云计算平台下大数据处理效率分析及优化
2021-02-10欧卫红杨永琴李家华
欧卫红 杨永琴 李家华
(广州科技职业技术大学,广东 广州 510550)
1 云计算技术与大数据技术现状分析
近年来,信息技术的发展日新月异,人们的一举一动都在被数字化,人们逐渐从信息匮乏的时代走入了信息充裕的时代。信息的社会地位也在不断上升,现已成为人们生产、生活中不可缺少的重要资源。可以毫不夸张地说“谁掌握了信息技术的话语权,谁就掌握了未来”。而数据作为信息的主要来源和原始材料,迅速成为信息技术科学中的一个热点,数据也成为一种新的自然资源[1]。在大千世界中各种活动产生着大量的数据,我们称之为大数据。[2,3]据统计每年产生的数据量正在逐年增长,而且根据数据显示该增长趋势依旧处于加速状态,预估近几年数据量的增长速度将超过50%。[4]大数据其表现形式各样,结构复杂,但蕴含了各种丰富的信息,且具有广泛的应用潜质。当今世界国际一体化加快形成,“互联网+”快速推进,各种技术不断成熟,因而又促进了信息处理技术快速发展。信息论告诉我们数据中包含了知识、客观存在的规律等异常珍贵的财富和资源。计算机科学技术的快速发展为信息处理提供了一个理想的工作平台,并逐步形成了分布式处理、知识识别及表达、数据挖掘、边界处理等新的学科领域。
现阶段各研究机构和相关企业都在转变模式,利用大数据分析处理来解决自身关注的问题及提升业务的处理能力。例如:在医学应用方面,利用新的信息技术获取大量数据(图形、图像、文字、行为过程等),来研究疾病的发病机理及治疗的方法;在图像处理方面,利用新的信息技术获取大量数据,实现人脸识别技术。在企业中,人们利用各种渠道获取用户的大量数据,利用大数据挖掘出用户的爱好、需求趋势、行为习惯等,从而调整自身的生产、销售、库存等以实现更大的效益。在国内,近年来大数据技术在各方的合力下发展非常迅速。2016年,国家工信部发布了《大数据产业发展规划(2016-2020年)》。2017年12月,中共中央政治局就实施国家大数据战略进行第二次集体学习,习近平主席发表重要讲话。“十九大”的政府工作报告中明确提出云计算、大数据成为“十四五”重点发展的技术领域。
大数据的高效处理需要强有力的基础计算力,目前有两种方式来提高计算力,一种是利用超级计算机处理大数据,这种方式投入大,一般应用于科学研究的数据处理;另一种是利用云计算平台来处理大数据,云计算具有超大规模、处理速度快、虚拟化、高可靠性、通用性、高可扩展性、性价比高等特点,它为大数据高效处理提供了一个理想的解决方案。
云计算技术[5,6]就是分布式计算的一种具体实现,它是分布式计算、网格计算、负载均衡、并行计算、网络存储、热备份冗杂和虚拟化等技术混合演进并跃升的结果。云计算技术的出现给大数据高效处理提供了一个理想的解决方案。云计算它提供一种“按需分配”的可扩展的计算服务,提供强大的存储能力和计算能力。[7]目前云计算技术得到了快速发展,2019年,以IaaS、PaaS和SaaS为代表的全球云计算市场规模达到1883亿美元,增速20.86%,预计未来几年将以每年20%左右的增长率快速增长[8]。各种迹象表明云计算的研究与开发在未来的若干年还将持续升温,引领着计算机技术飞速发展。[9]这反映出人们从传统的IT服务向云端服务的转变,逐渐将业务趋向于数字化战略,云计算理所当然成为承载大数据处理的首选基础平台。
2 云平台下大数据处理效率分析
如何更有效地在云平台下实现高效处理大数据,可从以下几个方面进行分析:
2.1 任务和虚拟机的调度问题
实现高效的并行计算的关键点就是任务和虚拟机的调度问题,好的调度算法可大幅度提高资源利用率和处理数据的效率。云平台在提供服务时,其物理节点的资源消耗是动态调整的,调度时不能保证每次新的任务都能及时部署到最优剩余资源量的节点上。在实际的应用过程中,用户每次新的任务都是随机地部署到一个物理节点上,如果提交的任务资源需求量比选取的物理节点的可用资源数更大,就会发生任务部署失败的事件,影响处理效率。另一种情况,如果提交的任务资源需求量刚好与选取的物理节点的可用资源数相近,虽然能正常部署,但是其物理节点的负荷太高,其处理效率也不会高。我们改变一下任务的部署策略,每次都将任务部署到最空闲的物理节点上,这样是可以得到最好的执行效率,但大多数物理节点的利用率就会非常低,造成了大量的资源浪费。因此,不同的任务部署方式和不同的系统负载分布情况,直接决定云平台的处理效率和服务能力。因此,大数据要在云平台上进行高效处理,云平台需要有相匹配的最佳虚拟机及任务部署方法,提高平台的负载均衡能力,提高云计算平台处理大数据的效率。图1给出了任务在IAAS云平台的部署过程。

图1 任务在IAAS云平台的部署
综上所述,如何合理地进行任务和虚拟机的调度以实现整个云平台的负载均衡是影响云平台下大数据处理效率的第一个主要因素。
2.2 云平台下的大数据存储问题
数据存储技术一直对数据处理效率影响较大,选择不同的数据存储方式其数据处理效率有非常大的差异。如今,主要的网络存储解决方案有以下三种[10]:直连存储DAS(Direct Attached Storage),联网存储NAS(Network Attached Storage),存储区域网络SAN(Storage Area Network)。目前,在实际应用中使用比较多的是SAN,存储区域网络SAN[11]是独立于服务器网络系统之外的高速存储网络,网络上的应用服务器可以共享所有的存储设备,它一般采用FC(Fiber Channel,光通道)和SCSI(Small Computer System Interface,小型计算机系统接口)作为存储访问协议,并通过专用的交换机等设备组成高速可靠的网络,使存储子系统网络化,实现真正高速共享存储的目标[12]。图2是三种网络存储结构图。

图2 三种网络存储结构图
在云平台下一般资源都是分布式的,数据的存放也是分布式的。如何整合存储在网络上分布式的不同类型的数据,提高其存储空间利用率,并提供简单、高效、智能的管理方式,降低运行成本是当前云平台下存储技术要急需解决的问题。
虚拟存储技术的出现为云平台提供了一个最佳的存储解决方案。虚拟存储技术将所有的存储资源在逻辑上映射为一个整体,屏蔽了单个存储设备的容量、速度等物理特性,向用户呈现单一透明的存储视图。[13,14]虚拟存储(Storage Virtualization)是逻辑存储,它管理存储数据的方式比较智能化。[15]其结构如图3所示。
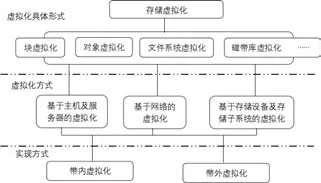
图3 虚拟存储结构及分类
从存储虚拟化的实现原理来看,存储虚拟化又分为带内和带外两种。[16]其虚拟化方式可分为三类:基于主机及服务器的虚拟化、基于网络的虚拟化、基于存储设备及存储子系统的虚拟化。[17,18]他们各有优缺点:基于主机及服务器的虚拟化具有较高的稳定性,但不便于扩展,受限于主机自身的资源,也会导致主机性能下降。基于存储设备及存储子系统的虚拟化具有独立性,节省主机的资源,扩展性也不错,但存在兼容性问题,不同厂商的设备可能无法互联互通。基于网络的虚拟化存储系统,从形式上是分布式的,是把网络上的存储设备或存储系统进行整合并抽象成统一的存储池,可以为用户提供按需分配的服务,它具有以下优点:结构上简化了存储架构、实行集中存储管理;存储资源是按需分配的、并且可以动态调整,实现跨存储平台分级存储,业务处理不受物理存储设备的变化影响,同时解决了不同厂商的设备的兼容性问题,也有效降低了存储成本。
因此,在云平台上处理大数据时,选择什么样的存储结构是提高大数据处理效率的又一个主要因素。当然,影响在云平台上处理大数据的处理效率的因素还很多,本文只是抛砖引玉,现在已经有更多的学者去分析解决相关问题。
3 如何更好地提升云平台下大数据处理效率
如何提升云平台下大数据处理效率,本文提出了一种启迪式的感应负载均衡方法来优化任务和虚拟机的调度,从而提高云平台处理大数据的效率。
负载均衡的调度算法一般被分成两类:动态负载均衡算法和静态负载均衡算法。[19]经典的静态负载均衡调度算法有:轮询调度(RR算法)算法、权重轮询均衡(WRR算法)算法、最小连接数法(LC算法)算法、加权最小连接调度算法(WLC算法)等等。静态负载均衡算法相对简单,它主要是根据系统中一些静态信息进行任务调度和分配,实现起来也比较容易,但它不能实时动态反映云平台中各种资源的变化情况,而且当规模迅速扩大后存储这些静态信息的量也快速增长,其调度效率快速下降,使用静态负载均衡算法就更显得力不从心。因此,它不能很好满足云平台高效处理大数据的需求。
大数据处理的问题一般是规模比较大的,问题的复杂度也是比较高的,当我们处理问题的规模扩大后解决问题的时间复杂度就会快速增长,处理大数据的平台的复杂度也会快速增长。人们在分析处理这类规模大复杂度高的问题时一般会采用P类问题和NP类问题来抽象。动态负载均衡调度算法[20]就是最典型的NP完全组合及优化问题,在一大批解决问题的方法中求最优值。在实际的生产和生活中,一般会借助于组合数学、拟阵和广义拟阵以及图论等理论,用直观算法、近似算法来解决组合最优化的问题。基于这些理论,提出了一大批实用高效的算法;如VMware就采用了分布式的资源调度算法(DRS算法),[21]DRS对资源的分配方式有两种:第一种是将虚拟机迁移到另外一台具有更多合适资源的服务器上,第二种是将该服务器上其他的虚拟机迁移出去,从而为该虚拟机腾出更多的“空间”。DRS减少了虚拟机停机时间,保持业务的持续性和稳定性,提高了处理效率,减少了需要运行服务器的数量以及动态地切断当前不需要使用的服务器的电源,提高了能源的利用率。文献[22]中提出了基于网络感知的虚拟机放置方法,这个方法提高了云计算平台环境下虚拟机资源利用率以及数据密集型程序的运行效率,使其数据访问时间最小,并且当该虚拟机的数据访问时间不能满足要求时,运用概率统计知识,将它迁移到其它物理服务器上。文献[23]提出了基于虚拟机网络亲和度的动态调度策略,它主要是通过监控成对虚拟机间的网络亲和度,再结合分布式交换算法来动态地调整虚拟机的迁移和放置,使通信的开销最小化,从而实现负载均衡,提高处理效率。还有基于静态和动态相结合的调度策略,基于改进遗传算法和帕累托最优化理论的启发式自适应多目标优化算法[24],都从不同角度很好地解决了目前任务和虚拟机调度的效率问题。结合上述的分析,本文提出一种基于长期的工作过程的云计算平台下启迪式的感应负载均衡方法E-LBI(Enlightening Load Balancing Method of Induction)来优化在云计算平台下处理大数据的效率。
E-LBI是从云平台的长期运行维护的角度出发的,其主要的思想是将聚类思想与贝叶斯理论相结合,认为当集群中的所有物理主机的剩余负载率趋于相近时能反映出云平台的负载均衡情况,利用聚类思想将主机动态分成剩余负载率低、中、高等集合。其任务部署问题可以形式化如下:有m个任务在Δt时间内到达云平台,需要把它们分配到由n台物理服务器组成的云平台上运行着的虚拟机上。我们用一个m维解向量P(p1,p2,……,pm)来表示一个任务部署的解决方案,pi代表将要执行某个任务请求i的目的物理服务器。通过向量P来确定某个任务将会被部署到哪个物理服务器中。E-LBI方法就是利用它的算法机制以解向量P的形式解出最终部署策略。我们从六个方面来描述它,用一个六元组γ={SV,TC,Rc,Rm,Dc,Dm}来描述要求解的问题,其中SV表示n个可用物理主机的集合,SV(n,t)={sv1,sv2,...,svm},t表示任务部署的初始时间。TC(m,Δt,t)={tc1,tc2,...,tcm}表示在一个Δt时间内所有的请求集合。Rc表示SV中各物理服务器的CPU所剩余的资源量,Rc(n,t)={Rc1,Rc2,...,Rcn}。Rm表示SV中各物理服务器的可用内存资源量,Rm(m,t)={Rm1,Rm2,...,Rmm}。Dc表示TC中m个任务请求的CPU计算资源需求量,Dc(m,t)={Dc1,Dc2,...,Dcn}。Dm(m,t)={Dm1,Dm2,...,Dmm}是TC中m个任务请求的内存资源需求量。
第i物理服务器的剩余资源量Ri可以定义如下:

α表示计算资源CPU的权重,β表示存储资源内存的权重。
任务集合的性能约束值可以被定义为TC中最大的资源请求量,其公式表达为:

第i个任务的请求资源量可定义如下:

E-LBI方法通过计算所有主机的剩余负载率的标准差来评价负载均衡程度,其期望和标准差表示如下:
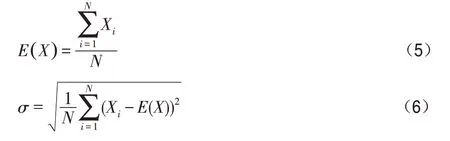
第i个物理服务器的剩余负载率公式如下:

Ti表示第i个物理服务器的资源总量,其公式表达为:
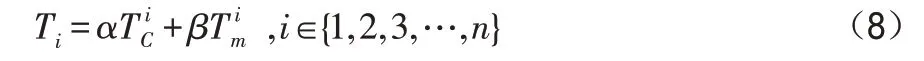
代表第i个物理服务器的总CPU资源,代表第i个物理服务器的总内存资源。E-LBI方法认为每个主机的剩余负载率Ei尽可能相近的情形可以反映一个云计算平台的负载均衡程度,通过上面的公式,优化目标可以得到以下公式:
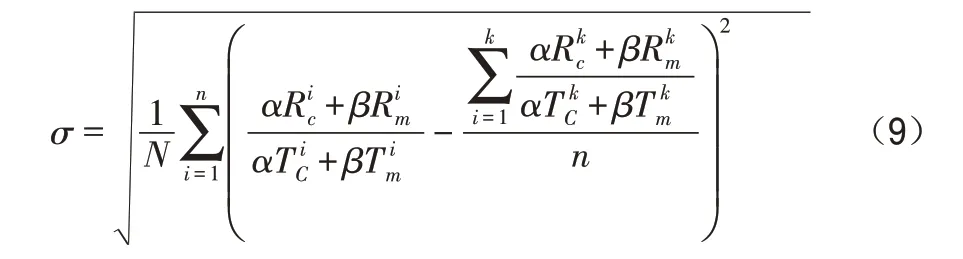
E-LBI方法不是直接应用公式(9)去优化目标,而是从云平台长期运营的角度来设计一个框架和过程式的方法集,从而实现更好的负载均衡效果。在E-LBI中,将剩余资源量比约束值大的物理服务器组成一个具有nˊ个物理服务器的新集合NSV,该集合中的物理服务器成为任务分配的最优候选集,再利用聚类的思想把物理服务器之间的相似度与给定的阈值进行比较从NSV集合中找出最优类簇组成最后的物理服务器最优候选集。
相似度函数定义如下:

和表示物理服务器i和物理服务器j的第k个属性。
物理服务器i的后验概率P(Bi|A)公式如下:
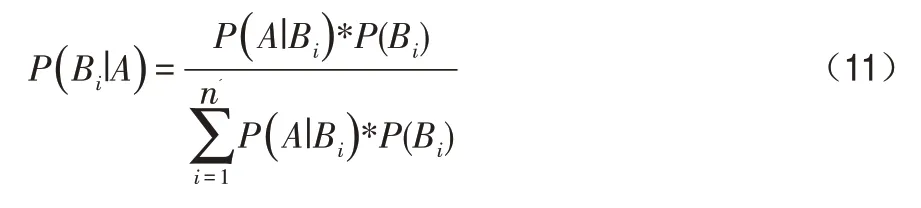
采用E-LBI进行虚拟机和任务部署时有如下几个步骤:第一步,通过动态监测选出剩余资源比当前提交的任务的最大资源需求更大的一批主机构成一个候选集群。第二步,先确定集合中每一台物理主机的先验概率,再通过贝叶斯理论计算出每一台物理主机后验概率,最后找出具有最大后验概率的主机,同时结合物理主机的计算资源和内存资源量,利用这三个值来计算其它所有主机与最大后验概率主机的相似度。第三步,确定相似度阈值,把相似度值在阈值内的主机构成一个最优物理主机集合。第四步,部署任务到最优物理主机集合中的物理主机上来执行。图4描述了E-LBI任务部署过程。
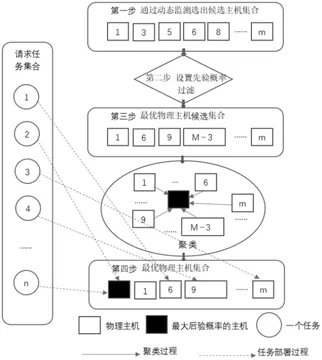
图4 E-LBI任务部署过程
我们采用CloudSim模拟器[25]对E-LBI启迪式的感应负载均衡方法、DLB动态负载均衡方法、RD随机部署方法进行验证和评估,分别从最大完成时间、衡量负载均衡效果的标准差值、任务部署事件的失败次数进行比较。在CloudSim模拟器中创建一个模拟云平台,该平台由100台物理服务器组成。模拟有30批任务同时请求,而且每批任务又有50个不同资源需求的子任务连续到达平台。
在实验中E-LBI、DLB、RD的最大完成时间的对比图如图5所示:RD方法是随机地将任务部署到主机上的,随着任务数量增加系统的性能下降比较快,因此任务的执行时间增长也较快。DLB方法是基于历史数据与经验再加上知识库来预测将要到来的任务需求,通过计算系统负载均衡的收益值来进行任务部署,随着任务数量增加各物理服务器之间的通信开销快速增加,从而降低物理服务器处理性能,因此任务的执行时间也随之增加,但比RD方法要小。E-LBI方法经过多次迭代会选择最优物理服务器集合来部署和处理任务,减少了大量的通信开销,物理服务器的性能得到最大程度的发挥,处理时间也会随着任务数量增加而加大,但在相同条件下,E-LBI的处理时间更小。
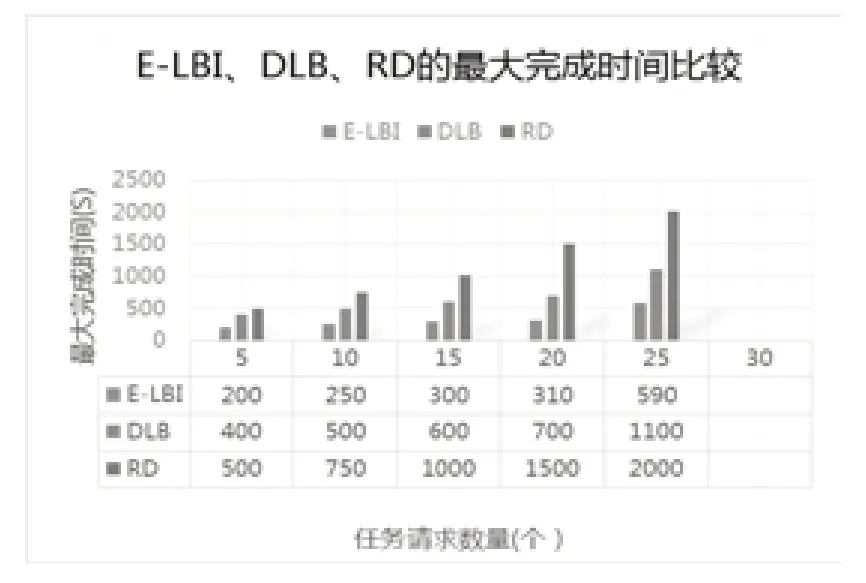
图5 E-LBI、DLB、RD的最大完成时间比较
在实验中E-LBI、DLB、RD的负载均衡效果的标准差值对比图如图6所示:RD方法的标准差一直是最大的;DLB与E-LBI方法的标准差随着时间的推移逐渐减少,其速度更快一些;E-LBI方法随着时间的加长标准差减少比DLB更快。显然,标准差值越小表示云平台负载越均衡。
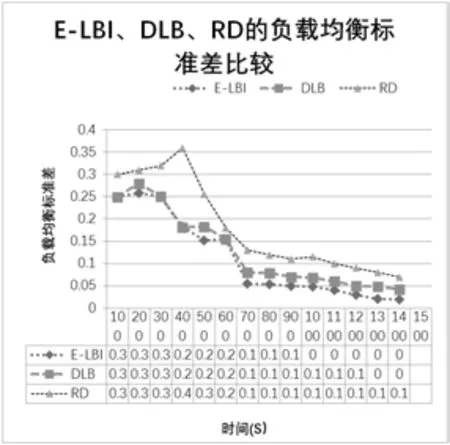
图6 E-LBI、DLB、RD的负载均衡效果的标准差比较
在实验中E-LBI、DLB、RD任务部署事件的失败次数进行比较如图7所示:RD方法和DLB方法随着任务的增加,其部署任务失败的次数越多,E-LBI相对增长缓慢一些。

图7 任务部署事件失败数量的比较
通过应用E-LBI方法进行虚拟机的调度及任务部署,减少了任务部署失败次数,实现了更好的云平台负载均衡效果,特别是在部署大规模而且连续任务请求时,它的表现更为优秀,它提高了云平台处理大数据的效率。
4 结语
数据已成为当今社会的重要资源,为了更好更高效地处理大数据,人们还在不断地寻找新途径和新方法。IAAS云计算平台正在成为社会的基础设施,是信息处理的基础,它提供了一个“按需分配”的计算、存储、网络资源池,为大数据处理提供强大的支持。云计算平台和大数据处理都是一个复杂的大系统,它们之间如何更好地结合,如何提高云计算平台下大数据处理效率,本文只作了简单的分析及优化,并提出一种云计算平台下启迪式的感应负载均衡方法E-LBI,下一步仍将继续优化完善。
