应用于农业场景视觉解析任务的番茄数据集
2021-02-13周玲莉张文翔程雅雯易中懿
周玲莉 任 妮 张文翔 程雅雯 陈 诚 易中懿
(江苏省农业科学院信息中心,南京 210014)

数据库(集)基本信息汇总表
1 引言
随着计算机视觉技术的发展,复杂环境下的视觉解析在诸多领域中发挥出巨大的作用,包括交通、医疗、金融等[1][2]。现如今在深度学习[3]的大背景下,计算机视觉技术又跨上一个新台阶,各领域中的机器人系统离不开包括图像分类[4]、物体检测[5]、图像分割[6][7]等视觉任务的顺利交付。支撑深度神经网络发展的一个重要元素是大规模、标注过的图像数据集[8][9],比如在自动驾驶领域,诸如Cityscapes[10]、KITTI[9]等在内的城市道路场景解析数据集。这些大规模数据集是深度神经网络的基石,使得基于深度学习的计算机视觉技术能有更好的性能表现。
在农业领域,由于农作物种类繁多、背景复杂、数据采集困难等原因,大规模的可用于深度学习的数据集相对较少,算法的实现与评价通常依赖研究人员自身收集的少量数据[11][12][13]。比如论文[11]与论文[13]虽然具有相同的视觉任务,两者都是使用深度学习方法对苹果果实进行识别和定位,但由于前者采集数据过少且标注较为简单,后者无法对这些数据进行再利用,只能重新进行拍摄与标注。因此,在评价指标相同的情况下,研究成果之间不具有可比性,彼此之间的优劣无法体现,进而限制了深度学习方法在农业领域的研究应用,导致计算机视觉技术在此领域的发展相对落后。此外,还有一些研究中所用的数据是在实验环境中获得的,比如在论文[14]中,使用从谷歌搜集到的图片进行深度学习的训练实现目标果实的检测,然后在搭建的实验环境中进行评估与测试。实验环境与作物实际复杂生产环境相差甚远,因此文中提出的方法难以适用于真实农作场景下的应用。
为了缩小差距,一些学者也做了不少的尝试[15][16],其中最值得关注的是Wageningen 大学等人制作的甜椒数据集[17]。他们提出一种人工数据合成方法,使用软件模拟制作出甜椒种植环境,然后通过渲染得到甜椒合成图像以及对应合成语义分割标签。然而,如图1(a)所示,他们提供的甜椒经验图像是在特殊光照下拍摄的,参照经验图像制作的合成图像也是背景类似的暗图像,但大多数农业机器人都是在自然光照下作业,其相机拍出的图像如图1(b)所示。

图1 (a)甜椒经验图像和(b)番茄经验图像Fig.1 (a)pepper empirical image and(b)tomato empir⁃ical image
本文从对番茄采摘机器人的研究出发,结合其视觉系统中当前以及长远对数据的需要,提供一个包含合成部分和经验部分的大规模番茄图像数据集。其中,合成部分参考Wageningen 大学等人[17]提出的数据合成方法,生成3250 张合成图像和对应的像素级语义分割标签,可用于计算机视觉模型的预训练;经验部分包含750 张单目图像和400 张双目图像,这些图像都拍摄于真实番茄生产温室,保证了数据的真实性与复杂性。对于部分经验图像,除了进行像素级语义分割标注外,还为可采摘果实和不可采摘果实两个类别添加了实例级语义分割标注,并使用软件自动生成两种果实的物体检测标签,保证了标注信息的多维性。该番茄数据集为采摘机器人视觉系统提供数据支持,具有很高的实用性与价值性,也为其他作物生长环境下的视觉解析任务提供预训练数据,为计算机视觉技术在农业领域的发展提供了一定的数据基础。
2 数据采集与处理方法
2.1 经验图像的采集
经验图像的拍摄地址为江苏省农业科学院的番茄生产智能温室,该温室专门用于设施果蔬智能化生产技术的集成与示范。温室中育有苏粉11 号等品种番茄共18 行,行间距90cm,每行每隔25cm 育有一颗番茄植株。由于拍摄场景存在近距离、高密度的特点,因此对相机的分辨率和焦距选择有一定要求。单目图像的拍摄选择分辨率为1600 像素×1200 像素的德国uEye SE 工业相机和焦距为4.16mm 的镜头,双目图像的拍摄使用国产Lena 相机,搭配3.6mm 的定焦镜头,左右图的分辨率设置为1280像素×720像素。
拍摄时间集中在2020 年12 月至2021 年2 月,此时温室中的番茄处于成熟期,可进行番茄的采摘、产量估测等工作。在整体天气情况为晴天时进行拍摄,不同于论文[17]中在夜晚使用白色发光二极管矩阵照亮拍摄区域,选择在白天进行番茄的拍摄,得到自然光照下的番茄图像,这更符合一般条件下采摘机器人等应用对图像的要求。为增加数据的多样性,拍摄过程中,相机的角度与水平面夹角在-45 度到45 度之间变换,离植株的距离控制在20cm 至40cm 之间,每行植株都有前光和背光两种拍摄情况。根据该温室中植株的间距,相机沿着植物行每隔20cm 的增量进行成像,以便在每个图像的视野中都包含一个新的植株。最后,对拍摄图像做进一步检查,剔除部分不符合要求的图像。包括由于相机曝光过度或不足导致的颜色过明、过暗图像,或相机移动导致的模糊图像,以及其他原因导致的不清晰图像。最终剔除约7%单目图像,约10%双目图像,筛选出750张单目图像、400张双目图像。
2.2 经验图像的处理
观察图片可以发现多张连续图像之间存在高相似性的特点,因此从单、双目图像中随机、分散地各选出具有代表性的100 张图片,使用开源的数据标注软件Labelme 对这些图像进行标注。图像的像素级标签由分层多边形组成,要求注释者从后向前标注图像,确保每个对象的边界没有被重复标注。由于番茄植株环境复杂,为了保证标注的质量水平同时加快标注的速度,每张图只进行部分标注。如图1(b)所示,即只关注图像中前两行距离较近的植株场景,其他较远的部分在采摘时可均视为背景。此外,基于以下两点考虑:(1)在采摘之前会对植株进行打老叶,此时番茄果实周围叶片稀少,且少量叶片遮挡不会阻碍机器人机械手运动;(2)番茄植株的叶片呈不规则形状出现导致标注困难。因此人工语义分割标签与合成标签相比,省去叶片这一类别的标注,标签类别一共为8 个,分别为背景、可采摘果实、不可采摘果实、花托、主干、侧枝与叶茎、细线、切口处,每个类别在标签图中由同一种颜色表示。标注过程中,除了给每张图像添加像素级别的分割标签,还为可采摘果实和不可采摘果实两个类别添加实例级标签。平均每张图片的标注耗时约为1h。
每个果实实例均为一个检测目标,使用Python代码,可以快速给每张图生成可采摘果实和不可采摘果实的目标检测标签。最终,由每张原始图像生成了包含图像语义分割、实例分割以及目标检测在内的三种计算机视觉任务标签。
2.3 合成数据的制作
合成数据的制作需借助Plantfactory 和Blender两个软件,图2 为制作番茄合成数据的方法流程图。首先,根据Plantfactory 软件制作需要,测量番茄植株各部位的几何参数和各部位之间的拓扑结构标量化参数(如表1 和表2 所示),将这些关键参数输入到Plantfactory 软件,经过调整构建出多棵番茄植株,导出为3D 模型文件;然后,在Blender 软件中导入上述番茄植株模型和使用Artec三维扫描仪扫描得到的番茄果实模型,使用番茄植株的彩色图像和叶片2D 扫描图像将模型纹理化。再模拟番茄种植温室,加入背景、地面、基质架、细线等物体,构建一个番茄植株群体环境。最后给植株群体添加光照属性、相机参数等,使用Blender的图像渲染功能,生成番茄的合成图像,以及对应的合成语义分割标签图。
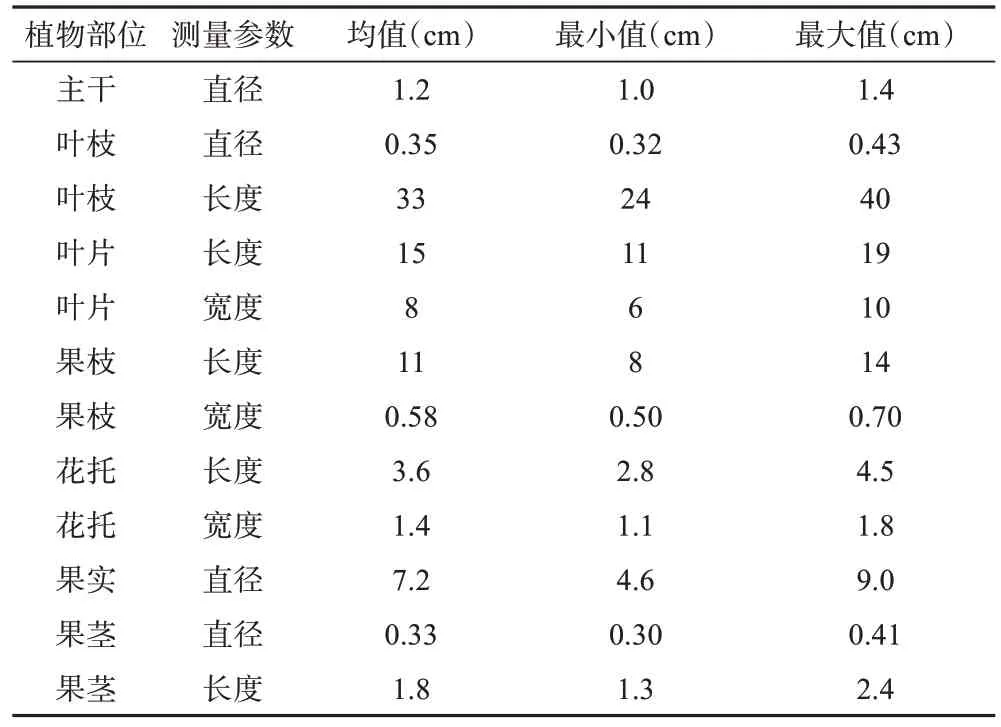
表1 番茄植株的各部位几何参数Table 1 Geometric parameters of each part of tomato plant

表2 番茄植株拓扑结构标量化参数Table 2 Scalar parameters of tomato plant topology
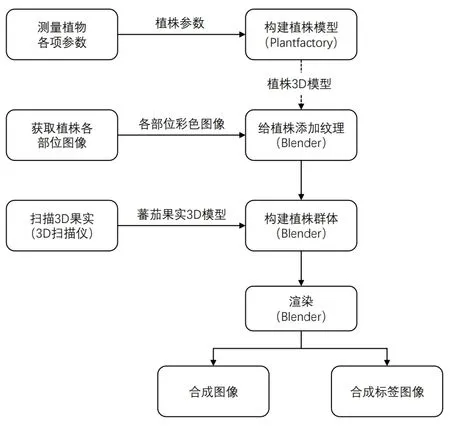
图2 合成数据制作流程图Fig.2 Flow chart of synthetic data production
3 数据样本描述
3.1 合成部分
合成部分的数据一共使用3 个文件夹进行保存,第一个文件夹中保存的是bmp 格式的RGB 合成图像;第二个文件夹中保存的是png 格式的RGB 合成标签图;第三个文件夹中保存的是对RGB 合成标签图进行处理后得到的单通道png 格式的灰度图,灰度图中的像素数值大小在0 到8 之间,每个数值对应一个类别,便于语义分割网络的使用。每个文件夹中的每张图像按照“该文件夹名_序号”的方式命名,合成图像和其对应的RGB 语义分割标签图示例如图3所示。

图3 合成图像与合成标签示例Fig.3 Example of synthetic image and synthetic ground-truth
3.2 经验部分
使用4 个一级文件夹分别保存经验部分的原始拍摄图像、目标检测标签、语义分割标签以及实例分割标签。保存原始图像的一级文件夹下包含两个二级文件夹,分别存储单目图像和双目图像。每张单目图像的命名规则为“拍摄日期_monocular_序号”;双目图像分为左图和右图,分别命名为“拍摄日期_binocular_Left_序号”和“拍摄日期_binocular_Right_序号”,使用两个文件夹进行保存。
保存三种标签的每个文件夹下也分为单目和双目两部分。每张原始图像对应的各类型标签存储格式如表3 所示,目标检测的标签为txt 格式的文档,语义分割的标签为png 格式的分割图,实例分割的标签为文件,每个文件中包含5 个描述同一个实例分割标签的文档与图片。每个标签均命名为其对应的原始图像名称,部分标签示例如图4所示。
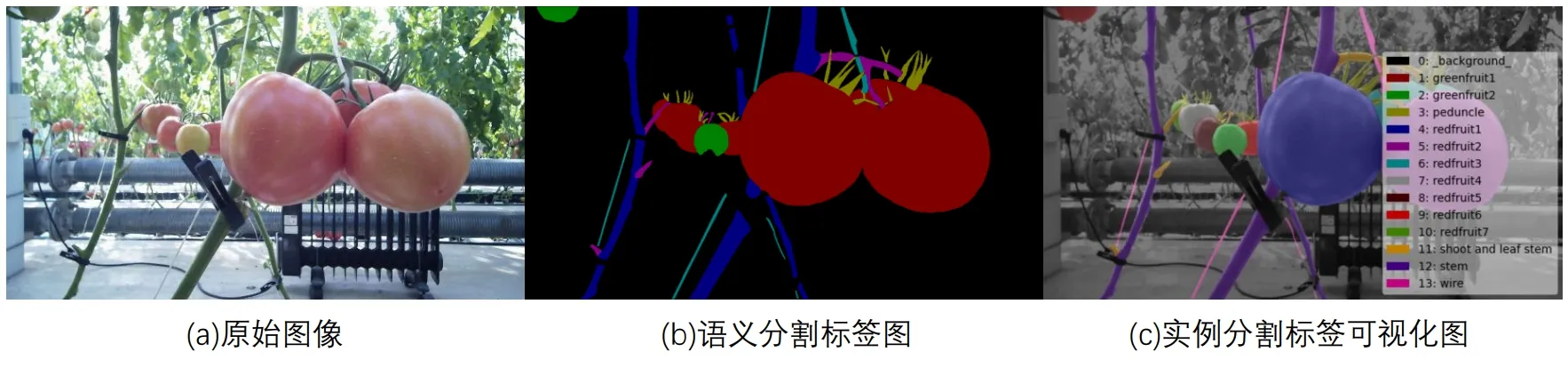
图4 部分经验图像标签示例图Fig.4 Images of partial labels
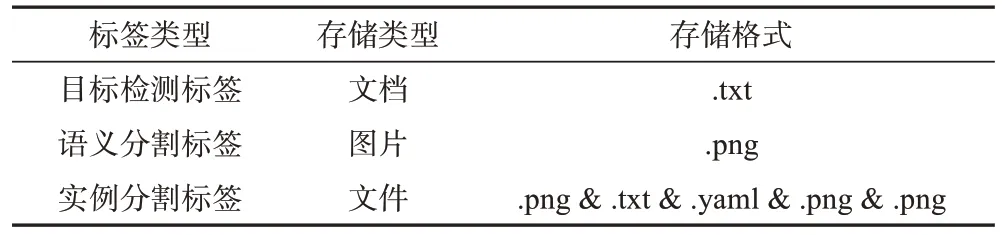
表3 三种类型标签的存储格式Table 3 Storage formats for three types of labels
4 数据质量控制与验证
前期合成部分的制作人员对Plantfactory 和Blender 两个软件进行自主学习,制作过程中尽可能保证对真实番茄植株环境的还原。经验图像由固定人员进行采集,减少人员差异导致的不一致性;对拍摄图像进行甄别与筛选,并由其他人员做进一步的检查,剔除约7%的单目图像,约10%的双目图像,保证数据的质量。根据统一的标注规范方案,对所有数据标注人员进行培训,督促其在标注过程中及时进行自查,全部数据标注完成后标注人员之间相互校对,对约10%的图像标注进行二次修改。所有的数据按照“名称+序号”的方式妥善保存并备份,以便将来对该数据集进行完善和补充。
使用两个深度学习网络验证该数据集的可用性,分别为yolo[18]目标检测网络以及基于ResNet101[19]的DeepLab[20]图像语义分割网络。对于目标检测任务,使用单目标注图像的前1~85 张进行训练,第86~100 张进行测试;对于语义分割任务,为证明该番茄数据集中合成部分对经验部分在深度学习网络训练中的指导性,对该部分实验做2个设置,具体如下:
设置1:不使用番茄数据集中的合成部分进行预训练,仅使用单目标注图像的前1~85张进行训练,第86~100张图像进行测试。
设置2:使用该番茄数据集合成部分第1~3000张图像进行预训练,单目标注图像的前1~85 张进行微调,第86~100张图像进行测试。
表4 为目标检测任务的测试结果,使用可采摘果实和不可采摘果实两个类别的精确度(Precision,P)、召回率(Recall,R)、IoU 值设置为0.5的平均精度(Average Precision,AP)以及平均AP 值作为评价指标。表5 为图像语义分割任务的测试结果,使用像素准确度(Pixiel Accuracy,acc)和所有类别的平均交并比(mean Intersection-over-Union,mIoU)作为评价指标。图5为这两个网络测试的视觉结果图。从表5中可以看到,设置2的测试结果和设置1的相比,acc和mIoU两个值均有不同程度的提升,尤其是mIoU 值增加了2.68%,可见合成数据对经验数据在网络训练中的指导作用,而这些表格和图片中的可观数值也有力证实了该数据集的有效性。

图5 数据验证视觉结果Fig.5 Visual Results of Data Validation

表4 目标检测实验测试结果Table 4 Test results of object detection

表5 图像语义分割实验测试结果Table 5 Test results of image semantic segmentation
5 数据价值与使用建议
该数据集的合成部分可用于农业场景下的图像语义分割任务预训练;经验部分的原图像是在真实番茄温室环境中采集的,包含多种类型的视觉解析任务标签,为番茄图像的物体检测、语义分割、实例分割等神经网络的实现与评价提供数据支持;此外,该数据集可为其他作物生长环境下的视觉解析任务提供预训练数据,大大减少标注的数量,节省人力与时间。
数据作者分工职责
周玲莉,分工:合成数据的制作、经验数据采集、数据汇总整理及论文撰写。
任妮,分工:组织实施及论文撰写。
张文翔,分工:合成数据的制作、数据采集、数据标注。
程雅雯,分工:合成数据的制作、数据标注。
陈诚,分工:数据质量控制。
易中懿,分工:总体方案设计与指导。
