矩阵
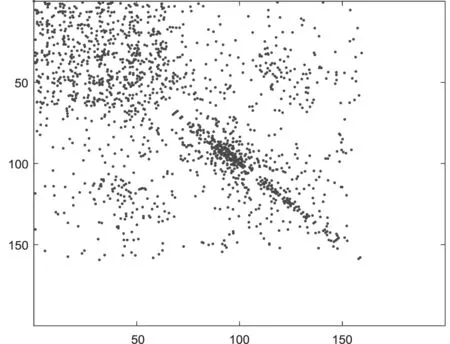
(b)GSC权值矩阵

(c)TSC权值矩阵

(d)KA-TSC权值矩阵
从图3中可以看出,左上和右下表示同域的分布差异,而左下和右上角为跨域的分布差异,可以看到SC、GSC方法中跨域分布较为稀疏,表明源域与目标域分布差异较大;而TSC和KA-TSC因为考虑了域间分布差异,散点面积更广,表明了缩小域间分布差异的重要性;而KA-TSC比TSC分布更为丰富,表明了本文方法进一步考虑类间差异的有效性。
4.3 参数分析
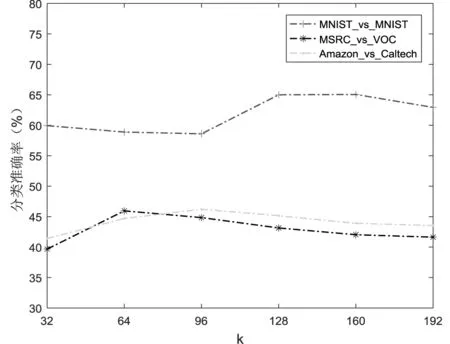
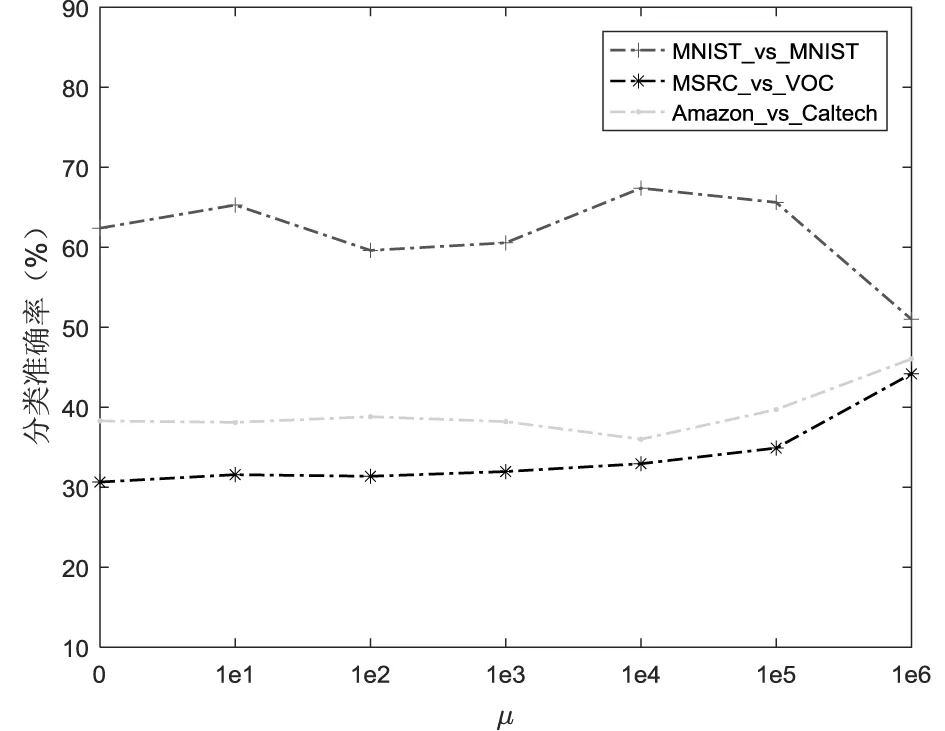
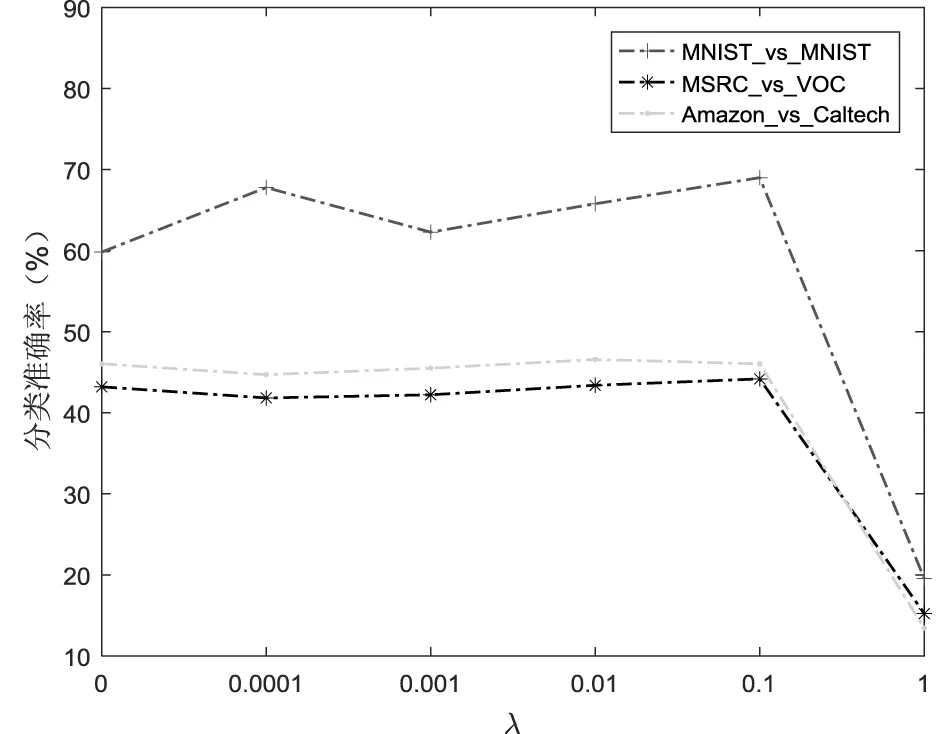
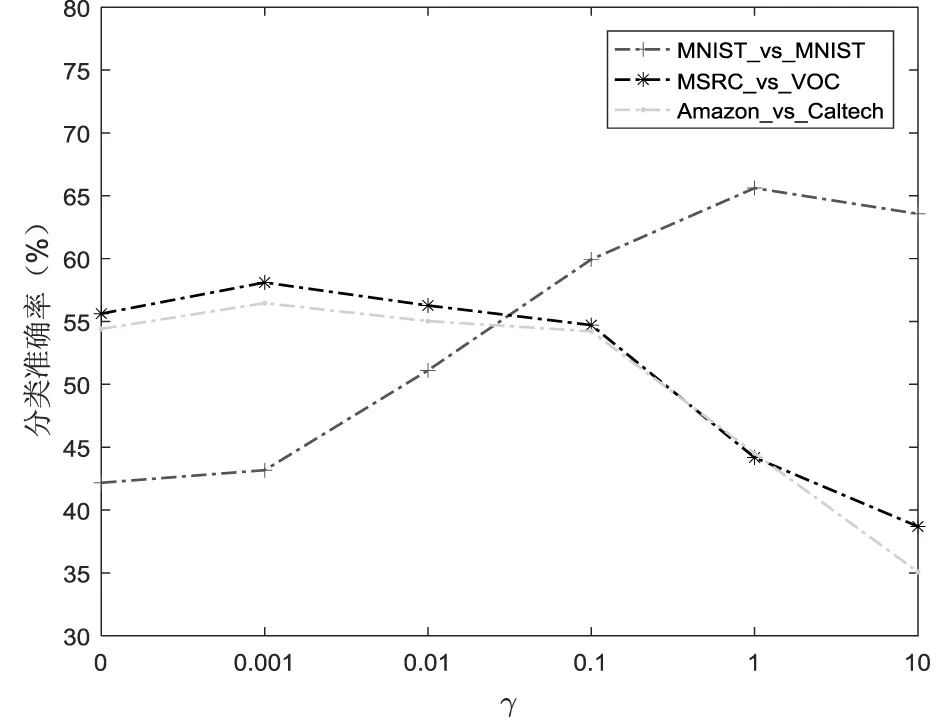
为了分析各个参数对分类性能的影响,本文选择部分跨域领域任务USPS_vs_MNIST,MSRC_vs_VOC,Amazon_vs_Caltech进行测试,分别测试β、κ、μ、λ、γ和迭代次数NT对分类精度的影响。采用的方法是控制变量法,通过固定其中3个参数,设置另一个参数进行实验。实验结果如图4所示。

(a)权值调节因子β
(b)聚类维数k
(c)最大均值差参数μ
(d)稀疏惩罚参数λ
(e)图正则化参数γ
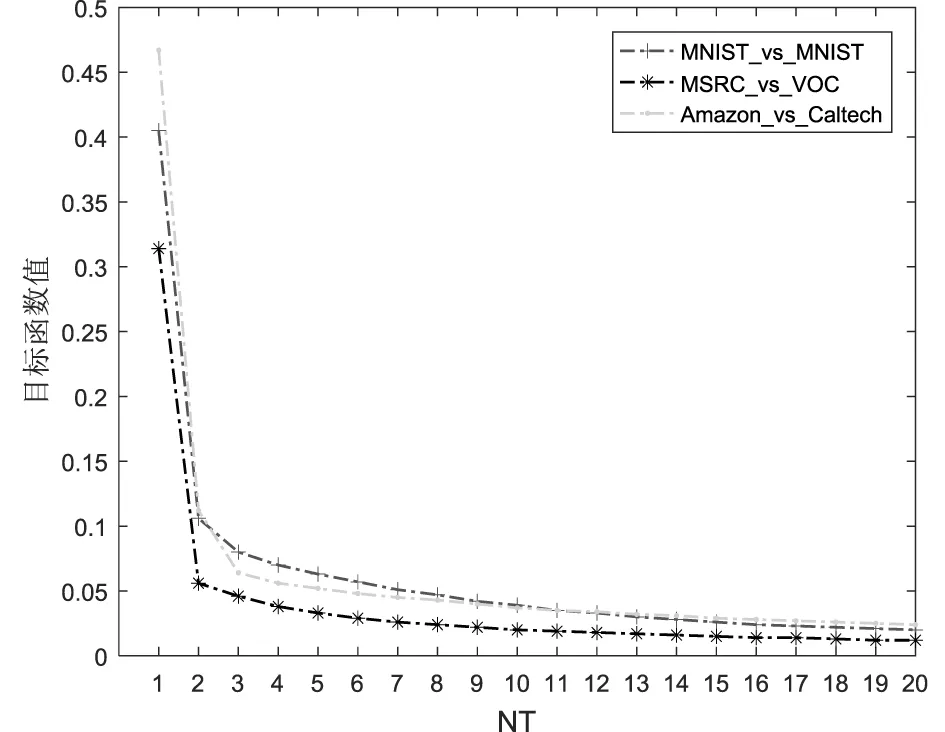
(f)迭代次数NT
首先,分析权值参数的影响,如图4(a)所示,可以看出,在β∈[0.05,0.45]时,在这个较宽的范围内分类效果较好,而当β∈[0.45,1]时,仅有个别数据集的分类性能有所提高。其次,对于聚类数k,实验效果如图4(b)所示,观察得出,当κ∈[128,160]时分类性能最稳定。均值差参数μ对分类性能的影响如图4(c),当μ∈[1e4,1e5]时分类效果较稳定,当μ=1e6,部分数据集分类性能有所提高。稀疏参数λ和图正则化参数γ的影响如图4(d)和图4(e)所示,当λ∈[0.01,0.1]和γ∈[0.1,1]时效果稳定。图4(f)为迭代次数对目标函数收敛度的影响,明显可以看出,目标函数是逐渐收敛的。可见,本文方法可在有效范围内实现源域到目标域的有效迁移,一定程度提高跨域分类准确率。
结语
本文提出的基于联合特征和迁移学习的跨域图像分类方法(KC-TSC),在迁移稀疏编码的基础上,首先在字典学习上通过Kmeans聚类初始化字典基,学习更具代表性的初始字典;其次在编码学习中进一步考虑域间和类间分布差异,在目标函数中最小化源域与目标域的条件分布并最大化源域中类间分布,并借助平衡因子调节分布权重。在目标函数的求解中,利用拉格朗日对偶法和特征符号搜索法优化字典和编码,通过迭代求解,学习特征表示。最终,在MNIST和USPS、Office和Caltech等多个通用迁移数据集上进行对比实验和参数分析,主要发现如下:(1)利用Kmeans初始化字典是字典优化的有效方法;(2)充分考虑域间与类间分布差异,可有效提高源域到目标域的迁移性能。
