云农场智慧服务大数据平台设计与实现
2021-02-13凌诺娟
凌诺娟 饶 元
(1.安徽农业大学信息与计算机学院,合肥 230036;2.智慧农业技术与装备安徽省重点实验室,合肥 230036)
1 引言
随着信息时代的快速发展,大数据成为推动社会发展的关键技术,对包括农业在内的各个领域的发展都起着非常重要的作用[1]。大数据技术往往集成先进的数据分析处理技术,及时统计、分析、处理及预测相关数据信息,获取相应的数据价值,以此满足目标业务需求。将农业与大数据技术相结合,能合理整合各种农业生产资源,为带动区域经济进步奠定基础[2]。由于信息化技术发展滞后,信息数据资源获取与整合不及时,大别山区特色农业产业的发展存在产业技术薄弱、农产品销售不畅等突出问题,制约了农产品市场竞争力的提升。为了解决大别山区产业发展所面临的问题,提高大别山区农产品产业竞争力,需要借助以大数据为代表的信息技术助力提高大别山区特色农产品产业的发展水平。
近年来,随着各国积极推进农业大数据工作的展开,学界对于大数据应用于农业领域的发展也作出了深刻的理论研究[3-6]。温孚江[7-8]认为大数据的应用为农业科研、生产决策、涉农企业发展等提供新思路,指出当前农业领域存在的食品安全、农产品价格、农业生产管理结构调整等问题,都可以应用大数据的思维来解决。孙九林[9-10]院士指出,农业大数据在生产领域能节本增效,在农业经营领域能激发市场活力,在农业管理领域能稳定消费者信心,在农业综合服务领域能服务三农的诸多方面。许世卫等[11]提出有数据分析和服务能力的增强,大数据逐渐成为农业生产的定位仪、农业市场的导航灯和农业管理的指挥棒。Carolan 等[12]在农场管理决策时利用大数据,通过对大数据行业人员的访谈表明,人们对于设计销售和推广大规模数据采集、预测分析软件和传统农业应用的精确度方面有着一定的期待,对于建立粮食系统的农业大数据平台有很高的期望。Coble 等[13]则指出了未来探测农业大数据来源的重要性。当前,我国已经建立了国家农业科学数据共享中心[14]、中国农业监测预警平台[15]、安徽省植保大数据平台[15]等多个农业大数据应用研究系统。由此可见,农业大数据的构建与积累对农业现代化发展具有重要的推进作用。
本文以Hadoop大数据生态体系为代表的分布式存储与计算平台为基础,实现云农场智慧服务大数据平台。对于海量多源异构的农产品全产业链数据,采用NoSQL数据库的无模式、高可扩展性的特点,存储由农业物联网设备采集的大量非结构化数据,如图像、监控视频等的实时写入,为平台的数据分析提供支持。以有效整合农产品全产业链数据资源为基础,搭建农业大数据平台,提供产业区农业数据信息共享、智能预警等智慧服务,从而促进大别山区现代信息化水平的提高。
2 平台设计
云农场智慧服务大数据平台的整体建设思路是按照育种、收获、存储、加工、流通和销售等多个农产品全产业链关键环节,分析大数据平台建设需求。依托于物联网、互联网、大数据等信息技术及平台建设需求,构建云农场智慧服务平台总体架构,完成对农产品全产业链数据的收集、处理、分析,建设全产业链数据资源库,高效整合涉农数据,促进农场与信息科技进一步结合,实现生产经营主体对农产品生产周期全要素、全过程信息化管理。
2.1 设计需求
农产品全产业链数据资源众多,但数据分散,价值密度较低,如何有效整合数据资源提高价值密度,并用于指导农产品生产经营,是研发本平台所面对的主要问题。本文通过分析全产业链关键环节数据资源,平台需要完成的主要功能包括:农产品全产业链数据资源存储归集、大数据ETL 处理、数据挖掘分析、数据可视化、数据决策服务等功能。总体功能需求如表1所示。

表1 平台功能需求Table 1 Platform functional requirements
2.2 数据资源建设
农业数据作为重要战略性资源,在推动农业科技创新等方面发挥重要作用[16]。数据资源体系建设是支撑大数据平台建设的基础工程[17]。在特色农产品全产业链背景下可获得的数据类型众多,具有与大数据同样来源广泛、类型复杂、体量大的特点。针对农业大数据的数据特征,根据功能需求促使数据标准化,结合平台面向的业务主题,应用数据变化的分层思想[18],形成原始数据资源库,格式化数据资源库,应用数据资源库的数据层级框架,基于分布式大数据计算框架实现多源异构数据的标准化治理,提升数据可用性水平。
2.2.1 原始数据资源库
数据资源是实现云农场智慧服务大数据平台的基础,对数据进行的任何处理都会带来信息的丢失,即便是脏数据、空数据、冲突数据,也都表征了数据产生时刻的数据情况。因此,保留未经任何处理的原始数据有助于掌握数据产生时刻的情况,为后续相同问题的解决提供帮助。
在农业大数据技术背景下,基于在产区农场内部署的监控摄像头、智能传感器等物联网设备以及4G/5G、LoRa 网络,汇聚的多源异构农业数据资源存储按照数据结构划分为结构化数据和非结构化数据,分类存储到大数据平台中作为平台的原始数据资源库,由Hadoop 组件之一HDFS 文件系统作为原始数据资源库的存储区域。大别山区农业数据主题分类大致可规划为“天”“地”“人”“网”四类。如表2所示,“天”数据主题主要是通过与气象、遥感等信息网站接口连接获取大别山区农场所在区域气象、遥感图像等数据信息,从而获得农场产业区的气象环境、种植面积数据;“地”数据主题是通过布设于田间的物联网设备采集农产品生产环境信息,包括土壤温湿度、光照强度等数据;“人”数据主题是通过生产经营者采集收录农产品从培育、种植、收获、加工到销售流通等关键环节数据,归集农产品全产业链各环节生产经营数据信息;最后通过“网”数据主题,获取网络端图像、文本等农产品历史数据。由这些数据构成平台建设基础原始数据资源库,为实现云农场智慧服务提供数据支撑。

表2 数据主题描述Table 2 Data subject description
2.2.2 格式化数据资源库
格式化数据资源库是原始资源库中储存的数据经过数据清洗、分类组织、规范化后的标准数据。农产品全产业链各环节数据存在不同的来源途径,如环节数据可能是工作人员通过信息采集系统手工录入,生长环境数据则是由智能传感器实时记录数据所采集,不同来源的数据可能产生重复、格式不一等错误,在格式化库中,不同来源但同一主题数据是经过清洗、融合与标准化的操作,从而形成具有统一的、规范的结构的格式化数据。
格式化库中的数据根据业务需求和数据所属主题将数据根据企业为主要划分规则,将数据资源划分农产品全产业链各环节数据宽表、视频监控数据宽表和农产品生长环境数据宽表等符合业务需求的数据。
农产品全产业链数据宽表:用于描述企业旗下农产品生产、加工及流通仓储等关键环节数据,用于记录农产品从生产到销售流通的产业链详细数据信息。
视频监控图片数据宽表:农产品生产过程中的非结构化信息,记录田间种植地等视频监控、图片数据存储路径,描述农产品真实生长过程详细信息。
农产品生长环境数据宽表:农产品生长过程的环境数据,由架设于田间的传感器传输的数据,实时记录农作物生长过程的土壤温度等环境数据信息。
构建格式化数据资源库,目的是将企业旗下农产品数据经过处理形成规范的可用性较高的数据记录。
2.2.3 应用数据资源库
应用数据资源库是在格式化数据资源库的基础上,根据业务需求从格式化数据资源库中抽取数据,并按照维度建模进行统计、分析和汇总,从而形成具有指导意义的应用数据。各类业务数据资源的分析汇总为应用库是为了实现以企业为划分单位,由相关工作人员通过应用数据资源库数据的可视化界面充分掌握该企业的生产经营信息,从而为企业经营决策者更好的经营农产品提供科学的辅助决策服务。
应用库的指标根据场景应用需求可划分为业务明细表、业务统计表及业务指标表。
业务明细表:经过系统的分析聚合,生成企业农产品生产经营各环节数据主题业务明细表,其中包括同一企业农产品生产种植、流通方向、销售区域与价格等明细信息。
业务统计表:存储业务统计数据,在不同维度的情况下统计产业数据,包括农产品生产量、销售量以及企业收入情况等各类统计信息。
业务指标表:存储农产品经营方向预测、预警等指标数据,是考虑多方面因素进行的数据分析,提供面向生产需求、生长监测需求及销售需求等指标。
2.3 总体架构设计
本平台基于Hadoop 大数据技术进行研发,实现数据采集、存储、计算分析以及前端显示等需求。总体架构如图1 所示,包括四个逻辑层次,自下而上分别是基础设施层、数据资源层、数据处理分析层、数据显示层。
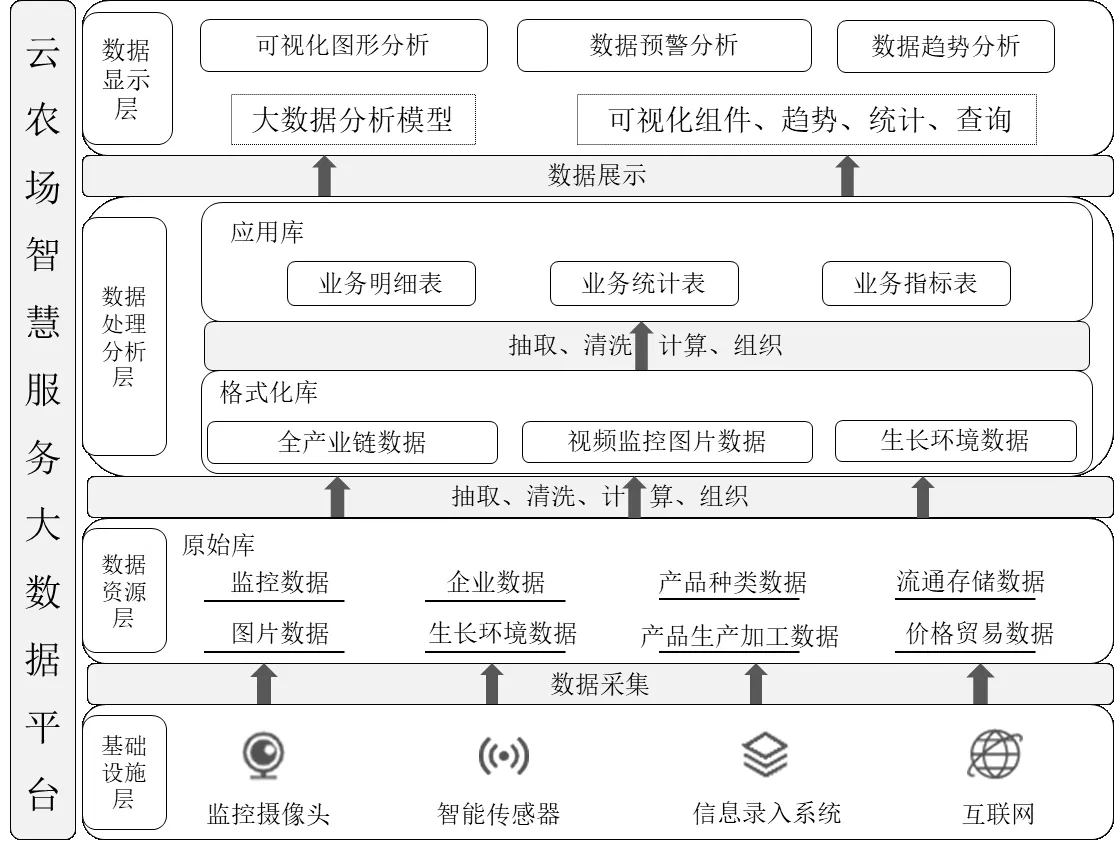
图1 平台整体架构Fig.1 Overall architecture of the platform
2.3.1 基础设施层
借助大别山区农产品产业链关键环节数据信息录入存储系统,以及部署于农产品产业区中的各种物联网设备,包括监控摄像头、生长环境智能传感器等,作为数据采集工具,连接互联网进行农产品数据的实时传输,存储于数据资源层即进入Hadoop 大数据体系。
2.3.2 数据资源层
数据资源层用于与产区内监测点各传输设备的数据源建立技术连接,新建多种数据主题文件,用于存储不同数据来源的农产品生产经营数据。未经任何处理的农业数据构建生成原始数据资源库,为平台提供服务的功能研发提供基础数据资源。
2.3.3 数据处理分析层
数据处理分析层的作用是对数据资源层的数据进行处理分析和对数据显示层的访问提供服务。根据建设平台功能需求,利用大数据计算技术对原始数据资源库数据进行抽取、清洗、分类、聚合,组织生成条理清晰、价值密度高的格式化数据资源库。面向云农场智慧服务大数据平台中的各种业务需求,从格式化数据资源库中进一步抽取数据,建立业务大数据技术分析模型,生成对生产经营具有一定指导意义的应用数据资源库,并提供统一的数据访问接口,为上层数据可视化提供服务。
2.3.4 数据显示层
数据显示层的作用是对产区数据资源的集中展示。利用数据可视化技术,搭建大数据平台各类子系统平台页面,以多样的方式展示应用数据资源库中数据,将产业区农产品关键环节动态变化情况以更加直观地方式呈现给农业相关从业者。
3 关键技术设计
数据资源从采集到的原始数据到具有一定指导意义的应用数据资源需要经过多重技术处理,目的是从海量数据资源中抽取业务数据作为标准应用数据。本平台在建设过程中以业务需求出发,经过大数据相关技术整合业务数据,形成标准数据以支撑平台提供的业务功能。下面重点从业务数据如何存储、处理到服务于生产经营的流程来阐述实现本平台的关键技术。
3.1 数据存储流程
Hadoop 大数据体系以HDFS 文件系统作为高可靠的底层存储系统,为HBase 数据库及Hive 数据仓库提供存储支撑。农产品全产业链数据主要包括图片、视频及结构化数据三种类型,在存储时需要对数据类型进行判断。存储流程如图2 所示,本平台使用Sqoop、Kafka 等数据组件采集农产品全产业链原始数据至分布式文件系统HDFS 中存储,按照平台业务需求和业务数据类型对数据进行整理、清洗,存储业务计算所需主题数据于HBase数据库。
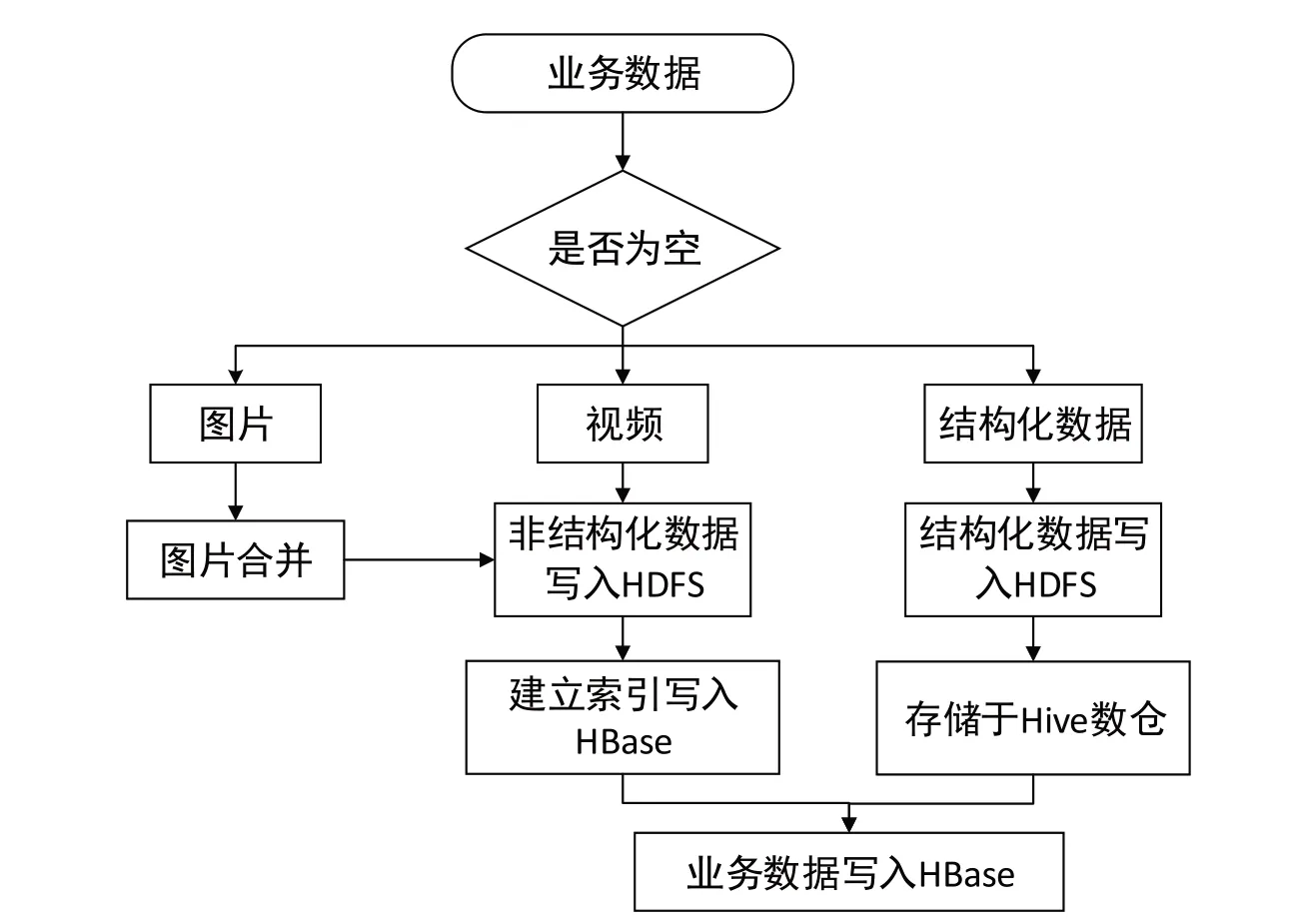
图2 数据存储流程图Fig.2 Data storage flow chart
3.2 业务数据处理流程
面向大别山区农产品全产业链数据资源的收集过程,主要获取的是包括农产品培育、收获、仓储、加工、销售等关键环节中产生的数据。上述数据因为设备失温、传输中断、网络环境不稳定等原因会产生空数据、脏数据等结构或内容出现异常的数据,需要经过一定的数据降噪聚合等操作处理成规则的结构化数据来响应业务需求。数据处理流程如图3 所示,基于Spark 计算引擎提供的SparkRDD、SparkSQL 等技术组件实现数据处理,提高业务处理能力和数据处理响应速度。
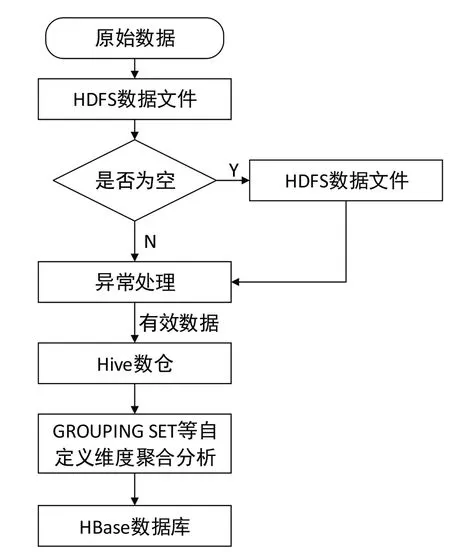
图3 数据处理流程图Fig.3 Processing flow chart
在读取HDFS 中存储的原始数据,若判断为空,则设置此条数据为空的部分为NULL,目的在于还原数据结构完整性。并利用Spark 计算引擎提供的Filter 等算子对原始数据进行处理清除这类异常数据。SparkSQL 整合Hive 数据仓库,将结构内容完整的数据存储数据于Hive 数据仓库进行聚合分析,最终已分析汇总好的数据存储于HBase数据库。
3.3 数据服务
平台针对业务需求,集成了很多基础软件和应用软件,形成一个完整的解决方案。本平台采用前后端分离式架构开发,前端采用ElementUI 与Vue 实现前端页面开发,基于Axios 实现前后端数据交互,后端采用稳定性强的SpringMVC 架构,通过Java 语言完成服务器的应用程序开发,此部分主要是完成农产品全产业链数据的采集录入,作为此后数据分析操作的数据来源的基础。对于所要实现的数据信息共享服务,采用前后端分离形式,基于前端Jquery 框架技术及后端SpringBoot 开发框架,支持数据统计、综合查询及数据的导出服务,实现农产品信息共享服务。利用Echarts 图标库做数据可视化,实现经过处理分析后的数据以多样的图形方式表明农产品生产经营趋势走向,促进生产经营主体掌握农产品产业情况变化水平。
4 平台实现及效果
云农场智慧服务大数据平台实现了大别山区农业数据资源的整合归集、海量数据的有效管理、数据可视化分析等功能。平台整合产区大量涉农数据,形成农业大数据信息资源库,以有效整合产区涉农数据为目标,服务于农产品生产经营,实现海量多源异构数据的有序存储,实时处理与更新。平台根据具体的业务需求,对大别山区农业大数据进行采集、分析、归纳,实现以图形方式可视化数据信息,提供农业从业者及时获取农产品上下游供销链信息,有效应对实体农场的变化,从而辅助生产决策等智慧服务。
4.1 农产品全产业链信息归集
农业大数据的建立是通过录入系统归集产业区涉农数据,数据作为整个平台业务的承载中心,覆盖大别山区农产品生产、加工、销售、价格等农产品全产业链数据。如图4 所示,本系统实现企业用户登录系统功能服务,通过新增服务记录该企业生产经营对应企业数据、农产品生产种类、生产信息、加工、销售、贸易流通、仓库存储以及农产品价格消费等全产业链关键环节数据,完成对大别山区企业管理、农产品生产管理、产品加工、销售流通及市场价格消费等涉农原始数据的归集整合,为平台建立数据资源基础。
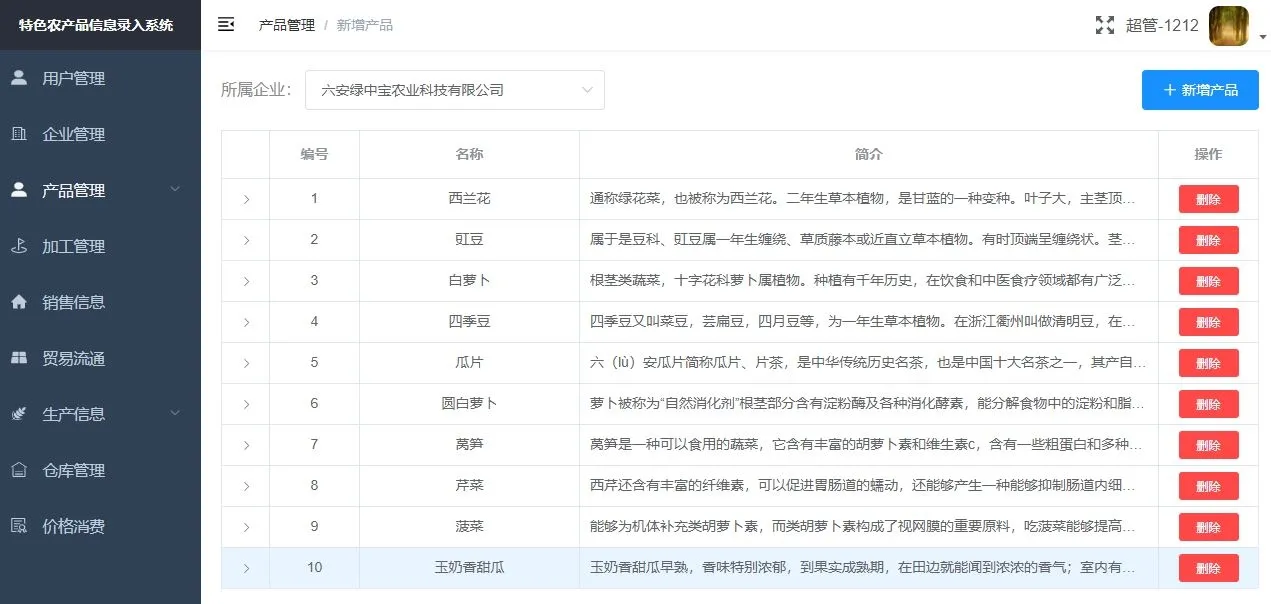
图4 信息录入系统图Fig.4 Information input system
4.2 全产业链数据集成共享
整合大别山区产业涉农数据,有效提升数据的关联性,提供数据导出共享服务,避免信息孤岛、解决数据分散,实现大别山区涉农数据与信息录入系统对接、统计、交换共享、整合挖掘数据资源内部价值。如图5 所示,本系统在数据录入系统对数据的归集整合的基础上,进一步集成企业信息、农产品信息,统计分析农产品生产、销售、流通情况、价格趋势,收集企业设备情况等数据信息,促使大别山区涉农数据信息密集化,提供数据导出功能,实现大别山区企业生产经营信息交流共享服务,有助于生产者掌握产区农业行情信息变化,提高产业竞争活力。
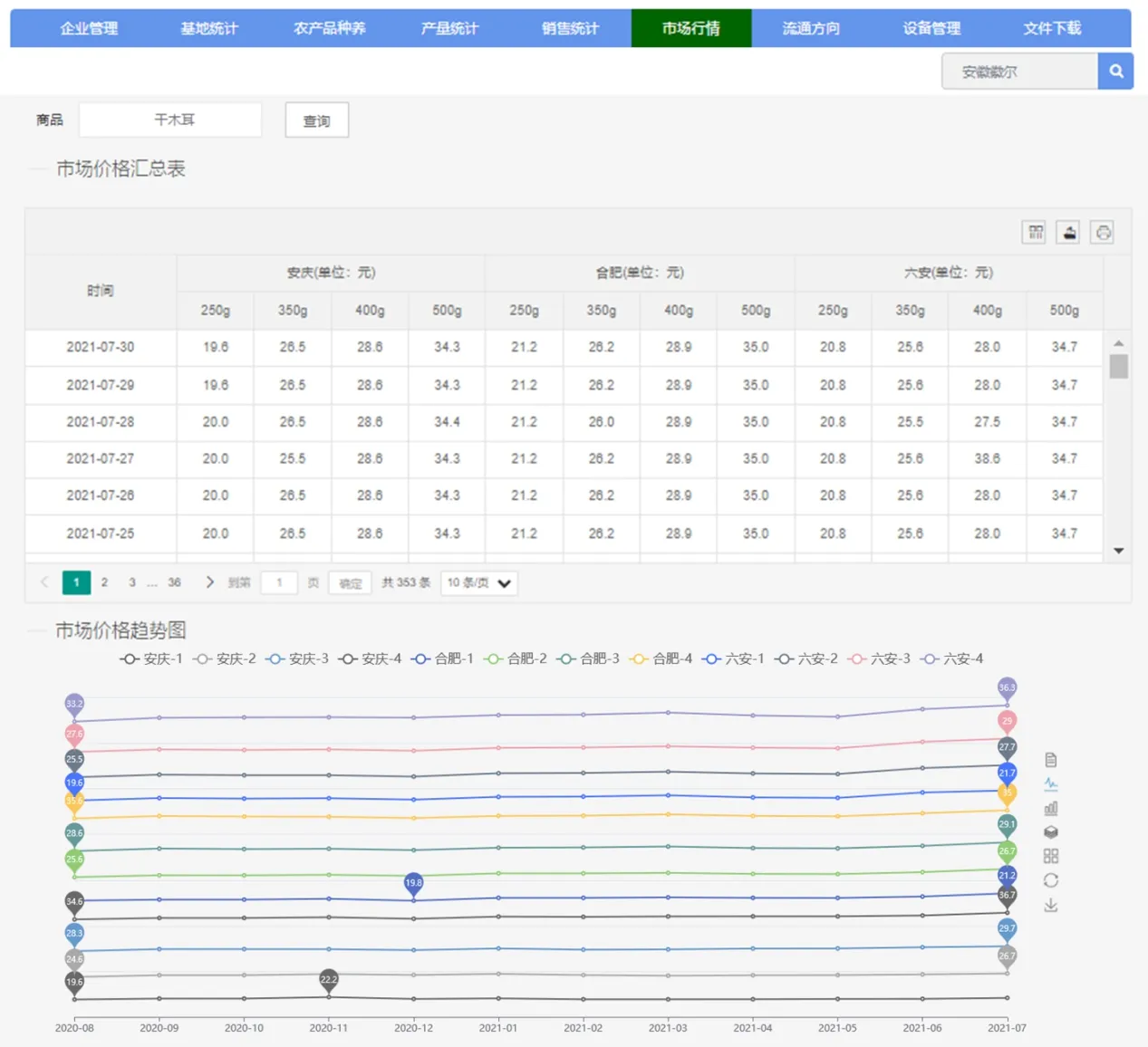
图5 数据集成共享图Fig.5 Data integration and sharing
4.3 全产业链数据可视化
平台通过对涉农数据的汇总分析,包括清洗、分类、多表联查、聚合等操作,借助ECharts 技术所提供的多类型图形的方式,打造云农场智慧服务可视化平台,构建了产业区大数据一张图,形成了用图形展示农业信息的新业态,如图6 所示。以可视化方式实时展示产业区农场内农产品生产环境数据,农产品产量销售等动态变化情况,为相关农业从业者提供农产品生产环境预警、掌握物联网设备状态、企业生产农产品主题辅助决策等智慧服务,通过以现代化信息技术为支撑的有效方式管理实体农场,及时应对实体农场发生的变化。
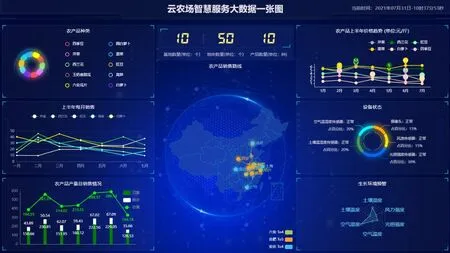
图6 云农场智慧服务大数据一张图Fig.6 Visual big data of Cloud Farm Smart Service
5 总结与展望
为了有效处理分析大别山区特色农产品全产业链数据,促进大别山区现代农业的发展,本文提出了一种基于Hadoop生态体系的云农场智慧服务农业大数据平台设计,实现农产品全产业链数据的多元化整合,解决数据分散问题,满足生产经营主体多个业务领域的数据管理分析功能需要,为产区经营主体提供农场农业数据可视化分析,提供信息共享、智能预警等智慧服务,有助于提升大别山区特色农产品全产业链生产经营和管理智能化水平。
在农业领域运用大数据技术搭建农业大数据平台,有助于促进农业信息化的发展水平。下一步将继续开展农产品全产业链数据分析,深度挖掘数据资源的价值,寻找农产品销售市场的动态变化规律,从而更好地发挥大数据在推动数字农业发展的作用,为农业农村现代化发展提供支撑。
